基于语料库统计的“音-形”激活概率及加工机制
2018-03-01李梅秀DanielWorlton邢红兵
李梅秀 Daniel S.Worlton 邢红兵
(北京语言大学汉语进修学院,北京 100083)
1 引言
形、音、义在心理词典中的联结关系及其加工机制是语言加工中很重要的问题,三者在心理词典中是相互联结的,并且在语言加工过程中相互作用。其中,“音-形”(从音到形)的加工情况是一个重要的方面。弄清楚“音-形”加工机制,对于深入了解母语者心理词典加工机制、预测二语学习者习得情况、矫治“音-形”加工问题导致的阅读障碍等都有一定的参考意义。
在国外词汇识别领域,Van Orden和Goldinger(1994)提出的共振模型认为语音和词形之间存在双向共振关系,即语音的激活会影响词形激活,反过来词形的激活也会影响语音的激活。后来的一系列研究证实了这种关系,并且发现词汇加工过程中存在反馈一致性效应(feedback consistent effect),即与拼读一致的词(一个语音只对应一个词形)相比,拼读不一致的词(一个语音对应多个词形)的识别速度更慢,错误率更高。因为在词汇加工过程中,同音词形会被激活,相互间产生竞争(Pattamadilok,Morais,Ventura,& Kolinsky,2007;Petrova,Gaskell,& Ferrand,2011;Ventura,Morais,& Kolinsky,2007;Ziegler,Petrova,& Ferrand,2008)。
在汉语的研究中也发现了这种一致性效应。比如来自成人的一些研究发现“音-形”加工过程中有同音字的比无同音字的加工难度更大(Zhou & Marslen-Wilson,1994);与同音字家族小的情况相比,同音字家族大的加工难度更大(周海燕,舒华,2008;Wang,Li,Ning,& Zhang,2012)。
然而,值得注意的是,在英语中,同音词家族成员多数只有2个,多音词也多数只有2个读音。因此,考察英语的“音-形”加工(即语音到字形或词形的加工,下文简称“音-形”加工)机制基本上只需分为拼读一致和拼读不一致两种情况。但是汉语的音、形关系比类似英语这样的拼音文字系统复杂得多。从音到形的角度看,音节载字量(一个音节对应的汉字数量称为该音节的“载字量”,即相关研究中所说的同音字家族数量)最多达92个,平均载字量为8.31(苏新春,林进展,2006)。从形到音的角度看,汉语多音字一般有两到三个读音,有些多音字的读音多达6个,而且多音字在常用汉字中的比例及其在语料中的使用率都比较高。据刘云汉(2012)统计,3500常用字中共有多音字507个,占14.5%;Worlton(2014)统计的8953个汉字中有901个多音字,占10%,其使用率占语料库近一半的字次。
显然,汉语“音-形”关系类型不能简单地分为一致(一音对应一字或一字对应一音)和不一致(一音多字或一字多音)两种情况,因为后者的交叉对应关系还可以分为很多情况,这使得汉语音、形之间的联结关系和激活机制比“音-形”对应关系相对比较简单的拼音文字要复杂得多,加工机制也会更复杂。
近年来,在心理词典表征和音、形、义加工的相关研究中,研究者越来越重视汉语的这一特点。很多研究以独立的汉字为实验材料,结合同音字的频度差异,考察了同音字家族数、同音字具体频率、音节的累积频率等因素在“音-形”加工中的作用。多数研究证实了在汉字加工中存在同音字家族数效应,并且发现同音字对目标汉字的影响受频度因素的制约(陈宝国,宁爱华,2005),各个同音字在加工过程中的激活程度存在差异(王文娜,2006;李小健,方杰,楼婧,2011;李小健,王文娜,李晓倩,2011;方杰,李小健,罗畏畏,2014)。
陈宝国等(2005)的视、听跨通道判断实验结果显示,当呈现的汉字为低频字时,其同音字越多,判断时间越长,但呈现的汉字为高频字时,没有同音字效应。说明在“音-形”加工过程中高频字的激活程度比较高,受同音字的干扰比较小。
李小健、王文娜等人进行的一系列相关研究进一步证实了同音字数的影响和同音字激活程度差异的存在。王文娜(2006)以一个单音节听写任务和两个“音-字”同音匹配判断任务来考察汉语单字词“音-形”加工过程中的同音字激活情况,结果发现高频字比低频字更容易激活,并且有优先通达最高频同音字的倾向。另外,同音字家族大的音节通达速度慢于同音字家族小的音节。李小健、方杰、楼婧(2011)和方杰、李小健、罗畏畏(2014)的研究采用跨通道“音-字”判断任务考察汉语同音字具体频率和同音字数在听觉词汇通达中的作用,结果显示汉字具体频率高的组反应时显著短于汉字具体频率低的组,正确率也更高;汉字具体频率和同音字数之间相互牵制,在二者的相互作用中具体频率起主导作用。李小健、王文娜、李晓倩(2011)用一个单音节听写实验和一个“音-字”判断实验重点考察了同音字族内的听觉通道词频效应,结果也显示存在同音字族内的听觉通道字频效应,同音字族内频度越高的字通达的机会越大,最高频字通常得到最多的通达机会。
从这些研究结果来看,当输入一个汉语音节时,会激活多个同音字,但激活程度有很大差异,表现为频度越高的字越容易激活,并且倾向于优先激活最高频字,说明不同频度的汉字在“音-形”加工中的激活程度是不一样的。这些研究成果对相关的研究有很多启发,但是,关于多音字的问题还需要探讨。以上提到的研究并没有对研究中所采用的字频进行说明,如果研究中采用的字频来自不区分多音字的汉字文本语料,那么得到的结果是不准确的。以往多数字频统计只是统计了字形的频率,并不区分多音字。比如:在字频词典中查到“和”的频度为0.00785,这个频度很可能包括“和(hé)”、“和(hè)”、“和(huó)”、“和(huò)”、“和(hú)”的频度。音节“huò”对应的几个比较常用的汉字字形按《汉字字频词典》中的频率从大到小排列依次为:和(0.00785)、或(0.00054)、获(0.00050)、货(0.00029)。那么,按照“频率越高的汉字越容易被激活”的结论,听到“huò”这个音节时这四个字的激活强度顺序(从大到小)应该是:和>或>获>货。然而,试测的结果显示,当听到“huò”时,这四个字被激活的概率(从大到小)为:或>获>货>和。与按照具体读音统计得到的频度顺序一致:或(0.1348)、获(0.0285)、货(0.0220)、和(0.0002)。显然,只有考虑多音字问题,按实际读音统计得到的频度才能体现这个激活规律。另外,有些研究为了控制相关因素,实验材料的选择避开多音字,那么这样得到的结果就不能预测多音字的“音-形”加工机制。
总之,已有研究多数证实了在“音-形”加工过程中存在一致性效应和频度效应。然而,由于汉字形与音的双向对应关系比较复杂,不能简单地分为一致或不一致两种情况,因为不一致的对应关系还包括一对多、多对一、多对多等多种情况,频度效应在不同对应关系中所起的作用必定会不一样。因此,要深入观察不同对应关系的“音-形”加工机制,需要综合考虑音、形对应关系和频度。
为了解决这个问题,研究首先通过基于语料库的统计数据计算出了“音-形”激活概率(即在语料库中出现某个音节时,其对应某个汉字的概率),并通过一个独立音节的听写实验来验证这种基于语料库统计的激活概率是否反映实际加工过程中的激活情况。如果基于语料库统计得到的激活概率反映真实的激活情况,就可以通过该“音-形”激活概率推测一个音节在加工过程中激活各个汉字的概率,可以基于该概率值构建“音-形”加工模型,模拟心理词典的加工。
2 “音-形”激活概率
Worlton(2014)建立的音节统计数据库已经解决了前面提出的多音字的问题。该数据库包含8953个汉字(type)、1400多个音节,提供所有汉字和音节的频率,以及汉字与音节的共现频率。在此基础上求出了语料库中的“音-形”对应概率(即一个音节对应于某个汉字的概率),具体计算方法如下。
将音节和汉字视为随机变量,用Z代表汉字,Y代表音节,通过以下条件概率公式的推导求得语料库中每个音节对应于某个汉字的概率。
以上公式中的P(Z∩Y)表示音节“Y”与汉字“Z”共同出现的概率,由公式“P(Z∩Y)=P(Y|Z)P(Z)”得到,P(Y|Z)是指语料库中某个汉字“Z”对应于某个音节“Y”的概率,P(Y)是音节在语料库中的频率,P(Z)是汉字在语料库中的频率。在当前研究中,P(Y|Z)、P(Y)、P(Z)均为已知变量(均为前期相关研究所建混合数据模型得到的数据)*P(Y|Z)=Z在语料中以Y音出现的频次÷Z在语料中的总频次(Z以不同读音出现的频次之和)。以计算“说”对应于“shuì”为例,模型可从原始数据中得到的已知数据为:P说(shuì)=0.000128,P税(shuì)=0.000236,P睡(shuì)=0.000173;P说(shuō)=0.004371,P说(shuo)=0.000025,P说(yuè)=0;F说(shuì)=24583,F说(shuō)=845659,F说(shuo)=4916,F说(yuè)=0(“F”代表频次,即在语料库中出现的次数)。由此可得:P(说)=P说(shuì)+P说(shuō)+P说(shuo)+P说(yuè)=0.004523;P(shuì)=P说(shuì)+P税(shuì)+P睡(shuì)=0.000537;P(shuì |说)=F说(shuì)÷(F说(shuì)+F说(shuō)+F说(shuo)+F说(yuè))=24583÷(24583+845659+4916+0)=0.028090。。以计算音节“shuì”对应于汉字“说”的概率为例,已知:P(shuì|说)=0.028090,P(说)=0.004523,P(shuì)=0.000537,计算过程如下:
(1)P(说∩shuì)=P(shuì|说)P(说)=0.028090×0.004523=0.000127;
(2)P(说|shuì)=P(说∩shuì)÷P(shuì)=0.000127÷0.000537=0.236499。
由此得到语料中出现“shuì”时对应的汉字是“说”的概率为0.236499。
研究假设这样求得的概率值反映实际加工中语音激活字形的概率,因此将其称为“音-形”激活概率(下文简称“激活概率”,用“PZY”表示),PZY值的范围均为0到1之间,每个音节与其对应的所有汉字的PZY值之和为1。
从统计的结果来看,多字音节可按“音-形”激活概率分为两类:一类为有优势字的音节,这类音节的特点是与之对应的多个汉字中某一个汉字的激活概率大于0.5,研究称这个汉字为该音节的绝对优势字;另一类是无绝对优势字的音节,即与各个对应汉字的激活概率分布趋于平均的音节,其中激活概率最高的汉字称为该音节的相对优势字(例子见图1~图4)。
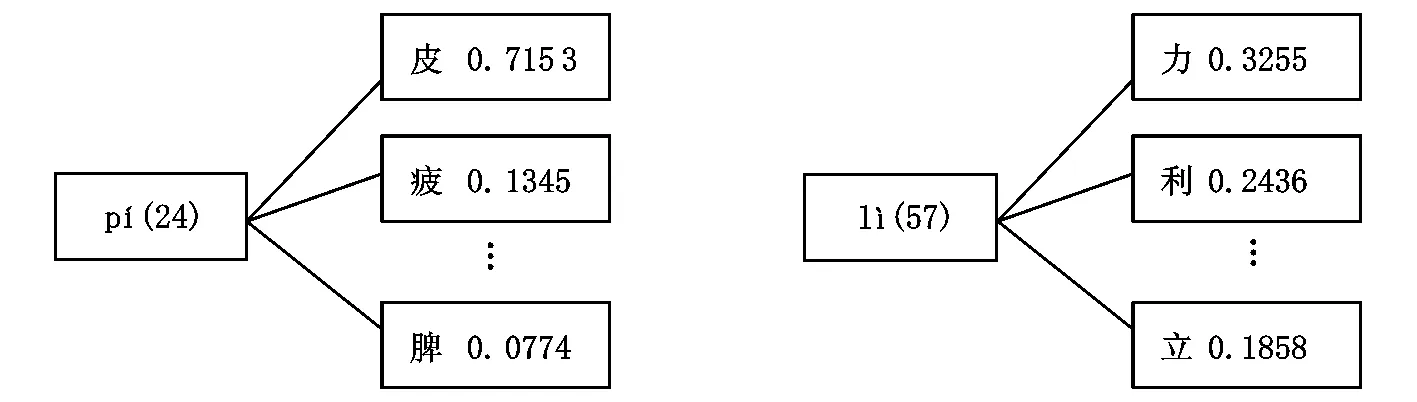
图1 载字量高、有绝对优势字的音节 图2 载字量高、无绝对优势字的音节

图3 载字量低、有绝对优势字的音节 图4 载字量低、无绝对优势字的音节
图1~图4括号中的数字为音节的载字量,汉字后面的数字表示“音-形”激活概率。如果这种基于语料库得到的激活概率反映实际加工中的“音-形”激活概率,那么图1和图3将优先通达第一个汉字,各个汉字的激活强度从上到下逐渐减弱。而图2和图4的汉字在“音-形”激活过程中被激活的随机性会比较大。另外,即使“音-形”对应概率分布模式基本相同,如果载字量不同,平均每个汉字分得的激活概率大小有差异,“音-形”激活情况也会不同,即图1和图3之间、图2和图4之间在加工机制上也会有一定差异。
3 实验研究
3.1 实验设计
3.2 被试
61名普通话标准的汉语母语者,均为北京语言大学硕士研究生,视力或矫正视力、听力均正常,未参加过相似的实验。
3.3 实验材料
从第2部分统计形成的数据库中选出100个音节,按图1~图4所示音节类型分成四组,每组25个音节,音节的邻域密度*邻域密度是指某个音节的邻居数量,一个音节的邻居是指与这个音节发音上相似、某些音位相同的音节,即通过增加、删减或替换一个音节的某个音位或声调得到的合法音节就是该音节的邻居(李梅秀,2014)。和频度为主要的控制变量(平均值见表1)。

表1 实验材料相关数据平均值和例子
实验材料的重复测量方差分析结果显示,PZY值组间差异主效应显著,F(3,96)=110.276,p<0.0005;载字量高水平上和载字量低水平上有优势字组和无优势字组间PZY值差异均显著(均为p<0.0005);不同载字量水平上两个有优势字组之间和两个无优势字组之间PZY值差异均不显著(优势字组间:p=0.136,无优势字组间:p=0.255)。
载字量组间差异主效应显著,F(3,96)=96.943,p<0.0005;有优势字组和无优势字组内载字量水平差异显著(均为p<0.0005);载字量高有优势字组和载字量高无优势字组之间以及载字量低有优势字和载字量低无优势字组之间载字量差异均不显著(分别为p=0.677,p=0.645)。
邻域密度组间差异主效应不显著,F(3,96)=0.159,p=0.923);频率组间差异主效应不显著,F(3,96)=2.020,p=0.116。
统计结果说明材料的相关变量值符合分组要求,控制变量得到了有效控制。
所有音节的音频均来自一名普通话水平为一级乙等(94分)的中国女发音人,用专业的录音设备在录音室录制。所有实验音节按随机顺序排列,并通过人工核查,保证所有相邻音节之间不构成双音节词,然后按随机排好的顺序编辑成一个连续的音频,每个音节前面以“嘟”声开头,每两个音节之间间隔3000ms(通过试测确定3000ms时间足够被试写下一个汉字,但是没有富余时间修改或写第一反应以外的字)。
3.4 实验程序
实验在一个安静的多媒体教室进行,集体施测,要求被试每听到一个音节之后,在3000ms内写下最先想到的一个汉字,写好以后不可以返回修改。整个实验时长约7分钟。
3.5 实验结果
3.5.1 两因素被试内方差分析
在最后的统计分析中,被试写出的汉字与目标音节不能对应的情况均视为错误。最终,所有被试计入统分析(所有被试正确率均达到90%以上,被试平均正确率为94.47%);所有项目也计入统计(所有项目正确率均在85%以上,项目的平均正确率为87.74%)。
分别以优势字产出率、字种数、各字产出率与PZY值的拟合度、错误率为因变量进行统计分析。其中,优势字产出率指被试写出PZY值最高的汉字(优势字或相对优势字)的平均比例;字种数指每个音节对应的所有汉字中被被试写出的字种数量;优势字产出率与PZY值的拟合度是某个汉字被被试写出的频率与其在语料库中的“音-形”对应概率的拟合度(通过拟合度分析所得的值);错误率是指被试写出的汉字不符合对应音节的比例。具体实验结果如表2所示。

表2 汉字产出情况和错误率(括号中为标准差)
优势字产出率的方差分析结果显示,音节类型主效应显著,有绝对优势字的音节,被试产出绝对优势字的比例高于无绝对优势字组被试产出相对优势字的比例,F(1,24)=4.276,p=0.05;载字量主效应显著,载字量低的组,被试更容易产出优势字(绝对优势字或相对优势字),F(1,24)=7.487,p<0.05;音节类型和载字量的交互作用不显著,F(1,24)=0.128,p=0.723。
字种数的方差分析结果显示,音节类型主效应显著,有绝对优势字的组,被试产出的字种数少于无绝对优势字的组,F(1,24)=192.000,p<0.0005;载字量主效应显著,载字量高的组产出的字种数多于载字量低的组,F(1,24)=246.674,p<0.0005;音节类型和载字量交互作用显著,F(1,24)=14.769,p=0.001。简单效应检验结果显示,在载字量低的水平上,音节类型的简单效应显著,F(1,24)=48.00,p<0.0005;但是,在载字量高的水平上,音节类型的简单效应更显著,F(1,24)=109.71,p<0.0005。
各个汉字产出率与PZY值拟合度方差分析结果显示,音节类型主效应不显著,F(1,24)=1.516,p=0.230;载字量主效应不显著,F(1,24)=1.884,p=0.183;音节类型和载字量交互作用不显著,F(1,24)=2.377,p=0.136。
错误率方差分析结果显示,音节类型主效应显著,有绝对优势字组错误率低于无绝对优势字组,F(1,24)=25.334,p<0.0005;载字量主效应显著,载字量低的组错误率更高,F(1,24)=20.600,p<0.0005;音节类型和载字量交互效应显著,F(1,24)=29.509,p<0.0005。简单效应检验的结果显示,在载字量高的水平上,音节类型的简单效应不显著,F(1,24)=0.32,p=0.574;在载字量低的水平上,音节类型的简单效应显著,F(1,24)=27.51,p<0.0005。
3.5.2 回归分析
由于影响汉字加工的因素较多,除了“音-形”概率值所涉及的字频和多音字之外,前面的分析结果以及已有相关研究结果均显示载字量也有很大影响,相关研究还证实汉字笔画数(如彭聃龄,王春茂,1997;杨沙沙,2015)、形声字的形旁或声旁(如王协顺等,2016)等也有影响。另外,根据被试的产出结果,如果一个音节对应的汉字中既有成词语素和非词语素,被试倾向于写出成词的汉字,由此推测成词与否也对加工带来一定影响。
因此,为了观察“音-形”激活概率在加工过程中的独特作用,对“音-形”激活概率(PZY)、载字量、笔画数、是否为形声字(形声字=1,非形声字=0)、是否成词(成词=1,不成词=0)五个自变量和产出率进行了相关分析(见表3)。

表3 四个自变量及汉字产出率的相关矩阵
从表3的相关矩阵中可以看到,“音-形”激活概率、载字量、是否为形声字、是否成词都和产出率显著相关。其中,“音-形”激活概率与产出率的相关度最高(r=0.562,p<0.0005),是否成词次之(r=0.353,p<0.0005)。另外,其他变量之间也存在一定的相关。
进一步以“音-形”激活概率、载字量、笔画数、是否为形声字、是否成词五个变量为自变量,产出率为因变量进行了回归分析。采用Enter法进行回归分析,得到R2=0.365,表明五个自变量能够解释产出率总变异的36.5%。显著性检验表明,自变量可解释的因变量变异与误差变异相比是统计上显著的,F(5,452)=51.918,p<0.0005。系数分析发现,PZY值和是否成词都对产出率有重要影响。进一步的层次回归分析结果显示,控制了其他三个变量之后,“音-形”激活概率的贡献仍然达到22.5%(ΔR2=0.358),其贡献在统计上是显著的(p<0.0005)。该结果表明,“音-形”激活概率确实有其他变量不能解释的作用,是“音-形”加工过程中汉字产出率的一个重要预测指标,可以反映实际加工中的“音-形”激活情况。
3.5.3 错误率分布情况
为了进一步了解“音-形”加工过程中除了对应汉字的字形,还有哪些表征可能会被激活,研究还对错误类型进行了分类统计。错误情况如图5所示。

图5 错误率分布
出现的错误可分为四大类:音近别字(如:bìng→定)、错字(如多笔画或者少笔画)、形近别字(如:yin1→困)、意义相关别字(如:xie1→休,该错误同时属于音近别字,因此也计入“音近别字”)。其中,音近别字最多,88%以上的错误输出都是音近别字,其他类型的错误非常少,都在10%以下。
这个结果至少可以说明两点:一、“音-形”加工过程中,与目标音节相似的语音也会部分激活;二、“音-形”加工过程中,相关的正字法信息和相关语义也部分参与了加工。
4 讨论
研究结果显示,汉语“音-形”加工过程中,不同“音-形”关系类型的音节在激活机制上存在差异,表现为:(1)有绝对优势字组有明显的优势字效应,优势字的平均产出率达到约50%。(2)有绝对优势字组产出的字种数(平均4个字)少于无绝对优势字组(约5.2个字)。说明有绝对优势字的音节在“音-形”加工过程中,主要集中激活与之联结概率最高的几个汉字,这几个汉字的激活值远高于PZY值较低的汉字,其在产出中占绝对优势,一定程度上抑制了其他同音字的激活;而无绝对优势字的音节,其对应的各个同音字被激活的概率比较平均,因此在听写过程中被写出的机会也较均等。(3)从回归分析的结果来看,PZY值在“音-形”加工过程中有着其他因素所没有的预测作用。从产出率与PZY值拟合度的被试内方差分析结果来看,不同类型音节PZY值对实际加工中“音-形”激活概率的预测作用也是一样的,表现为无论是有优势字组还是无优势字组,对应汉字的产出率与其PZY值的拟合度都是一样的,没有显著差异。(4)有绝对优势字的组错误率较低。这是因为有绝对优势字的音节倾向于优先激活绝对优势字,受音近、形近或意义相关汉字的影响较小,而无绝对优势字的音节,对应的多个汉字都有差不多的激活概率,每个汉字得到的激活度相对较低,容易受到音近、形近或意义相关汉字的干扰,甚至输出这些汉字。这些结果都说明基于语料库得到的“音-形”激活概率基本反映实际的激活情况。
另外,载字量也会影响“音-形”激活机制,表现为:(1)与载字量高的音节相比,载字量低的音节更倾向于激活优势字,这是因为根据计算“音-形”激活概率的方法,每个音节激活其对应的所有汉字的概率值之和都是1,载字量高的音节,每个汉字分得的PZY值相对较低,即使同为有优势字或有相对优势字的音节,载字量高的音节激活优势字或相对优势字的概率要低于载字量低的组,因此,表现出了载字量高的组激活优势字或相对优势字的概率低于载字量低的组。(2)载字量低的组产出的字种数相对较少,除了因为载字量低的音节对应的汉字更少,另外一个原因是载字量低的音节优势字激活概率较高,其他同音字的激活概率相对更低。(3)在不同载字量水平上,“音-形”加工过程中音节类型差异的表现也不同,载字量高的组,有优势字和无优势字产出的字种数相差更大,这是因为载字量高的水平上,有绝对优势字的组,绝对优势字以外的同音字PZY值都很低(因为有更多的同音字“分享”PZY值),这些字的激活水平相应的都很低;在载字量低的水平上,大部分音节绝对优势字与其它同音字之间的激活值差异相对较小,绝对优势字以外的同音字也有一定的竞争力,因此产出的字种数要多一些;而对于无绝对优势字的音节来讲,无论是载字量高的组还是载字量低的组,同音字之间的PZY值都比较平均,被写出来的概率都差不多。(4)从错误率上看,载字量越低的音节,对应汉字产出的错误率越高。这可能是因为载字量低的音节在“音-形”加工中可选择的输出相对较少,容易受到音近、形近或意义相关汉字的干扰。
通过这些结果,可以肯定的是,同音字家族内各个成员被激活的概率存在明显的差异,这一结果支持李小健、王文娜等关于汉语同音字表征激活具有不同等性的发现(王文娜,2006;李小健,方杰,楼婧,2011;李小健,王文娜,李晓倩,2011)。这种激活强度的差异,可以用基于语料库的“音-形”激活概率来预测。
另外,通过错误类型的统计发现,在“音-形”加工过程中,还会激活音节对应汉字字形以外的信息,包括邻居音节(读音相似的音节),还有形近或意义相关的汉字。说明“音-形”的加工过程并不是简单地从音到形的单向激活过程,相关的语音、正字法和语义信息也会被激活,周海燕和舒华(2008)的研究也发现“音-形”加工过程中受到语义的影响。因此,虽然目前的“音-形”激活概率已经基本可以预测实际的加工情况,但在未来的研究中,如果要更加精确地预测和模拟“音-形”激活情况,语义也是需要考虑的一个因素。
通过以上讨论,可以得出这样几点认识:首先,汉语心理词典中音-形的加工机制在某种程度上表现为一个概率模型,心理词典的加工机制取决于二者之间的联结概率,这种概率可以用基于语料库统计得到的概率值来预测。其次,音、形、义的加工在某种程度上会相互影响,从其中任何一种表征到另一种表征的加工过程中必定会不同程度地激活第三种表征,只是激活强度有差异,至于哪种表征的激活强度更强取决于具体的加工目的。
5 结论
基于语料统计得到的“音-形”激活概率基本反映实际的“音-形”激活情况:
(1)“音-形”激活概率越高的汉字被激活的概率和强度越高,并且有明显的优势字效应。
(2)“音-形”的加工还受载字量、笔画数、是否为形声字、是否成词等因素的影响,部分与目标音节和目标汉字相关的语音、字形和语义信息也参与到加工中,但基于频率和多音字信息得到的统计概率仍然具有独立于这些因素的预测功能。
陈宝国,宁爱华.(2005).汉字识别中的同音字效应:语音影响字形加工的证据.心理学探新,25(4),35-39.
方杰,李小健,罗畏畏.(2014).汉语音节累积词频对同音字听觉词汇表征的激活作用.心理学报,46(4),467-480.
李小健,方杰,楼婧.(2011).汉语同音字具体频率和同音字数在听觉词汇通达中的相互作用.心理科学,34(1),43-47.
李小健,王文娜,李晓倩.(2011).同音字族内的听觉通道词频效应与同音字表征的激活.心理学报,43(7),749-762.
刘云汉.(2012).常用多音字的读音考察.廊坊师范学院学报(社会科学版),28(5),27-30.
彭聃龄,王春茂.(1997).汉字加工的基本单元:来自笔画数效应和部件数效应的证据.心理学报,29(1),9-17.
苏新春,林进展.(2006).普通话音节数及载字量的统计分析——基于《现代汉语词典》注音材料.中国语文,(3),274-288.
王文娜.(2006).同音字音节的听觉词汇通达研究.硕士学位论文.广州:华南师范大学.
Worlton,D.S.(2014).超越汉字:现代汉语音节动态统计分析.数字化汉语教学(2014)(pp.437-443).北京:清华大学出版社.
王协顺,吴岩,赵思敏,倪超,张明.(2016).形旁和声旁在形声字识别中的作用.心理学报,48(2),130-140.
杨沙沙.(2015).汉字加工中的笔画数效应:来自ERP的证据.硕士学位论文.重庆:西南大学.
周海燕,舒华.(2008).汉语音-形通达过程中的同音字家族效应和语义透明度效应.心理科学,31(4),852-855.
Pattamadilok,C.,Morais,J.,Ventura,P.,& Kolinsky,R.(2007).The locus of the orthographic consistency effect in auditory word recognition:Further evidence from French.LanguageandCognitiveProcesses,22,1-27.
Petrova,A.,Gaskell,M.G.,& Ferrand,L.(2011).Orthographic consistency and word frequency effects in auditory word recognition:New evidence from lexical decision and rime detection.FrontiersinPsychology,2(4),263.
Van Orden,G.C.,& Goldinger,S.D.(1994).Interdependence of form and function in cognitive systems explains perception of printed words.JournalofExperimentalPsychology:HumanPerceptionandPerformance,20(6),1269-1291.
Ventura,P.,Morais,J.,& Kolinsky,R.(2007).The development of the orthographic consistency effect in speech recognition:From sublexical to lexical involvement.Cognition,105(3),548-576.
Wang,W.,Li,X.,Ning,N.,& Zhang,J.X.(2012).The nature of the homophone density effect:An ERP study with Chinese spoken monosyllable homophones.NeuroscienceLetters,516(1),67-71.
Zhou,X.,& Marslen-Wilson,W.D.(1994).Words morphemes and syllables in the Chinese mental lexicon.LanguageandCognitiveProcesses,9(3),393-422.
Ziegler,J.C.,Petrova,A.,& Ferrand,L.(2008).Feedback consistency effects in visual and auditory word recognition:Where do we stand after more than a decade?JournalofExperimentalPsychology:LearningMemory&Cognition,34(3),643-661.
