基于属性向量协同过滤推荐算法并行化
2018-03-16温占考易秀双王兴伟
温占考,易秀双,刘 勇,李 婕,王兴伟
(东北大学 计算机科学与工程学院,辽宁 沈阳 110819)
0 引 言
协同过滤[1]推荐算法可大致分为基于评分预测和基于排序预测两类。基于评分预测的协同过滤是最为熟知的,原理是根据相似用户(物品)评分,预测目标用户(物品)评分,将评分排序后得到一个Top-N推荐列表。基于用户的协同过滤算法[2]利用用户对所有物品评分行为相似性来查找相似用户,而基于物品的协同过滤算法[3]利用所有用户对物品评分行为相似性来查找相似物品,但两者都是利用相似用户或者物品的历史评分来进行预测。
现存算法面临几个核心问题。①仅考虑用户对物品评分而忽略物品属性信息[2,3],不能准确表示用户的兴趣,使得准确率受到很大的限制;②物品数量众多,用户-物品评分矩阵稀疏程度太高及维度过高[4],用户之间共同评分的物品很少,对物品全排列的时间复杂度变高,不能准确找到相似用户,影响推荐准确率;③大数据背景下,难以及时响应用户请求。
Yi Cai等从全新的方向出发,提出基于典型性协同过滤算法,极大提升了预测准确率[5];李改等运用基于K近邻的属性—特征映射的算法得到新用户和新项目的特征向量来解决冷启动问题[6];文献[7]基于排序预测的推荐算法直接预测用户对物品的排序;CLiMF算法对二元相关数据进行建模并且优化了二元相关性的度量[8]; VSRank用向量空间模型来表示两个用户间的兴趣,且通过考虑每对用户兴趣的相对重要性对预测做出了进一步提升[9];ListCF用所有物品全排列概率分布直接预测,降低了基于排序预测算法计算复杂度[10]。
本文提出Hadoop环境下基于属性向量典型性的协同过滤推荐算法,综合考虑物品属性信息及用户对物品历史评分等多维度信息,计算用户间的相似度,依据相似用户的评分行为预测目标用户对物品排列概率,将算法在Hadoop环境下并行化来及时响应用户请求。
1 算法的数据处理
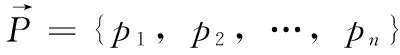
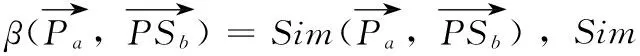
(1)
(2)
从上述典型性计算结果中,可得到物品j在物品类Sk中的典型性Wj,k。通过式(3),可得出用户i对物品类Sk的评分,其中n代表物品类Sk中物品的个数,由此可得到用户-物品类的评分矩阵
(3)
将物品属性信息等进行综合考虑来对物品进行聚类及评分更能体现用户兴趣,提高相似用户查找准确率。且将矩阵维度从物品数目的无限维降低到物品类的常数级别,极大减少查找相似用户的计算复杂度。
2 基于属性向量典型性推荐算法描述
主要描述算法相似用户查找和物品排序预测两部分。根据物品类全排列的概率分布查找相似用户;根据相似用户对目标用户未评分物品全排列概率分布,预测目标用户对未评分物品排序[12,13]。
2.1 相似用户查找
Plackett-Luce是用来描述排列概率分布的模型。对于某种排列,如果评分越高对应排序越靠前,相应的概率也就应该越大。用I来表示物品集合,物品所有全排列集合用ΩI(π1,π2,…,πi,…πn)来表示。对于一个排列πi(i1,i2,…ij…,in),ij表示排列第j个位置上是物品ij,与排列对应物品ij的评分为{ri1,ri2,……,rin},排列π的概率计算如式(4)所示,其中η(rik)表示物品ik被选择的概率,为递增的正函数,本文选取η(rik)=erik
(4)
用Kullback-Leibler(KL)散度实现用户之间的相似性度量,可描述两个概率分布差异。两个用户u和v之间的KL散度可由式(5)得到
(5)
(6)
2.2 物品排序预测
接下来是对目标用户u未评分的物品R(r1,r2,……,rs)进行预测排序,将排序靠前的k个物品推荐给用户u。
如果将s个物品进行全排列,计算复杂度是s!。Top-K概率模型只关注排列的前K个位置物品,可以将计算复杂度降到s!/(s-k)![12]。Top-K物品排列集合表示为G(g1,g2,……,gn),其中gj(i1,i2,……,ik)代表前K个位置是(i1,i2,…,ik)这些物品所有排列,Top-K排列概率用式(7)计算
(7)
相对熵损失函数可以调优概率分布间的距离[13],使u对R全排列的概率分布PRu与Nu对R的全排列概率分布PRNu尽可能接近,用式(8)构造出相应的优化函数,其中R’代表目标用户u未评分,但相似用户v评分的物品集合,PR’v代表是物品集合的概率分布,G’代表对R’的Top-K全排列
(8)
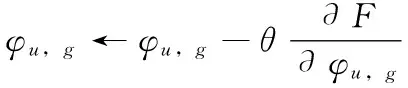
(9)
对每个相似用户v∈Nu,都可对物品集合R’中物品Top-K全排列G’的概率分布进行求解,可得到PRu。根据概率的大小对物品进行排序后进行推荐。
3 在Hadoop环境下并行化算法
随着数据量的爆炸式增长,为及时响应用户请求,本文将算法在Hadoop环境下进行并行化。算法并行化包含数据处理并行化、相似用户查找并行化、推荐并行化3部分。
数据处理并行化设计两个MapReduce任务:①物品属性向量典型性计算任务,Map()函数将物品归入到所属类中,Reduce()函数根据物品属性向量和类原型向量计算典型性,将结果保存在HDFS中;②矩阵计算任务,Map()函数读取用户对每个物品的评分,Reduce()函数根据Map()函数中间结果以及任务①中输出在HDFS中的数据,计算每个用户每个物品类的评分。数据流为图1。
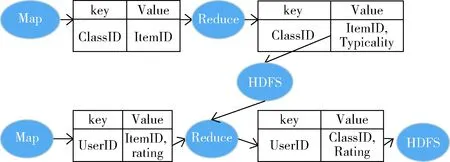
图1 数据处理并行化数据流
相似用户查找并行化设计两个MapReduce任务:①计算物品类的概率分布,Map()函数用于找出每个用户与目标用户共同评分过得物品类,Reduce()函数计算每个用户对物品类概率分布。②Map()函数利用任务①在HDFS中保存的中间结果计算目标用户与每个用户之间的相似性,Reduce()函数将相似度排序后,输出Top-K个相似用户到本地。数据流如图2所示。
推荐并行化设计两个MapReduce任务:①计算未评分物品概率分布,与相似用户查找中第一个MapReduce相似;②根据目标函数迭代求取目标用户对未评分物品的概率分布,Map()函数是进行一次迭代,Reduce()函数则用于判断是否达到迭代结束条件。这部分任务间逻辑关系与相似用户查找并行化的数据流图基本相同就不再重复。
4 仿真实验与性能分析
4.1 实验步骤
首先给出算法实现流程图3所示。
具体实验过程分为以下3个部分:
(1)根据算法实现流程图将算法在串行环境和并行环境下分别实现。
(2)对于串行环境,用MovieLens-1M数据集,测试本算法和其它算法在不同K值的时耗;然后测试本算法和基于评分预测算法,CoFiRank算法,Listwise算法准确率,并进行相应的分析。
(3)在并行环境下,用MovieLens-lastest数据集,对目标用户随机选取不为0的评分数据的10%作为测试集,其它部分作为训练集,进行加速比实验分析。
4.2 算法效率评价
由于数据预处理矩阵转换可以离线进行,且在线进行部分查找相似用户所占时间比重远高于推荐所占用时间,而Top-K中K的选择影响推荐准确率。因此在不考虑矩阵转换耗时情况下,分析本文算法和Listwise算法各种Top-K排列时,查找相似用户效率,得到结果见表1。
从表1可看出,算法在相同k值情况下,由于物品类数量m远小于物品数量n,计算耗时远低于Listwise算法,说明本文算法在查找相似用户时效率更高。
4.3 预测准确率评价
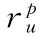
(10)
与本文算法进行比较的是基于评分预测算法,CoFiRank算法和Listwise算法。由于求所有物品全排列概率分布计算复杂度过高,用Top-K概率模型只考虑排列的前K个位置来降低计算复杂度。选择k=3,因为当k>3时,算法准确率提升有限,计算复杂度却指数增长。通过仿真实现,得到实验结果如图4所示。
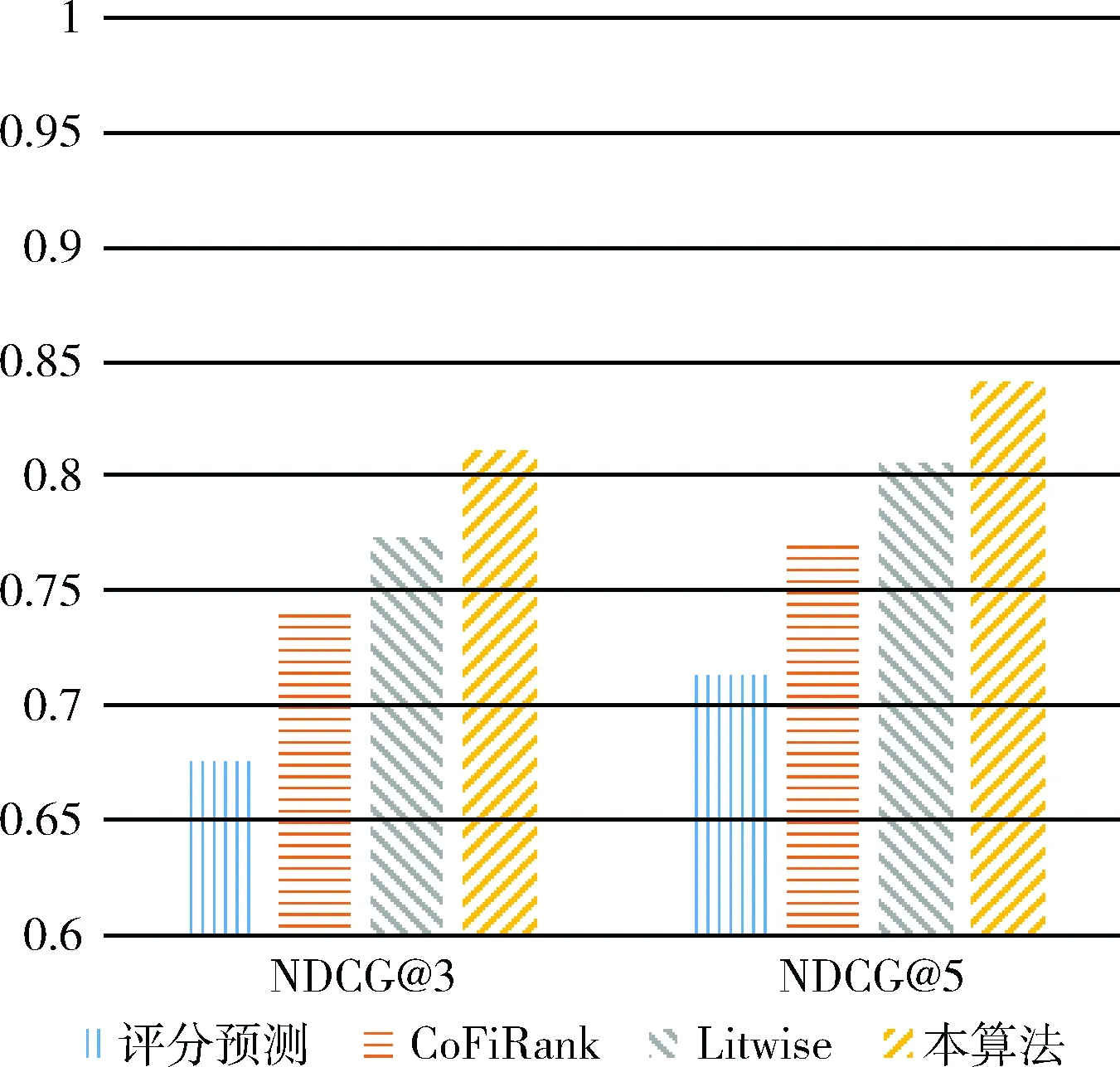
图4 各个算法准确率
通过以上实验可以发现,将NDCG作为评价指标,面向排序预测的算法准确率明显优于面向评分预测的算法准确率。本文算法相对最先进的面向评分预测的算法相比,准确率提升了11.9%,比CoFiRank算法提升了6.1%,比面向排序预测Listwise算法提升了3.6%。在用户-物品评分矩阵非常稀疏时,相似用户查找的准确率受到限制,从而使得预测准确率也遇到瓶颈,本文通过矩阵转换较好解决了这个问题,因此本算法有更高的预测准确率。
4.4 并行化加速比分析
本文对所实现的算法进行了并行化设计,评价算法并行化优劣可通过算法加速比进行。通过实验,得到本文算法加速比与理想情况下的算法加速比,实验结果如图5所示。
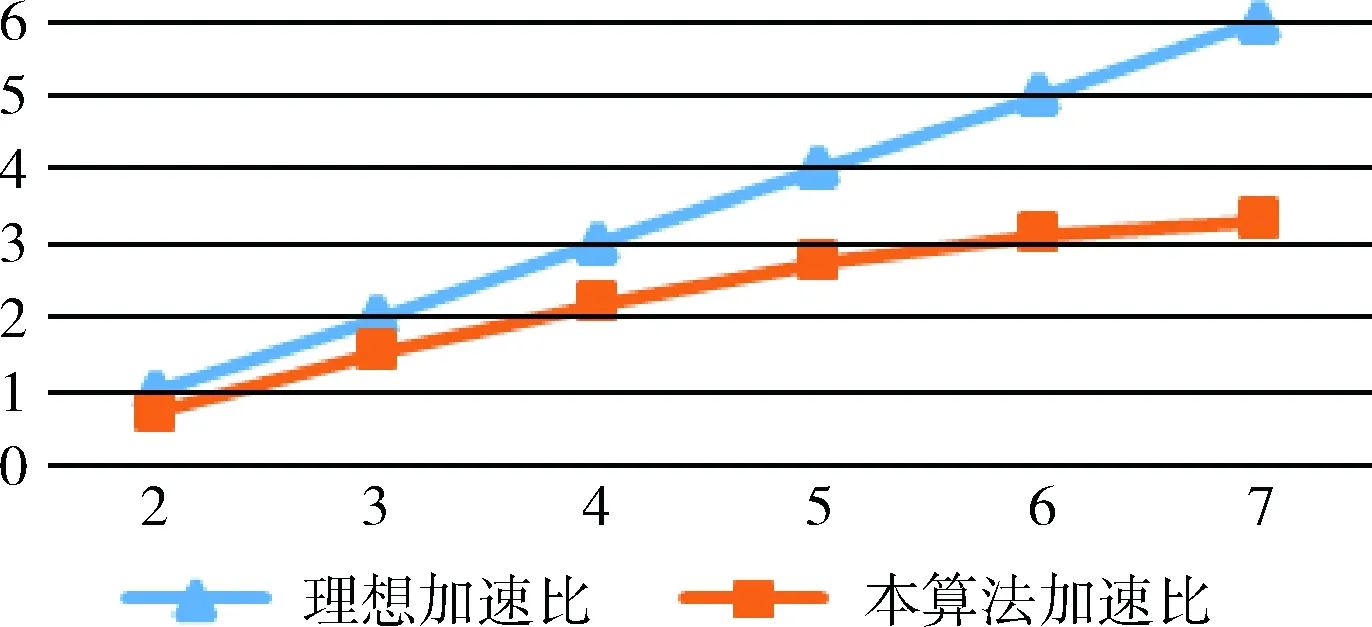
图5 算法加速比
从图3中可以看出,在只有两台计算机的集群中由于其中一台是进行任务调度,且每个任务的中间结果都输出到本地,再交给下一个任务,此时加速比是小于1;后续加速比的增长越来越慢,是由于在最后预测排序阶段,通过梯度下降算法迭代进行,每次迭代结果都输出到本地,再从本地读取进行下一次迭代,这样随着集群规模扩大,需将中间结果合并耗费时间也就越来越长,使得加速比增长受到限制。
5 结束语
本文利用物品属性向量典型性将用户-物品评分矩阵转换为用户-物品类矩阵,更能体现用户的兴趣,然后用物品类全排列的概率分布代替物品全排列概率分布,解决了数据稀疏性对相似用户准确查找及物品维度过高造成的计算复杂度过高问题。通过仿真实验说明本文算法在时间效率和推荐排序准确率均有明显提升,同时在Hadoop环境下对算法进行并行化,根据加速比实验结果,可以表明本算法有较好的可扩展性及应用价值。
[1]Meng-Hui Chen,Chin-Hung Teng,Pei-Chann Chang.Appl-ying artificial immune systems to collaborative filtering for movie recommendation[J].Advanced Engineering Informatics,2015,29(4):830-839.
[2]RONG Huigui,HUO Shengxu,HU Chunhua,et al.User similarity-based collaborative filtering recommendation algorithm[J].Journal on Communications,2014,35(2):16-24(in Chinese).[荣辉桂,火生旭,胡春华,等.基于用户相似度的协同过滤推荐算法[J].通信学报,2014,35(2):16-24.]
[3]Baltrunas L,Ricci F.Experimental evaluation of context-dependent collaborative filtering using item splitting[J].User Modeling and User-Adapted Interaction,2014,24(1):7-34.
[4]YANG Yang,XIANG Yang,XIONG Lei.Collaborative filtering and recommendation algorithm based on matrix factorization and user nearest neighbor model[J].Journal of Computer Applications,2012,32(2):395-398(in Chinese).[杨阳,向阳,熊磊.基于矩阵分解与用户近邻模型的协同过滤推荐算法[J].计算机应用,2012,32(2):395-398.]
[5]Yi Cai,Ho-fung Leung,Qing Li.Typicality-based collaborative filtering recommendation[J].IEEE Transactions on Knowledge and Data Engineering,2014,26(3):766-779.
[6]LI Gai,LI Lei.A new algorithm of cold-start in a collaborative filtering system[J].Journal of Shandong University(Engineering Science),2012,42(2):11-17(in Chinese).[李改,李磊.一种解决协同过滤系统冷启动问题的新算法[J].山东大学学报(工学版),2012,42(2):11-17.]
[7]ZHU Yuxiao,LYU Linyuan.Evaluation metrics for recommender systems[J].Journal of University of Electronic Scie-nce and Technology of China,2012,41(2):163-175(in Chinese).[朱郁筱,吕琳媛.推荐系统评价指标综述[J].电子科技大学学报,2012,41(2):163-175.]
[8]Shi Y,Karatzoglou A,Baltrunas L,et al.Climf:Learning to maximize reciprocal rank with collaborative less-is-more filtering[C]//The 6th ACM Conference on Recommender Systems.New York:ACM,2012:139-146.
[9]Wang S,Sun J,Gao BJ,et al.VSRank:A novel framework for ranking-based collaborative filtering[J].ACM Trans Intelligent Systems Technolgy,2014,5(3):51.
[10]Shanshan Huang,Shuaiqiang Wang,Tie-Yan Liu.Listwise collaborative filtering[C]//International ACM SIGIR Conference on Research & Development in Information Retrieval.New York:ACM,2015:343-352.
[11]CHEN Kehan,HAN Panpan,WU Jian.User clustering based social network recommendation[J].Chinese Journal of Computers,2013,36(2):349-359(in Chinese).[陈克寒,韩盼盼,吴健.基于用户聚类的异构社交网络推荐算法[J].计算机学报,2013,36(2):349-359.]
[12]HUANG Zhenhua,ZHANG Jiawen,TIAN Chunqi,et al.Survey on learning-to-rank based recommendation algorithms[J].Journal of Software,2016,27(3):691-713(in Chinese).[黄震华,张佳雯,田春岐,等.基于排序学习的推荐算法研究综述[J].软件学报,2016,27(3):691-713.]
[13]Mohammad Abbassia,Maryam Ashrafib,Ebrahim Sharifi Tashnizic.Selecting balanced portfolios of R&D projects with interdependencies:A cross-entropy based methodology[J].Technovation,2014,34(1):54-63.
