运用自适应粒化模型的一种数据分类方法
2018-03-27蒙祖强沈亮亮甘秋玲
蒙祖强,沈亮亮,甘秋玲,覃 华
(广西大学 计算机与电子信息学院,南宁 530004)
1 引 言
数据分类是一种重要的数据分析技术[1-4].在大数据时代,数据的复杂性和异构性呈多元化、多样化趋势,一般难以事先从数据中获取面向特定应用的先验知识.对数据分类而言,由于缺乏先验知识,往往需要不断调试算法的有关参数来提高分类性能,而这种调试过程大多是经验性和探试性的,缺乏有效的指导理论,从而极大地降低了分类方法的应用价值和应用范围.因此,构造自适应于复杂数据环境而无需先验知识、具有较高分类准确率的数据分类算法是数据分类研究领域中追求的目标之一[5].在构造自适应数据分类方法研究方面,学者们做了大量的工作.文献[6]研究了最大散度差分类算法的识别率随参数C变化特征,提出了基于最大散度差鉴别准则的自适应分类算法,该算法可以根据训练样本的类内散布矩阵特性自动选择恰当的参数C.文献[7]提出一种自适应的支持向量机分类算法,其优点在于它可以在局部与全局之间保持较好的平衡性,从而在一定条件下提高分类准确率,但它缺乏考虑训练样本之间的关系,其适应性受到限制[8].文献[8]则针对渐变概念漂移的分类问题提出一种自适应近邻投影均值差支持向量机算法,该算法在全局优化中融入数据自身的分布特征,从而提高算法的自适应性.文献[9]亦针对渐变概念漂移的分类问题进行了研究,但其重点研究的是针对概念漂移数据流的一种自适应分类算法.文献[10]针对可拒绝一类分类问题,提出基于最小生成树的多分辨率覆盖模型,实现了在多分辨尺度下对数据流形的自适应紧致覆盖.文献[11]针对kNN分类算法选择参数k难的问题,将k值引入到目标函数设定中,通过计算属于每一类的损失函数值来选择拥有最小函数值的类作为测试样本的类别,从而提出自适应大间隔近邻分类算法.文献[1]通过构造与不同数据集自动相适应的规则评价函数来提高分类准确性,从而提出一种自适应蚁群分类算法.透过这些研究成果可以发现,在自适应数据分类研究方面,目前大多数研究工作主要是面向特定问题对分类算法中某些重要参数的设置和选择进行自适应优化,但在研究自适应于数据集的自适应分类算法方面,相关工作还很少,特别是在利用数据之间存在的关系(如相容关系)来构造自适应分类算法方面的研究,相关工作还很缺乏.
所谓数值数据间的相容关系,是指数值型属性中基于近似相等关系而形成的属性值之间的一种关系,它满足自反性和对称性,因而是相容关系.现有的方法往往“割裂”这种相容关系而未能加以利用,如流行的离散化方法、C4.5中对数值数据的“二分法”等方法都采用类似的处理方式.另外,现有分类算法一般都涉及到许多参数,这些参数的设置和优化尚无有效的指导理论,多凭经验来选择[12,13],受主观因素影响较大,导致现有许多分类方法在不同数据集上表现出来的分类性能差别很大,即它们受到数据集的影响很大[14].因此,如何构造针对数据集的、实现完全数据驱动的自适应分类方法是现今复杂数据环境下数据分析研究面临的一个重要任务.
本文基于属性-值对块(attribute-value block)技术,通过利用数值数据之间的相容关系和数据对象的粒化方法构建数据的自适应粒化模型,然后基于该模型设计面向数据的、完全由数据驱动的自适应分类算法.
2 相容关系下的属性-值对块及其性质
属性-值对块(attribute-value pair block)是美国著名学者Grzymala-Busse教授提出的用于处理不完备信息的一种数据分析技术[15,16].本节先介绍属性-值对块的概念及有关性质,在下一节中将用这种技术来对数值数据进行建模,进而构造自适应粒化模型和数据分类方法.
对给定的训练集T,其对应的数据模型表示为(U,A=C∪D),不妨记为T=(U,A=C∪D),其中U表示训练集中数据对象的集合,A是所有数据属性的集合,C和D分别称为条件属性集和决策属性集,且C∩D=∅;对a∈C,用Va表示属性a的值域.不失一般性,假设D={d},即假设决策属性集D仅由一个属性d组成.对任意x∈U和a∈C,用函数fa(x)表示对象x在属性a上的取值,f称为信息函数.对v∈Va,(a,v)便是决策逻辑语言[17]中的一个原子公式;令[(a,v)]={y∈U|fa(y)=fa(x)},其中v=fa(x),(a,v)称为对象x的属性-值对(attribute-value pair),[(a,v)]称为对象x的关于属性a和值v的属性-值对块(attribute-value pair block)[15].属性-值对块的特点是将一个概念的内涵(属性-值对)和外延(块)有机地结合起来,用于表示粒计算[18]中的基本积木块,为问题的粒化提供方法支撑.可以看到,属性-值对块的物理意义和逻辑意义都很明显.例如,属性-值对块[(a,fa(x))]表示所有与对象x在属性a上取值相同的对象的集合,用属性a是无法区分集合中的这些对象,因而它们构成了基本的积木块,而(a,fa(x))是这个块的一个描述,是解释分类器的一个原子公式.
根据上面的定义,属性-值对块[(a,fa(x))]实际上就是关于等价关系Ra的一个等价类[x]a,其中Ra={
定义1.令δ为闭区间[0,1]中的一个小实数,对于两个对象x,y∈U,称对象x和y在属性a上关于δ近似相等,记为x≈a,δy,如果|fa(y)-fa(x)| ≤δ.
这种近似相等关系≈a,δ实际上是一种相容关系,δ称为相容半径.
性质1.给定δ∈ [0,1],令Tol(a, δ)={
如果δ= 0,则这种相容关系就变为等价关系.
下面给出关于δ的相容关系下有关属性-值对块的概念.
定义2.在相容关系Tol(a,δ)下,令[(a,fa,δ(x))]={y(U|x≈a,(y},[(a,fa,δ(x))]称为对象x的关于属性a的属性-值对块,其中a∈C.
为了方便起见,[(a,fa,δ(x))]通常记为Ka,δ(x),即Ka,δ(x)=[(a,fa,δ(x))].如无特别说明,下文讨论的属性-值对块都是在相容关系Tol(a,δ)意义下进行的.
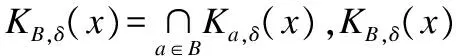
为了方便起见,如果B仅由一个属性组成,如B={a},则KB,δ(x)可写为Ka,δ(x).
如果说Ka,δ(x)是原子积木块,那么KB,δ(x)就是由Ka,δ(x)构成的复合积木块.复合积木块有一个重要的单调性质.
性质2.对任意B1,B2⊆C,如果B1⊆B2,则KB2,δ(x)⊆KB1,δ(x).
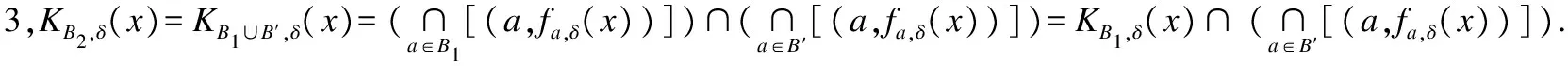
3 基于属性-值对块的自适应粒化模型
目前,自适应分类方法主要是针对算法中的一些重要参数进行自适应优化.实际上,在复杂数据环境下针对数据集的自适应优化同样很重要.对于数值型数据,现有预处理方法和分类算法往往是人为“割裂”了数值数据之间本来蕴含的一些关系,或者说它们蕴含的关系不能很好地利用到算法当中、为提高分类性能提供帮助.例如,假设有一属性a,其属性值都已经归一化:fa(1)=0.000,fa(2)=0.099,fa(3)=0.100,fa(4)=0.110,fa(5)=1.000.对此属性,如果采用区间原理来离散化,可能得到如下的离散化结果:[0,0.1),[0.1,0.2),…,[0.9,1.0](这些区间是不相交的).这存在许多不合理的地方,例如,根据这种离散化结果,fa(2)和fa(3)被认为是不相等的,而fa(4)和fa(3)是相等的.但直觉告诉我们,fa(2)比fa(4)更接近fa(3);C4.5在分类过程中采用的“二分法”同样有可能造成类似的问题,其根本原因在于离散化后或分裂后形成的区间是不相交的.实际上,一个属性值应该允许它等于其“附近的”数(排序后),这在许多场合中更为合理.比如,fa(3)应该“等于”其附近的fa(2)和fa(4).这种思路是以数据对象为中心来考虑数据之间的关系,或者说,以对象为中心来考虑数据之间的“相等”问题能够更好地利用数据之间本来蕴含的关系,这种关系就是数据之间的相容关系.本小结将对此进行形式化描述并探讨更深层次的问题.
3.1 理论模型
以数据对象为中心的处理方法可以利用属性-值对块技术来实现.以属性-值对块替换对应的数据对象,于是得到一个新的粒化模型——基于属性-值对块的粒化模型(granulation model),记为GM=(Ka,δ(U),C∪D)a∈C,其中,Ka,δ(U)={Ka,δ(x) |x∈U}.Ka,δ(x)是这个模型中的基本积木块.对任意y∈Ka,δ(x),fa(x)被认为与fa(y)相等.
这个模型与原来的数据模型T=(U,A=C∪D)相比,其基本数据积木块由原来的数据对象变成了数据对象的属性-值对块.显然,相容半径δ决定着属性-值对块Ka,δ(x)的大小:δ越大则Ka,δ(x)越大,δ越小则Ka,δ(x)越小.当相容半径δ等于0的时候,粒化模型GM就退化为原来的数据模型T.到底相容半径δ取多大合适呢?这是本文讨论的重点内容之一.为此,先引入相关的概念.
定义4.对给定的粒化模型GM=(Ka,δ(U),C∪D)a∈C,D={d},如果存在x∈U,使得|fd(KC,δ(x))| > 1,则该粒化模型是不一致的,否则是一致的;相应地,令ρ(GM,δ)=|{x‖fd(KC,δ(x))|>1}|/|U|,ρ(GM,δ)称为粒化模型GM的不一致程度,其中fd(KC,δ(x))表示块KC,δ(x)在信息函数fd下的像.
也就是说,粒化模型GM是不一致的当且仅当ρ(GM,δ) > 0.
该定义的直观意义是,|fd(KC,δ(x))| > 1就意味着块KC,δ(x)至少跟两个决策类相交,因而是不一致的.对数值系统来说,初始的数据模型一般都是一致的.如果相容半径δ=0,粒化模型退化为原来的初始数据模型,都是一致的;如果δ逐渐增大,各个基本块也逐步增大,从而ρ(GM,δ)逐渐变大,粒化模型也随之逐步趋向不一致;当δ=1时,ρ(GM,δ)达到最大值1,粒化模型变得完全不一致,当然这种粒化模型没有任何研究价值,一般不考虑.我们有下面的性质.
性质3.对给定的粒化模型GM=(Ka,δ(U),C∪D)a∈C,不一致程度ρ(GM,δ)会随相容半径δ呈非严格单调递增.
证:对任意两个相容半径δ1,δ2([0,1],假设δ1<δ2,我们只需要证明ρ(GM,δ1)≤ρ(GM,δ2).
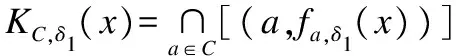
性质3说明,在区间[0,1]中必存在一点δ0,使得当δ<=δ0时,ρ(GM,δ)=0(粒化模型一致);当δ>δ0时,ρ(GM,δ)>0(粒化模型不一致).我们引入如下定义.
定义5.令δ0=max{δ∈[0,1]|ρ(GM,δ)=0},则δ0称为粒化模型的一致临界点.
对于给定的原始数据模型T=(U,A=C∪D),当构造其粒化模型时,最为关键的问题是如何选择相容半径?过大或过小的相容半径都会导致不好的分类结果.在多次的实验中我们发现,当相容半径约等于一致临界点的两倍值时,分类准确率达到最大值或近似最大值.根据性质3,我们可以利用折半查找方法,完全依赖于数据之间的相容关系,快速找到粒化模型的一致临界点,从而实现对相容半径的自适应优化,这个优化过程是完全由数据驱动的,不需要任何先验知识.假设δ0表示找到的一致临界点,其二倍值2δ0记为δ″,即δ″=2δ0,则由此构造的粒化模型可以表示为(Ka,δ″(U),C∪D)a∈C,称为自适应粒化模型(一种理论模型).
3.2 存储模型
根据上述自适应粒化模型的理论描述,模型中每一个属性值实际上一个属性-值对块.这样,其存储空间会就是原来训练集规模的多倍,极大浪费存储开销,限制模型的实际应用范围.因此,需要寻找一种有效的存储结构.
在粒化模型(Ka,δ(U),C∪D)a∈C中,任意一属性a∈C,数据间的关系Tol(a,δ)都是相容关系(性质1),于是可以引入下面的一些概念并导出有关性质.
定义6[19].在相容关系Tol(a,δ)下,对子集TC⊆U,如果对任意x,y∈TC,均有
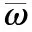
性质4.在粒化模型GM=(Ka,δ(U),C∪D)a∈C中,Ka,δ(x)=∪MCa,δ[x],即Ka,δ(x)={y|y(TC,TC∈MCa,δ[x]},其中x∈U.
根据属性-值对块以及最大相容类的定义,我们不难证明此性质,具体证明过程在此省略.
性质4表明,属性-值对块的计算可以通过合并对应最大相容类来实现,而在数值条件下的最大相容类则可以通过先排序,然后一遍扫描数据集即可快速产生[20],其时间复杂度为O(|U|log|U|);对整个模型而言,建立最大相容类空间ψ(δ)的复杂度为O(|C‖U|log|U|).如果相容程度不是很高,ψ(δ)需要的存储空间略大于O(|C‖U|);如果相容关系退化为等价关系,则其需要的存储空间恰好是O(|C‖U|).
在建立了最大相容类空间ψ(δ)之后,再建立各最大相容类的索引结构,以便实现快速访问.
定义8.对于给定的最大相容类空间ψ(δ),令loc(TC)表示最大相容类TC在ψ(δ)中的位置索引,令R(δ)={ga(x)|ga(x)={loc(TC)|TC(MCa,δ[x]},x(U,a∈C},ψ(δ)称为ψ(δ)的位置索引结构.
最大相容类空间ψ(δ)及其位置索引结构ψ(δ)共同构成了粒化模型的存储结构(模型),记为[Rψ(δ),ψ(δ)].
我们的目标是找到一致临界点δ0.根据性质3,这个目标可以用折半查找的方法来实现.假设计算δ0的精度要求是λ∈(0,1),则最多需要找1/λ个点.而根据折半查找算法的复杂度,总共只需要进行log2(1/λ)次查找操作即可找到λ0(精度λ下的一致临界点),从而形成自适应粒化模型(Ka,δ″(U),C∪D)a∈C的存储结构[R(δ″),ψ(δ″)],其中δ″=2δ0.因此,建立[R(δ″),ψ(δ″)]的计算复杂度约为O(log2(1/λ)|C‖U|log|U|).例如,如果精度λ=0.01,则log2(1/λ)=log2100 ≈6.6 ≈ 7,即需要7次计算可找到δ0.如果精度λ要求不是很高时,O(log2(1/λ)|C‖U|log|U|)约等于O(|C‖U|log|U|).

4 基于自适应粒化模型的分类算法
在生成自适应粒化模型(Ka,δ″(U),C∪D)a∈C后,可以通过数据对象的约简和对象规则的简化来构造分类器.为此,先引入相关概念,然后分别讨论这两个过程.

任何一条基本规则都是通过删除训练集T中某一条数据对象的若干条件属性(包括属性值)后得到的,不妨称为由该数据对象导出的基本规则.为方便,我们用r或r1,r2等来表示一条基本规则.任何一条基本规则实际上都是决策逻辑语言中的一条公式.对任意给定的公式φ,用set(φ)表示公式φ中出现的条件属性的集合(不含决策属性).例如,如果r=(a,0.11)∧(c,0.93) → (d,yes),则set(r)={a,c}.

显然,一条有意义的规则必须满足ant_cover(r)⊆(con_cover(r),这称为规则的有效性;对于有效规则r,|ant_cover(r)|称为规则r的有效覆盖度.有效覆盖度是一条规则所能覆盖的数据对象的数目.
为获得泛化能力强的规则,需要提高规则的支持度,这意味着要尽可能地删除规则的条件属性.这样,随着条件属性的减少,ant_cover(r)逐步变大.但为保证有效性,规则必须满足条件ant_cover(r)⊆con_cover(r).因此,对于给定的一条数据对象,保留哪些条件属性来构造规则是一个关键问题,这就是数据对象的约简问题.
定义11.对于基本规则r,令B=set(r),如果满足下面两个条件,则称B是规则r的一个约简:(1)ant_cover(r)⊆con_cover(r);(2)从规则r中删除任何一个条件属性,得到的新规则r′都不满足ant_cover(r′)⊆con_cover(r′).
已有研究结果表明[20],寻找最优约简是NP难问题.因此,本文不追求最佳的约简,而是寻找近似约简.主要思路是,对给定的数据对象(记录),按照某一种既定顺序对对象中的条件属性进行逐一检测:如果删除某属性后没有破坏上述条件(1),则将之删除,否则保留.虽然这种方法只是得到近似约简,但其可操作性强,具有实际意义,已为许多工作所采用[12,13,21].
另外一个影响效率的问题是,在循环检测过程中如何检查是否满足条件(1).直接用集合的方法会比较耗时.我们注意到,|con_cover(r)|=1,因此也有|ant_cover(r)|=1.利用这一点,可以加速对条件(1)的判断.
对数据对象的约简是逐一进行的,每一条数据对象都会导出一条基本规则.假设RuleSet是训练集T=(U,A=C∪D)经过约简后形成的规则集,则|RuleSet|=|U|,且RuleSet中的规则和U中的对象是一一对应的.但RuleSet中的规则会大量出现功能重复的情况.例如,可能会产生这样的两条后件一样的有效规则r和r′:ant_cover(r′)⊆ant_cover(r).显然,规则r在功能上完全能够替代规则r′,因此规则r′是冗余的,应予以删除.此外,我们还要保证训练集中的每一条数据对象都必须存在能够覆盖它的规则.这样,如何删除这些功能上冗余的规则以及保留必要的规则(以覆盖整个训练集)是构造分类器的另一个关键问题.
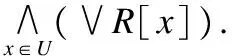
一种途径是利用有效覆盖度来构造启发信息.方法是,先计算RuleSet中每条规则r的有效覆盖度,并按照有效覆盖度对U中的数据对象进行降序排列,然后利用这个序列来选择规则,最终构造分类器.这样,结合上述的自适应粒化模型,我们可以给出一个完整的分类算法,算法描述如下:
分类算法的描述:
输入:训练集T=(U,A=C∪D)
输出:分类器RS(由规则构成)
Begin
Step1. 建立自适应粒化模型(Ka,δ″(U),C∪D)a∈C及
存储结构[R(δ″),ψ(δ″)];
Step2. 基于[R(δ″),ψ(δ″)],对U中的对象进行约简,
设结果为RuleSet;
Step3. 对所有r∈RuleSet,计算ant_cover(r),同时
保存R[x],其中r为x导出的规则;
Step4. 据RuleSet中相应规则的覆盖度,对U中对象
降序排序,设结果为U={x1,x2,…,xn};
Step5. 令RS=∅;
Step6. 令i=1;
Step7. while(U≠∅)
{
Step8. 令U=U-xi;
Step9. if∀r1∈RS,r1∉(R[xi]then
{

Step11. 令RS=RS∪{r0};
}
Step12.i++;
}
Step13. returnRS;
End
步骤1中,建立存储结构[R(δ″),ψ(δ″)]的计算复杂度为O(log2(1/λ)|C‖U|log|U|),如果精度(比较大时(精度要求不高),O(log2(1/λ)|C‖U|log|U|)≈O(|C‖U|log|U|).此后,算法的计算都依赖于存储结构[R(δ″),ψ(δ″)].
步骤2中,计算属性-值对块KB,δ″(x)的复杂度略大于O(|B|m),其中m为涉及的最大相容类规模的平均值.因此,计算所有数据对象的约简的复杂度略大于O(|U‖C|m′),其中为m′所有最大相容类规模的平均值.
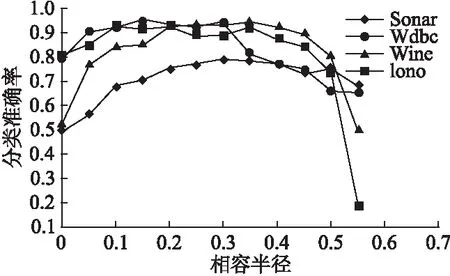
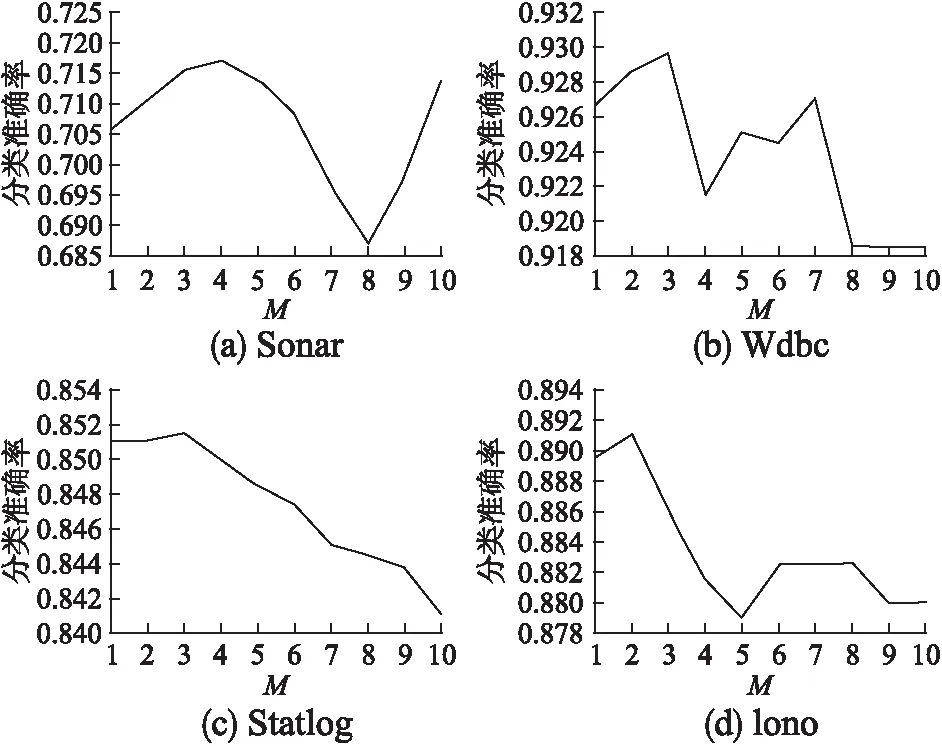
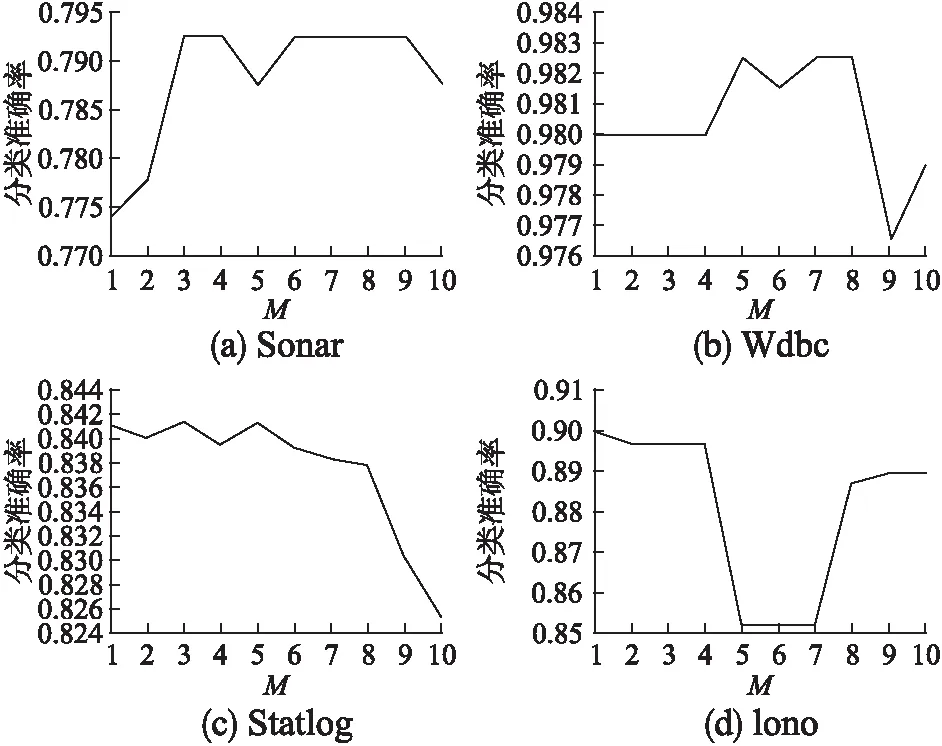
在步骤3中,假设RuleSet={r1,r2,…,rn},ri为对象xi导出的规则,则该步骤的计算复杂度为O(|set(r1)|m1+set(r2)|m2+…+|set(rn)|mn)< 步骤7-12为一个循环体,循环次数为|U|.循环体中,步骤10是在覆盖规则集R[xi]中选择一条覆盖度最大的规则,R[xi]是在步骤3中已经形成的中间结果;耗时的是步骤9,它每次都需要判断RS中每一条规则是否属于R[xi].RS是在不断增加的,|RS|在循环开始时为0,其后逐步增加,但最后也远远小于|U|.我们用RSi表示第i次循环时所形成的规则集,并假设c为各覆盖规则集的规模的平均值,则循环体的计算复杂度为:O(|RS1|c+ |RS2|c+…+ |RS|U||c)=O((|RS1|+ |RS2|+…+ |RS|U||)c)< 综合以上分析,决定算法效率的部分主要是步骤1、步骤2以及步骤7-12(循环体),它们的计算复杂度分别为O(|C‖U|log|U|)、O(|U‖C|m′)和O(|U‖RS|c).这三部分的复杂度表达式不一样,我们难以直接从形式上去判断它们的优劣,但从实验中我们发现,步骤2是最耗时的,因此O(|U‖C|m′)代表了算法的复杂度,其中为m′所有最大相容类规模的平均值. 为验证所提出算法的有效性,本文以C++为开发语言,在CPU为Intel(R) Core(TM) i7-4510U CPU @ 2.00GHz,内存8GB,以Win7为操作系统的计算机上,从多角度对算法的性能进行了验证和对比分析.实验方法采用十折交叉验证,实验用到的数据是来自机器学习研究领域中广泛使用的UCI数据集*Ucirvine Machine Learning Repository. 表1 数据集的基本信息 序号数据集(缩写)规模条件属性个数决策类个数1Sonar2086022Wdbc5693023Wine1781334Iono3513425Statlog6435366 相容半径(对粒化模型的影响最为关键,也是构建自适应粒化模型和整个分类算法唯一需要优化的参数(数据驱动的自动优化),其取值对后面分类性能的影响是至关重要的.我们在4种数据集上分别测试不一致程度和相容半径之间的关系,结果如图1所示. 图1 不一致程度随相容半径变化的趋势Fig.1 Variation of inconsistency degree with tolerance radius 由图1可以看出,不一致程度随相容半径的增加而呈现单调递增的变化趋势,这个结果和性质2是吻合的.这个结论的成立为我们利用折半查找来寻找一致临界点提供了理论依据. 为进一步观察相容半径对最终分类性能的影响,分别就上述4种数据集用不同的相容半径来构造不同的粒化模型,然后基于构造的粒化模型分别运行本文提出的分类算法,以观察分类准确率随相容半径的变化趋势.结果如图2所示. 图2 分类准确率随相容半径变化的趋势Fig.2 Variation of classification accuracy with tolerance radius 由图2,当相容半径从0向1逐渐增加时,分类准确率在各个数据集上大致呈现先逐步升高后逐步下降的趋势,是一种相对的“单峰”变化趋势.也就是说,在相容半径的取值区间[0,1)中,分类准确率的最大值大致位于此“峰顶”上,这为我们寻找最大值提供了启发信息. 再仔细分析图1和图2涉及的实验数据,我们发现数据集Sonar,Wdbc,Wine和Iono对应粒化模型的一致临界点大约分别是0.1797,0.0938,0.1750和0.1094;当容半径大约取值在这些一致临界点的两倍值上时,分类准确率达到最大值或近似最大值.例如,上述一致临界点的二倍值分别为0.360,0.188,0.350,0.219,它们分别接近0.35,0.20,0.35,0.20.在我们测试的结果中,当相容半径分别为0.30,0.15,0.35,0.20时,算法在数据集Sonar,Wdbc,Wine,Iono上分别获得最大的分类准确率,它们是0.78,0.94,0.94,0.91.上述的对应关系如图3所示. 根据图3中所示的一致临界点与最大分类准确率的关系以及图1中所示的单调性和图2所示的“单峰”性,我们可以估计当相容半径大约为一致临界点的两倍值时,本文算法能够获得近似最大准确率.这样,我们先利用折半查找来寻找一致临界点,然后以临界点的两倍值作为相容半径的值,从而实现完全由数据驱动来构造自适应粒化模型,并基于该模型利用本文提出的分类算法可以获得近似最大分类准确率. 图3 一致临界点与最大分类准确率的近似关系Fig.3 Relation between consistent critical point and the best classification accuracy 为进一步对比本文算法在自适应方面的性能,在四种数据集Sonar,Wdbc,Statlog和Iono上,我们测试了C4.5、Cart、SVM三种著名分类算法在不同参数下的分类性能,测试结果分别如图4、下页图5和图6所示. 图4 C4.5准确率在不同数据集上随参数M的变化情况(M为叶子结点上的最小对象数)Fig.4 Variation of C4.5′s accuracy with parameter M on different data sets (M denotes the minimum number of instances per leaf) 从图4-图6可以看出,C4.5、Cart、SVM在这些数据集上获得的分类准确率受到参数的影响较大,不同的参数设置可能导致完全不同的分类结果;换句话说,不同的数据集可能需要设置不同的参数.实际上,这些算法涉及的参数不只这些,比如在SVM算法中核函数的选择就有多种.因此,如何有效地设置分类算法中涉及的参数、保证算法在具体的数据集上能够获取较高的分类准确率是分类算法研究的一个重要问题.遗憾的是,对参数的这种优化设置目前尚无有效的指导理论,很多是凭经验设置的,受主观因素影响大. 图5 Cart准确率在不同数据集上随参数M的变化情况(M为叶子结点上的最小对象数)Fig.5 Variation of Cart′s accuracy with parameter M on different data sets (M denotes the minimum number of instances per leaf) 本文提出的基于自适应粒化模型的数据分类算法不涉及人工参数设置,它完全由数据驱动,可直接用于对数值数据进行分类,并且获得较好的分类结果.为验证本文算法的分类准确率,我们进一步将本文算法与C4.5、Cart和SVM在表1中所示的4数据集上进行对比,其中本文算法不需要任何的手工参数设置,完全由数据驱动,而其他算法则经过了一系列的手工参数选择,以选择最好的结果.实验结果如表2所示. 从表2中可以看出,总体上本文算法表现出了较好实验效果——准确率和召回率都相对比较高,但在数据集Wdbc和Wine上略比SVM算法低.实际上,我们对算法C4.5、Cart和SVM进行了大量的参数调整,从中选择最好的结果,这本身是一个繁杂的过程,有时候是不可实现的;而本文算法则是自适应地在这些数据集上运行,不做任何的参数调整和设置就能表现出相对较高的分类性能,实现了自适应的数据分类效果. 图6 SVM准确率在不同数据集上随参数C的变化情况(使用线性核函数,C为权重参数)Fig.6 Variation of SVM′s accuracy with parameter C on different data sets (linear kernel function is used and C denotes the weight in SVM) 表2 分类准确率和召回率Table 2 Accuracy and recall of classification algorithms 在现今复杂数据环境下,往往难以事先获得有关数据的先验知识,这限制了带有许多参数的分类方法的应用范围.本文研究了一种面向数值数据的自适应分类问题,提出了一种基于自适应粒化模型的数据分类方法.在该方法中,通过粒化方法来构造数据的自适应粒化模型,然后基于此模型,通过数据对象的约简和对象规则的简化来构造分类器.自适应粒化模型的特点在于,不割裂数据之间蕴含的关系,而是以数据对象为中心,充分考虑了数据之间的关系——相容关系,并基于这种关系,通过相容半径的自动优化来构造自适应粒化模型.提出的整个分类方法完全是由数据驱动的,不需要任何先验知识,实现了对数据的自适应分类,并且表现出相对较好的分类效果.从工程应用的角度看,本文算法具有更好的实际应用价值. [1] Ma An-xiang,Zhang Chang-sheng,Zhang Bin,et al.An adaptive ant colony classification algorithm[J].Journal of Northeastern University (Natural Science),2014,35(8):1102-1106. [2] Mao Guo-jun,Hu Dian-jun,Xie Song-yan.Models and algorithms for classifying big data based on distributed data streams[J].Chinese Journal of Computers,2016,39(72):1-16. [3] Nieto P J G,García-Gonzalo E,Fernández J R A,et al.A hybrid wavelet kernel SVM-based method using artificial bee colony algorithm for predicting the cyanotoxin content from experimental cyanobacteria concentrations in the trasona reservoir (Northern Spain)[J].Journal of Computational & Applied Mathematics,2016,309:587-602. [4] Barkana B D,Saricicek I,Yildirim B.Performance analysis of descriptive statistical features in retinal vessel segmentation via fuzzy logic,ANN,SVM,and classifier fusion[J].Knowledge-Based Systems,2017,118:165-176. [5] Wu X,Zhu X Q,Wu G Q,et al.Data mining with big data[J].IEEE Transactions on Knowledge and Data Engineering,2013,26(1):97-107. [6] Song Feng-xi,Zhang Da-peng,Yang Jing-yu,et al.Adaptive classification algorithm based on maximum scatter difference discriminant criterion[J].Acta Automatica Sinica,2006,32(4):541-549. [7] Grinblat G L,Uzal L C,Ceccatto H A,et al.Solving nonstationary classification problems with coupled support vector machines[J].IEEE Trans on Neural Networks,2011,22(1):37-51. [8] Zhang Jing-xiang,Wang Shi-tong,Deng Zhao-hong.Adaptive classification algorithm for gradual concept-drifting data[J].Pattern Recognition & Artificial Intelligence,2013,26(7):623-633. [9] Guo Gong-de,Li Nan,Chen Li-fei.A self-adaptive classification method for concept-drifting data streams[J].Journal of Shandong University (Engingeering Science),2012,42(4):1-7. [10] Hu Zheng-ping,Feng Kai.An cdaptive one-class classification algorithm based on multi-resolution minimum spanning tree model in high-dimensional space[J].Acta Automatica Sinica,2012,38(5):769-775. [11] Yang Liu,Yu Jian,Jing Li-ping.An adaptive large margin nearest neighbor classification algorithm[J].Journal of Computer Research and Development,2013,50(11):2269-2277. [12] Hu Q H,Yu D R,Xie Z X.Neighborhood classifiers[J].Expert Systems with Applications,2008,34(2):866-876. [13] Hu Q H,Liu J F,Yu D R.Mixed feature selection based on granulation and approximation[J].Knowledge-ased System,2008,21(4):294-304. [14] Cervantes J,García-Lamont F,Rodriguez-Mazahua L,et al.PSO-based method for SVM classification on skewed data sets[J].Neurocomputing,2017,228:187-197. [15] Grzymala-Busse J W,Clarka P G,Kuehnhausen M.Generalized probabilistic approximations of incomplete data[J].International Journal of Approximate Reasoning,2014,55 (1):180-196. [16] Grzymala-Busse J W.Generalized parameterized approximations[C].Proceedings 6th International Conference on Rough Sets and Knowledge Technology (RSKT 2011),2011:136-145. [17] Pawlak Z.Rough Sets-theoretical aspects of reasoning about data[M].Kluwer Academic Publishers,1991. [18] Pedrycz W.Granular computing:an alysisand design of intelligent systems[M].CRCPress,Francis Taylor,BocaRaton,2013. [19] Meng Zu-qiang,Shi Zhong-zhi.A fast approach to attribute reduction in incomplete decision systems with tolerance relation-based rough sets[J].Information Sciences,2009,179(16):2774-2793. [20] Liu Shao-hui,Sheng Qiu-jian,Wu Bin,et al.Research on efficient algorithms for rough set methods[J].Chinese Journal of Computers,2003,26(5):524-529. [21] Jia X Y,Liao W H,Tang Z M,et al.Minimum cost attribute reduction in decision-theoretic rough set models[J].Information Sciences,2013,219(1):151-167. 附中文参考文献: [1] 马安香,张长胜,张 斌,等.一种自适应蚁群分类算法[J].东北大学学报(自然科学版),2014,35(8):1102-1106. [2] 毛国君,胡殿军,谢松燕.基于分布式数据流的大数据分类模型和算法[J].计算机学报,2016,39(72):1-16. [6] 宋枫溪,张大鹏,杨静宇,等.基于最大散度差鉴别准则的自适应分类算法[J].自动化学报,2006,32(4):541-549. [8] 张景祥,王士同,邓赵红.适于渐变概念漂移数据的自适应分类算法[J].模式识别与人工智能,2013,26(7):623-633. [9] 郭躬德,李 南,陈黎飞.一种适应概念漂移数据流的分类算法[J].山东大学学报(工学版),2012,42(4):1-7. [10] 胡正平,冯 凯.高维空间多分辨率最小生成树模型的自适应一类分类算法[J].自动化学报,2012,38(5):769-775. [11] 杨 柳,于 剑,景丽萍.一种自适应的大间隔近邻分类算法[J].计算机研究与发展,2013,50(11):2269-2277. [20] 刘少辉,盛秋戬,吴 斌,等.Rough 集高效算法的研究[J].计算机学报,2003,26(5):524-529.5 实验分析
Table 1 Main information of data sets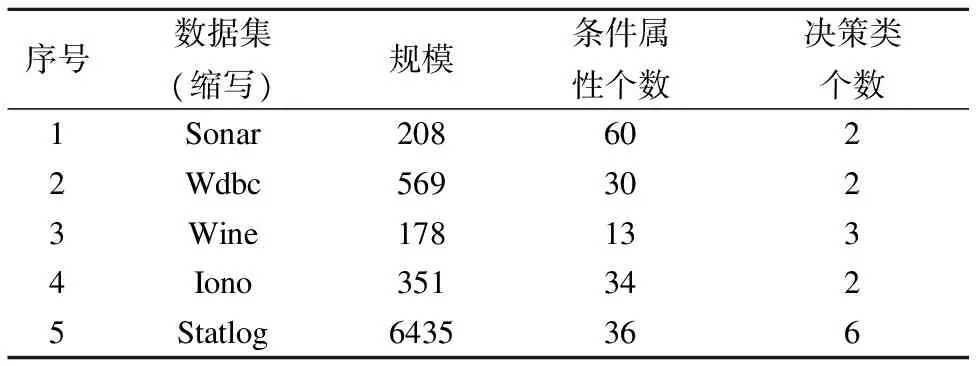




6 结 论
