基于跨连接LeNet-5网络的面部表情识别
2018-03-10林小竹蒋梦莹
李 勇 林小竹 蒋梦莹
随着计算机的快速发展,人机交互越来越多地出现在日常生活中,如何让计算机更好地理解人类的心理是人机交互必须要解决的问题.人的面部表情中包含丰富的信息,研究指出,面部表情可以比动作和语言更好地表达人类的心理活动[1],面部表情识别也因此成为了人机交互中不可或缺的部分.一个普通人可以很好地读取别人的面部表情并做出相应的判别,但对于计算机来说这是一项十分困难的任务,为此大量的专家学者投入到该领域的研究中来.面部表情是一个十分复杂的系统,各国研究者们构建了不同的模型来实现表情分类,其中最具代表性的就是Ekman等[2]在1978年提出了面部动作编码系统(Facial action coding system, FACS),随后在1984年根据不同动作单元的组合定义了6种基本的表情:生气、厌恶、开心、悲伤、惊讶、恐惧.研究者们据此构建了不同的表情库,其中日本的JAFFE公开库就是采用这六种基本表情构建的表情库,并且在此基础上增加了第7类表情:无表情.卡耐基梅隆大学的Lucey等[3]于2010年在Cohn-Kanade dataset的基础上发布了The extended Cohn-Kanade dataset(CK+),这个库中包括了123个人的593个视频序列,其中有327个序列是包含表情标签的序列,该库中的表情除了6种基本的表情以外增加了蔑视和无表情两种.进入上世纪90年代以后,面部表情识别与分析迅速发展起来,研究者们提出了不同的算法来提高识别的准确率,主要的方法有两种:1)是基于几何的方法,例如Lanitis等[4]采用几何特征方法进行识别,该方法是通过标记人眼、口、鼻等特征点,计算其相对位置来识别表情,虽然这种方法大大减少了输入的数据,但是仅用有限的点来表示复杂的人脸表情显然会丢失很多重要的信息,因而整体的识别率并不太高;2)是基于整体的识别方法,例如Praseeda等[5]使用Gabor小波和SVM相结合的方式进行面部表情识别,首先用Gabor滤波器对表情图像滤波、提取特征,将提取到的特征用于SVM训练,训练分类器进行表情的分类识别,这种方法同样依赖于前期人工提取特征的优劣,人为干扰因素较大.近年来,随着计算机运行速度的提高,处理大数据成为可能,同时互联网的快速发展,研究者采集大量的数据变得相对容易,在此基础上,深度卷积神经网络被证实了在图像识别领域有巨大的优势.Krizhevsky等[6]于2012年在ImageNet图像数据集上使用AlexNet卷积神经网络结构取得惊人的成绩,其识别率远超传统的识别方法.这个数据集包含约120万张训练图像、5万张验证图像和10万张测试图像,分为1000个不同的类别,传统的特征提取方法被网络结构取代,网络可以自行提取特征并分类而不需要人工干预.
1 深度学习与卷积神经网络
2006年,机器学习领域泰斗Hinton与他的学生在Science上发表的文章[7]掀起了深度学习研究的浪潮,多隐层的神经网络再次回到人们视野之中.在那以后,斯坦福大学、纽约大学、蒙特利尔大学等名校迅速成为深度学习研究的重要场所,甚至美国国防部DARPA计划也首次资助了深度学习项目[8].卷积神经网络作为深度学习的一支,也迅速受到了广泛的关注.现今,深度学习广泛地应用于监控视频事件检测[9]、自然语言处理[10]、语音信号的基音检测[11]、图像分类与识别等领域[12−15].
卷积神经网络虽然是在近年来才受到广泛的关注和应用,但早在1962年Hubel等[16]就通过对猫视觉皮层细胞的研究,提出了感受野(Receptive field)的概念.1984年日本学者Fukushima等[17]基于感受野的概念而提出的神经认知机(Neocognitron)可以看作是第一个实现了的卷积神经网络,这也是感受野概念在人工神经网络领域的首次应用. Le Cun等[18]提出的深度卷积神经网络,就是以神经认知机为基础,并使用了反向传播算法来识别手写数字,后来在1998年正式确定的LeNet-5模型,在文档识别中取得了很好的效果[19],该模型当年成功用于美国大多数银行支票的手写数字识别,是卷积神经网络在工业界最早的应用.Le Cun设计的LeNet-5卷积网络结构图如图1所示.
LeNet-5卷积神经网络可以看成是一个多隐层的人工神经网络,其基本结构主要包括输入层、卷积层、池化层、全连接层和输出层.其中卷积层和池化层会交替出现,构成了特殊的隐层.如图1所示, Input是输入层,输入大小为32像素×32像素的图片,MNIST手写数字库中图片大小为28像素×28像素,所以实际使用时将其扩展为大小为32像素×32像素的图片使用.Layer 1层是卷积层,共有6个特征图,每一副输入为32像素×32像素的图片都与6个不同的大小为5像素×5像素卷积核卷积,得到大小为28像素×28像素的特征图. Layer 2层是池化层,Layer 1中6个大小为28像素×28像素的特征图经过池化后得到6个大小为14像素×14像素的特征图.Layer 3层是卷积层,共有16个大小为10像素×10像素的特征图.每个10像素×10像素的特征图是由前一层的某几个或全部特征图与5像素×5像素的卷积核卷积得到,具体连接方式如表1所示.Layer 4层是池化层,共16个5像素×5像素的特征图,由Layer 3层16个特征图经过池化得到.Layer 5层是卷积层,共有120个1像素×1像素的特征图,每一个特征图都是由Layer 4层所有的特征图与5像素×5像素卷积核卷积得到.Full层是全连接层,共有84个单元,Layer 6层与Layer 5层为全连接关系.Output层是输出层,输出分类结果.
不同于传统的神经网络,卷积神经网络采取的是局部连接(Locally-connection)的方式,不仅有效地减少了与神经元连接的参数个数,而且在误差反向传播过程中,让梯度在一个较小的广度范围内传播[20],使得训练变得更加容易.权值共享也是卷积神经网络的一个特点,对于输入图像的每一个小块,用相同的卷积核进行卷积操作,这种方法来源于局部感受野的概念,可以使得图像具有平移不变性.最后,卷积神经网络中的池化操作,就是一次下采样操作,将相邻的几个像素点用一个像素点代替,根据采样方法的不同分为Max-pooling和Avg-pooling,该操作可以使图片具有一定的缩放不变性.

图1 LeNet-5结构图Fig.1 The LeNet-5 convolutional neural network
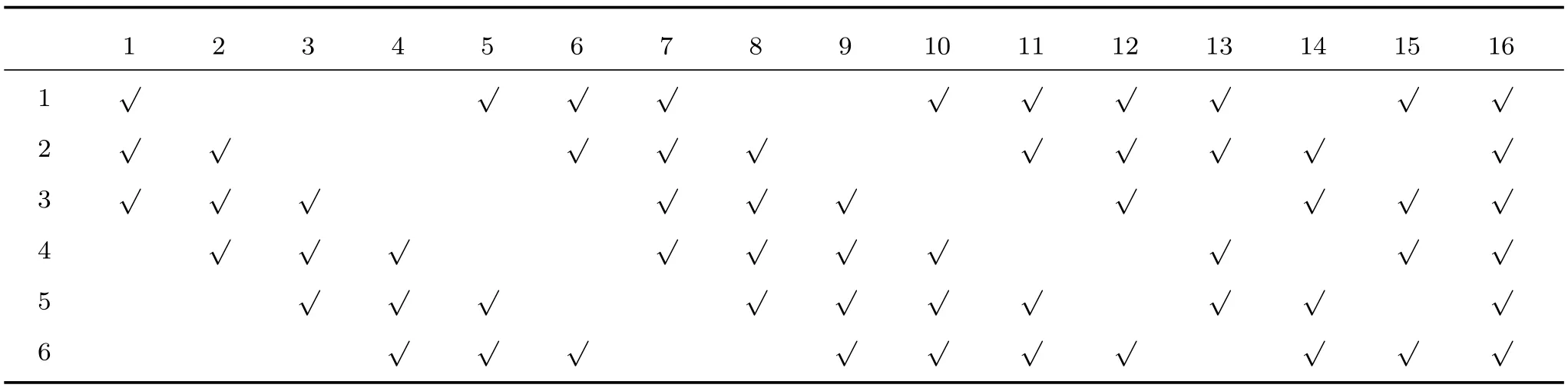
表1 LeNet-5网络Layer 2与Layer 3之间的连接方式Table 1 Connection between LeNet-5 network′s Layer 2 and Layer 3
2 改进的LeNet-5网络
LeNet-5卷积神经网络是通过不同的卷积核自行提取特征,将原始数据经过一些简单的非线性的模型转变为更高层次的、更加抽象的表达,最终使用高层次的特征进行分类识别.然而这种分类方法没有考虑到低层次的细节特征,而且随着网络深度加深,网络训练的困难程度在增加,尤其是梯度消失或爆炸问题[21],为了能够解决深层网络的训练问题,研究者提出了跨层的连接方式.早期训练的多层感知机通常将输入作线性变换后加到输出上[22],近年来Srivastava等[23]提出了一种新的网络连接结构Highway networks,该结构主要特点是提供了一种门限机制,一部分的特征不需要经过处理直接通过某些网络层,该结构更加容易优化,并且在CIFAR-10数据集上表现优于Romero等[24]提出的FitNets.而He等[25]提出的深度残差网络同样在标准的前馈卷积网络上,增加了一些跨层的连接,目的也是为了降低训练的难度,该结构不仅在层数上刷新了记录,而且在ImageNet和COCO几个主要的任务中都取得了优异的成绩.Sun等[26]提出的DeepId网络中也有设计将最后的池化层和卷积层与全连接层相连,张婷等[27]提出的跨连的卷积神经网络(Cross-connected convolutional neural net-work,CCNN)可以有效地将低层次特征与高层次特征结合起来,构造出更好地分类器,在性别分类中取得了不错的结果.本文在LeNet-5的结构基础上引入跨连的思想,将LeNet-5网络的两个池化层与全连接层相结合用于最后的分类器构造中.
虽然LeNet-5在手写数字集上取得了巨大的成功,但是将该结构用于表情识别时却难以得到理想的结果,本文提出了改进的LeNet-5结构如图2所示,包括一个输入层、3个卷积层、2个池化层、一个全连接层和一个输出层.网络输入是32像素×32像素的图片,经过卷积池化操作后将前两个池化层与全连接层结合起来作为softmax分类器的输入,最终获得7种表情的分类输出.表2为各层的网络参数.
整个网络的训练过程分为正向传播和反向传播,其中正向传播过程就是隐层提取特征的过程,主要是卷积和池化操作.反向传播采用BP反向传播算法传递误差,使用随机梯度下降算法,更新权值参数.给定输入,整个网络的计算过程如下:
1)对于卷积层输入X,卷积过程
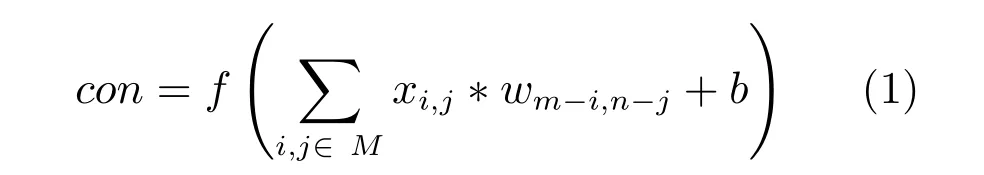
其中,x表示输入X中卷积区域M中的元素,w表示卷积核中的元素,m,n表示卷积核的大小,b表示偏置,f(·)表示ReLU激活函数.卷积核大小及卷积步长如表2所示.

图2 改进的LeNet-5卷积神经网络Fig.2 Improved LeNet-5 convolutional neural network
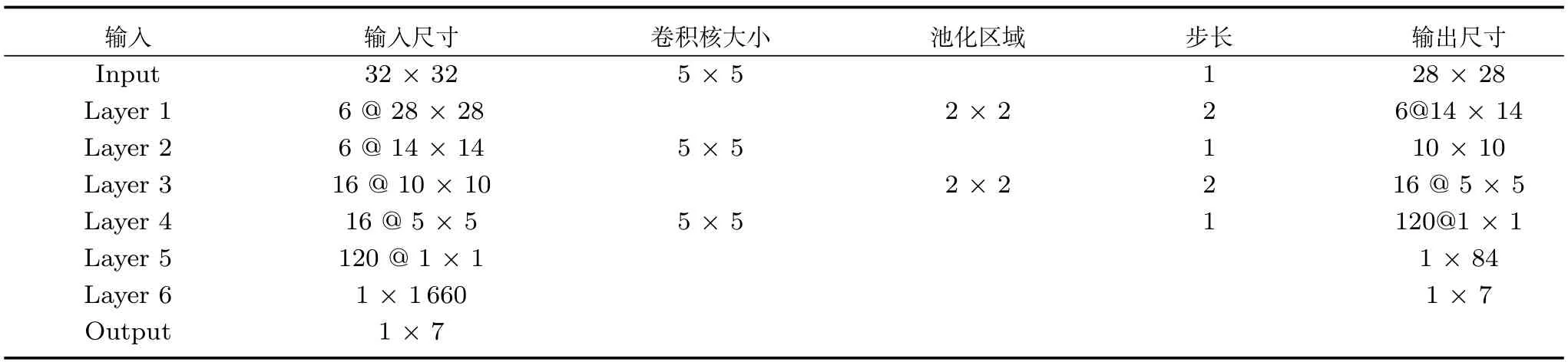
表2 卷积网络参数Table 2 Convolutional network parameters
2)对于池化层输入Y,池化过程

其中,y表示池化层输入Y中池化区域p中的元素,down(·)是下采样过程,保留池化区域中的最大值.池化区域大小及步长如表2所示.
3)对于全连接层输入Z

其中,z表示输入Z中的元素,w表示权值,b表示偏置,f(·)表示ReLU激活函数.
4)对于输出层输入X
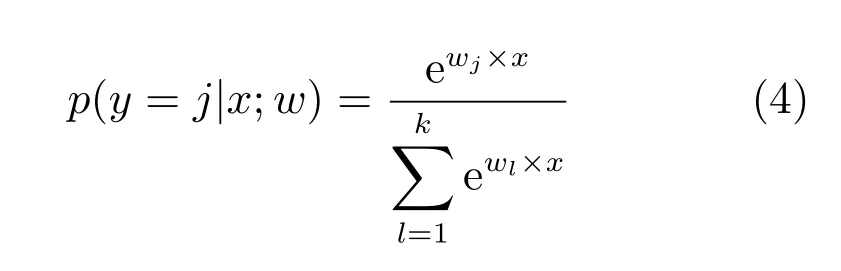
式(4)为Softmax分类器的假设函数,计算的是输入分类为类别j时的概率,w是权值参数,k为总的类别数.其损失函数为
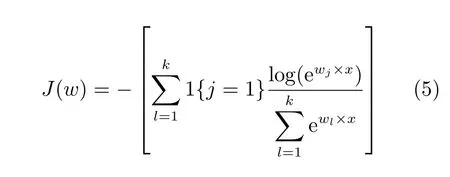
其中,1{·}是示性函数,1{值为真的表达式}=1, 1{值为假的表达式}=0.
反向传播过程如下:输入样本得到实际输出之后首先需要计算每一层的反馈传递误差
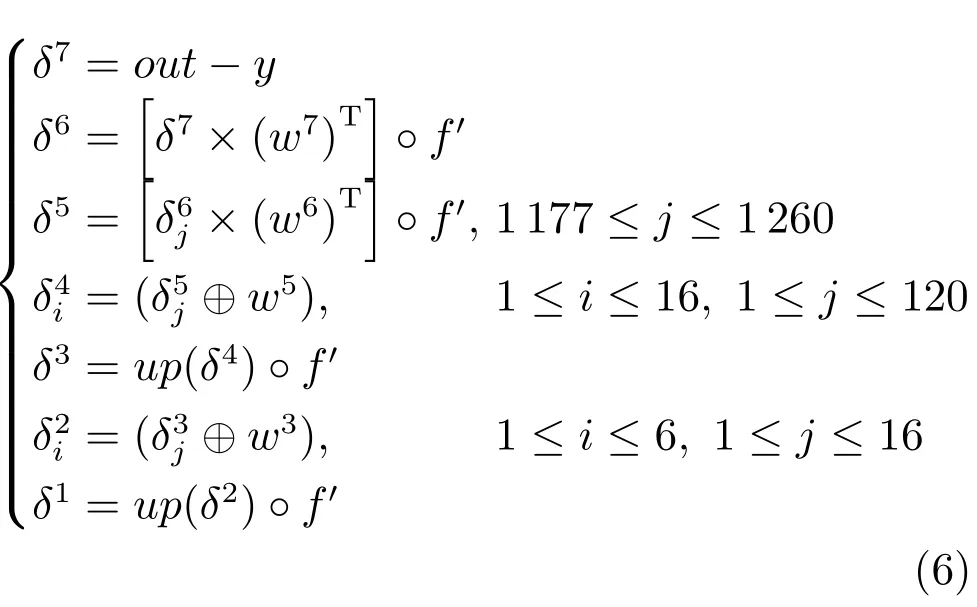
式(6)为网络各层的反馈传递误差,式中符号◦表示矩阵或向量中对应的元素相乘.参考图2可知,δ7是输出层(Output)的反馈传递误差,out表示网络的实际输出,y表示网络的目标输出.δ6是Layer 6层的反馈传递误差,w7是Layer 6与输出层之间的权值.本算法采用的是ReLU激活函数,f′表示ReLU激活函数的导数.全连接层是由跨连接组合而成,Layer 5层只与该层中(1177≤i≤1260)部分连接,故误差传递时只需使用δ6(1177≤j≤1260)参与计算,式中δ5是Layer 5层的反馈传递误差,w6是Layer 5与Layer 6之间的权值.δ4i是Layer 4层第i个特征图对应的反馈传递误差,w5是Layer 4与Layer 5之间的卷积核,对于每一个δ4i,都是将δ5j(1≤j≤120)与w5进行外卷积得到,⊕表示的是外卷积操作,参考文献[27]定义外卷积与内卷积如下:假设有A和B两个矩阵,大小分别为M×N,m×n,其中M,N≥m,n.内卷积C=A⊙B,C中所有元素

其中,1≤i≤M−m+1,1≤j≤N−n+1.外卷积定义为
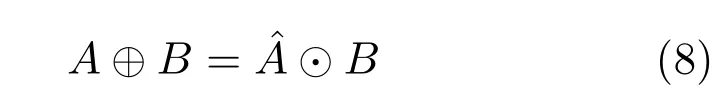
δ3是Layer 3层的反馈传递误差,up(·)是一个上采样操作,同时需要乘以激活函数的导数.δ2i是Layer 2层的反馈传递误差,它的计算过程与Layer 4层相似,每个δ2是由δ3(1≤j≤16)与w3进行外卷积得到,不过这里要注意Layer 2与Layer 3之间的连接方式,具体可参见表2.δ1是Layer 1层的反馈传递误差,与Layer 3层类似.
计算权值和偏置的偏导数:
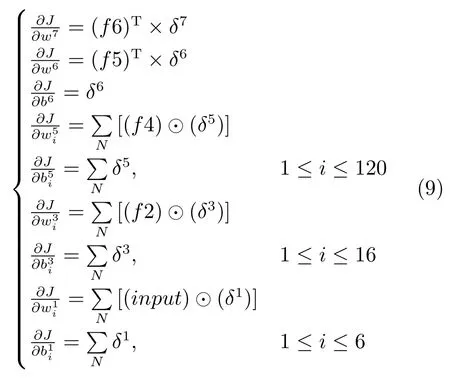
式(9)即为各层权值和偏置的偏导数,其中f6为Layer 6的特征图,以此类推,f5、f4、f2分别为对应层的特征图,input是输入图像.式中⊙表示内卷积操作,定义见式(7).
对于训练集S={xl,yl}算法流程如下:
1)确定迭代次数、网络结构、学习步长,随机初始化卷积核以及偏置.其中初始学习步长选择为0.005,随着训练次数的增加,测试误差变化较小时,将学习步长除以10,直至学习步长降至0.00005,停止训练.
2)输入样本,正向传播,计算实际输出.
3)优化目标函数,采用反向传播算法计算反馈传递误差.
4)计算参数的修正量.
5)通过梯度下降法更新参数值.
3 实验
本文所有实验均在Matlab7.0上实现,硬件平台为Lenovo Tian-Yi 100:Intel(R)Core(TM)i5-5200u CPU,主频为2.20GHz,内存为4.00GB.
3.1 数据集
本实验分别采用JAF FE表情数据库和CK+数据库进行实验.JAFFE表情数据库包含7种表情,分别属于10名女性,每个人每种表情有2∼4张,共213张图片.图3为7种表情的示例图像.

图3 JAFFE表情库7种表情示例图像Fig.3 7 kinds of facial expression image in JAFFE expression dataset
CK+数据库中有123个人的不同表情序列,为保持一致性,在CK+数据库中也只考虑七种表情,从库中取出七类表情共990幅图片,图4为7种表情示例图像.

图4 CK+表情库7种表情示例图像Fig.4 7 kinds of facial expression image in the CK+ expression dataset
3.2 实验结果及分析
将数据集中图片统一裁剪采样至大小为32像素×32像素,采用交叉验证的方法,将JAFFE数据集中图片分为3份,每次取其中两份为训练数据,另一份为测试数据;将CK+中图片分为5份,每次取其中4份作为训练数据,1份作为测试数据.
表3为本文算法在JAFFE表情库中不同表情的分类结果,表4为本文算法在CK+数据库中不同表情的分类结果.由表3和表4可以看到,在一些测试集上,整个网络表现较好,正确率高,但是在另一些上表现相对较差,其原因可能是训练样本数据中能提取出的表情特征不足,无法获得足够的特征进行训练,导致分类器分类效果较差,这个现象也反映出了样本数据对于卷积神经网络的重要.
表5为不加跨连方式的网络与加了跨连接之后的网络在测试集上的正确率对比.实验过程中,由于样本较少,不加跨连方式的网络训练难度大,参数调整困难,而跨连接网络收敛速度快,训练更容易.由表5可以发现,直接采用LeNet-5网络结构识别正确率很低,不能很好地分类,主要原因是LeNet-5是设计用于手写数字识别,相对于数字而言,面部表情特征更复杂,然而样本数量却更少,仅用高层次特征不足以训练得到好的分类器,本文加入了跨连接的方法后,低层次特征参与最后的分类器的构造后,识别效果显著提高,即使在小样本中也有不错的正确率.由表5还可以发现,同样的结构在JAFFE表情库中得到的正确率高于CK+库中的正确率,原因是JAFFE中只有10名亚洲女性的表情图像,而在CK+中包含了123个不同性别不同肤色的人的表情图像,后者更为复杂,因而需要的样本数量更多,否则难以学习到足够多和足够好的特征进行分类.

表3 JAFFE表情库不同表情的分类正确率(%)Table 3 Classi fi cation accuracy of diあerent expressions in JAFFE expression dataset(%)

表4 CK+数据库不同表情的分类正确率(%)Table 4 Classi fi cation accuracy of diあerent expressions in CK+dataset(%)

表5 网络是否跨连接正确率对比(%)Table 5 Classi fi cation accuracy of the network whether cross connection or not(%)
表6为本文方法与传统非深度学习方法的比较,可以看出,相对于SVM等浅层学习方法,本文算法在JAFFE表情数据上表现较为优异.

表6 不同方法在JAFFE上的对比(%)Table 6 The comparison of diあerent methods on JAFFE(%)
4 结论
卷积神经网络的特点是自动地、隐式地学习特征,不需要人为地定义特征,如果有足够多的样本用于训练,网络可以学习到很好的特征进行分类.相反如果没有足够多的样本进行训练,那么卷积神经网络就不如人为地定义特征能更快地找到样本之间的联系,从而达到好的分类效果.本文在LeNet-5的网络基础上,引入跨连接的方法,设计出新的卷积神经网络结构,将其应用于面部表情识别.实验结果表明,低层次特征的应用可以一定程度上弥补样本数量的不足,获得不错的分类效果.另外,由本次实验可知,卷积神经网络现在没有一种通用的结构可以很好地解决多种问题,在手写数字库上表现非常好的LeNet-5结构在表情识别中表现较差,所以不同的问题需要设计不同的结构来解决问题,这给卷积神经网络的普及带来了一定的困难.
下一步研究计划是寻找各层特征之间的关系,运用反卷积等方法实现卷积神经网络各层特征的可视化,更好地理解各层特征,进而找到更加通用的卷积神经网络结构设计方法.
1 Pantic M,Rothkrantz L J M.Expert system for automatic analysis of facial expressions.Image and Vision Computing, 2000,18(11):881−905
2 Ekman P,Friesen W V.Facial Action Coding System:A Technique for the Measurement of Facial Movement.Palo Alto,CA:Consulting Psychologists Press,1978.
3 Lucey P,Cohn J F,Kanade T,Saragih J,Ambadar Z, Matthews I.The extended Cohn-Kanade dataset(CK+): a complete dataset for action unit and emotion-speci fi ed expression.In:Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops(CVPRW).San Francisco,CA,USA:IEEE, 2010.94−101
4 Lanitis A,Taylor C J,Cootes T F.Automatic interpretation and coding of face images using fl exible models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 1997,19(7):743−756
5 Praseeda Lekshmi V,Sasikumar M.Analysis of facial expression using Gabor and SVM.International Journal of Recent Trends in Engineering,2009,1(2):47−50
6 Krizhevsky A,Sutskever I,Hinton G E.ImageNet classiifcation with deep convolutional neural networks.In:Proceedings of the 25th International Conference on Neural Information Processing Systems,Lake Tahoe,Nevada,USA: NIPS,2012.1097−1105
7 Hinton G E,Salakhutdinov R R.Reducing the dimensionality of data with neural networks.Science,2006,313(5786): 504−507
8 Yu Kai,Jia Lei,Chen Yu-Qiang,Xu Wei.Deep learning: yesterday,today,and tomorrow.Journal of Computer Research and Development,2013,50(9):1799−1804
(余凯,贾磊,陈雨强,徐伟.深度学习的昨天、今天和明天.计算机研究与发展,2013,50(9):1799−1804)
9 Wang Meng-Lai,Li Xiang,Chen Qi,Li Lan-Bo,Zhao Yan-Yun.Surveillance event detection based on CNN.Acta Automatica Sinica,2016,42(6):892−903
(王梦来,李想,陈奇,李澜博,赵衍运.基于CNN的监控视频事件检测.自动化学报,2016,42(6):892−903)
10 Xi Xue-Feng,Zhou Guo-Dong.A survey on deep learning for natural language processing.Acta Automatica Sinica, 2016,42(10):1445−1465
(奚雪峰,周国栋.面向自然语言处理的深度学习研究.自动化学报, 2016,42(10):1445−1465)
11 Zhang Hui,Su Hong,Zhang Xue-Liang,Gao Guang-Lai. Convolutional neural network for robust pitch determination.Acta Automatica Sinica,2016,42(6):959−964
(张晖,苏红,张学良,高光来.基于卷积神经网络的鲁棒性基音检测方法.自动化学报,2016,42(6):959−964)
12 Sui Ting-Ting,Wang Xiao-Feng.Convolutional neural networks with candidate location and multi-feature fusion.Acta Automatica Sinica,2016,42(6):875−882
(随婷婷,王晓峰.一种基于CLMF的深度卷积神经网络模型.自动化学报,2016,42(6):875−882)
13 Wang Wei-Ning,Wang Li,Zhao Ming-Quan,Cai Cheng-Jia, Shi Ting-Ting,Xu Xiang-Min.Image aesthetic classi fi cation using parallel deep convolutional neural networks.Acta Automatica Sinica,2016,42(6):904−914
(王伟凝,王励,赵明权,蔡成加,师婷婷,徐向民.基于并行深度卷积神经网络的图像美感分类.自动化学报,2016,42(6):904−914)
14 Chang Liang,Deng Xiao-Ming,Zhou Ming-Quan,Wu Zhong-Ke,Yuan Ye,Yang Shuo,Wang Hong-An.Convolutional neural networks in image understanding.Acta Automatica Sinica,2016,42(9):1300−1312
(常亮,邓小明,周明全,武仲科,袁野,杨硕,王宏安.图像理解中的卷积神经网络.自动化学报,2016,42(9):1300−1312)
15 Sun Xiao,Pan Ting,Ren Fu-Ji.Facial expression recognition using ROI-KNN deep convolutional neural networks.Acta Automatica Sinica,2016,42(6):883−891
(孙晓,潘汀,任福继.基于ROI-KNN卷积神经网络的面部表情识别.自动化学报,2016,42(6):883−891)
16 Hubel D H,Wiesel T N.Receptive fi elds,binocular interaction and functional architecture in the cat′s visual cortex.The Journal of Physiology,1962,160(1):106−154
17 Fukushima K,Miyake S,Ito T.Neocognitron:a neural network model for a mechanism of visual pattern recognition.IEEE Transactions on Systems,Man,and Cybernetics, 1983,SMC-13(5):826−834
18 Le Cun Y,Boser B,Denker J S,Howard R E,Habbard W,Jackel L D,Henderson D.Handwritten digit recognition with a back-propagation network.Advances in Neural Information Processing Systems 2.San Francisco,CA,USA: Morgan Kaufmann Publishers Inc.,1989.396−404
19 Le Cun Y,Bottou L,Bengio Y,Haあner P.Gradient-based learning applied to document recognition.Proceedings of the IEEE,1998,86(11):2278−2324
20 Bengio Y.Learning deep architectures for AI.Foundations and TrendsR○in Machine Learning,2009,2(1):1−127
21 Glorot X,Bengio Y.Understanding the diきculty of training deep feedforward neural networks.In:Proceedings of the 13th International Conference on Arti fi cial Intelligence and Statistics(AISTATS)2010.Sardinia,Italy:Chia Laguna Resort,2010.249−256
22 Ziegel R.Modern Applied Statistics with S-plus(3rd edition),by Venables W N and Ripley B D,New York: Springer-Verlag,1999,Technometrics,2001,43(2):249
23 Srivastava R K,GreあK,Schmidhuber J.Highway networks.Computer Science,arXiv:1505.00387,2015.
24 Romero A,Ballas N,Kahou S E,Chassang A,Gatta C,Bengio Y.FitNets:hints for thin deep nets.Computer Science, arXiv:1412.6550,2014.
25 He K M,Zhang X Y,Ren S Q,Sun J.Deep residual learning for image recognition.In:Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. arXiv:1512.03385,2016.770−778
26 Sun Y,Wang X G,Tang X O.Deep learning face representation from predicting 10,000 classes.In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Columbus,OH,USA:IEEE,2014. 1891−1898
27 Zhang Ting,Li Yu-Jian,Hu Hai-He,Zhang Ya-Hong.A gender classi fi cation model based on cross-connected convolutional neural networks.Acta Automatica Sinica,2016, 42(6):858−865
(张婷,李玉鑑,胡海鹤,张亚红.基于跨连卷积神经网络的性别分类模型.自动化学报,2016,42(6):858−865)
28 Kumbhar M,Jadhav A,Patil M.Facial expression recognition based on image feature.International Journal of Computer and Communication Engineering,2012,1(2):117−119
