基于文本相似度的智能工单分析系统解决方案研究
2018-02-27黄峰王定军
黄峰 王定军

摘要
在互联网和大数据时代,企业将一些密集重复性的工作逐渐由机器来替代。进入人工智能时代后,以大数据驱动的智能方面的研究方兴未艾,旨在通过大数据加机器学习相关技术将企业的问题工单进行自动识别、打标签,为企业智慧运营提供分析决策支撑。本文介绍并实现了一种基于文本相似度的自动打标签研究方法,同时通过实验评估了本方法的实施效果。
【关键词】文本相似度 机器学习 工单打标签
文本相似度是进行文本聚类的基础,和传统的结构化数值数据的聚类方法相似,文本聚类是通过计算文本之间的“距离”来表示文本之间的相似度,并产生聚类。文本相似度的常用计算方法有普贝叶斯。但是文本数据和普通的数据不同,它是一种半结构化的数据,在进行聚类之前必须要对文本数据源进行处理,如分词、向量化表示等,其目的就是使用向量化的数值来表达这些半结构化的文本数据。使其适用于文本分析。
1 基于文本相似度的智能工单分析系统解决方案
集团管理域信息化集中后,每天会受理大量的工单,工单反应出系统的使用的问题,和业务的导向,现阶段每月靠人工处理大量工单,并人工为工单打上标签。耗费大量人力物力,因此需要一套系统能够对工单进行自动识别和打上标签。基于文本相似度的工单标签分析系统通过以下几个方面的步骤实施,能够对工单进行自动识别打标,解决企业痛点。
1.1 选取并训练数据集
(1)取最近一年内,人工已经打过标签的工单约30000条记录的70%,约21000条作为训练集;
(2)通过IK分词器,对工单内容进行分词处理,这里面包括停用词库和扩展词库的的编辑;
(3)通过关键词及其出现频次,构建向量空间和标签的对应关系。
1.2 工单打标签
(1)对剩余的30%,约9000条工单进行分词,并提取关键字;
(2)对分词过的工单,构建向量空间;
(3)用工单的向量值跟训练集的向量值,通过普贝叶斯对数据进行分类,并自动打上标签。
1.3 结果比对
9000条机器打标签的工单跟人工标签比对,6342条标签完全一致,1795条不一致,863条没有打上。
结论,通过文本相似度算法,工单打标签准确率约70%,具有一定普识性,能够代表运维问题的趋势和导向,后期通过优化算法和调整词库,可以进一步提高准确度。
2 基于文本相似度的智能工单分析系统实现
分数据采集、数据处理、数据分析三层,来构建系统,用过可以通过浏览器快速的查询打标的情况和基于打标后的分析月报等内容。系统分3个功能模组:
2.1 工单系统的数据采集
通过跟工单系统接口获取工单流程信息和工单类型、组织、状态等数据;通过和数据中心的接口获取工单内容信息。考虑到数据比较大,采用增量方式每小时定期获取最新的数据。
2.2 采集的工单数据进行清理、训练、分类、打标
数据采集完成后,对数据里面的特殊字符和无用字段进行清理,清理后的数据提取一部分作为训练数据进行分词和向量化。训练集以外的工单,通过普贝叶斯算法进行分类,并自动打上对应标签。主要过程如下:
2.2.1 分词
文本举例:16FJ001197001nbsp;nbsp;预转固OSS資产提交,提示错误,请协助处理。谢谢!
分词:[16fj001197001nbsp][预转固][oss][资产][提交][提示][错误]。
去掉停用词:请协助处理。谢谢!等。
2.2.2 建立词向量(word2vec)
通过转换,可以把对文本内容的处理简化为向量空间中的向量运算,计算出向量空间上的相似度,来表示文本语义上的相似度。向量的长度为词典的大小,向量的分量只有一个1,其他全为。,I的位置对应该词在词典中的位置。举个例子,“话筒”表示为[0001000000000000…]。
2.2.3 权重TFIDF
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF实际上是:TF*IDF。
词频(Term Frequency,TF)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)
逆向文件频率(Inverse DocumentFrequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
2.2.4 分类算法朴素贝叶斯算法
通过朴素贝叶斯算法对数据集进行训练,从而统计出所有词向量各种分类的概率,对于待分类的文本,在转换为词向量之后,从训练集中取得该词向量为各种分类的概率,概率最大的分类就是所求分类结果。朴素贝叶斯分类算法常常用于文本的分类,而且实践证明效果挺不错的。如图1所示。
2.3 基于打标结果的统计分析和运维月报
依据前面的数据采集和工单打标,每个月出具运维月报,按专工程、财务和采购三个专业出具:标签覆盖率、标签发单量和标签转二线率等维度的图文分析报告。集团依据这个结果进行通报,各下属公司依据报告对当月问题进行整改。
2.3.1 标签覆盖率
标签覆盖率包括:工单总数、工单打标数和标签覆盖率3个具体指标,工单总数主要反映一段时间内工单数量的变化情况,从而知晓业务峰谷的时间特征;工单打标数和标签覆盖率表示打上标签的工单数量以及和总工单数的比例,反映出标签的普适度是否合理。
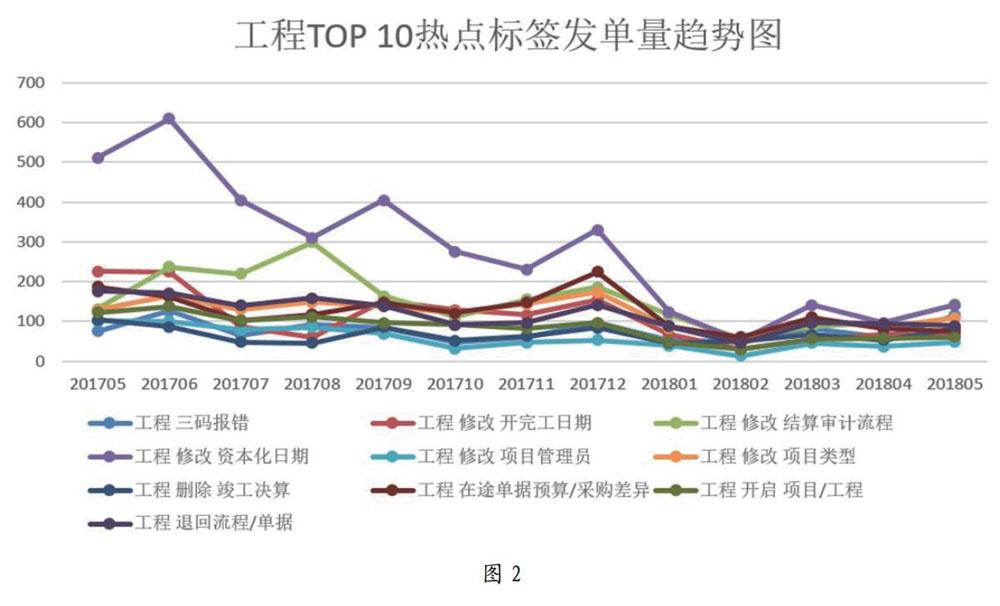
2.3.2 标签发单量
标签发单量表示各类标签的工单数量在时间段内的趋势变化情况,反映出系统某类业务问题的变化,对于持续增长的问题标签,各部门应该制定应对方案,降低问题的发生率,提高系统的易用性。
2.3.4 标签转二线率
标签转二线率体现的是相关标签的工单提交集团数量和总工单的比例,这个是集团考核各省公司的硬性指标,大部分的问题各省一线层面必须自己办法解决,实在有问题的才能提交到集团二线支撑,作为KPI指标对各省运营负责部门进行绩效考核。如图2所示。
3 基于文本相似度的智能工单分析系统效果评估
目前,中国电信集团MSS运营中心每个月的运营大会,都会基于此分析结果进行通报,各省对分析结果比较认同,也基于分析结果进行问题整改,便于集团了解各省的运营过程出现的问题和业务时间趋势,对业务系统进行优化,对业务流程进行及时调整。更好了支撑业务运营,也进一步落实集团提出的智慧运营目标,目前对运营工作的支撑明显。
参考文献
[1]张连文.贝叶斯网引论[M].科学出版社,2006.
[2]Cameron Davidson-Pilon贝叶斯方法:概率编程与贝叶斯推断[M].人民邮电出版社,2017.