用户和相似性填充相融合的协同推荐模型
2018-03-16武俊芳
武俊芳,吴 婷
(1.郑州工商学院 机械与电信工程学院,河南 郑州 451400;2.中原工学院 计算机学院,河南 郑州 450000)
0 引 言
当前有大量优秀的协同过滤推荐模型[1-3],并且在实际应用中取得了不错的推荐效果[4],然而协同过滤推荐模型存在许多缺陷,最常见的为:在数据稀疏情况下,推荐质量急剧下降[5]。目前主要通过降维技术解决数据稀疏难,如有学者提出了基于概率矩阵分解的降维技术[6];有学者提了采用主成分分析、因子分析的降维技术[7,8],这些降维技术可以在保留原始数据信息的基础上,有效实现数据维数,推荐效果得到了明显的改善,但在降维同时,会损失一定数量的重要信息[9]。随后有学者提出了奇异值分解和k近邻的协同过滤相融合的推荐模型,采用奇异值对原始评分矩阵进行分解,然后采用近似评分矩阵估计用户相似度,最后采用k近邻算法进行推荐预测,一定程度上缓解了数据稀疏性问题,但其仍然无法全面挖掘用户特征信息[10]。
针对当前协同过滤推荐模型存在的精度低、冷启动等难题,设计了用户和相似性填充相融合的协同过滤推荐模型,采用标准数据集Movielens和Book-Crossing数据集对模型性能进行测试,结果表明,该模型提高了协同过滤推荐的预测精度,而且预测性能要明显好于对比模型,解决对比模型存在的缺陷,获得了理想的协同过滤推荐效果。
1 相关理论
1.1 经典协同过滤推荐模型
协同过滤模型已经引起了学者们的高度关注,其中基于用户的协同过滤应用最为广泛[11]。兴趣度是协同过滤推荐模型中的一个重要指标,主要描述用户与项目之间的联系,常采用户-评分矩阵进行刻画。设共有n个用户、m个项目,那么用户-项目评分矩阵的计算公式为
(1)
式中:ru,j——用户u对项目j的评分。
基于用户的协同过滤推荐步骤为:
步骤1 利用评分矩阵估计用户u,v的相似度Sim(u,v),其中u,v∈U,U表示用户集合,当前用户相似度估计算法很多,针对不同应用领域,选择不同的估计算法,其中基于皮尔逊相关系数的用户相似度估计算法最为常用,具体为
(2)
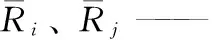
步骤2 采用k邻近算法选择邻居集合。设用户u0的邻居集合为Uu0,若预测ru0,j,首先搜索评价过项目j的用户集合Uj,并计算u0与Uj元素间的相似度,然后根据相似度的值进行降序排列,选择前k个元素组成居集合Uu0。
步骤3 根据式(3)实现u0对项目j的评分预测
(3)
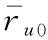
1.2 概率矩阵分解技术
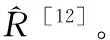
(4)
式中:σ——观测噪声的方差。
U和V的概率密度函数分别为
(5)
式中:σU,σV——先验噪声的方差。
根据式(4)和式(5)得到贝叶斯后验概率为
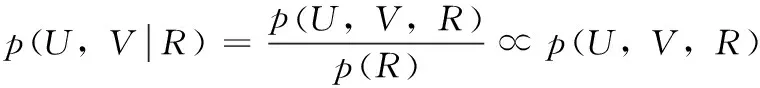
(6)
对式(6)进行对数变换得到
(7)
式中:C——一个常数。
最大化U和V的后验概率为
(8)
式中:λU、λV——正则化参数。
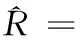
2 用户和相似性填充的协同推荐模型
2.1 部分填充算法
对于数据稀疏性问题,通常采用数据填充算法实现数据补充,提高用户相似性计算精度,当前填充算法很多,如项目评分均值、用户评分均值等,但它们破坏原始数据的分布和特征,有时反而降低了用户相似性计算精度,为此采用一种新的填充算法,即部分填充算法,具体如下:
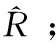
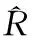
(3)根据R得到用户a和b的评分项目集合Va和Vb;
(4)计算Va、Vb的项目并集Va∪b和交集Va∩b,根据Va∪b和Va∩b,得到a和b没有评价过的项目集合Va⊕b,即有
Va⊕b=Va∪b-Va∩b
(9)
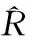
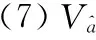
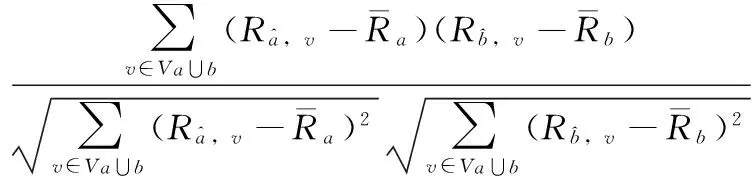
(10)
2.2 用户信任因子
采用部分填充算法虽然可以解决数据稀疏性问题,但得到的相似性度值无法准确描述用户间的实际关系,因此对评分进行预测时,需求考虑其它因素,称它们为用户信任因子,具体为:
(1)对原始和填充后的皮尔逊相似度进行加权,得到最后的用户相似度为
Sim_adj=w1×Simfill_pearson+w2×Simpearson
(11)
式中:w1和w2表示权值,且有w1+w2=1。
(12)
(3)综合上述,相似度的最终计算式为
Simtr=w1Simfill_pearson+w2Simpearson+w3Nu
(13)
2.3 用户和相似性填充的协同推荐步骤
(1)构建用户-项目评分矩阵。
(2)采用概率矩阵分解技术对评分矩阵进行分解。
(3)根据分解结果进行逆操作得到近似评分矩阵。
(4)采用近似矩阵对对缺失评价的项目进行填充,得到用户相似度。
(5)用信任度因子对填充误差进行适当调整,得到最终的用户间相似度。
(6)通过k-近邻算法构建用户邻居集,并对用户评分进行预测,得到预测结果。
(7)根据预测结果实现用户协同推荐。
3 仿真测试
3.1 数据以及评价指标
为了测试用户和相似性填充相融合的协同推荐模型(User-SF)的有效性,在Matlab 2014平台进行仿真实验,采用当前协同推荐测试的标准数据集——Movielens作为研究对象,该数据集共包含943个用户对1682个项目的评价,数据采集时间为:1997.9.19~1998.5.22,用户评分集为1~5级。该数据集的稀疏等级为93.7%,其中训练集和测试集所占比例分别为80%和20%。
当前协同推荐结果的评价很多,选择平均绝对误差MAE(mean absolute error)作为协同推荐结果的评价标准[13]。设测试集的期望评分为{p1,p2,p3,…,pn},评分的预测结果为{q1,q2,q3,…,qn},那么MAE的计算公式为
(14)
为了测试User-SF的优越性,选择当前几种经典模型进行对比测试,它们分别为:①基于Pearson的协同过滤模型(Pearson)、②评分均值的矩阵填充的协同过滤模型(Mean-CF)。
3.2 结果与分析
采用基User-SF、Pearson和Mean-CF对测试集进行预测,并统计预测结果,不同邻居数目条件下,它们的MAE变化曲线如图1所示。对图1的实验结果进行分析可以发现,随着邻居数量的增加,用户推荐结果的MAE值不断下降,当邻居数量达到一定程度时,用户推荐结果的MAE值变化比较平稳,而在相同邻居数量的条件下,User-SF的MAE值最小,这表明User-SF的用户推荐结果更优,有效提高了用户的推荐精度,这主要是由于User-SF采用矩阵填充用户项目评分集合得到用户间相似度,并引入信任度因子对填充误差进行适当调整,克服了对比模型存在的局限性,实验结果验证了User-SF的优越性。
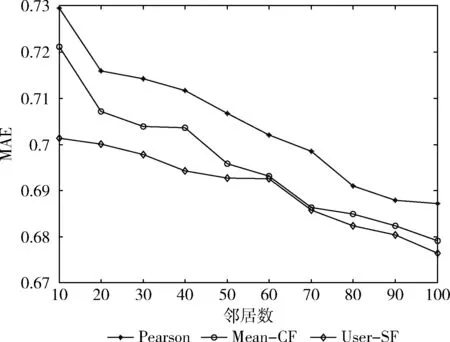
图1 不同邻居数目的MAE比较
从Movielens数据集随机选择100个用户,将它们评分信息全部清除掉,统计该情况的MAE值,实验结果如图2所示。对图2的实验结果进行对比和分析可以看出,相对于对比模型,User-SF解决了用户推荐过程中的冷启动难题,有效减少了用户推荐误差,有效改善了用户推荐效果,验证了User-SF具有良好的鲁棒性。
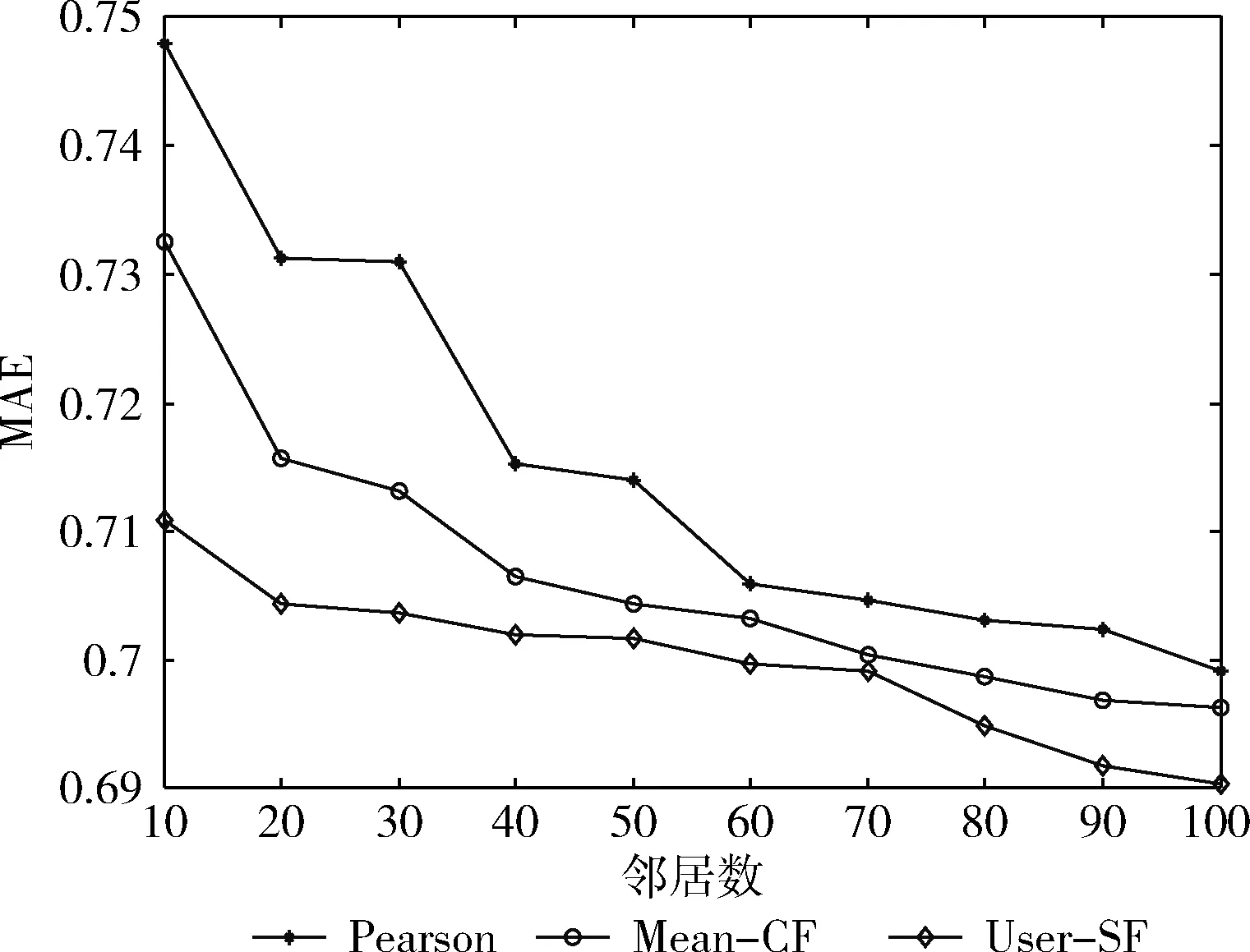
图2 冷启动条件下的MAE比较
随机选择部分数据,并对它们进行稀疏度处理,模拟数据的稀疏特性,并统计它们的MAE值,结果如图3所示。从图3的实验结果可以发现,数据的稀疏特性越严重,那么MAE值就越大,在相同数据的稀疏特性条件下,User-SF的MAE值相对更小,较好解决了数据的稀疏特性难题,提高了用户推荐精度。
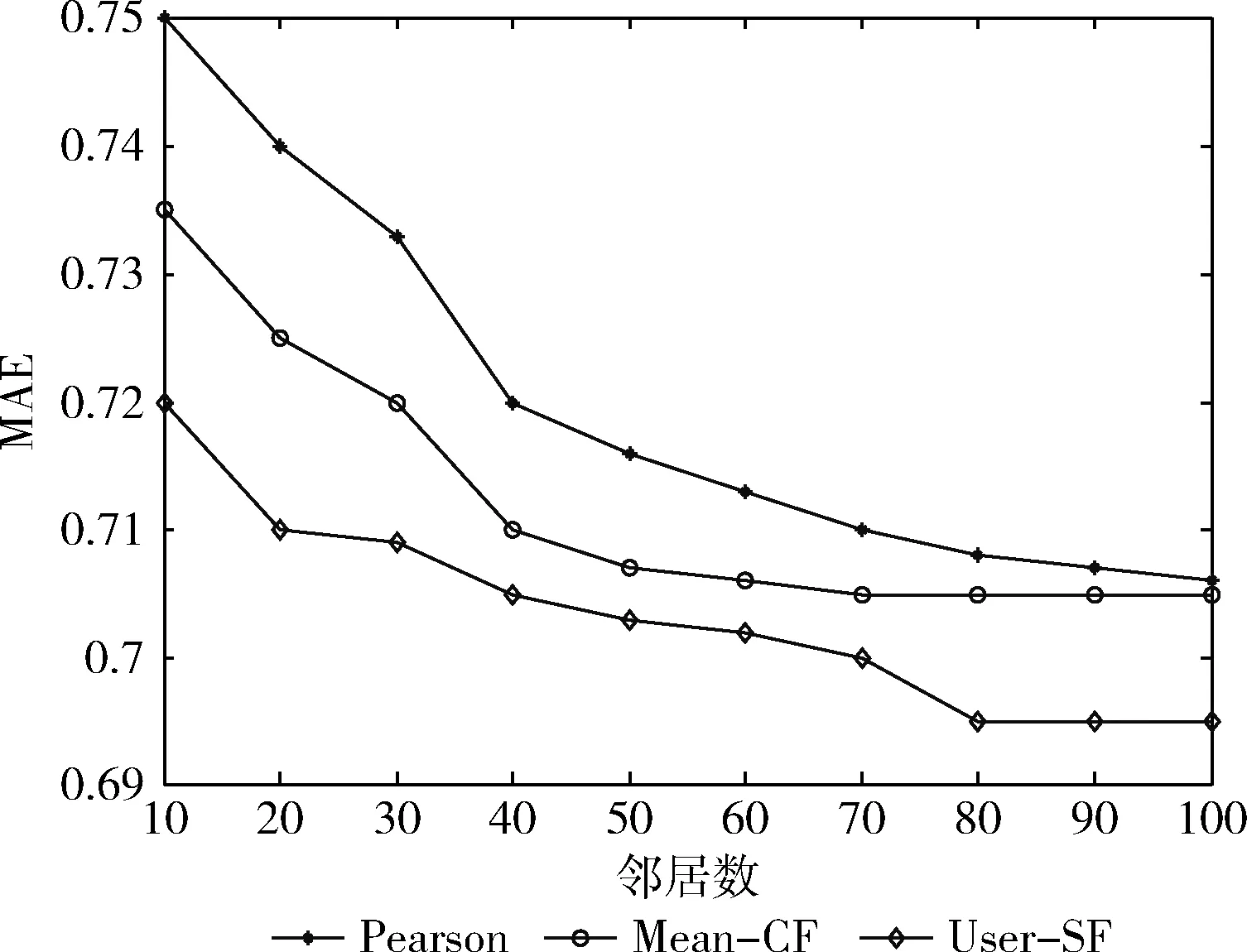
图3 稀疏度条件下的MAE比较
为了分析协同推荐模型的通用性,选择另一个标准数据集—Book-Crossing作为实验对象,该数据MAE模型的包含了278 858个用户的评分信息,不同模型的MAE值统计结果如图4所示。对图4的MAE值进行对比可以知道,相对于对比模型,User-SF的MAE值更小,获得更高的用户推荐精度,实验结果验证User-SF具有更优的通用性,适用范围更加广泛。
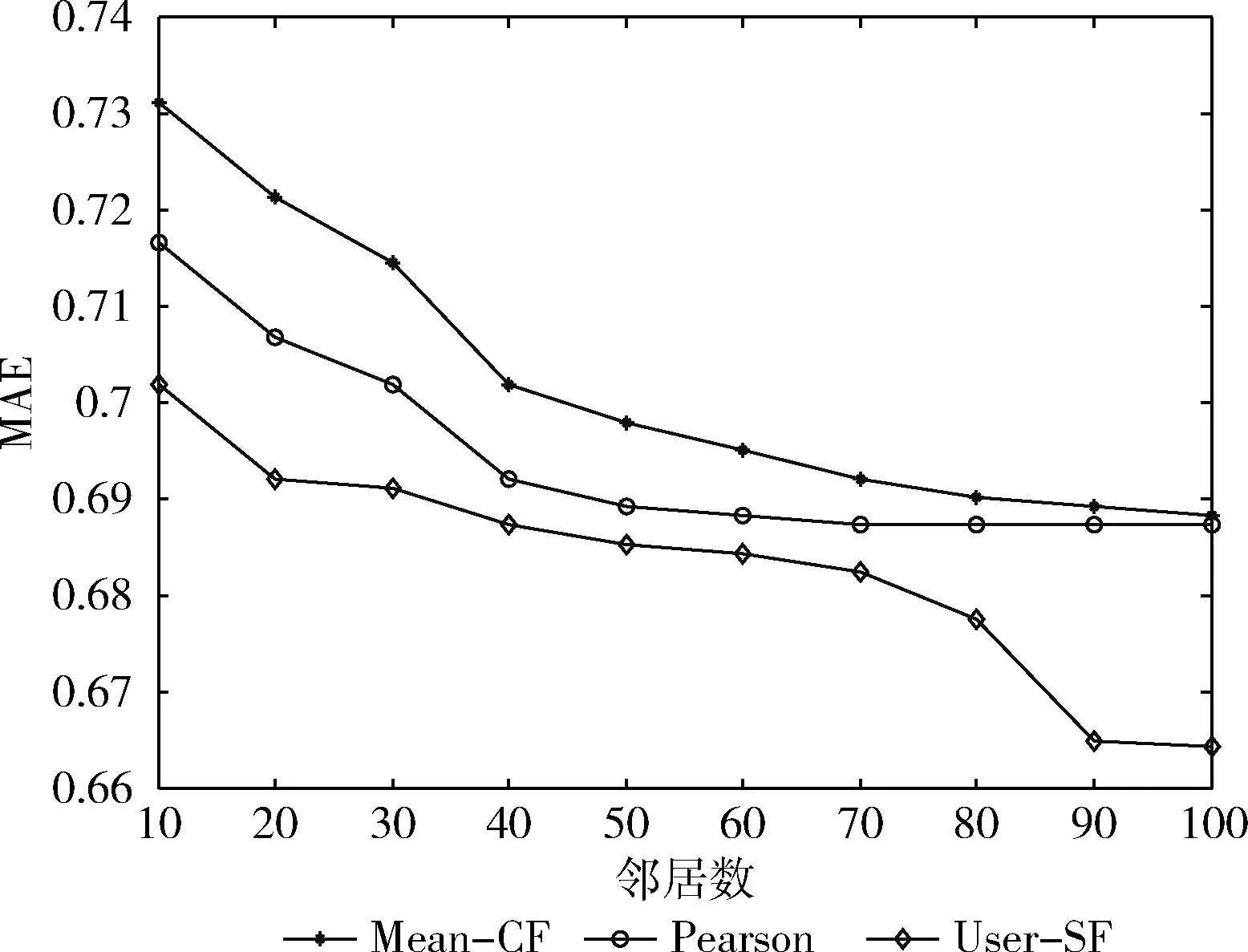
图4 不同模型的Book-Crossing的MAE比较
4 结束语
在分析当前用户协同推荐模型的局限性基础上,提出了基于用户和相似性填充相融合的协同过滤推荐模型。首先引入部分填充算法避免出现用户数据和信息的过度填充现象,解决均值和全部填充存在的不足以及数据稀疏特性难题,然后引入信任因子和相似性度权重调整方法得到更为准确的用户间相似度,采用标准数据集Movielens和Book-Crossing进行了仿真测试。结果表明,该模型提高了用户协同推荐的精度,获得了更加理想的用户协同推荐结果,具有更高的实际应用价值。
[1]KeunhoChoi,YongmooSuh.Anewsimilarityfunctionforselectingneighborsforeachtargetitemincollaborativefiltering[J].KnowledgeBasedSystems,2013,37(1):146-153.
[2]KrzywickiA,WobckeW,KimYS,etal.Collaborativefilteringforpeople-to-peoplerecommendationinonlinedating:Dataanalysisandusertrial[J].InternationalJournalofHumanComputerStudies,2015,76(12):50-66.
[3]SHIFengxian,CHENEnhong.Combiningtheitems’discri-minabilitiesonuserinterestsforcollaborativefiltering[J].JournalofChineseComputerSystems,2012,33(7):1533-1536(inChinese).[施风仙,陈恩红.结合项目区分用户兴趣度的协同过滤算法[J].小型微型计算机系统,2012,33(7):1533-1536.]
[4]YANGXingyao,YUJiong,TurgunIbrahim,etal.Collaborativefilteringrecommendationmodelbasedontrustmodelfilling[J].ComputerEngineering,2015,41(5):6-13(inChinese).[杨兴耀,于炯,吐尔根·依布拉音,等.基于信任模型填充的协同过滤推荐模型[J].计算机工程,2015,41(5):6-13.]
[5]ZOUBenyou,LICuiping,TANLiwen,etal.Socialrecommendationsbasedonusertrustandtensorfactorization[J].JournalofSoftware,2014,25(12):2852-2864(inChinese).[邹本友,李翠平,谭力文,等.基于用户信任和张量分解的社会网络推荐[J].软件学报,2014,25(12):2852-2864.]
[6]XIAOXiaoli,QIANYali,LIDanjiang,etal.Clusteringre-commendationalgorithmbasedonuserinterestandsocialtrust[J].JournalofComputerApplications,2016,36(5):1273-1278(inChinese).[肖晓丽,钱娅丽,李旦江,等.基于用户兴趣和社交信任的聚类推荐算法[J].计算机应用,2016,36(5):1273-1278.]
[7]RENKankan,QIANXuezhong.Researchonusersimilaritymeasuremethodincollaborativefilteringalgorithm[J].ComputerEngineering,2015,41(8):18-22(inChinese).[任看看,钱雪忠.协同过滤算法中的用户相似性度量方法研究[J].计算机工程,2015,41(8):18-22.]
[8]YINHang,CHANGGuiran,WANGXingwei.EffectofclusteringalgorithminK-nearestneighborhoodbasedcollaborativefiltering[J].JournalofChineseComputerSystems,2013,34(4):806-809(inChinese).[尹航,常桂然,工兴伟.采用聚类算法优化的K近邻协同过滤算法[J].小型微型计算机系统,2013,34(4):806-809.]
[9]RONGHuigui,HUOShengxu,HUChunhua,etal.Usersimilarity-basedcollaborativefilteringrecommendationalgorithm[J].JournalonCommunications,2014,35(2):16-24(inChinese).[荣辉桂,火生旭,胡春华,等.基于用户相似度的协同过滤推荐算法[J].通信学报,2014,35(2):16-24.]
[10]DINGShaoheng,JIDonghong,WANGLulu.Collaborativefilteringrecommendationalgorithmbasedonuserattributesandscores[J].ComputerEngineeringandDesign,2015,36(2):487-491(inChinese).[丁少衡,姬东鸿,王路路.基于用户属性和评分的协同过滤推荐算法[J].计算机工程与设计,2015,36(2):487-491.]
[11]WANGXingmao,ZHANGXingming,WUJiangxing.Collaborativefilteringrecommendationalgorithmbasedononejumptrustmodel[J].JournalonCommunications,2015,36(6):193-200(inChinese).[王兴茂,张兴明,邬江兴.基于一跳信任模型的协同过滤推荐算法[J].通信学报,2015,36(6):193-200.]
[12]ZHOULulu.Improvedrecommendationsystembasedonsocialtrustrelation[J].ComputerApplicationsandSoftware,2014,31(7):31-35(inChinese).[周璐璐.融合社会信任关系的改进推荐系统[J].计算机应用与软件,2014,31(7):31-35.]
[13]DENGXing,DENGZhenrong,XULiang,etal.Optimizedcollaborativefilteringrecommendationalgorithm[J].ComputerEngineeringandDesign,2016,37(5):1259-1264(inChinese).[邓星,邓珍荣,许亮,等.优化的协同过滤推荐算法[J].计算机工程与设计,2016,37(5):1259-1264.]
