自适应属性加权近邻传播聚类算法
2018-03-26李海林
李海林,魏 苗
(1.华侨大学信息管理系 福建 泉州 362021;2.华侨大学现代应用统计与大数据研究中心 福建 厦门 361021)
聚类分析是数据挖掘领域中较为基础的数据处理手段,通过聚类算法对数据分类能够将一个数据集划分为若干个类内对象尽可能相似而类间数据对象相异的类簇[1],从而在数据集中发现潜在的数据模式与内在联系[2]。由于数据分类应用的广泛性,聚类分析在多个领域扮演着重要角色,如:统计数学[3]、模式识别[4]、社交网络[5]、天文学[6]、电气电子学[7]和生物科学[8]等。
在众多聚类算法中,文献[9]提出的近邻传播聚类(affinity propagation, AP)不仅有效地解决了传统K-Means聚类算法中初始聚类中心的选择对聚类结果产生影响的问题,而且不需要提前设定聚类的类簇数目。它在聚类过程中将每个数据对象视为潜在的数据代表点,通过在数据之间传播两种竞争信息,即代表度与有效性,最终获得较为稳定的聚类结果。近邻传播聚类算法自提出以来,不少学者对它进行了研究并提出改进方法,如文献[10]提出一种可变相似性度量的近邻传播聚类,通过改进近邻传播聚类中的相似性度量方法,拓展了近邻传播的应用领域,并提升了近邻传播算法的性能。文献[11]提出一种用于社区发现的基于近邻传播的多目标演化算法,该算法通过结合近邻传播与演化算法,有效提升了社区发现的准确率与效率。通常情况下,多数学者在进行聚类分析研究时,将数据的所有属性视为同等重要,即每个属性在算法设计时都设为相同的权值[12],没有考虑因数据属性权重不相等对数据挖掘分析结果的影响。如在医学检查记录中,针对不同的疾病诊断,人们往往关注的是不同病历指标属性的数值结果,存在指标属性重要程度的差异性问题。也有研究[13]表明,有意义的聚类模式和结果通常会出现在某几个特定属性组成的数据中,而不是所有属性。由于属性的重要性不相等,在聚类过程中提高较有实际意义的属性权值,削减不重要属性对聚类结果的影响,使得基于权重属性分析的聚类算法能够提高分类结果的质量。部分学者在这方面做了相关研究[14-16],并提出了更具有挖掘效果的聚类分析方法[15,17-18]。然而,这些方法因使用了K-Means聚类从而易受初始聚类中心选择的影响,造成基于加权属性的K-Means聚类方法不稳定、聚类结果不准确。
针对数据属性的重要程度存在相异性和经典聚类算法的加权改进,如加权K-means算法的聚类结果存在不稳定性的问题,本文提出一种自适应数据属性加权的近邻传播聚类算法(adaptive feature weight algorithm based on affinity propagation, AFW_AP)。该方法在传统近邻传播聚类的过程中通过相似性矩阵考虑数据属性权重的影响,根据每次迭代聚类结果的目标评价函数来自适应确定数据属性的权值,动态更新近邻传播算法中的两种竞争信息,进而提升近邻传播聚类算法的效果。通过在传统近邻传播聚类算法中加入属性权值的计算,在提高近邻传播聚类质量的同时,还继承了近邻传播不受初始聚类中心影响的特点,使得聚类结果具有较好的稳定性。数值实验结果表明,与其他聚类算法相比,新方法AFW_AP具有更好的数据聚类分析效果。
1 近邻传播聚类
AP是一种高效的基于图论的聚类方法,以数据间的相似性矩阵为聚类基础,在每次迭代过程中不断在数据间交换两种竞争信息:代表度(responsibility)和有效性(availability),直到产生一个收敛的聚类结果为止。与K-Means聚类不同,近邻传播聚类不需要限定聚类簇数,并且不进行初始聚类代表点的选择,它在聚类过程中将数据集中的每个数据对象都作为潜在的数据代表点。由于近邻传播不需要初始化聚类代表点,它所产生的聚类结果较K-Means聚类更加稳定。
近邻传播算法中的任意两个数据对象之间的相似性定义为两点间距离平方的负数。例如,数据点xi和数据点xj的相似性表示为特别的,在相似性矩阵中,s(i,i)的值被称为偏向参数(preferences)。偏向参数的选择会影响聚类结果中的类簇数目,偏向参数的取值为相似性矩阵中的元素最小值时能产生类簇较少的聚类结果,偏向参数取相似性矩阵中的最大值时会产生类簇数目较多的聚类结果[19]。一般情况下取相似性矩阵的中位数作为偏向参数的值。
在近邻传播聚类算法的迭代过程中,代表度和有效性两种信息的计算目的是在数据之间不断传递以产生胜出的代表点。代表度r(i,j)是从数据点xi传到候选代表点xj的信息,反映点xj对点xi的代表程度。有效性a(i,j)是从代表点xj传递到数据点xi的信息,反映点xj作为点xi的代表点的有效程度。代表度和有效性的更新为:
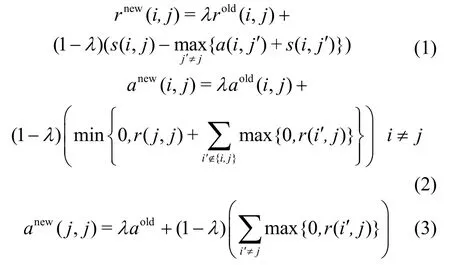
代表度和有效性在聚类过程中不断迭代更新,直到产生一个收敛的聚类结果为止。其中,为了避免近邻传播在聚类过程中发生数据震荡,在迭代过程引入阻尼因子λ,使得每次迭代的值都为上一次迭代旧值和当前迭代新值的加权计算结果。λ的取值能够影响近邻传播的迭代次数,当λ较小时,迭代次数较少;若λ较大,迭代次数也会增加。研究[20]表明当λ的取值区间为(0.5,1)时能够明显增强算法的稳定性。为了减少数据震荡的几率,本文将λ的取值设为0.9。另外,在近邻传播算法的任意迭代阶段,可以通过式(4)利用代表度矩阵R和有效性矩阵A得出聚类结果,即每个数据对象选择代表度与有效性之和最大的数据点作为自身的聚类代表点:
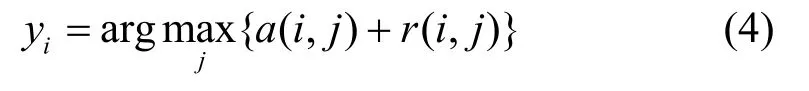
式中,a(i,j)为矩阵中A的元素;r(i,j)为矩阵R的元素。近邻传播算法通过在聚类过程中对两种传播信息的更新计算得出聚类结果,无需初始化聚类中心,并且不用指定聚类结果中类簇的数目,算法易用性较强。然而,大多数对近邻传播算法的研究缺少考虑在聚类过程中属性权值的影响,因此在对高维数据集进行聚类时,有必要进一步研究基于属性权值的近邻传播聚类算法。
2 自适应属性加权近邻传播聚类
自适应属性加权近邻传播聚类算法是在传统近邻传播聚类算法的基础上,考虑了属性权重的影响,使得属性权值能够根据近邻传播聚类过程中每次迭代的聚类结果实现自适应调整,并且通过更新后的相似性矩阵将属性权值的调整反映到下次迭代过程中,重新计算两种竞争信息,以便获得更好的近邻传播聚类效果。
2.1 自适应属性权值
针对传统近邻传播算法缺少考虑属性权重的问题,提出基于数据属性权值的近邻传播聚类方法。从传统近邻传播的过程中易知,近邻传播算法能通过逐步更新两种竞争信息来逐渐获取更好的聚类结果,最终使得聚类算法结果趋于稳定。在每次迭代过程中,近邻传播聚类都可以获得相应的聚类结果,根据该结果的数据分布不仅可以确定属性的重要程度,还可实现动态自适应的属性权值更新,进而使近邻传播算法产生更好的聚类效果。
为了得到自适应的数据属性权值,在近邻传播的聚类过程中需要考虑两个问题:1)什么样的聚类结果是好的,即确定聚类结果的评价目标函数;2)如何根据聚类结果来确定数据的属性权值,即确定每次迭代计算中数据属性权值的更新规则。
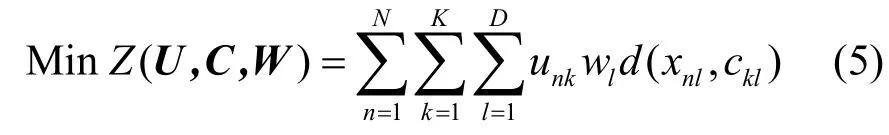
且须满足:
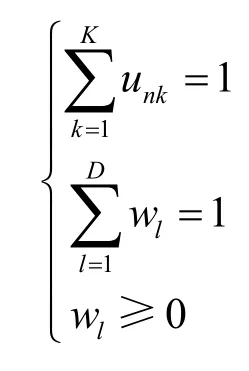
式中,Z代表各个类簇中的数据对象与其聚类代表点之间的距离之和,Z越小表示当前聚类质量越高,即期望最终的聚类结果使其最小;U代表一个N×K的分类二元矩阵;当时,表示数据点xn属于第k个类簇;否则,该数据点不在第k类;代表k个类簇中的聚类中心,在K-Means算法中,该聚类中心为每个簇中所有对象的均值,K为类簇数目;代表每个属性的权值;表示数据点xn和第k个聚类中心点ck在第l个属性上的距离。
实际上,在近邻传播的聚类分析过程中,除了需要考虑每个簇中对象的聚合性外,还需要进一步考虑簇与簇之间的耦合性,即类内数据尽可能相似与类间数据尽可能相异。为此,式(5)可转化为:
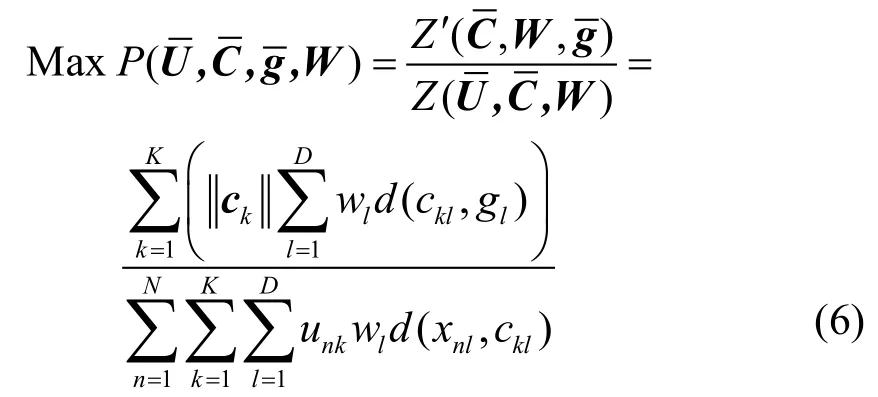
为了使P值尽可能的大,每次迭代后属性的权值应根据当前聚类结果进行调整,使得P值趋于递增。同时,如果某个属性对于聚类结果的贡献较大,那么应该增大其属性权值,使得P值变大。假设第t次迭代中的属性权值代表第t次迭代过程中第l个属性的权值。则在计算第t+1次迭代中第l个属性的权值时除了考虑第t次的权值外,还需要考虑根据当前聚类结果用以增大P值的属性权重的变化量,即:
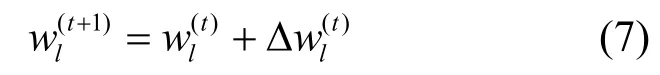
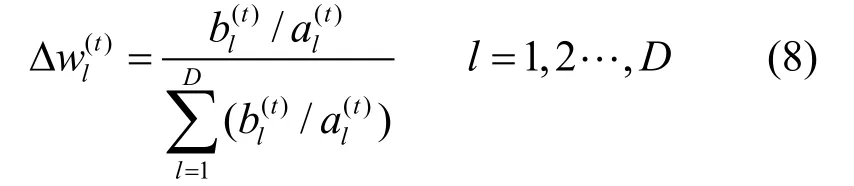
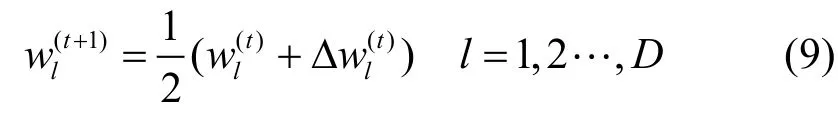
通过在迭代过程中计算每个属性对聚类结果做出的贡献从而更新属性权值,使P值逐步趋向最优,从而提升聚类质量。另外,通过初始化各属性权重,结合式(9)的权重变化和迭代过程,使得聚类过程中的权重值不需要人工干预,可以实现根据具体数据分布自适应地确定,增强了算法的稳定性和适用性。
2.2 加权近邻传播聚类算法
传统近邻传播聚类算法通过一次计算数据点之间的距离来获得相似性矩阵,并通过更新两种竞争信息来实现迭代过程中的聚类分析,聚类思想过程如图1所示。若聚类分析结果满足聚类要求或迭代次数达到终止条件,则可获得最终聚类结果,否则进一步迭代更新两种竞争信息,以便获得更好的聚类结果。然而,传统近邻传播聚类算法过程缺少考虑数据属性权重的影响,同时每次迭代过程获得的聚类结果缺少目标函数的评价。为了更好地提高近邻传播聚类算法的性能,本文提出一种基于属性权值的近邻传播聚类算法,该方法不仅考虑了属性权重的影响,还在聚类过程中通过目标函数评价功能自适应地更新属性权值,使其在迭代过程中逐步获得更好的聚类效果。
图2描述了本文AFW_AP算法的聚类思想过程。可以看出,AFW_AP算法在近邻传播的聚类过程中,根据当前迭代聚类结果的目标函数P值,将属性权值自适应地往增大P值的方向调整,并将属性权值调整反映到加权相似性矩阵S的计算中。从式(1)~式(3)易知,代表度矩阵R是根据相似性矩阵S计算得到的,有效性矩阵A是根据代表度矩阵R计算得出。因此,利用更新后的属性权值W获得加权相似性矩阵S,可以将属性权值的影响通过两种竞争信息在近邻传播聚类迭代过程中不断传播,实现更好的聚类效果。

图1 传统近邻传播聚类过程
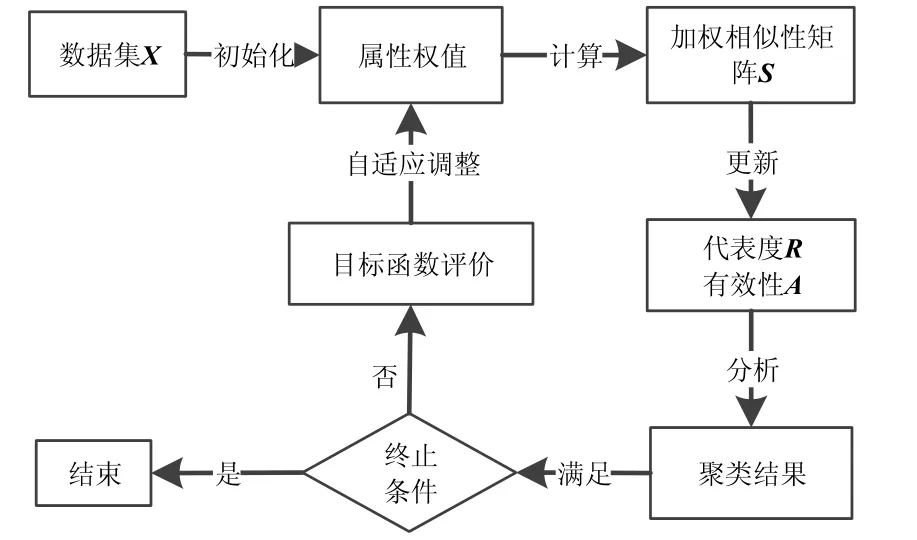
图2 AFW_AP算法聚类过程
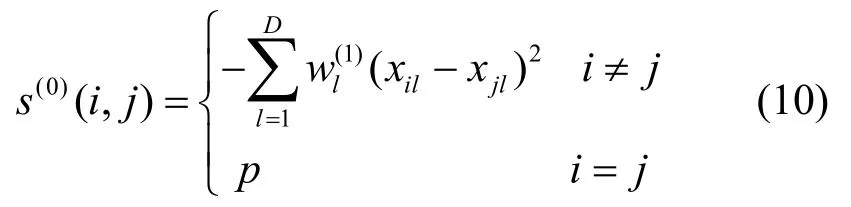
与传统近邻传播聚类相同,将偏向参数p设为相似性矩阵的中位数,即
利用式(1)~式(3)更新代表度矩阵R(1)和有效性矩阵A(1),利用式(4)根据代表度矩阵和有效性矩阵找出第一次迭代后的聚类代表点和每个代表点所代表对象。然后,分别利用式(9)和式(10)得到更新后属性权值和加权相似性矩阵需要注意的是,为了产生稳定的聚类结果,在每次迭代过程中加权相似性矩阵中的对角线元素的值不会随着迭代次数的变化而改变。将S(1)带入式(1)~式(3)中进行下一轮迭代,随着近邻传播产生的聚类结果不断更新属性权值和加权相似性矩阵,直到产生一个收敛的聚类结果或达到最大迭代次数为止。
AFW_AP聚类算法:Y=AFW_AP(X)
1)初始化阻尼因子λ=0.9和属性权值其中
2)根据式(10)计算加权相似性矩阵S(t),且
3)根据式(1)~式(3)计算代表度矩阵R和有效性矩阵A。
4)根据式(4)求出当前各个数据对象的代表点。
5)根据式(9)更新属性权值W(t+1)。
6)重复步骤2)~步骤5)直到产生收敛的聚类结果。
7)根据式(4)得到第i个数据对象所对应的代表
从上述算法过程易知,AFW_AP算法不要求输入过多的参数,可以大大地提高传统近邻传播聚类算法的易用性和结果的稳定性,无需更多的先验知识即可产生较好的聚类结果。与传统近邻传播算法相比,AFW_AP算法在迭代过程中增加了一个根据当前聚类结果调整权值并更新相似性矩阵的步骤,该步骤根据属性的贡献水平调整属性权值使属性权值逐步达到最优。与近邻传播相同,AFW_AP算法产生的类簇数目随着偏向参数的取值不同而改变,并且算法迭代次数受到阻尼因子的影响(一般情况下λ为0.9)。
新算法在聚类过程中通过属性权值的更新改变相似性度量矩阵的值,会影响近邻传播的计算结果。随着迭代次数的增加,属性权值逐渐达到稳定,在聚类后期,由于属性权值不再改变,相似性度量矩阵能够达到稳定状态使得新算法能够随着近邻传播聚类的收敛而收敛。
本文提出的算法时间复杂度较高,加入权值更新后时间复杂度在近邻传播聚类的基础上增加其中D为数据集中的属性个数,k为当前聚类结果中的类簇数目,n为数据集中的样本个数,但是加入调整的属性权值对算法结果的精度能够有一定的提高。因此在面对大数据量的数据集时,可以在小样本、抽样或训练集数据上执行所提出的算法,获得更新的属性权值后,直接将该值代入相似性矩阵的计算,并将属性加权的相似性矩阵作为近邻传播聚类的输入参数,从而提升近邻传播聚类的聚类效果。在计算过程中为了提高AFW_AP聚类的计算速度,增强算法的稳定性,可将属性的权值和相似性矩阵的更新频率设为一个固定的值。
3 实验与结果分析
本文使用UCI与文本数据集结合常用的聚类评价指标(F-Measure、Folkes_Mallows和corrected rand index)进行算法聚类质量的评价。同时,分别从目标函数P值、属性权值变化、聚类结果和迭代收敛性分析来检验新方法的性能。另外,由于基于近邻传播的聚类所产生的类簇数目受到偏向参数的影响,因此实验中将所有基于近邻传播的聚类方法中的偏向参数设为相似性矩阵的中位数,并根据AP算法所产生的类簇数目限定K-Means等传统限定类簇数目聚类算法的聚类参数。
3.1 聚类评价指标
由于实验所用的UCI数据集其分类簇的结果是已知的,可以使用外部度量的聚类指标对新方法的聚类结果进行有效性评价。实验中使用3种不同的外部度量指标对聚类结果进行评价,以便更好地比较说明方法的有效性。
1)F-Measure
F-Measure[21]指标是常用的聚类质量测评指标之一,它同时考虑了准确率(precision)和召回率(recall)两个指标,能够得到综合的评价结果:
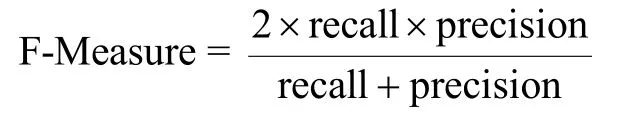
2)Folkes_Mallows
Folkes_Mallows(FM)[22]指标是一个落在[0,1]之间的聚类评价指标,FM越大,表明聚类的正确率越高。当聚类结果中的类簇数目与正确的类簇数目不相同时,FM评价指标能够得出更客观的评价结果:
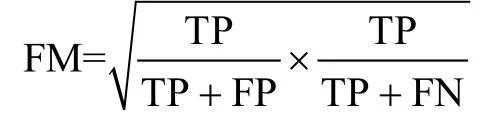
式中,TP表示同一类的数据对象被分到同一个簇;TN表示不同类的数据对象被分到不同簇;FP表示不同类的数据对象被分到同一个簇;FN表示同一类的数据对象被分到不同簇。
3)Corrected Rand Index
Corrected rand index(CRI)[23]是常用的半监督聚类评价指标,它在rand index的基础上进行了改进:
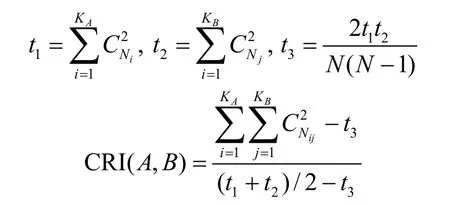
式中,A和B是数据集的两个分类,分类A中有KA个类簇,分类B中有KB个类簇;Nij代表在A中属于第i个簇同时也在B中属于第j个簇中数据对象的数量;Ni和Nj分别表示A中第i个簇与B中第j个簇中数据对象的数量;符号C代表组合数的计算。
3.2 目标函数P值
属性权值在近邻传播的聚类过程中,根据当前聚类结果,以增大目标函数P值为目的不断更新。在本次实验中,通过计算每次属性权值更新后的P值验证属性权值对P值的影响,实验结果如图3和图4所示(实验数据集的具体信息见3.4节)。
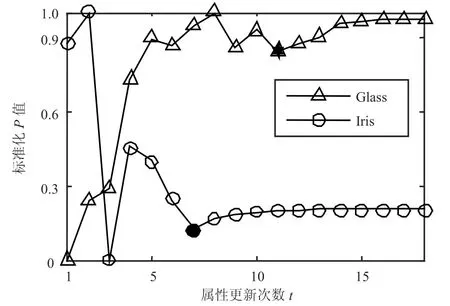
图3 Iris和Glass数据集的P值变化过程
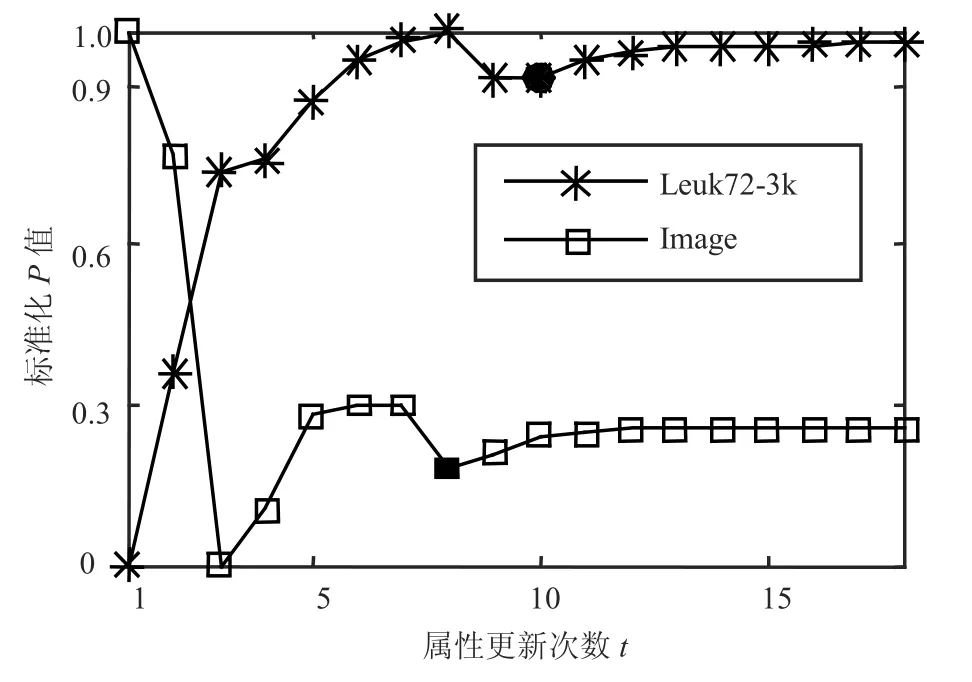
图4 Leuk和Image数据集的P值变化过程
由于近邻传播聚类将所有数据对象视为潜在的代表点,在聚类初始阶段,近邻传播聚类往往倾向于生成类簇较多的聚类结果(极端情况为每个数据对象自成一类),然后在迭代中逐步将类簇数目调整为合适的值。因此,目标函数P值在聚类初始阶段并不是一个稳定上升的过程。若类簇数目较多,初始阶段的P值很可能为一个较大数值(即Iris与Image数据集曲线所示情况,初始曲线变化呈现一个快速下降的趋势),随着类簇数目的不断调整,P将达到稳定点,即在该点以后聚类结果中的类簇数目为一个稳定的值。因此,P到达稳定点以后,类簇数目不再变动,属性权值对目标函数P值具有稳定的影响。
从图3和图4中可以看出,目标函数P值由于类簇数目的逐步稳定,在初期的波动结束后达到某个稳定点(即图中的实心点)。稳定之后的P值会随着属性权值的不断调整,呈现一个逐渐增大并稳定的过程,即目标函数能够通过属性权值的调整逐步接近最优。上述过程验证了属性权值的调整对P值能够产生积极影响,使目标函数逐步接近最优。
3.3 属性权值分析
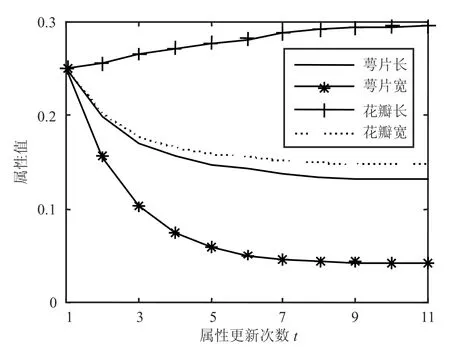
图5 Iris数据集上的属性权值变化

图6 Pima数据集上的属性权值变化
经过AFW_AP算法在聚类过程中对属性权值的调整,数据集中的某个对聚类结果贡献较大的属性会在调整中不断增大,而剩余属性值则随着更新次数逐渐减小。实验过程中属性权值的变化如图5和图6所示。
从图5中可以看到Iris数据集中的表示花瓣长的属性随着属性权值在迭代中的调整,在聚类过程中所占的比重逐渐增大,而其余的属性权重则不断减小。这说明在对Iris进行分类时,花瓣的长度对分类所起到的作用远大于其余属性对分类结果的影响,并且增大花瓣长度的属性权值可以提高聚类结果的质量。
从图6中可以得出,在Pima数据集上属性五相较其余属性对聚类质量的改进作用更大,它在更新的过程中不断上升至0.4,而剩余的5个属性的权值则不断降低最终稳定在一个相似的值上。因此,从实验结果来看,属性权值随着更新次数变化到一定阶段时,会达到一个稳定值,促使新聚类算法产生稳定的聚类结果。
3.4 聚类实验
为了进一步验证AFW_AP算法的聚类结果,使用UCI数据集对算法进行聚类分析。实验中使用11个UCI数据集和一个文本数据集进行算法验证,数据集的具体信息如表1所示,其中Text数据集为中文文本数据集,数据集来源为搜狗实验室。
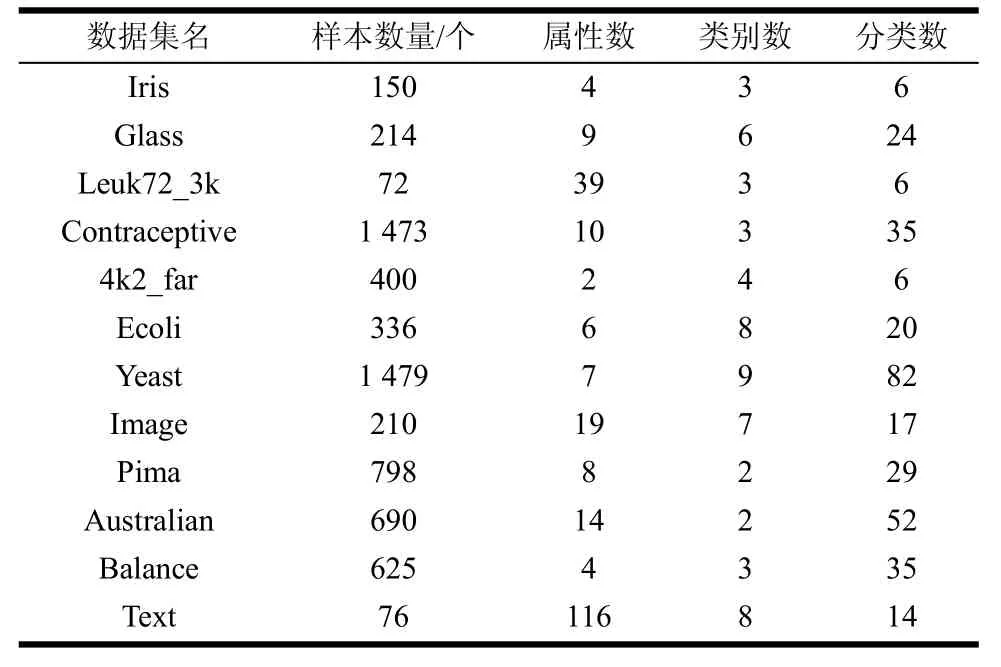
表1 实验数据集信息
表1中的分类数为将偏向参数设为相似性矩阵的中位数时AP算法对数据集的聚类结果中含有的类簇数目。可以看出当数据集中样本较多时,聚类结果中含有的类簇数目远大于样本中的类别数。该现象同样出现在AFW_AP算法与SAP算法的聚类结果中。在实际应用中可根据需要,对近邻传播的偏向参数进行调整,使得聚类结果中的分类数目达到理想。
本次实验所使用的对比算法有AP、子空间近邻传播聚类算法(SAP)[16]、加权K-Means算法(WK-means)、clara算法[24]、谱聚类算法(spectal)和增量AP聚类算法(IAPKMA)[25],并结合3种评价指标进行聚类结果分析。为了提升算法的稳定性与计算速度,实验中将AFW_AP算法中的权值更新频率设为每十次迭代更新一次。在实际应用中也可根据需要设定更新频率,这里综合考虑算法效率与属性权值的更新准确性将属性权值的更新频率设为10。特别地,由于Iris数据集较小,将Iris数据集中的权值更新频率设为每次迭代更新,以充分体现权值更新对聚类的影响。聚类实验结果如表2,表3和表4所示。
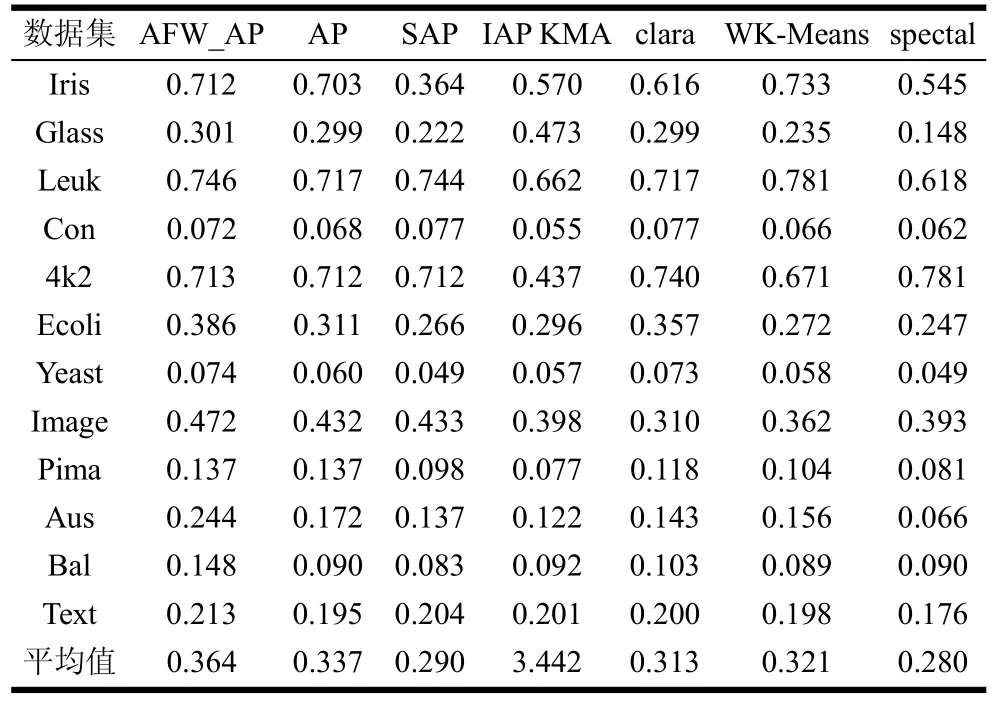
表2 7种方法聚类结果的F-Measure指标值
从表2中可以看出加权K-Means算法在12个数据集中的2个数据集上能获得优势的聚类结果,而SAP, IAPKM和谱聚类算法分别在其中1个数据集中有突出表现,AFW_AP算法则在剩余的数据集上的聚类效果占优势。最后,从算法均值上看AFW_AP在F-Measure指标上的表现优于对比算法。
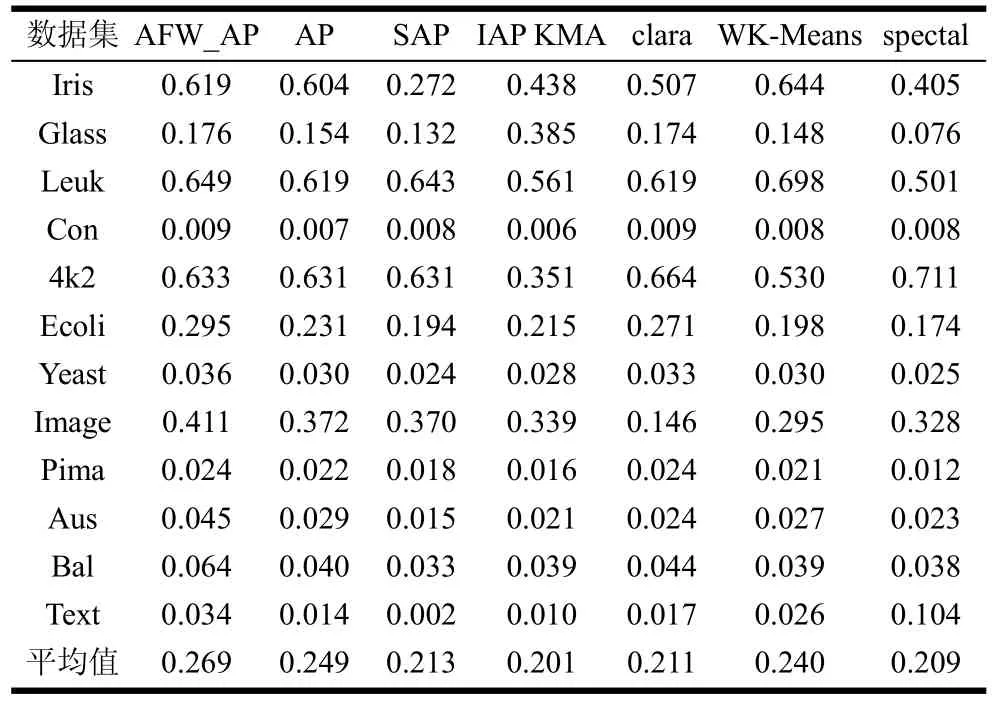
表3 7种方法聚类结果的CRI指标值
从表3中可以看出,在所使用的12个数据集中,AFW_AP算法在其中8个数据集上能获得优势聚类结果,而加权的K-Means聚类算法则能在其中两个数据集中领先对比算法。最后,从均值上看AFW_AP算法能够取得较高质量的结果。
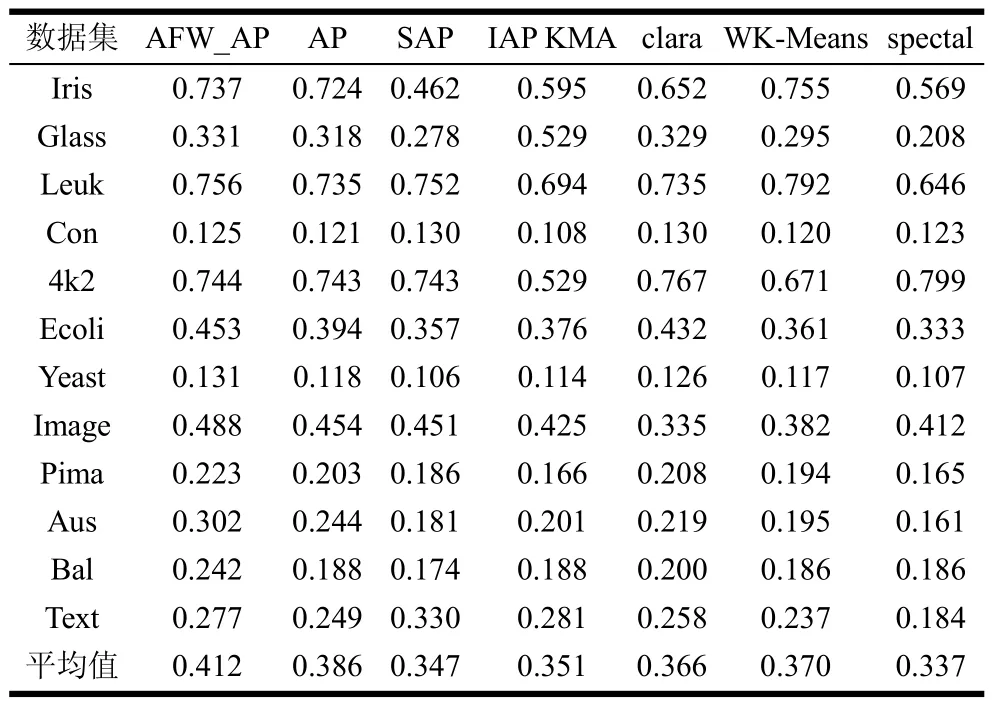
表4 7种方法聚类结果的Folkes_M指标值
从表4中可以看出,与CRI指标不同,在FM指标上SAP算法在Contraceptive数据集与文本数据集数据集上的聚类结果要优于AFW_AP算法,但AFW_AP算法在多数数据集与均值上的聚类表现仍较对比算法占优势。综合表2~表4的聚类结果,与近邻传播聚类和传统聚类算法相比,AFW_AP算法在3个聚类有效性评价指标上均有较明显的提升,说明AFW_AP算法通过自适应权值的更新和使用对近邻传播聚类方法能够起到积极的效果。
3.5 迭代收敛性比较
AFW_AP算法较于传统AP算法在大部分数据集中能够使用更少的迭代收敛次数取得较好的聚类结果,迭代收敛次数结果比较如图7所示。图中曲线值表示AFW_AP算法所用迭代次数与AP算法所用迭代次数的相对值(在多数数据集的计算中近邻传播聚类所用的收敛迭代次数落入[150, 250]区间内)。容易看出,AFW_AP算法通过对属性权值进行调整,在12个实验数据集中的7个数据集上比AP算法使用更少的迭代收敛次数(除AFW_AP算法在Ecoli和Yeast上未能取得收敛的聚类)。为了进一步对比两个算法的迭代收敛性,将AP算法与AFW_AP算法在Glass数据集上的收敛曲线进行比较,实验结果如图8所示。图中纵坐标的值为聚类过程中类簇中的点与类簇代表点的距离之和。聚类净相似度随着算法的收敛会逐渐减小并达到稳定值。
从图8与图9可以看出AFW_AP聚类在最初的几次迭代中由于属性权值的调整收敛曲线产生一次大幅震荡,随后AFW_AP聚类逐步趋向收敛,并且在更短的迭代周期内完成聚类收敛。而AP聚类的收敛曲线不产生大幅震荡,而是在小幅的调整中逐步达到收敛,这也使得AP聚类的收敛需要较多的迭代周期。
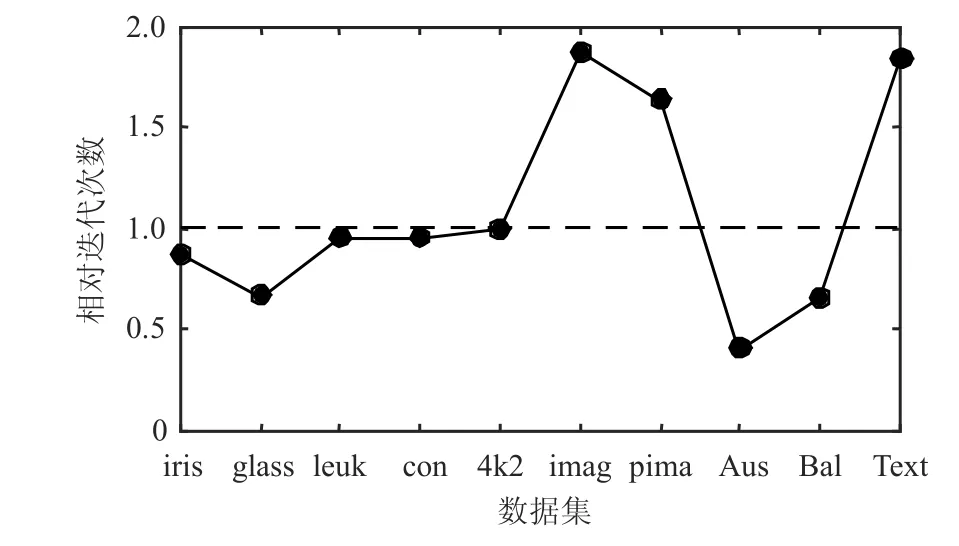
图7 AFW_AP和AP算法的迭代收敛次数对比
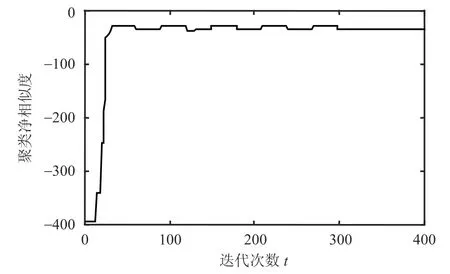
图8 AP算法在Glass数据集上的收敛曲线
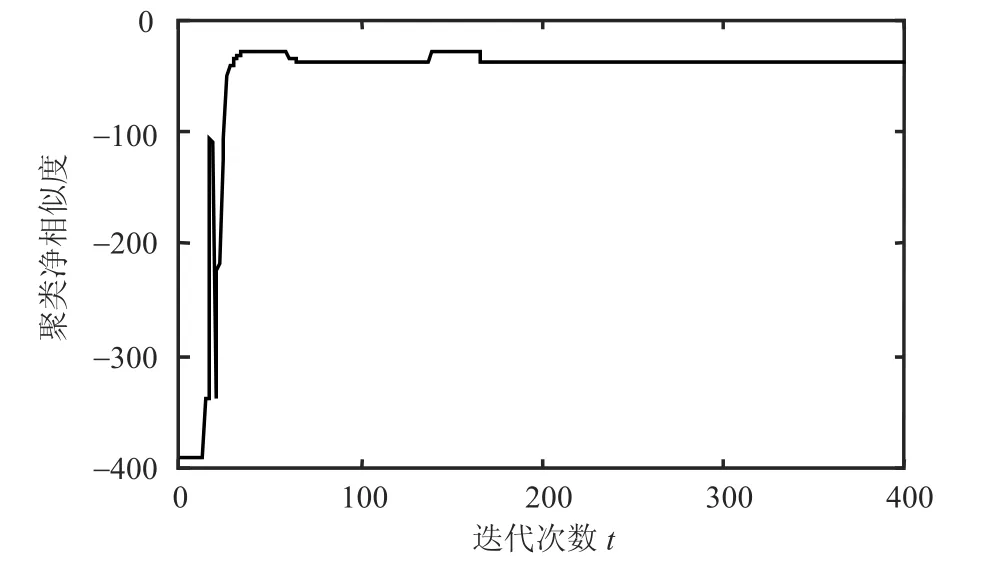
图9 AFW-AP算法在Glass数据集上的收敛曲线
4 结束语
本文对属性权值在近邻传播聚类过程中的影响进行了研究,提出一种基于自适应属性权值的近邻传播聚类算法AFW_AP。该方法在近邻传播算法中根据每次迭代聚类结果的目标评价函数来自适应更新属性权值,使得当前数据划分的结果可以计算各个属性对聚类的贡献程度,从而调整属性权值与相似性矩阵,逐步使聚类结果接近最优进而提升整体近邻传播的聚类质量。同时,AFW_AP算法不需要额外的参数设定,增强了聚类算法的适用性,且属性权值在后期迭代过程的稳定性促使近邻算法可以获得稳定的聚类效果。数值实验结果表明,属性权值的更新过程在新算法中能够起到积极作用,与传统聚类算法相比,AFW_AP算法能够获得好的聚类准确率。然而,虽然AFW_AP聚类产生收敛的聚类结果所使用的迭代次数较AP聚类少,但是迭代过程中新增权值和相似性矩阵的计算等步骤使得AFW_AP聚类需要额外的时间开销,这也是将来应需要进一步探讨和研究问题。
[1]JAIN A K, DUBES R C.Algorithms for clustering data[M].New Jersey: Prentice-Hall, 1988.
[2]DU Ke-lin, SWAMY M N S.Neural networks and statistical learning[M].Berlin: Springer, 2014.
[3]MCLACHLAN G,KRISHNAN T.The EM algorithm and extensions[M].New York: Wiley, 2008.
[4]张衡, 谭晓阳, 金鑫, 等.基于多视图聚类的自然图像边缘检测[J].模式识别与人工智能, 2016(2): 163-170.ZHANG Heng, TAN Xiao-yang, JIN Xin, et al.Multi-view clustering based natural image contour detection[J].Pattern Recognition and Artificial Intelligence, 2016(2): 163-170.
[5]朱张祥, 刘咏梅.在线社交网络谣言传播的仿真研究-基于聚类系数可变的无标度网络环境[J].复杂系统与复杂性科学, 2016, 13(2): 74-82.ZHU Zhang-xiang, LIU Yong-mei.Simulation study of propagation of rumor in online social network based on scale-free network with tunable clustering[J].Complex Systems and Complexity Science, 2016, 13(2): 74-82.
[6]王光沛, 潘景昌, 衣振萍, 等.基于线指数特征的海量恒星光谱聚类分析研究[J].光谱学与光谱分析, 2016, 36(8):2646-2650.WANG Guang-pei, PAN Jing-chang, YI Zhen-ping.Research on the clustering of massive stellar spectra based on line index[J].Spectroscopy and Spectral Analysis, 2016,36(8): 2646-2650.
[7]徐毅非, 蒋文波, 程雪丽, 等.基于谱聚类的无功电压分区和主导节点选择[J].电力系统保护与控制, 2016,44(15): 73-78.XU Yi-fei, JIANG Wen-bo, CHENG Xue-li.Partitioning for reactive voltage based on spectral clustering and pilot nodes selection[J].Power System Protection and Control, 2016,44(15): 73-78.
[8]王宇超, 周亚福, 王得祥, 等.秦岭南坡中段主要森林群落类型划分及环境梯度解释[J].生态环境学报, 2016,25(6): 965-972.WANG Yu-chao, ZHOU Ya-fu, WANG De-xiang.The quantitative classification and environmental interpretation of forest communities in the middle area of south slope of Qinling mountains[J].Ecology and Environment Sciences,2016, 25(6): 965-972.
[9]FREY B J, DUECK D.Clustering by passing messages between data points[J].Science, 2007, 315(5814): 972-976.
[10]董俊, 王锁萍, 熊范纶.可变相似性度量的近邻传播聚类[J].电子与信息学报, 2010(3): 509-514.DONG Jun, WANG Suo-ping, XIONG Fan-lun.Affinity propagation clustering based on variable-similarity measure[J].Journal Of Electronics & Information Technology, 2010(3): 509-514.
[11]SHANG Ron-ghua, LUO Shuang, ZHANG Wei-tong, et al.A multiobjective evolutionary algorithm to find community structures based on affinity propagation[J].Physica A:Statistical Mechanics and its Applications, 2016(453):203-227.
[12]YU Jian.General C-means clustering model[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2005, 27(8): 1197-1211.
[13]HUAN Liu, YU Lei.Toward integrating feature selection algorithms for classification and clustering[J].IEEE Transactions on Knowledge and Data Engineering, 2005,17: 491-502.
[14]刘铭, 吴冲, 刘远超, 等.基于特征权重量化的相似度计算方法[J].计算机学报, 2015(7): 1420-1433.LIU Ming, WU Chong, LIU Yuan-Chao, et al.Similarity calculation based on feature weight evaluation[J].Chinese Journal of Computers, 2015(7): 1420-1433.
[15]de AMORIM R C, MIRKIN B.Minkowski metric, feature weighting and anomalous cluster initializing in K-Means clustering[J].Pattern Recognition, 2012, 45(3): 1061-1075.
[16]GAN G J, NG M K.Subspace clustering using affinity propagation[J].Pattern Recognition, 2015, 48: 1455-1464.
[17]HUANG J, NG M, RONG H, et al.Automated variable weighting in k-means type clustering[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27:657-668.
[18]TSAI C Y, CHIU C C.Developing a feature weight self-adjustment mechanism for a K-means clustering algorithm[J].Computational Statistics & Data Analysis 2008, 52(10): 4658-4672.
[19]周世兵, 徐振源, 唐旭清.一种基于近邻传播算法的最佳聚类数确定方法[J].控制与决策, 2011, 8: 1147-1152.ZHOU Shi-bin, XUN Zhen-yuan, TANG Xu-qing.Method for determining optimal number of cluster based on affinity propagation clustering[J].Control and Decision, 2011, 8:1147-1152.
[20]GUI Bin, YANG Xiao-ping.Advanced technologies,embedded and multimedia for human-centric computing[M].Berlin: Springer Netherlands, 2013: 637-644.
[21]POWERS D.Evaluation: from precision, recall and F-measure to ROC, informedness, markedness and correlation[J].Journal of Machine Learning Technologies,2011, 2(1): 37-63.
[22]FOWLKES E B, MALLOWS C L.A method for compareng two hierarchical clusterings[J].Journal of the American Statistical Association, 1983, 78(383): 553-569.
[23]WARRENS M J.On the equivalence of Cohen’s Kappa and the Hubert-Arabie adjusted rand index[J].Journal of Classification, 2008, 25(2): 177-183.
[24]KAUFMAN L, ROUSSEEUW P J. Clustering large applications (program clara)finding groups in data: an introduction to cluster analysis[M].New York: John Wiley& Sons Inc, 2008.
[25]GUO C.Incremental affinity propagation clustering based on message passing[J].IEEE Transactions on Knowledge& Data Engineering, 2014, 26(11): 2731-2744.
