服务接口测试自动化工具的研究
2018-03-13卓欣欣白晓颖李恩鹏康介恢宋文莉
卓欣欣 白晓颖 许 静 李恩鹏 刘 喻 康介恢 宋文莉
1(清华大学计算机科学与技术系 北京 100084)2(南开大学计算机与控制工程学院 天津 300350)(zhuoxinxin@mail.nankai.edu.cn)
服务化作为网络化环境下软件的基本存在形态已然成为一种趋势.将软件功能封装为单个服务并通过明确定义的接口使用服务,在屏蔽服务实现细节的同时,能够有效支持软件复用和松耦合的分布式应用.服务接口的属性、约束与调用方式通常以标准协议描述,如同一份契约,需要大家的共同遵守才能正确地使用服务提供的功能.对于提供者而言,契约代表了对所提供功能的一种承诺,对服务消费者而言,则在编程和调用的过程中需要严格遵从这份契约的约定.互联网上越来越多的服务商都在以服务接口的方式提供应用,因而接口的质量非常重要,一个开放接口中存在的缺陷很容易四处扩散,进而导致大规模的软件故障.所以,服务接口测试对于确保服务和服务组合的质量和可靠性至关重要.然而,服务固有的开放、协同和动态等特性,增加了对其进行有效测试的难度,尤其是服务具有在线发布、升级、演化的特性,这就要求针对服务接口的测试需要具有快速、高效、持续的特点.因此,研究针对服务接口的自动化测试方法具有重要意义[1-3].
模型驱动测试是实现自动化测试的一种重要策略.测试人员使用模型抽象化描述被测系统,并基于模型进行有效测试用例的生成,进而实现测试自动化.将模型驱动测试适当地应用到软件生命周期的不同阶段中将有助于提高软件故障检测效率、降低测试成本和时间、有效应对软件需求变更、增强测试自动化水平[4].当模型驱动用于服务接口测试时,一般都是对被测服务接口进行建模,并基于接口模型实现测试用例的自动生成.
然而,模型驱动测试的高效与否取决于其采用的建模技术是否能够充分捕获被测系统的有效特征.建模技术的选取是模型驱动测试研究的关键问题之一.目前,已有的基于模型驱动的服务接口测试方法普遍存在这样一些问题:1)模型描述方法形式化程度较差,自然语言以及文本方式的描述使得自动化处理难以实现.2)表述能力十分有限,缺乏对服务操作行为和集成信息的语义描述,导致无法准确定义服务的使用场景和约束关系.这些问题向消费者屏蔽了一些客观存在的隐含信息,导致服务提供者和消费者无法对服务采用达成一致的理解,进而造成服务无法正确运行.3)生成的测试用例过于抽象,自动化执行难,由于采用模型语言描述的服务接口通常具有语言无关性,因此生成的测试用例往往采用通用语言描述(如XML),无法在不同编程语言环境中自动执行.
为此,本文提出了一种基于语义的服务接口测试方法,使用模型驱动测试生成,并设计实现了测试自动化工具——AutoTest.通常,服务接口签名采用接口操作名称以及相应特定数据类型描述的输入输出返回值参数来定义服务接口函数.无论是参数之间还是函数之间都隐藏着多种类型的约束条件,例如数据的范围和分区、函数的前置后置条件和可执行约束(参数间的依赖关系、执行顺序、时间约束等).为了强化测试的有效性,将上述信息作为领域知识添加进服务接口规范中是相当有必要的.AutoTest工具首先采用半形式化建模方法基于语义规则和本体技术为服务及其相关数据构建了统一的基于接口语义契约(interface semantic contract,ISC)的领域概念模型,支持对被测服务接口数据结构和操作行为的领域建模,在增强服务的易理解性的同时,也使得服务的信息表达更加丰富;其次,基于模型实现测试数据和用例的自动生成,采用多种组合算法优化测试数据和用例生成,支持图形化的测试计划编排,能有效完成单个服务和组合服务的测试用例设计和生成;第三,借助用例元模型,实现对测试用例的跨语言描述,灵活生成不同语言的测试代码文件.图1为自动化测试工具AutoTest的体系架构图.AutoTest的视频演示链接地址为:https:v.qq.comxpagey0377oapdi9.html.
AutoTest是基于Eclipse的插件平台进行设计和实现的.它提供了一个可视化的用户友好界面,并基于模型驱动测试方法实现了对接口建模到测试生成这一测试全过程的支持.AutoTest中实现了多种基于组合测试的决策表生成算法用于优化测试生成.实验结果表明,AutoTest可为服务接口测试快速生成大量有效的测试用例.
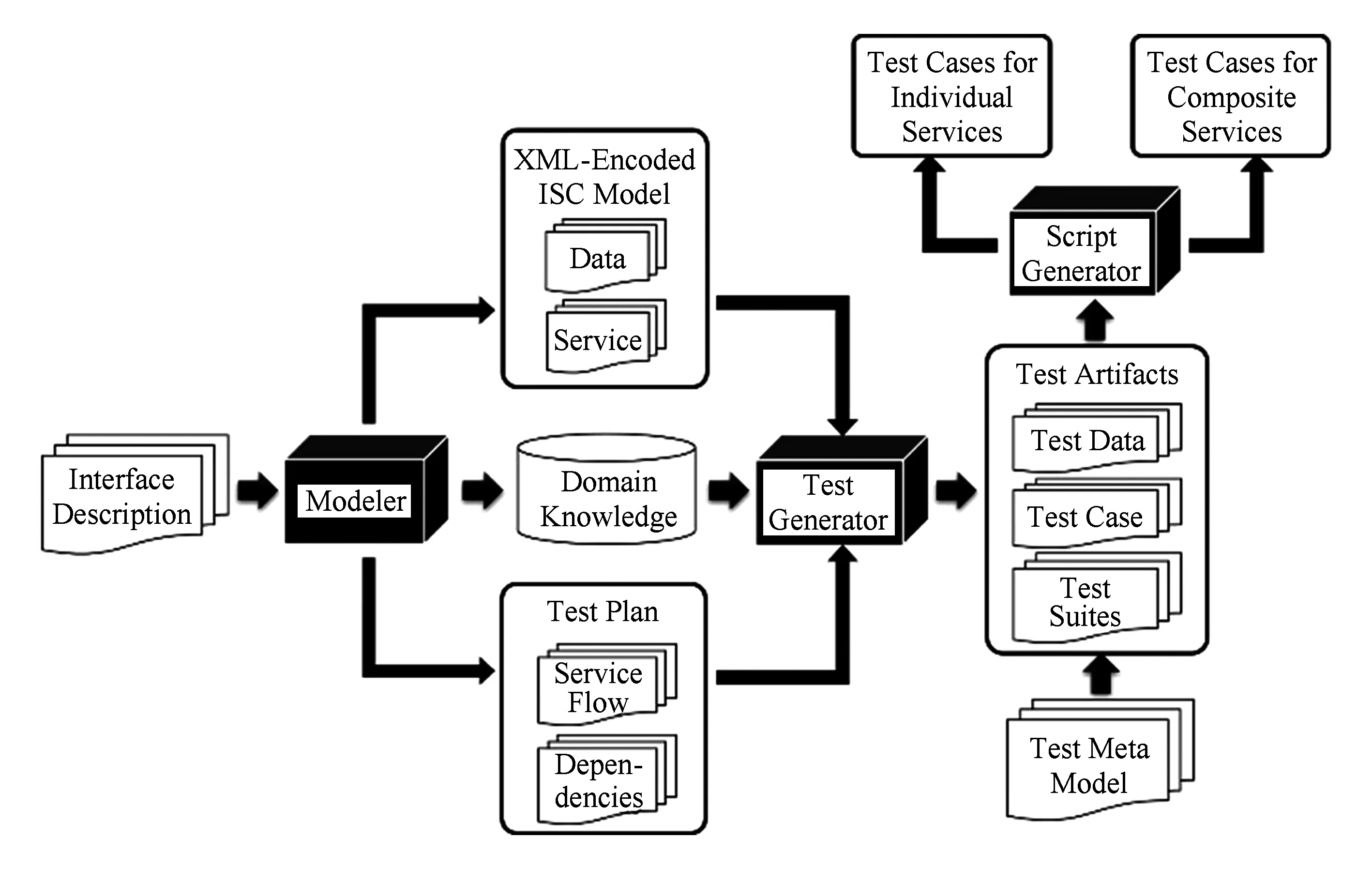
Fig. 1 AutoTest approach overview图1 AutoTest体系架构
1 模型的定义与生成
1.1 接口语义契约模型
服务提供者和消费者基于服务接口契约对服务达成一致理解是服务正确调用和执行的重要前提条件.契约中主要包含服务运行所需的数据信息和上下文信息.数据信息中蕴含着丰富的领域概念.上下文信息反映了数据之间的约束和依赖关系、服务与服务之间的依赖关系以及服务与环境之间的依赖关系,捕获这些关系并将其添加进服务接口模型中将会在一定程度上提高所构建模型的准确性.
文献[1-2, 5-9]在测试设计中应用了基于语义的知识表达技术,丰富了数据的表达含义,获得了更加全面的服务接口描述.文献[1-2]基于Web服务接口的契约和语义知识,使用本体和规则语言为接口构建接口语义契约模型(数据模型和服务模型),并基于模型实现了用于生成测试数据的分区生成算法和模拟退火算法.文献[5]使用基于语义的领域模型对服务的外部行为进行了刻画,并且提供了领域模型转化为测试用例的映射机制.文献[6]构建的语义模型能够对服务的数据、功能以及约束进行良好定义,并且通过语义规则实现了对服务预期行为的描述.由该语义模型计算所得的测试断言独立于服务的具体实现,可在具有相同接口标准的服务间实现复用.文献[7]基于对满足OWL-S规范的组合服务及其工作流的分析,将OWL-S语义中可能包含的突变算子划分成了4类,分别是数据突变、条件突变、控制流突变以及数据流突变,并提出了一种基于本体的突变解析方法.通过将该解析方法应用到服务实例BookFinder中,对该方法是否能够作为标识OWL-S组合服务测试充分性的指标进行了验证.文献[8]使用过程控制等方法丰富了传统契约所能够表达的信息,使用OWL-S 过程模型形式化描述服务契约,并通过检验服务功能和契约表述是否一致来确认契约定义是否有效.文献[9]通过构建测试本体模型(test ontology model, TOM)定义了测试设计和执行阶段的语义信息,并且基于OWL-S中的语义说明解析了服务参数的类属性和类间关系,进而为其划分了数据分区.
本文在上述文献的基础上,从3个层次为被测服务构建基于语义契约的接口模型(ISC):数据模型、服务模型以及实现组合测试所需的计划模型,如图2所示.构建ISC模型时,采用类、属性、关系、约束以及个体等本体元素描述特定服务接口的领域概念知识.使用语义规则对ISC模型的数据约束进行描述,包括单个数据模型内约束的描述,如区间约束、枚举约束和模式定义约束;以及多个模型间约束的描述,如简单数据模型、复杂数据模型以及服务参数模型间约束优先级的定义和测试计划模型中数据依赖关系的定义.
数据模型用于服务接口参数信息建模,分为简单数据模型和复杂数据模型,分别用于描述领域内的基础概念和复杂概念,复杂数据模型一般由多个简单数据类型构成.每个数据模型都可以定义自己的约束关系.
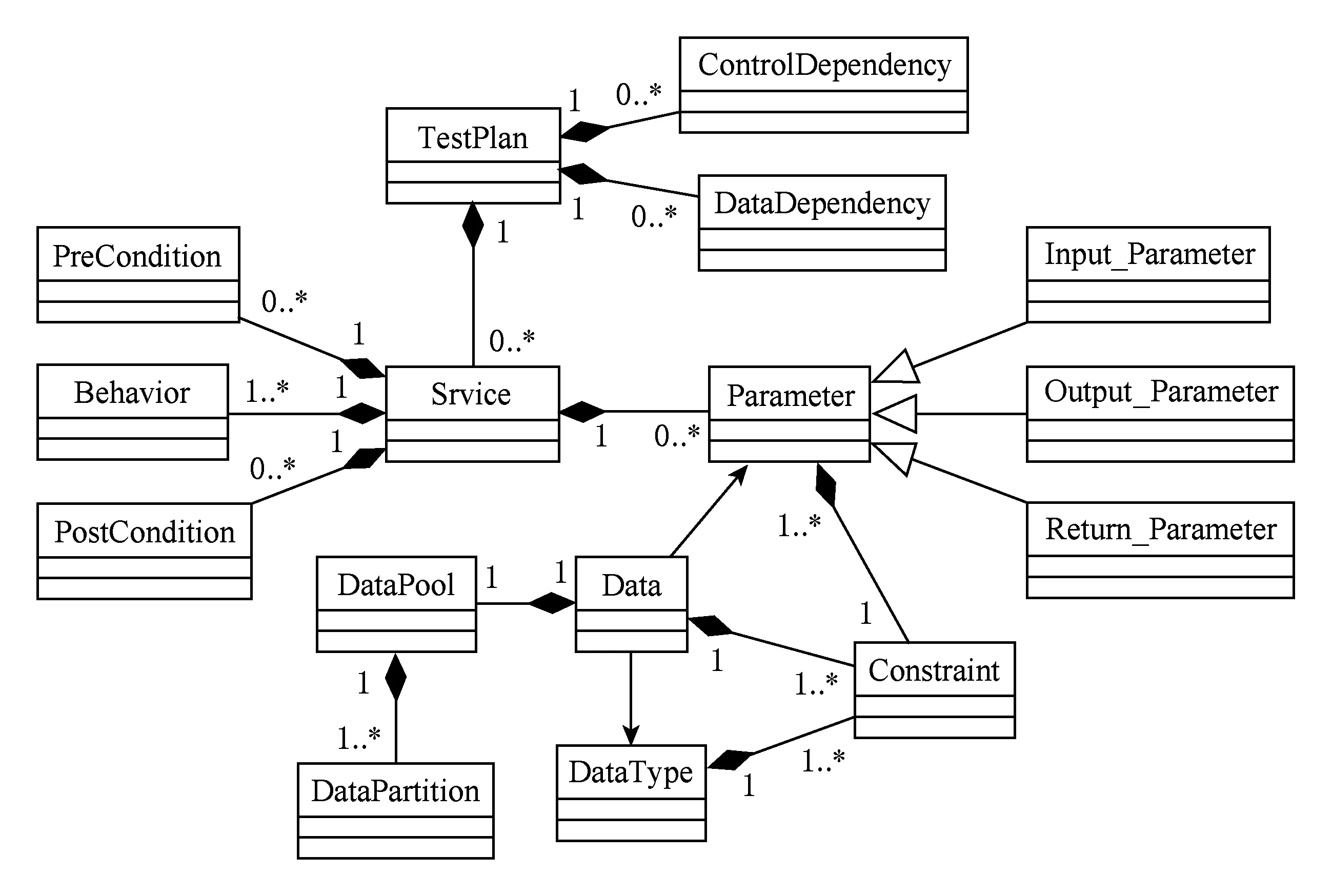
Fig. 2 ISC class diagram图2 ISC模型类结构图
服务模型通过描述服务执行所必需的数据信息和上下文信息来刻画被测服务功能.具体地,数据信息的描述是建立在数据模型的基础之上,而上下文信息的描述是通过添加相关头文件来实现.
计划模型是以单个服务模型为基础,增加了对服务之间控制依赖和数据依赖等多种依赖关系的定义,从而能够更加准确地描述特定业务场景下各个服务之间的协同关系和执行条件.
1) 数据模型定义
DatatypeSimpleDatatype|ComplexDatatype.
SimpleDatatypeID,classType,generalType,Description,Constraints.
ComplexDatatypeID,classType,Description,Attributes.
①ID:数据模型唯一标识;
②classType:数据模型的名称;
③generalType:基本数据类型,如int,char;
④Description:数据模型的描述信息;
⑤Constraints{Constrainti}:约束集合;
⑥ConstraintInterval,Enumeration,Schema-Definition:3种约束类型,即区间约束、枚举约束和模式定义约束;
⑦Attributes{Attributei}:复杂数据模型的属性集合;
⑧AttributeID,Name,SimpleDatatype,AttrConstraints:属性定义,由简单数据类型构成.
2) 服务模型定义
ServiceID,Name,Inputs,Outputs,Return,HeaderFiles.
①ID:服务模型唯一标识;
②Name:服务模型的名称;
③Inputs{Parameteri}:输入参数集合;
④Outputs{Parameteri}:输出参数集合;
⑤ReturnParameter:返回值;
⑥ParameterID,Name,Type,isPointer,Description,Datatype,ParaConstraints:参数定义,以数据模型为基础;
⑦HeaderFilessystemFiles,userdefined-Files:服务的头文件集合,用于描述服务运行时所必需的上下文信息.
数据模型和服务模型之间通过数据的约束依赖关系紧密联系,协同合作实现服务功能.简单数据模型、复杂数据模型以及服务模型之间的数据依赖关系可看作为优先级由高到低的不同约束(Constraints,AttrConstraints,ParaConstraints),低级约束的添加需满足高级约束的限制.
3) 计划模型定义
PlanID,Name,Description,Services,Dependencies.
①ID:计划模型的唯一标识;
②Name:计划模型的名称;
③Description:计划模型的描述信息;
④Services{Servicei}:组成计划的服务集合;
⑤Dependencies{ControlDpi},{DataDpi}:依赖关系集合,用于描述各个服务之间的交互信息,包括控制依赖和数据依赖;
⑥ControlDpseqInvokes,parInvokes,self-Invokes:控制依赖关系,描述了服务的调用序列,包括顺序调用、并行调用和自调用;
⑦DataDpIn-InDps,Out-OutDps,In-OutDps:数据依赖关系,描述了服务之间的参数依赖关系.例如:服务IS1和服务IS2顺序执行,In-InDps指的是IS2的输入依赖于IS1的输入,Out-OutDps指的是IS2的输出依赖于IS1的输出,In-OutDps指的是IS2的输入依赖于IS1的输出.
1.2 服务模型的转换与生成
本文设计并实现的测试工具AutoTest虽然可以辅助完成建模工作,但是对建好的模型如何重复利用?这是决定自动化测试优势能否发挥的关键点之一.如图1所示,本文通过解析服务接口的接口描述文档及其相关领域概念知识构建ISC模型中的数据模型和服务模型.在初始条件下,模型的构建基于机器可理解的输入完成,建好的模型可以导出为本体语言描述的模型文件;而在后续回归测试中,模型的构建可通过直接导入模型描述文件自动化生成.对于频繁更新的服务接口而言,回归测试在整个测试周期中占比相当高,AutoTest为测试人员高效更新模型并快速重新生成大量可执行测试用例提供了便捷,规避了人工方式下的繁琐和易错性,能够有效降低测试生成成本,提高测试效率,缩短测试周期[10].
与文献[1-2,5-9]一样,本文同样采用本体语言——OWL (Web ontology language)作为模型描述语言对ISC模型中的数据模型和服务模型进行刻画.使用AutoTest工具提供的可视化模板完成ISC模型中数据模型和服务模型的构建后,模型可以导出为“.owl”格式,后续可将OWL描述的模型文件直接导入到测试工具中.
ISC模型和OWL模型采用XML的JDOM树形结构进行转换描述.转换的关键是确定OWL语言数据结构和ISC模型之间的对应规则,这其中主要涉及到了4种OWL语言结构,它们分别是“DatatypeProperty”,“Class”,“Thing”,“Named-Individual”.“DatatypeProperty”用于指明描述对象为数据模型.“Class”结构用于对数据模型进行更加细致的描述,父类为“Thing”结构的“Class”结构用于描述简单数据模型和复杂数据模型;父类为非“Thing”结构的“Class”结构用于描述构成复杂数据模型的简单数据模型,这种情况下,父类即为相应复杂数据模型对应的结构.“NamedIndividual”结构用于描述服务模型及其参数信息.该结构中的“process:hasInput”,“process:hasOutput”,“process:hasReturn”可用于区分输入参数、输出参数和返回值参数.通过为OWL模型中的相应属性赋值可实现ISC模型到OWL模型的转换;通过解析OWL模型中相应属性的值可重构ISC模型.具体的OWL文件生成和解析算法如算法1和算法2所示:
算法1. OWL文件生成算法.
输入:简单数据模型、复杂数据模型、服务模型;
输出:OWL文件.
Elementroot=GeneHeadForOwl();
Documentd=newDocument(root);
addDataModel(simpleData,complexData,root);
For (eachsinservices) do
root.addContent(GeneService(s));
End For
For (eachsinservices) do
For (eachpins.inputParas) do
root.addContent(GeneInputForService(p));
End For
For (eachpins.outputParas) do
root.addContent(GeneOutputForService(p));
End For
For (eachpins.returnParas) do
root.addContent(GeneReturnForService(p));
End For
End For
DocTypedType=newDocType(“rdf:RDF”);
StringstrDeclare=GetDeclare();
dType.setInternalSubset(strDeclare);
d.setDocType(dType);
owlFileGenerate().
算法2. OWL文件解析算法.
输入:OWL文件;
输出:简单数据模型、复杂数据模型、服务模型.
/*root为OWL文件根节点*/
For (eacheleinelels) do
If (ele节点名称为“DatatypeProperty”)
then
addToSimpleData(ele);
End If
If (ele节点名称为“Class”) then
If (ele第0个孩子节点属性为“Thing”)
then
addConstrainToSimpleData(ele);
Else
addConstrainToComplexData(ele);
/*解析约束,添加到已有的复杂数据模型中,若该复杂模型不存在,则新建*/
End If
End If
If (ele节点名称为“NamedIndividual”)
then
If (ele第0个孩子节点属性为
“AtomicProcess”) then
addToServices();
For (eachcinele第1个以后孩子节点) do
If (c节点名称为“hasInput”) then
addInputParaToService();
Else
If (c节点名称为“hasOutput”)
then
addOutputParaToService();
Else
If (c节点名称为“hasReturn”)
then
addReturnParaToService();
End If
End If
End If
End For
End If
End If
End For
2 基于模型的测试生成
在需求分析时,我们遇到了以下4个问题需要解决:1)自动化生成方法固然能够在短时间内快速生成大量测试数据,但是如何挑选具有高覆盖率、低数量级的测试数据集?这对于降低后续测试执行成本而言是一个关键问题;2)无论采用哪种组合算法,生成的决策表都会存在冗余和无效的决策,如果不能及时剔除,在后续生成测试用例时会造成额外的开销;3)被测服务的开发语言存在差异,测试工具可以根据自然语言描述的服务接口文档完成建模工作,无需关注内部实现语言,但在生成测试代码时却缺少灵活性,只能以程序中固化的方式生成特定语言的测试代码;4)进行组合测试时,服务之间会存在数据和控制依赖关系,如何能便捷直观地描述各种依赖关系,高效完成测试计划编排?
针对上述问题,我们在测试工具的设计与实现中采取了针对性的解决方法.
2.1 基于数据分区的组合测试数据生成
基于数据模型和服务模型中的参数约束,可以根据测试覆盖率的需求生成测试数据.使用服务参数的整个输入域作为测试输入,无疑会得到最大的测试覆盖率,但是会带来针对性差、代价高的问题.并且,当同时存在多个参数时,追求全覆盖会导致参数组合爆炸.
为此,本文提出基于数据分区的组合测试方法,通过为服务参数的输入域划分数据分区并为分区组合构建决策表,解决测试数据生成的盲目性问题,同时在覆盖率和组合爆炸之间取得折中.方法描述如图3所示.
1) 数据分区划分.依据等价类划分的思想,为服务的每个输入参数划分数据分区,包括合法分区和非法分区,用于描述更加细化的参数数据约束条件.
2) 分区数据集设置.针对每个数据分区,可采用随机方式或者自定义方式从每个分区中选取少数代表性数据作为分区数据集,用于最终的测试数据自动生成.分区数据集的设计,既有效避免了使用整个分区作为输入时可能导致的测试数据量过大的问题,又能有效提高测试的针对性,为满足使用尽量少的测试用例达到尽量大的覆盖率的测试目标提供了可能.
3) 决策表生成.以服务的输入数据分区作为条件属性,以服务的返回值作为决策属性,为服务的输入参数组合创建决策表.为了避免组合爆炸,采用了多种组合测试算法(全组合、IPO2组合、基于拟水平法的正交实验设计、基于并列法的正交实验设计)来生成满足不同测试覆盖率需求的决策表.
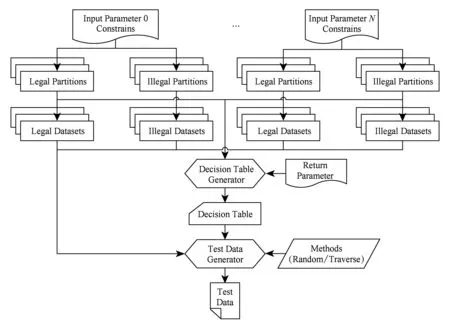
Fig. 3 Generation of test partitions and test data based on combinatorial algorithms图3 基于组合测试算法的数据分区和测试数据的生成
计划模型的测试用例来自于其组成服务的测试用例集组合,对这些用例数据进行笛卡儿积组合遍历无疑会导致组合爆炸,因此,也采用组合测试算法来支持计划模型的测试数据生成.
2.2 决策表约减算法
组合测试算法生成的决策表由决策规则集R={r1,r2,…,rn}构成,其中,每条决策规则rx均是由p项条件属性Crx={c1,c2,…,cp}和q项决策属性Drx={d1,d2,…,dq}构成.为了对决策表中可能出现的冗余和无效规则进行剔除,本文定义了如下的决策表约减规则:
对于决策表中的任意2条决策规则rx和ry,R={r1,r2,…,rx,…,ry,…,rn},如果它们的条件属性中有且仅有1项是不同的,即Crx={c1,c2,…,cix,…,cp},Cry={c1,c2,…,ciy,…,cp},并且它们的决策属性均相同,即Drx=Dry={d1,d2,…,dq},则可将rx和ry进行约减合并,R={r1,r2,…,rx+y,…,rn},Crx+y={c1,c2,…,cix+ciy,…,cp},Drx+y={d1,d2,…,dq}.
在决策表中不断重复执行上述约减规则,直至找不到符合约减规则的决策规则为止.具体的决策表约减算法如算法3所示.对决策表进行约减能够提高后续测试用例的生成效率,有效避免了决策表冗余可能造成的额外开销.
算法3. 决策表约减算法.
输入:原始决策规则集R={r1,r2,…,rn};
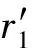
R′←R;
Forx=0 to |R′|-1 do
Fory=x+1 to |R′|-1 do
If (rx和ry的p项条件属性有且仅有1项不同) && (rx和ry的q项决策属性均相同) then
rx=rx+y;
R′.remove(ry);
x=x-1;
break;
End If
End For
End For
算法3所示决策表约减算法的复杂度为O(n2),在面对规模较大的决策表时,其执行代价较高.如何改进算法,降低算法执行成本,进而助力于缩短测试数据生成时间,是本文后续工作的重点之一.
2.3 跨语言测试代码生成
为屏蔽被测服务在实现语言上的差异性,支持不同编程语言测试代码的灵活生成,首先,我们提出了通用用例元模型的概念,使用XML作为模型描述语言,根据用例信息,对测试代码生成所需的各类要素进行建模,包括:被测服务的基本信息、被测服务的参数信息以及测试数据等.定义如下:
TestCaseServiceInfo,ParametersInfo,TestData.
1)ServiceInfoServiceName:被测服务信息,用于测试代码中被测服务接口的声明;
2)ParametersInfoParaName,Type,isPointer,Datatype,GeneralDataType:被测服务参数信息,用于测试代码中被测服务参数的声明;
3)TestData:测试数据,即服务参数取值.
其次,考虑到Velocity模板引擎技术[11]具有基于模板引擎快速生成代码的强大优势,而且遵循相应编程语言的语义和语法定义设计出来的Velocity模板能够为测试数据转换成指定编程语言的测试代码提供映射规则,我们将用例元模型所需的各要素映射到Velocity模板中,即可实现基于多种编程语言的测试代码的自动生成,比如C++或者Java.其中,生成C++代码时会包含2个版本,一个是直接编码版本,另一个是动态链接库版本.
图4展示了基于通用用例元模型生成测试用例代码文件的过程.使用用例元模型,不仅能够帮助用户更清晰地理解测试用例,同时还能够简化测试用例的自动生成过程,为验证不同语言测试用例代码的一致性提供依据.
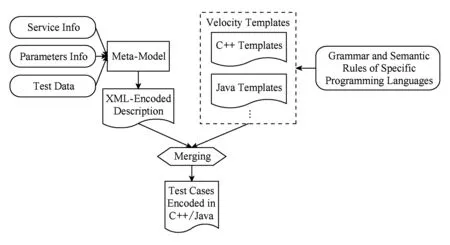
Fig. 4 Test cases generation based on the meta-model图4 基于通用用例元模型生成测试用例代码
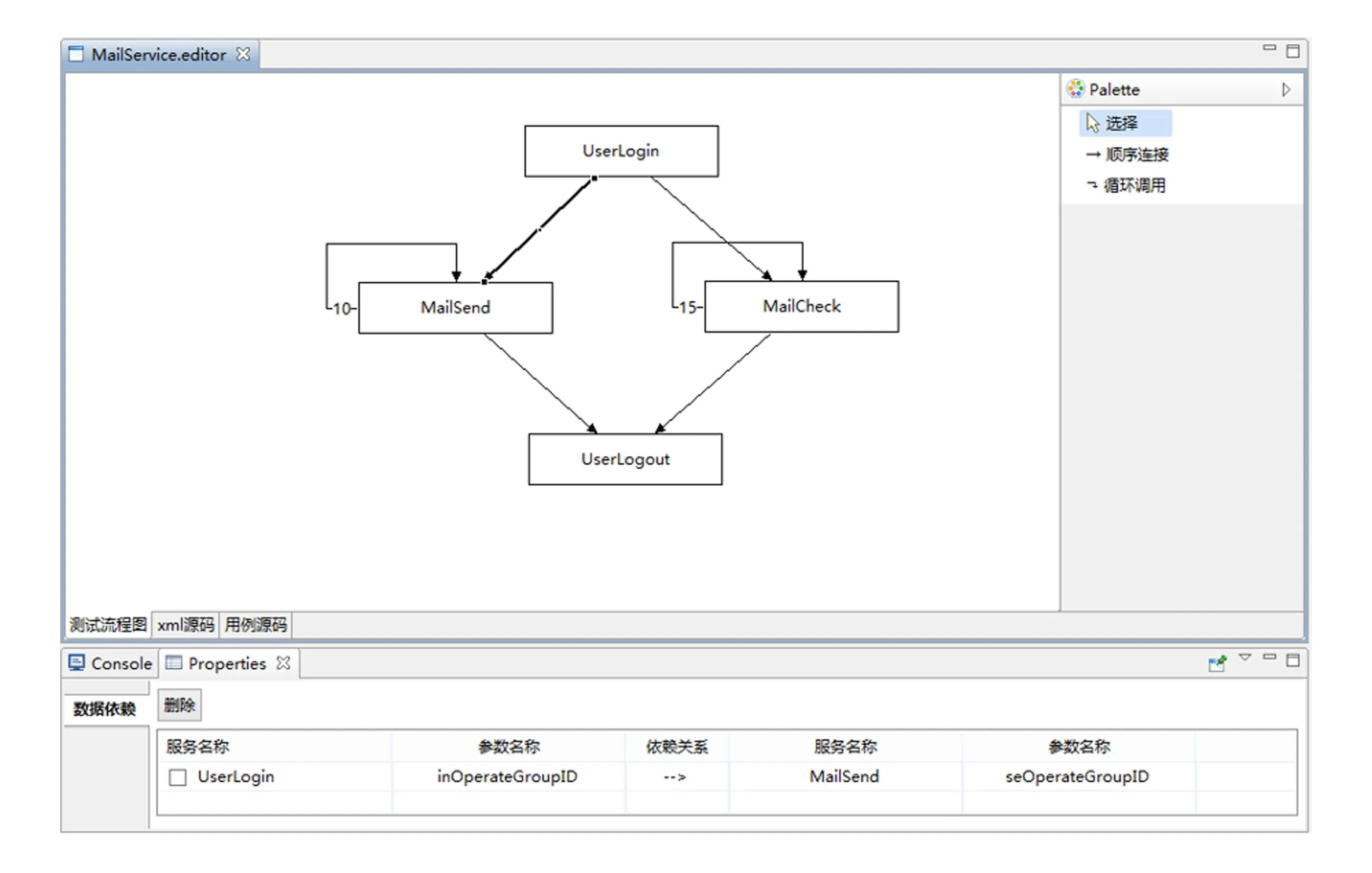
Fig. 5 Test plan visual editor图5 测试计划图形化编排
2.4 可视化测试计划编排
我们提出一种可视化的测试计划编排思路,并基于图形化编辑框架(graphical editor framework,GEF)开源框架予以实现.GEF符合标准的模型-视图-控制器(model view controller, MVC)架构,模型和视图之间彼此透明,仅通过控制器进行信息传递,将模型和视图的具体实现分割开来,减少二者之间的交互操作,从而提高了框架的可复用性.图5是使用AutoTest测试工具编排的测试计划.
测试计划定义为有向图,节点(矩形)表示被测服务的用例代码集合,边表示被测服务用例代码集合之间的控制依赖关系,可定义用例代码集合之间的控制流和数据流结构.控制流结构可定义自调用依赖关系(折线)、顺序调用依赖关系(直线)、并行调用依赖关系.数据流结构可定义输入输入参数依赖关系、输出输出参数依赖关系、输入输出参数依赖关系.AutoTest采用图形化编辑工具进行测试计划有向图的编辑,通过拖拽方式编辑测试用例代码集之间的组合关系.
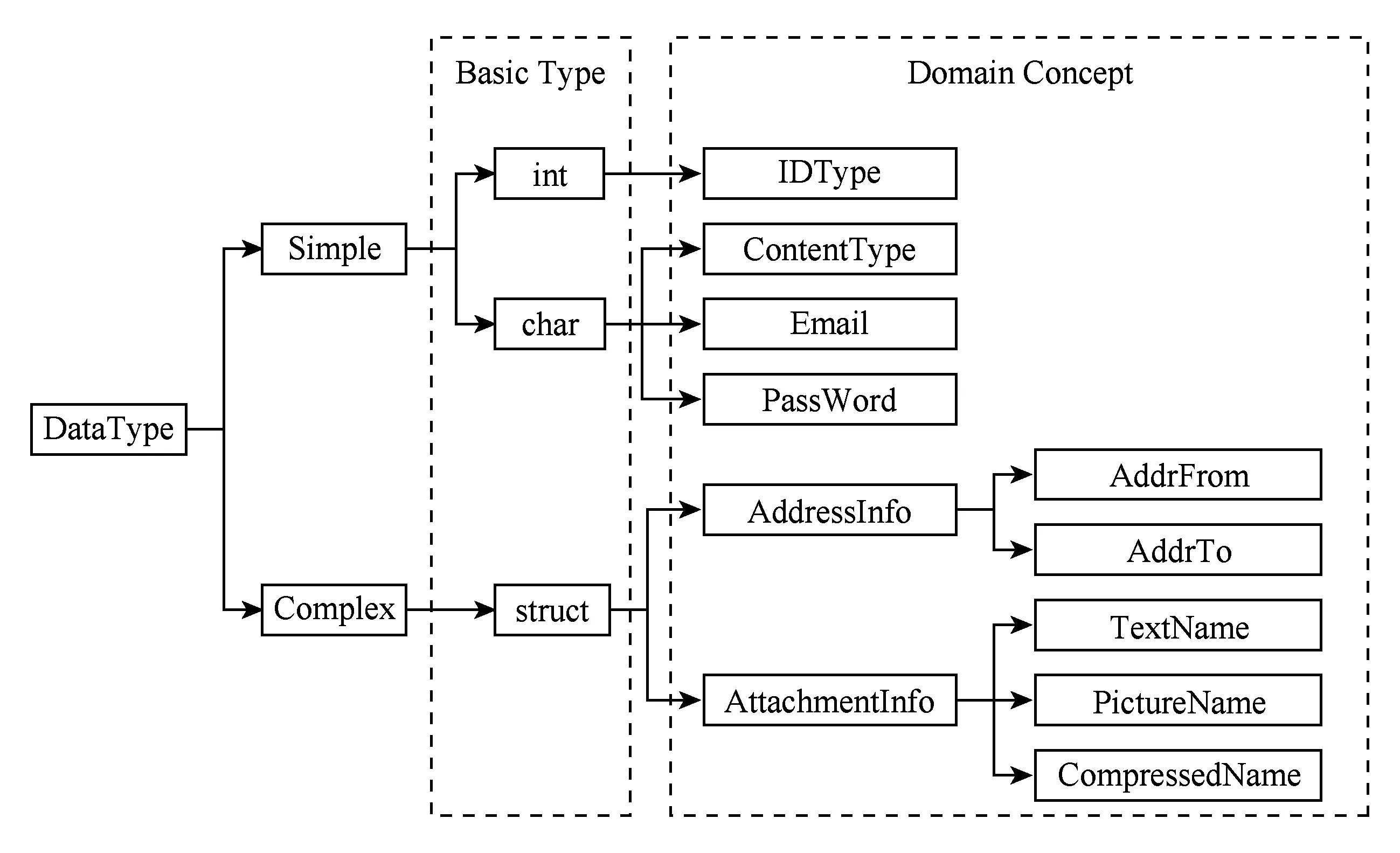
Fig. 7 The data model of MailService图7 MailService数据模型
据此,图5所示测试计划MailService可表示为由节点构成的集合V和由有向边构成的集合E构成的图G,记为G=(V,E).其中:
1)V={UserLogin,MailSend,MailCheck,UserLogout},共4个节点;
2) 有向边e使用二元组(c,d)表示,其中c=v1,v2表示1条由v1指向v2的有向边;d={[p1=p2]}表示有向边上的属性依赖集合,例如p1属性依赖于p2属性;
3)E={e}={(c,d)}={(UserLogin,Mail-Send,{[MailSend.seOperateGroupID=UserLogin.inOperateGroupID]}),(UserLogin,MailCheck,{[MailCheck.chOperateGroupID=UserLogin.inOperateGroupID]}),(MailSend,MailSend,{}),(MailCheck,MailCheck,{}),(MailSend,UserLogout,{[UserLogout.outOperateGroupID=MailSend.seOperateGroupID]}),(MailCheck,UserLogout,{[UserLogout.outOperate-GroupID=MailCheck.chOperateGroupID]})},共6条有向边.
为了提高测试计划的可复用性,测试计划模型使用XML文件进行描述和存储.图6为测试计划的部分XML描述.

Fig. 6 XML specification of test plan图6 测试计划的XML描述
2.5 实例研究
本文设计并实现的测试自动化工具AutoTest,支持服务建模、测试数据生成、测试用例生成及可视化测试计划编排.该工具用于服务接口测试时,测试活动分成2个阶段进行:1)独立测试阶段,完成单个被测服务的建模和测试生成;2)组合测试阶段,将多个服务按照应用场景编排成测试计划,生成计划用例.
本节使用邮件服务组合MailService作为测试对象来简要描述AutoTest工作过程.该组合包括4个单独的服务,分别是用户登录服务UserLogin、邮件发送服务MailSend、邮件查看服务MailCheck和用户注销服务UserLogout.根据业务逻辑,4个服务之间存在控制依赖关系,即用户需要先登录,然后进行邮件发送或查看操作,最后退出登录.
2.5.1 独立测试阶段
在该阶段,分别对组合中的4个服务进行独立测试.以MailSend为例,为了向服务模型提供数据和约束支持,在对服务的接口文档和领域知识进行解析之后,构建如图7所示的数据模型.“基本类型”为系统提供的基本数据类型,“领域概念”为描述被测服务接口领域知识所必需的特定数据类型.除此之外,依据服务的测试需求,还需要为相应的数据模型定义必要的约束条件,例如,在本实例中为数据模型Email定义了模式定义约束“*@mail.nankai.edu.cn”.
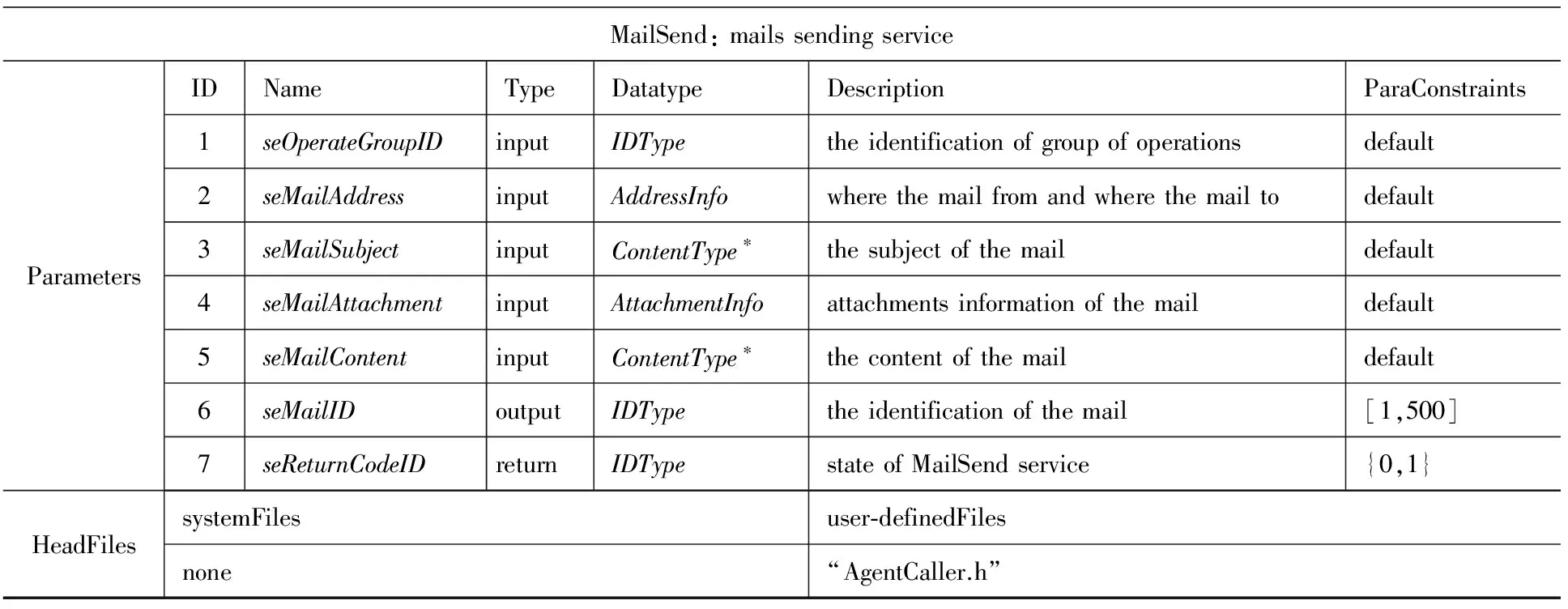
在数据模型构建完毕之后,即可进行服务模型的构建.服务模型使用图7中构建的数据模型描述其参数信息,并通过添加头文件来提供服务运行时所必需的上下文信息.图8为MailSend的服务模型.而图9所示为邮件服务组合MailService的OWL文件描述.
MailSend:mailssendingserviceParametersIDNameTypeDatatypeDescriptionParaConstraints1seOperateGroupIDinputIDTypetheidentificationofgroupofoperationsdefault2seMailAddressinputAddressInfowherethemailfromandwherethemailtodefault3seMailSubjectinputContentType∗thesubjectofthemaildefault4seMailAttachmentinputAttachmentInfoattachmentsinformationofthemaildefault5seMailContentinputContentType∗thecontentofthemaildefault6seMailIDoutputIDTypetheidentificationofthemail[1,500]7seReturnCodeIDreturnIDTypestateofMailSendservice{0,1}HeadFilessystemFilesuser⁃definedFilesnone“AgentCaller.h”
Fig. 8 Service model of MailSend
图8 MailSend的服务模型
在服务模型构建完成后,有必要为服务的每个输入参数划分合法数据分区和非法数据分区.分区的划分以参数的数据约束为基础.当参数约束为“default”类型时,约束内容由高一级的类型约束决定.以图8中的参数seOperateGroupID为例,其参数约束由IDType类型的约束决定.由于复杂数据类型的输入参数包含多个简单数据类型的子参数,在划分分区的时候,需要分别为每个子参数划分合法和非法分区以构成复杂数据类型参数的分区.当测试人员未进行分区划分时,系统会依据参数的数据约束自动地为相应参数生成1个合法分区和1个非法分区.根据测试需求,在本文实例中手动地为邮件发送服务MailSend划分了17个数据分区,如表1所示:

Table 1 Data Partitions of MailSend表1 MailSend的数据分区
基于数据分区,测试人员可以选择不同的组合测试算法(全组合、IPO2组合、基于拟水平法的正交实验设计、基于并列法的正交实验设计),为服务生成决策表,并基于分区数据集和决策表采用随机或者遍历的策略生成测试数据.
测试数据生成后,测试人员可以选择测试代码的语言类型,借助于通用用例元模型的描述,映射到Velocity模板中.Velocity模板引擎在初始化后,合并存放在其上下文中的测试数据和相应的代码模板,并将结果进行输出,从而得到所需语言的测试代码.
2.5.2 组合测试阶段
根据邮件服务组合MailService的测试需求,将独立测试阶段中生成的4个服务UserLogin,Mail-Send,MailCheck,UserLogout的测试用例集拖拽进计划模型编辑区域,如图5所示,根据顺序调用、并行调用和自调用3类控制依赖关系使用可视化连接组件连接各个服务.同时,定义了2个UserLogin→MailSend和UserLogin→MailCheck的In-OutDps,2个MailSend→UserLogout和MailCheck→UserLogout的In-InDps,共4个数据依赖.
数据依赖关系是否成立,取决于存在依赖关系的2个参数在数据类型和数据约束2个方面是否同时匹配.数据类型的匹配检查在依赖定义时进行,数据约束的匹配检查在计划用例执行过程中进行.
3 实验结果及分析
3.1 数据分区覆盖率
为评估不同组合算法生成的测试数据的覆盖率,我们对决策表规模和组合覆盖率2个指标进行了分析.实验对象为第2节的邮件发送服务MailSend.
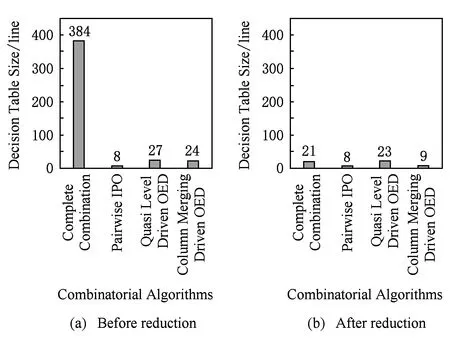
Fig. 10 Comparison of the size of decision tables of MailSend using various combinatorial algorithms图10 基于不同组合测试算法为MailSend生成决策表的规模
分别使用全组合算法、IPO2组合算法、基于拟水平法的正交实验设计算法以及基于并列法的正交实验设计算法生成决策表,图10(a)是约减前的决策表规模,图10(b)是约减后的决策表规模.从图10(a)中可以看出,对于同样的数据分区,全组合算法生成的决策表规模最大,IPO2组合算法得到的决策表规模最小.这是因为相比较于IPO算法,正交实验设计算法不仅需要满足一定的组合覆盖率,还要兼顾正交性,因此其决策表规模会稍大些.
从图10(a)和图10(b) 对比可以看出,全组合算法生成的决策表规模在约减后显著减小,而由其他组合算法生成的决策表的约减效果并不十分明显.这主要是因为本文实现的约简算法是针对有且仅有1个条件属性不同,其余条件属性以及决策属性均相同的决策规则集进行约减合并.全组合算法生成的决策表确保了对各个参数取值的全集覆盖,从而其中必然存在大量满足约简算法约减规则的决策规则集,因此其约减效果相当显著.IPO2组合算法生成的决策表确保了对各个参数取值的2组合覆盖,也即确保了任意2条决策规则至少有2个条件属性是不同的,从而不存在满足约简算法约减规则的决策规则集,因此约简算法对其是无效的.基于拟水平法的正交实验设计算法和基于并列法的正交实验设计算法生成的决策表为了确保其正交性,会在其决策表中添加少量满足约减算法约减规则的冗余决策规则集,因此其约减效果存在但并不明显.
图11为2组合、3组合、4组合以及5组合数据分区中各组合测试算法为邮件发送服务MailSend生成的决策表的覆盖率统计结果.其中,N组合是指随机选取N个参数,并从每个参数中随机挑选1个数据分区,构成N个数组分区的组合.覆盖率计算公式为:(决策表覆盖的组合数量随机的组合数量)×100%.其中,随机的组合数量是指随机地挑选相应数量的N组合.

Fig. 11 Comparison of the combination coverage of MailSend图11 MailSend组合覆盖率的比较统计
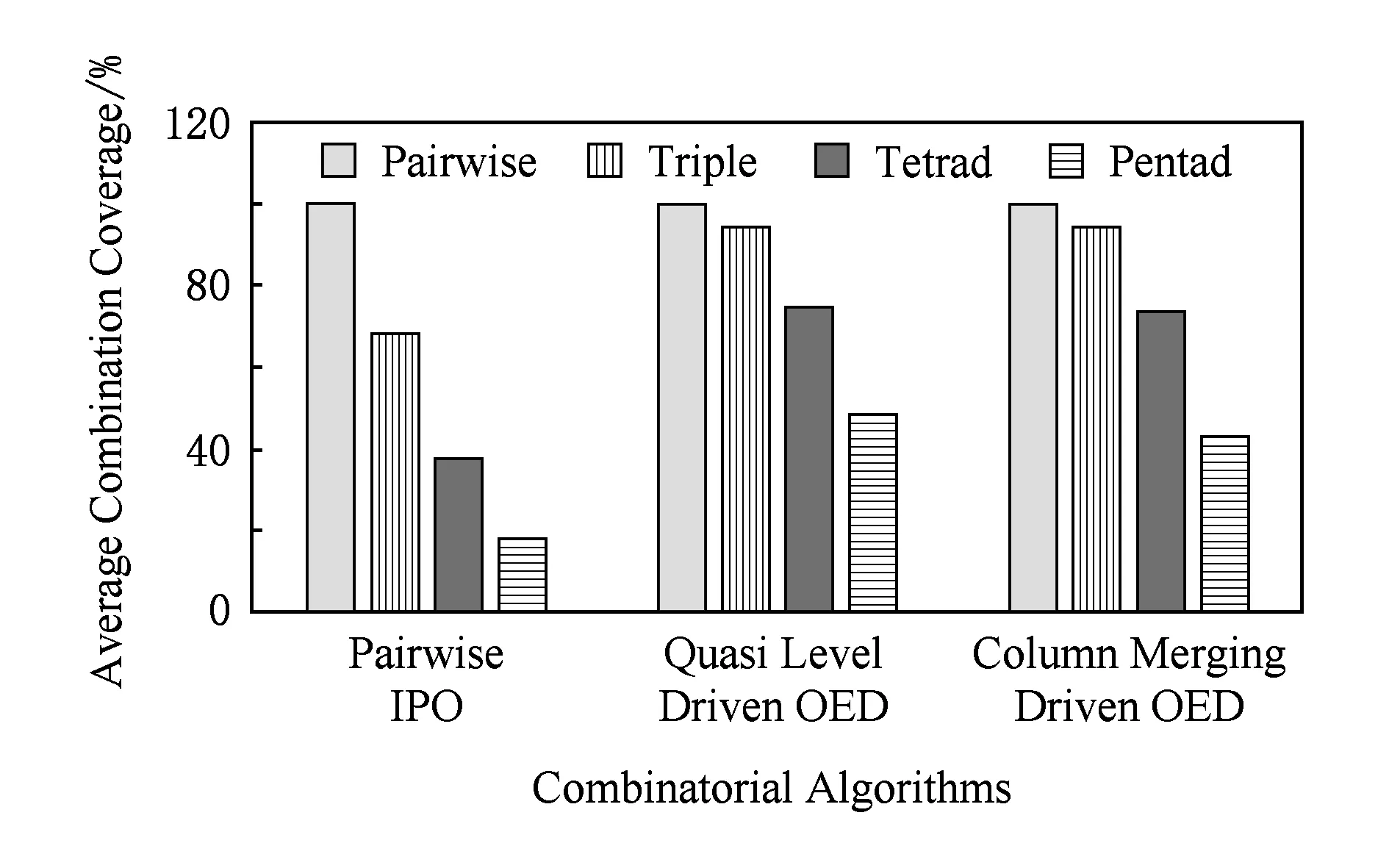
Fig. 12 Comparison of decision table coverage of MailSend图12 MailSend决策表覆盖率比较
从图11中,可以看到,在2组合中,3种组合测试算法均达到了100%的组合覆盖率;当组合内包含更多的数据分区时(3组合、4组合、5组合),正交实验设计算法的组合覆盖率始终优于IPO2组合算法.这是因为IPO2组合算法仅能够确保对两组合进行覆盖,无法确保对更多组合的覆盖率;而兼顾了正交性的正交实验设计算法依然能够在更多组合的情况下表现出良好的覆盖率.
图12为不同组合测试算法生成的决策表对不同数据分区组合的覆盖情况.从图12中,可以看到随着组合内包含的数据分区数量的增加,各算法的组合覆盖率均有明显下降.但是,由于软件失效大多数是发生在单点故障和2组合故障中,极少是由更多组合同时出现故障引起的,因此本文中的组合测试算法所生成的决策表能够对数据分区组合具有较好的覆盖率.
3.2 测试代价分析
实验使用第2节的邮件发送服务MailSend作为被测单个服务,邮件服务组合MailService作为被测组合服务,验证本文设计并实现的基于ISC模型的AutoTest能够有效支持大批量测试用例的设计和生成.
决策表中的每1行称作为决策规则.测试用例生成方式包括随机方式和遍历决策规则方式2种.在随机方式下(图13(a)),测试人员可指定随机的决策规则数量以及每条规则生成的随机测试用例数量.这就是说,在该方式下测试人员能够指定生成的测试用例总数量.在遍历决策规则方式下(图13(b)),由于所基于的分区数据集的规模可能是确定的(自定义方式),也可能是不确定的(随机方式),所以该方式下,每次生成的测试用例总数量是不同的,并且测试人员无法指定生成的测试用例总数量.考虑到测试应用场景的规模,本文在AutoTest工具中对生成的测试用例总数量的上界进行了限制(≤100 000)且使用自定义方式定义分区数据集.统计生成不同数量测试用例的总时间,如图13所示,可以发现生成单个测试用例的用时很短,并且大部分时间是用于文件的写入.这说明使用本文提出的测试方法能够快速为单个服务生成大量测试用例,这是手动方式无法赶超的.
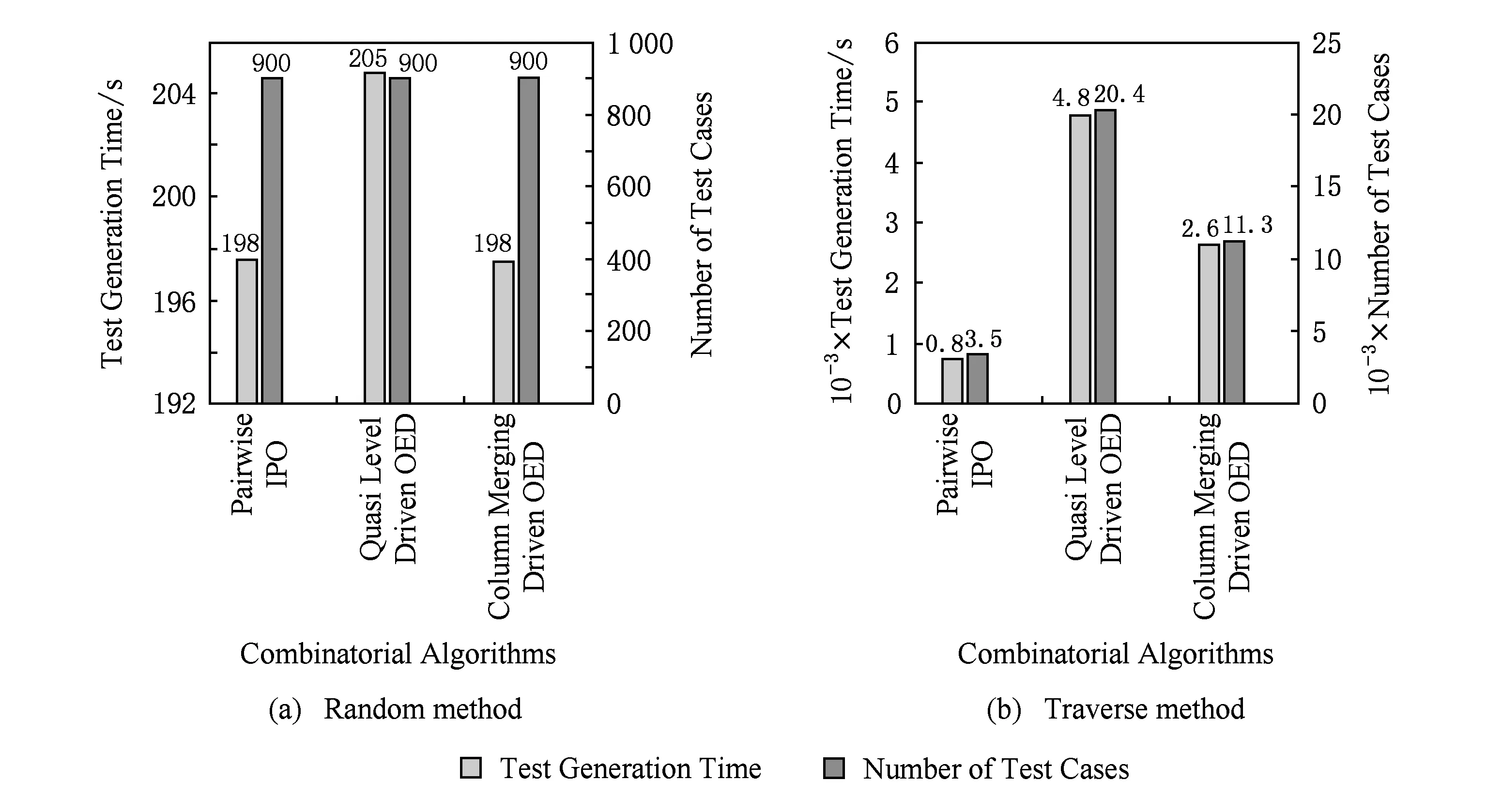
Fig. 13 Comparison of test generation time and size of MailSend图13 MailSend测试用例生成的时间和数量

Fig. 14 Comparison of test generation time and size of MailService图14 MailService测试用例生成的时间和数量
图14为使用不同组合测试算法为邮件服务组合MailService生成计划用例的数量和时间.观察图14可以发现,为邮件服务组合MailService生成计划用例时所表现出的在用例数量和生成时间上的特点与为邮件发送服务MailSend生成测试用例时的一致.并且,虽然由于单个计划用例中包含了更多的代码文件导致其平均生成时间有所增加,但该时间依旧是秒级的.这说明,在面对更为复杂的应用场景时,本文提出的测试方法仍然能保持较高的测试用例生成速度,有效降低了测试过程中的人力开销.
由于对各级模型进行了持久化存储,因此模型在被构建完毕之后可被不断复用,从而简化测试用例的自动生成进程,这为面向服务测试中最常进行的回归测试提供了极大的便利.
3.3 真实Web服务接口的测试生成与执行
实验挑选了百度第三方接口分发平台API Store上具有较多接口参数的3个较为典型的Web服务接口:HolidayService(节日查询服务接口)、GeoService(地理位置查询服务接口)和Currency-Service(汇率转换服务接口)作为被测服务,其服务接口链接地址如表2所示,验证自动化测试工具AutoTest能够为真实Web服务接口快速生成大量测试用例,并且这些测试用例具有可执行性和一定的错误检测率.

Table 2 URL of Web Services表2 Web服务接口链接地址
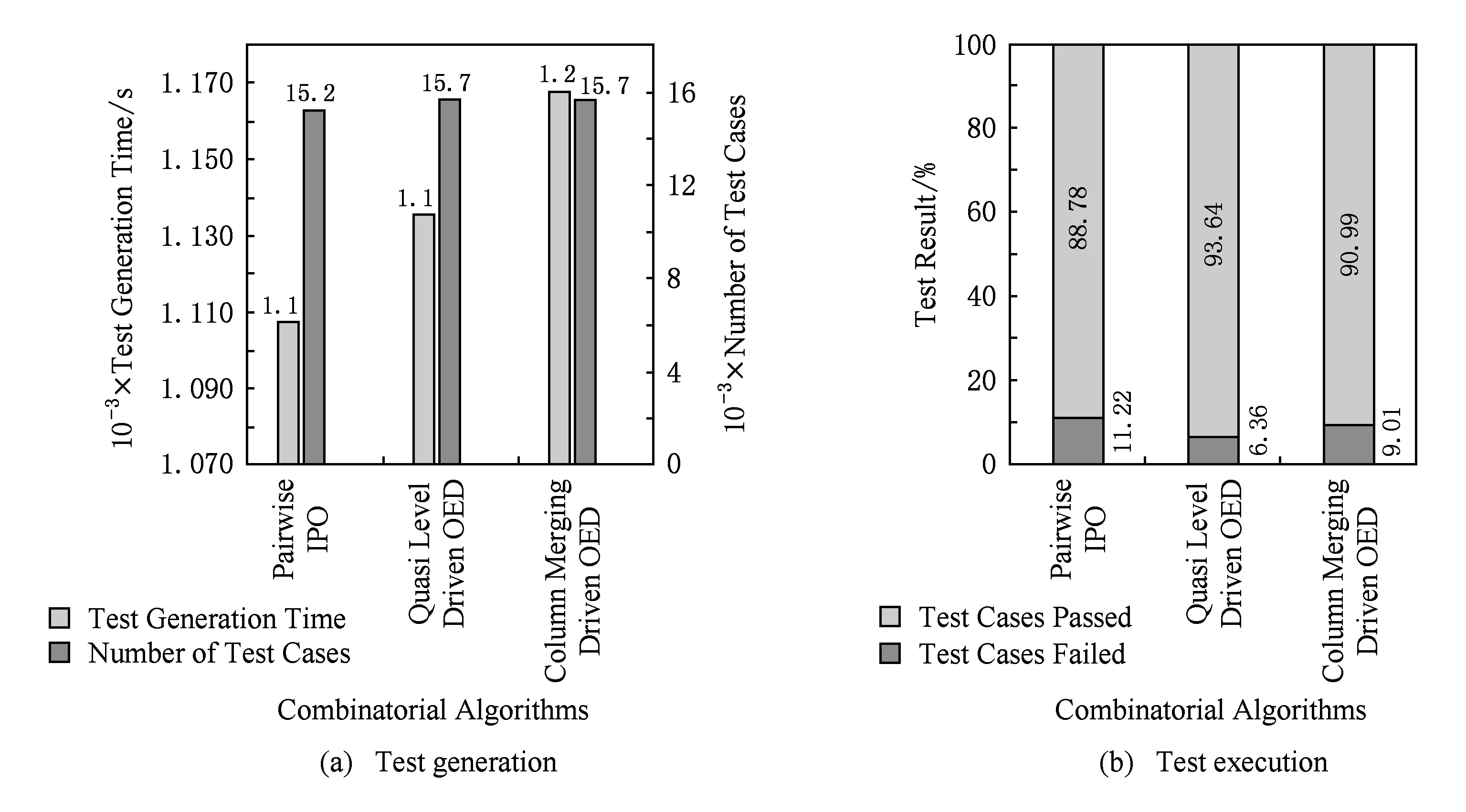
Fig. 16 Statistics of test of GeoService图16 GeoService测试生成与执行统计
图15(a)、图16(a)、图17(a)为使用AutoTest为HolidayService,GeoService,CurrencyService生成测试用例集的时间和数量统计结果,可以发现,AutoTest能够在短时间内为真实Web服务接口快速生成大量测试用例,极大地节约了测试成本,在解放人力的同时有效避免了手动生成测试用例时的繁琐和易错.
图15(b)、图16(b)、图17(b)为访问Web服务HolidayService,GeoService,CurrencyService,执行测试用例的结果统计,可以发现,由本文自动化测试工具AutoTest生成的测试用例具有可执行性并且具有发现接口错误的能力.同时,基于IPO2组合生成的测试用例具有最高的错误发现比率,基于并列法的正交实验设计算法次之,基于拟水平法的正交实验设计算法相对最低.这是因为这3个服务接口可能包含的错误基本上是单点或者是2组合的,因此决策表规模更小、生成测试用例数量更少的IPO2组合算法优势更为明显.通过解析CurrencyService未通过的测试用例发现,该服务接口具有不稳定性,会不定时出现“Service provider response status error”的错误,因此图17(b)所示未能满足上述规律.
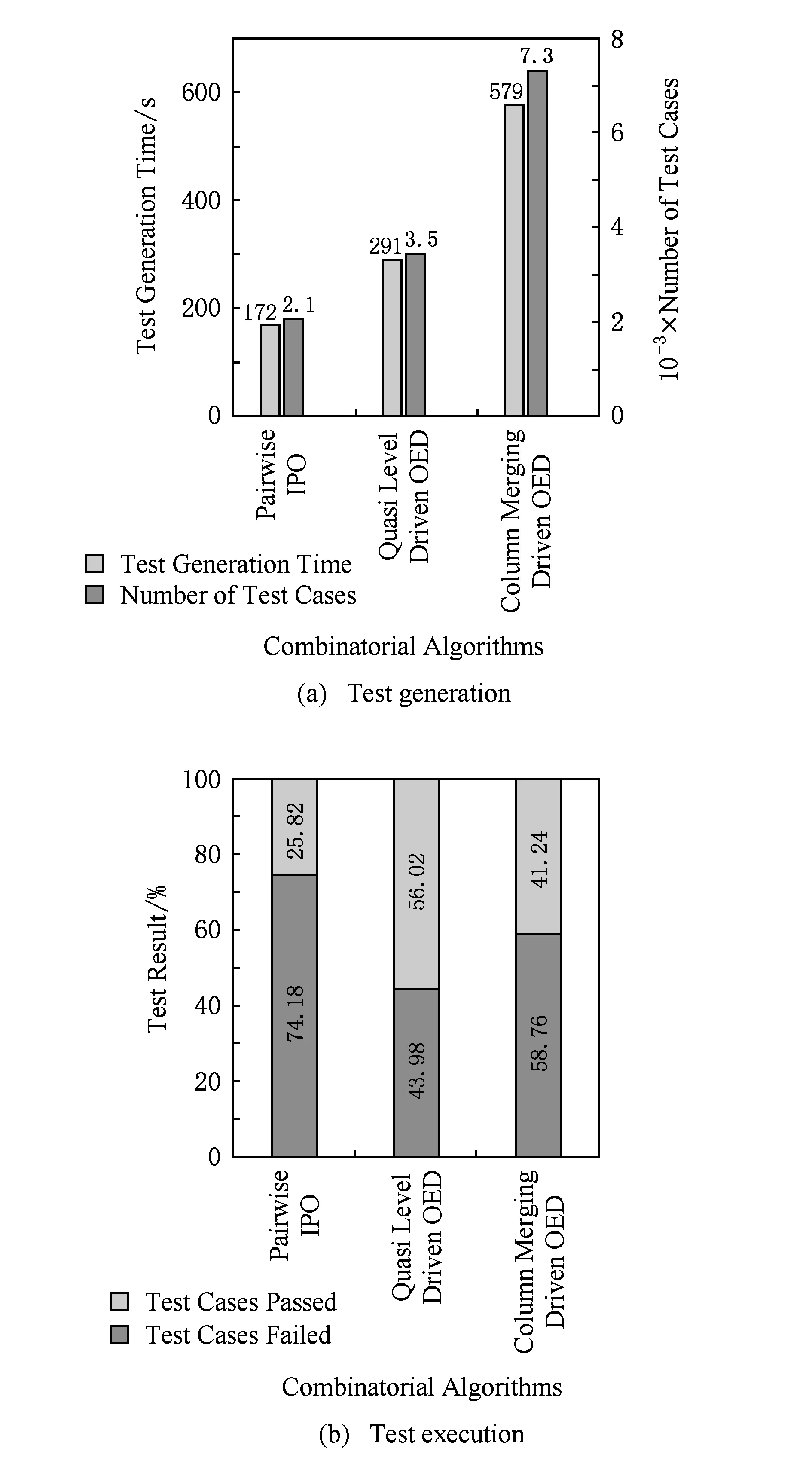
Fig. 15 Statistics of test of HolidayService图15 HolidayService测试生成与执行统计
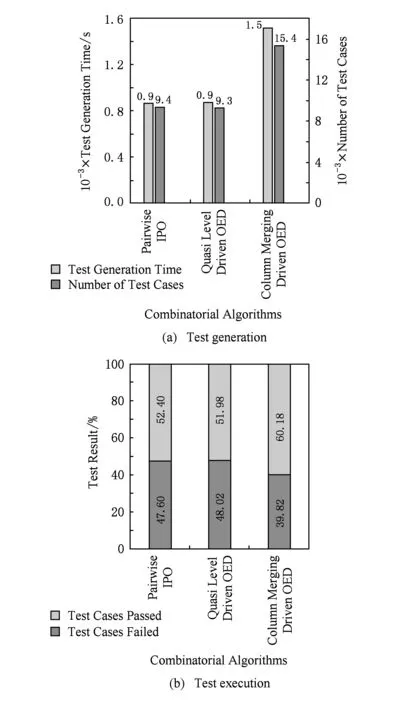
Fig. 17 Statistics of test of CurrencyService图17 CurrencyService测试生成与执行统计
通过解析HolidayService未通过的测试用例,发现了该Web服务未对输入的合法性进行检测,例如向该服务输入包含非数字字符的日期,服务仍能返回是否为节假日的查询结果,未对此类错误作异常处理;同时,发现该Web服务未对输入的日期有效性进行检测,即未对闰年、年月日值域等进行识别,导致服务在此类错误输入下仍能进行是否为节假日查询,出现错误的查询结果.
通过解析GeoService未通过的测试用例,发现该服务未对经纬度以及坐标系的非法输入进行检测,导致服务在此类错误输入下仍能返回查询成功的结果,未能向用户提供正确的服务执行结果.
4 相关工作
4.1 服务测试
近年来,对服务测试的研究工作涉及多个研究方向[12-14],包括测试建模、测试数据生成等.
1) 基于契约的测试设计.Bertolino等人[15]使用UML2.0协议状态机(PSM)增强了网络服务描述语言(Web service description language, WSDL)的描述能力,特别是其中的前置、后置条件和数据、进程约束,为用户验证不同条件下服务的可使用性提供了支持.Heckel等人[16]为基于XML的服务协议定义了基于XML的契约描述语言,扩展了此类服务协议的信息表达,通过使用图形转换规则修正基于UML的概念模型,从而实现了对契约的可视化展示.Bruno等人[17]使用测试用例来刻画服务契约.测试用例由服务提供商给定,并且可被用户用来进行回归测试,追踪服务在在线演化过程中功能和非功能特性的变化.基于契约的设计思想有助于服务提供商和用户形成对服务的一致理解,为二者的合作达成奠定基础.本文在设计服务模型时借鉴了基于契约的设计思想,并使用基于语义的知识表达技术进行辅助刻画,丰富了数据的表达含义,获得了更加全面的服务数据描述.
2) 组合服务测试.一般情况下,组合服务的方式有2种:一种是编制,另一种是编排.在编制方式下,存在一个主服务,该服务负责协调剩余的其他各个服务,使它们能够有条不紊地执行.然而,在编排方式下,所有的服务均具有平等的地位,它们彼此协同合作实现统一的功能.BPEL是描述编制方式的主流语言.Ni等人[18]通过捕获WS-BPEL描述的消息序列信息,包括顺序信息和约束信息,形成服务的消息序列图(MSG),并以此图为基础生成消息序列.Ilieva等人[19]开发出了一个健壮的测试框架—TASSA.该框架将使用BPEL语言描述的编制服务作为测试目标,同时在其具体实现中考虑了故障注入机制.Bentakouk等人[20]使用符号转换系统为WS-BPEL构建模型,并通过符号执行生成所需的测试用例.WS-CDL和WSCI是描述编排方式的2种语言.在编排方式下,服务之间通过交换消息实现信息交流.该过程中的数据流由XPaths进行刻画.Mei等人[21]提出了使用XPath重写图(XPGs)来描述XPath 和XML模式之间的映射关系.经过XPGs增强的标签转换系统能够更好地描述编排方式下各个服务的协同合作过程.Wieczorek等人[22]开发出了一个测试套件生成器,其中包括 Event-B和ProB.Event-B是该生成器的输入模型,由消息编排模型转化得来(MCMs);ProB是该生成器的模型检验器.本文的组合测试基于编排方式,采用可视化技术实现了对业务流程的灵活定制,从而可以更快地响应不断改变的业务测试需求.
4.2 组合测试
组合测试(combinatorial testing)是一种高效的以规约技术为基础的测试生成方法,其目的是用于检测被测软件中由少量参数组合交互所引发的一系列缺陷.Kuhn等人[23]通过实证研究证明了,绝大部分软件缺陷的发生仅与少量参数的组合具有相关性,从而组合测试能够在确保缺陷检出率的同时有效缩减测试用例集的规模.近年来,组合测试获得了国内外许多研究学者的关注,多种组合测试算法被提出.这些算法可被大致归纳为3类,分别是代数构造算法、贪心算法以及启发式搜索算法[24-25].目前,组合测试已被广泛成功地应用于学术界和工业界.
1) 代数构造算法.基于正交表的正交实验设计算法能够在极短的时间内为被测软件快速生成测试用例,并且,在部分情形下能够产生具有最优覆盖的测试用例集合.Mandl[26]将该算法应用于Ada编译器的测试中,Brownlie等人[27]基于该算法设计并实现了OATS工具.正交实验设计算法会额外地生成一些测试用例用以确保其所基于的正交表的正交性,这无疑会增加软件测试的成本,Williams等人[28]将组合数学中使用频繁的递归构造思想引入正交实验设计算法中,为改善上述问题提供了一种实用方案,同时,设计并实现了TConfig工具.该工具的优点是其适用范围广泛,并且具有较快的运行速度,缺点是其输出的测试用例数量通常过于庞大.本文实现了经典的代数构造组合测试算法——基于拟水平法和并列法的正交实验设计算法,和全组合算法相比,能够在有效降低生成的决策表规模的同时确保组合覆盖率,对于测试工具而言具有实用价值.
2) 贪心算法.one-test-at-a-time是一种典型的一维扩展算法,它遵循贪心策略,每次增添1个能够覆盖最多尚未覆盖组合的测试用例,直至全部组合均被覆盖.目前,基于该算法设计并实现的组合测试用例生成算法和工具有很多.Cohen等人[29]设计实现了商业测试工具AETG,但由于该工具将随机技术引入其测试生成过程中,因此最终获得的测试用例集具有不确定性.Tung等人[30]提出的TCG算法,通过对参数值域进行排序确保获得具有确定性的测试用例集.微软公司研发的工具PICT[31],通过固定随机种子确保其获得的测试用例集的确定性,但该工具现阶段只能适用于2组合测试场景中.Bryce等人[32]提出的基于密度的DDA算法,以参数密度为参照排序各个参数的取值顺序,因此其所获得的测试用例集不仅规模较小,还兼具确定性,但该算法也仅能在2组合测试情形下适用.史亮等人[33]针对2组合测试问题提出了基于解空间树的PSST算法,该算法能够在某些输入下得到具有最优覆盖的测试用例集.Lei等人[34]提出的IPO是一种典型的2维扩展算法,该算法初始为被测软件的前2个参数构建满足全组合覆盖的测试用例集,之后逐个添加参数并从水平和垂直2个维度对该测试用例集进行扩展,重复执行该二维扩展过程,直到所构建的测试用例集覆盖全部参数的两两组合.IPO算法通过复用先前生成的测试用例集来构建新的测试用例集,这使得它在面对参数数量或者参数取值频繁更新的被测软件时总能保持较高的测试用例生成速度.Lei等人后来对仅满足2组合覆盖的IPO算法进行扩展获得了可满足N组合覆盖的IPOG算法,同时基于该算法设计并实现了测试工具FireEye[35].本文实现了经典的贪心组合测试算法——IPO2组合算法,和正交实验设计算法相比,可进一步降低生成的决策表规模,并确保2组合的全覆盖.由于软件失效大多数是发生在单点故障和2组合故障中,极少是由更多组合同时出现故障引起的,因此,对测试工具而言实现该算法具有实用价值.
3) 启发式搜索算法.常见的启发式搜索算法有模拟退火算法、禁忌搜索算法、遗传算法等.与代数构造算法和贪心算法相比较,启发式搜索算法在测试用例生成过程中引入了各式各样的启发式策略,规避了算法陷入局部最优的可能性,从而可能得到具有更优覆盖的测试用例集合.然而,绝大多数基于启发式策略的算法需要多次,同时变换多个覆盖矩阵,导致测试用例生成时间过长[24].当前,此类算法仍处于研究阶段.
本文并不仅局限于IPO2组合算法以及基于拟水平法和并列法的正交实验设计算法的实现,工具提供了开放的接口,可以根据被测软件的应用背景和测试需求,灵活选取适用的组合测试算法进行测试生成.
4.3 接口(API)测试
在软件设计中采用接口的形式提供功能实现是一种普遍现象,单个接口中存在的缺陷在软件执行时很容易四处扩散,进而导致大规模的软件故障.因此,接口测试对于确保软件的质量和可靠性至关重要.Shelton等人[36]借助测试自动化框架——Ballista对Win32 APIs在不同操作系统的各个版本上的执行健壮性和可靠性进行了测试评估.Hoffman等人[37]设计并实现了针对JavaAPI的测试工具Roast,该工具首先为接口生成边界值,之后组合边界值生成测试用例.在2个Java组件中执行测试用例的实验结果证明了该工具具有可行性和有效性.然而,该工具也存在不足之处:1)没有可视化界面,用户体验不友好;2)测试设计没有考虑接口的语义信息,测试充分性不足.Jorgensen等人[38]提出将马尔可夫模型和等价类划分方法进行结合为API生成测试用例,并对Windows平台上的C++APIs进行了实测.该方法的不足之处在于它是一种人工密集型的测试方法,测试成本过高.McCaffrey在文献[39]中对.NET环境下的自动化API测试技术和原理进行了介绍.Kim等人[40]提出的REMI技术能够预测识别出具有高风险性的API,进而在测试阶段将更多的资源分配给此类API的测试.当面对有限的测试时间和测试资源,大量的被测API时,该项技术具有重要意义.
与上述大部分接口测试研究工作关注单个接口的测试不同,本文实现了对单个接口和多个组合接口的测试生成,并且基于ISC模型获得了对接口更加充分的描述、采用划分数据分区和组合测试算法在有效减少生成的测试用例数量的同时确保了测试覆盖率.
5 总 结
本文针对现有服务接口测试方法中存在的接口模型表述能力有限、测试数据覆盖率不够充分、用例自动生成欠缺灵活性等问题提出了基于语义的服务接口测试方法.该方法以模型驱动自动化测试方法为基础,借鉴基于语义的知识表达技术和基于契约的设计思想,解析服务相关的数据信息和操作行为,构建基于ISC的数据模型和服务模型用于描述单个服务;通过组合多个不同服务的测试用例集,定义服务间的依赖关系,构造基于ISC的计划模型描述更为复杂的业务场景.同时,本文提出通用用例元模型的概念,用于多种测试用例代码的自动生成,丰富了测试用例的表现形式.
基于ISC模型,本文设计并实现了一个自动化测试工具——AutoTest.实验表明,AutoTest能够快速为单个服务和组合服务生成大量测试用例,并且所生成的测试用例具有理想的覆盖率.同时,所构建的ISC模型可被不断复用,这为面向服务测试中最常进行的回归测试提供了极大的便利.
[1]Hou Kejia, Bai Xiaoying, Lu Hao, et al. Web service test data generation using interface semantic contract[J]. Journal of Software, 2013, 24(9): 2020-2041 (in Chinese)(侯可佳, 白晓颖, 陆皓, 等. 基于接口语义契约的Web服务测试数据生成[J]. 软件学报, 2013, 24(9): 2020-2041)
[2]Hou Kejia. Research on test automation for software as a service based on interface semantic contract[D]. Beijing: Tsinghua University, 2015 (in Chinese)(侯可佳. 基于接口语义契约的服务化软件自动测试技术研究[D]. 北京: 清华大学, 2015)
[3]Tsai W T, Bai Xiaoying, Huang Yu. Software-as-a-service (SaaS): Perspectives and challenges[J]. Science China: Information Sciences, 2014, 57(5): 1-15
[4]Belli F, Endo A T, Linschulte M, et al. A holistic approach to model-based testing of Web service compositions[J]. Software: Practice and Experience, 2014, 44(2): 201-234
[5]Bai Xiaoying, Lu Hao, Zhang Yao, et al. Interface-Based automated testing for open software architecture[C] //Proc of the 35th Annual Computer Software and Applications Conf Workshops. Piscataway, NJ: IEEE, 2011: 149-154
[6]Bai Xiaoying, Hou Kejia, Lu Hao, et al. Semantic-Based test oracles[C] //Proc of the 35th Annual Computer Software and Applications Conf. Piscataway, NJ: IEEE, 2011: 640-649
[7]Lee Shufang, Bai Xiaoying, Chen Yinong. Automatic mutation testing and simulation on OWL-S specified Web services[C] //Proc of the 41st Annual Simulation Symp. Piscataway, NJ: IEEE, 2008: 149-156
[8]Dai Guilan, Bai Xiaoying, Wang Yongbo, et al. Contract-based testing for Web services[C] //Proc of the 31st Annual Int Computer Software and Applications Conf. Piscataway, NJ: IEEE, 2007: 517-526
[9]Bai Xiaoying, Lee Shufang, Tsai W T, et al. Ontology-based test modeling and partition testing of Web services[C] //Proc of the Int Conf on Web Services. Piscataway, NJ: IEEE, 2008: 465-472
[10]Dalal S R, Jain A, Karunanithi N, et al. Model-based testing in practice[C] //Proc of the 21st Int Conf on Software Engineering. New York: ACM, 1999: 285-294
[11]The Apache Software Foundation. The Apache Velocity Project[EB/OL]. [2014-07-01]. http: //velocity.apache.org/
[12]Canfora G, Di Penta M. Service-oriented architectures testing: A survey[M] //Software Engineering. Berlin: Springer, 2009: 78-105
[13]Bozkurt M, Harman M, Hassoun Y. Testing Web services: A survey, TR-10-01[R]. London: Department of Computer Science, King’s College, 2010
[14]Rusli H M, Puteh M, Ibrahim S, et al. A comparative evaluation of state-of-the-art Web service composition testing approaches[C] //Proc of the 6th Int Workshop on Automation of Software Test. New York: ACM, 2011: 29-35
[15]Bertolino A, Frantzen L, Polini A, et al. Audition of Web services for testing conformance to open specified protocols[C] //Proc of the Int Conf on Architecting Systems with Trustworthy Components. Berlin: Springer, 2006: 1-25
[16]Heckel R, Lohmann M. Towards contract-based testing of Web services[J]. Electronic Notes in Theoretical Computer Science, 2005, 116: 145-156
[17]Bruno M, Canfora G, Di Penta M, et al. Using test cases as contract to ensure service compliance across releases[C] //Proc of the Int Conf on Service-Oriented Computing. Berlin: Springer, 2005: 87-100
[18]Ni Yitao, Hou Shanshan, Zhang Lu, et al. Effective message-sequence generation for testing BPEL programs[J]. IEEE Trans on Services Computing, 2013, 6(1): 7-19
[19]Ilieva S, Manova D, Manova I, et al. An automated approach to robustness testing of BPEL orchestrations[C] //Proc of the Service Oriented System Engineering. Piscataway, NJ: IEEE, 2011: 193-203
[20]Bentakouk L, Poizat P, Zaïdi F. A formal framework for service orchestration testing based on symbolic transition systems[C] //Proc of the 21st IFIP WG 6.1 Int Conf on Testing of Software and Communication Systems and 9th Int FATES Workshop. Berlin: Springer, 2009: 16-32
[21]Mei Lijun, Chan W K, Tse T H. Data flow testing of service choreography[C] //Proc of the 7th Joint Meeting of the European Software Engineering Conf and the ACM SIGSOFT Symp on the Foundations of Software Engineering. New York: ACM, 2009: 151-160
[22]Wieczorek S, Kozyura V, Roth A, et al. Applying model checking to generate model-based integration tests from choreography models[C] //Proc of the 21st IFIP WG 6.1 Int Conf on Testing of Software and Communication Systems and 9th International FATES Workshop. Berlin: Springer, 2009: 179-194
[23]Kuhn D R, Wallace D R, Gallo A M. Software fault interactions and implications for software testing[J]. IEEE Trans on Software Engineering, 2004, 30(6): 418-421
[24]Yan Jun, Zhang Jian. Combinatorial testing: Principles and methods [J]. Journal of Software, 2009, 20(6): 1393-1405 (in Chinese)(严俊, 张健. 组合测试: 原理与方法[J]. 软件学报, 2009, 20(6): 1393-1405)
[25]Chen Xiang, Gu Qing, Wang Xinping, et al. Research advances in interaction testing [J]. Computer Science, 2010(3): 1-5 (in Chinese)(陈翔, 顾庆, 王新平, 等. 组合测试研究进展[J]. 计算机科学, 2010 (3): 1-5)
[26]Mandl R. Orthogonal Latin squares: An application of experiment design to compiler testing[J]. Communications of the ACM, 1985, 28(10): 1054-1058
[27]Brownlie R, Prowse J, Phadke M S. Robust testing of AT&T PMX/StarMAIL using OATS[J]. AT&T Technical Journal, 1992, 71(3): 41-47
[28]Williams A W. Determination of test configurations for pair-wise interaction coverage[M] //Testing of Communicating Systems. New York: Springer, 2000: 59-74
[29]Cohen D M, Dalal S R, Fredman M L, et al. The AETG system: An approach to testing based on combinatorial design[J]. IEEE Trans on Software Engineering, 1997, 23(7): 437-444
[30]Tung Y W, Aldiwan W S. Automating test case generation for the new generation mission software system[C] //Proc of the Aerospace Conf. Piscataway, NJ: IEEE, 2000, 1: 431-437
[31]Czerwonka J. Pairwise testing in the real world: Practical extensions to test-case scenarios[EB/OL]. [2016-01-20]. https: //msdn.microsoft.com/en-us/library/cc150619.aspx
[32]Bryce R C, Colbourn C J. The density algorithm for pairwise interaction testing[J]. Software Testing Verification and Reliability, 2007, 17(3): 159-182
[33]Shi Liang, Nie Changhai, Xu Baowen. Pairwise test data generation based on solution space tree[J]. Chinese Journal of Computers, 2006, 29(6): 849-857 (in Chinese)(史亮, 聂长海, 徐宝文, 等. 基于解空间树的组合测试数据生成[J]. 计算机学报, 2006, 29(6): 849-857)
[34]Lei Yu, Tai K C. In-parameter-order: A test generation strategy for pairwise testing[C] //Proc of the 3rd High-Assurance Systems Engineering Symp. Piscataway, NJ: IEEE, 1998: 254-261
[35]Lei Yu, Kacker R, Kuhn D R, et al. IPOG: A general strategy for t-way software testing[C] //Proc of the 14th Annual IEEE Int Conf and Workshops on the Engineering of Computer-Based Systems. Piscataway, NJ: IEEE, 2007: 549-556
[36]Shelton C P, Koopman P, DeVale K. Robustness testing of the Microsoft Win32 API[C] //Proc of the Int Conf on Dependable Systems and Networks. Piscataway, NJ: IEEE, 2000: 261-270
[37]Hoffman D, Strooper P. Tools and techniques for Java API testing[C] //Proc of the Software Engineering Conf. Piscataway, NJ: IEEE, 2000: 235-245
[38]Jorgensen A, Whittaker J A. An API testing method[C/OL] //Proc of the Int Conf on Software Testing Analysis & Review (STAREAST). [2016-01-20]. https: //www.cmcrossroads.com/sites/default/files/article/file/2014/Application%20Program %20Interface%20(API)%20Testing%20Method.pdf
[39]McCaffrey J D. API test automation in .NET[J]. MSDN Magazine, 2004, 19(11): 29-34
[40]Kim M, Nam J, Yeon J, et al. REMI: Defect prediction for efficient API testing[C] //Proc of the 10th Joint Meeting on Foundations of Software Engineering. New York: ACM, 2015: 990-993
