基于卷积神经网络的建筑物精细化提取
2018-03-27黄小赛马佩坤吴剑亮
黄小赛,李 艳,马佩坤,高 扬,吴剑亮
(1.南京大学 国际地球系统科学研究所,江苏 南京 210023;2.江苏省地理信息技术重点实验室,江苏 南京 210023)
1 研究背景与方法
1.1 研究背景
随着高分辨率卫星和航空遥感图像的不断涌现,从这些数据中自动检测或提取人工目标和结构已受到广泛关注。Kim T[1]等提出了一种基于投票策略的建筑物提取方法,首先用Canny算子等边缘检测算法获取建筑物的边缘线段,再根据它们之间的空间关系进行分组,最终通过一些经验知识和搜索方法建立建筑物的空间结构和外形轮廓。CUI S Y[2]等先提取建筑物的几何特征和灰度特征,再根据其空间分布特征和Hough变换特征提取建筑物轮廓。Croitoru A[3]等首先建立城市建筑物的几何规则,然后用直角检测进一步提高建筑物的提取精度,在城市地区取得了不错的效果。Jung C R[4]等先通过窗口Hough变换提取矩形屋顶的角点,再根据几何约束确定矩形的中心点和方向,最终实现对矩形屋顶的提取。Kass M[5]等提出的Snake算法及其改进算法,特别是水平集算法,由于考虑到分割结果的平滑性,且容易集成先验知识,被广泛应用于图像分割,建筑物提取也不例外[6]。
近年来,深度学习发展迅速[7]。在图像处理领域,卷积神经网络(CNN)[8]在图像识别中取得了以往分类算法难以实现的惊人效果。与人工提取图像特征所造成的不确定性相比,该方法可从少量预处理甚至原始数据中学习到抽象、本质和高级的特征,并对平移、旋转、缩放或其他形式的变形具有一定的不变性,已被广泛应用于车牌检测、人脸侦测、文字识别、目标跟踪、机器学习、计算机视觉等领域[9-11]。
1.2 集成方法概述
本文将一张高分辨率航空影像和一张DSM图像作为实验数据。集成方法中包含两种网络模型:用于计算对象是建筑物概率的回归模型和用于判断建筑物形状的分类模型。
首先使用选择性搜索算法[12]生成感兴趣区域(ROI)及其对应的图像,这是一个矩形的子图像;再使用训练好的回归模型对每个ROI打分,并采用非极大值抑制算法得到建筑物对象;然后使用分类模型获得建筑物的形状;最后使用一种基于点集匹配的形状匹配方法获得准确的建筑物轮廓。
2 网络模型的训练
Szegedy C[13]等阐述了深层CNN的概念。CNN的工作过程分为前向传播和后向传播两个阶段。前向传播对输入图像数据进行多层卷积运算,再利用损失函数计算卷积结果得到损失值。反向传播是基于卷积反方向上损失值的传播,用于更新卷积核的权重。
CNN的最大特点是多层卷积,模拟了人类的视觉过程。CNN模型可从低到高,从边缘、线条到矩形平面地识别对象。
2.1 回归模型
本文提出了回归网络模型来评估一个ROI为建筑的概率(图1)。样本包括ROI的输入图像以及相应的LRaB。

图1 回归网络模型
首先需生成训练所需的ROI图像,常见的方法是提供一个固定大小的矩形框,沿着像素移动,再将图像裁剪为ROI图像。然而,该方法有两个问题:ROI图像的数量太大和相邻区域对应的ROI图像非常相似,换言之,数据非常冗余。为此,参考文献[12]提出了选择性搜索算法,用于生成ROIs。选择性搜索利用基于图的图像分割算法[12]生成基本区域,该分割方法通常是过分割的,但各分割区域内部具有非常好的同质性,局部细节保存也很好。一般来说,这些基本区域很小,是ROI的重要组成部分,所以需按一定的标准将这些基本区域合并为目标区域。参考文献[12]提出了一种区域合并方法,首先定义了一个函数来计算两 个区域在颜色、纹理、大小和拟合度等方面的综合相似度,再根据综合相似度的顺序来合并基本区域。通过选择性搜索,将较小的基本区域合并为大区域,就得到了包含不同层次的ROI集合,其中当然也包括建筑物。根据外接矩形切割每个ROI,属于ROI的像素保留原始灰度值,而其他像素填充为零,即可得到训练所需的ROI图像。
然后需为每个ROI指定对应的LRaB,即它们是建筑物的概率。手工分割图像得到一个二值图像,其中1为建筑区域,0为非建筑区域。LRaB的计算公式为:
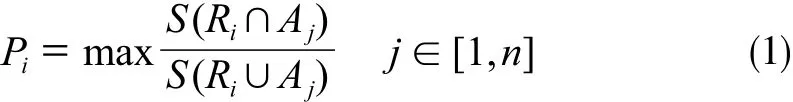
式中,Pi为i号ROI 的LRaB;Ri为一张和原始图像大小相同的二进制图像,其中位于i号ROI内部的像素值为1,其他像素值为0;Aj为一个手工分割的建筑图像,大小与原始图像相同,在编号为j的建筑物内部的像素为1,其他像素为0;S为一张二值图像中值为1的像素总数(图2)。通过以上步骤,创建了训练数据集,如图3所示。

图2 选择性搜索结果和人工分割图像

图3 回归网络模型训练数据制作
2.2 分类模型
本文需通过训练分类模型来判断建筑物的形状,因此训练数据是建筑物图像以及相应的形状类别。LRaB>0.7的ROI图像被认为是建筑物图像,它的形状类别被手动标记。本文预定义了4种形状(图4),以这些建筑物图像及其形状类别作为训练数据,对建筑物形状分类模型进行训练。

图 4 预定义建筑物形状类别
3 建筑物提取集成方法
3.1 建筑物定位
输入一个图像,通过选择性搜索得到ROI集,再通过训练好的回归模型计算各ROI是建筑物的概率。若一个ROI满足下列条件则被认定为建筑物:①评分大于0.5;②该ROI的评分超过所有与其有重叠区域的ROI的评分,即该ROI的评分是一个局部极大值。
图5为实验数据1、2的提取结果,证明了回归模型具有优秀的识别和定位能力,图中白色矩形是被认定为建筑物的ROI的外接矩形。

图5 回归模型结果
3.2 建筑物形状判断
每个建筑物的形状是由训练完成的分类模型判断得到的。图6显示了实验数据1和2的分类结果,其中不同的颜色对应不同的先验形状。从图6a中可以发现,这些建筑物的分类最接近于目视观察的识别。

图6 建筑物形状判断结果(外接矩形颜色与图4相对应)
3.3 建筑物形状匹配
为了获得建筑物的精确轮廓,必须确定从先验形状到建筑物ROI的平移、缩放和旋转参数。通过将建筑物像素设置为1,其他像素设置为0,将每个确定的建筑物ROI转换为二进制图像;再通过提取其边缘得到一个边缘点集合B(图7b中白色像素)。
给定5个参数(tx,ty,sx,sy,θ)和一个先验形状S,可以得到一个变换后的形状S*。点的坐标变换方程为:
(x*, y*,1)T=rotation×scaling×translation×(x, y,1)T(2)式中,(x, y)为S中某点的坐标;(x*, y*)为其在S*中的坐标。

式中,translation为平移矩阵;scaling为缩放矩阵;rotation为旋转矩阵;(a0,b0)为先验形状S的重心坐标。
为了提取建筑物的准确轮廓,本文建立了一个代价函数来衡量转换后的形状S*与B之间的吻合程度:
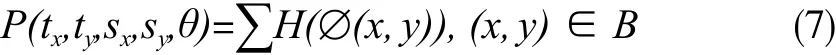
式中,∅(x, y)为点(x, y)到变换后的形状S*的最短距离;H(∅)为一个二值函数。
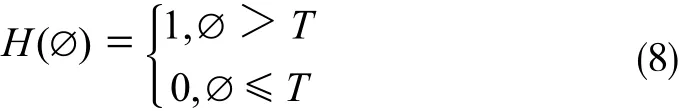
式中,T为阈值。
式(7)用于计算B中到变换后形状S*的最短距离大于阈值T的点的数目。这个代价函数的设计是考虑到集合B中存在一些距离真实建筑物轮廓较远的“错误点”。为了消除这些错误点的影响,需找到可以匹配B中大多数点的S*。为了最小化该代价函数,采用基于确定性排挤机制的小生境遗传算法(NGA)[14]。
完成上述计算后,得到了一组五元参数(tx1,ty1,sx1,sy1,θ1)和对应的变换后形状S*1。 S*
1已非常接近建筑物真实轮廓,不过为了进一步优化建筑轮廓,本文剔除了B中最短距离大于阈值T的点,得到一个新的建筑边缘点集合B1,并建立了一个新的代价函数为:
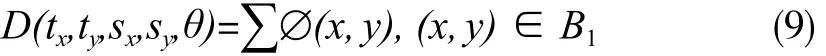
依然使用NGA来最小化式(9),目的是寻找最佳匹配。事实上,由于之前求得的五元参数(tx1,ty1,sx1,sy1,θ1)已非常接近最佳匹配,所以可减少搜索空间到它的一个较小邻域,这样可大幅提高搜索速度。简而言之,最小化式(7)消除了错误轮廓点,并得到五元参数的近似最优值;再最小化式(9),求出最佳匹配参数。

图8 集成方法图像分割结果
图8a、8b的提取精度如表1所示。两个指标的计算公式为:
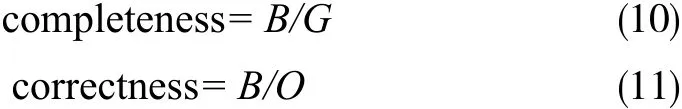
式中,B为在真实情况和分割结果中均被分类为建筑物区域的像素总数量;G为真实情况中是建筑物区域的像素总数量;O为分割结果中被分类为建筑物区域的像素总数量。
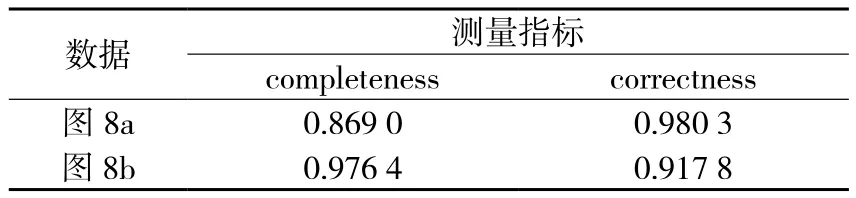
表1 定量评价
4 结 语
本文提出了一个集成方法来检测和提取图像中的建筑物,精细化建筑物的轮廓。该方法包括建筑物定位、建筑物形状判断、建筑物形状匹配等步骤;使用了选择性搜索算法、CNN和遗传算法。实验结果表明,该集成方法在DSM图像和高分辨率遥感影像上均取得了良好的效果。在未来的研究中,将探索如何在训练数据较少的情况下训练出有效的CNN,以及如何在没有先验形状约束的情况下提取准确的建筑物轮廓。
[1] Kim T, Lee T Y, Lim Y J, et al. The Use of Voting Strategy for Building Extraction from High Resolution Satellite Images[J]. IEEE International Geoscience and Remote Sensing Symposium,2005(2):1 269-1 272
[2] CUI S Y, YAN Q, Reinartz P. Complex Building Description and Extraction Based on Hough Transformation and Cycle Detection[J]. Remote Sensing Letters,2012,3(2):151-159
[3] Croitoru A, Doytsher Y. Right-angle Rooftop Polygon Extraction in Regularised Urban Areas: Cutting the Corners [J].Photogrammetric Record,2004,19(108):311-341
[4] Jung C R, Schramm R. Rectangle Detection Based on a Windowed Hough Transform[C].Computer Graphics and Image Processing, Xvii Brazilian Symposium, IEEE Computer Society,2004:113-120
[5] Kass M, Witkin A, Terzopoulos D. Snakes: Active Contour Models[J]. International Journal of Computer Vision,1988,1(4):321-331
[6] LI Y, ZHU L, Shimamura H, et al. An Integrated System on Large Scale Building Extraction from DSM[J]. Int Arch Photogramm Remote Sensing Spat Inf Sci,2010(38):35-39
[7] Salakhutdinov R, Hinton G. Using Deep Belief Nets to Learn Covariance Kernels for Gaussian Processes[C].International Conference on Neural Information Processing Systems, Curran Associates Inc.,2007:1 249-1 256
[8] Fukushima K. A Neural Network Model for Selective Attention in Visual Pattern Recognition[J]. Applied Optics,1986,9(1):5-15
[9] Lawrence S, Giles C L, Tsoi A C, et al. Face Recognition: a Convolutional Neural-network Approach[J]. IEEE Transactions on Neural Networks,1997,8(1):98-113
[10] Turaga S C, Murray J F, Jain V, et al. Convolutional Networks can Learn to Generate Affinity Graphs for Image Segmentation[J].Neural Computation,2010,22(2):511
[11] DONG C, Loy C C, He K, et al. Image Super-resolution Using Deep Convolutional Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2016,38(2):295
[12] Vand S K E A,Uijlings J R R, Gevers T,et al. Segmentation as Selective Search for Object Recognition[C].International Conference on Computer Vision, IEEE Computer Society,2011:1 879-1 886
[13] Szegedy C, LIU W, JIA Y, et al. Going Deeper with Convolutions[C].IEEE Conference on Computer Vision and Pattern Recognition, IEEE Computer Society,2015:1-9
[14] Mahfoud S W. Crowding and Preselection Revisited[C].In Parallel Problem Solving from Nature, North-Holland,1992:27-36
