基于Docker的分布式环境快速搭建
2018-02-27邹行健王同喜
邹行健 王同喜

摘要:随着大数据热度的不断提升,大数据学习的热潮已然来临。然而在学习大数据的过程中,常常由于各种原因需要重新配置相应的实验环境,这会浪费大量的时间。该文针对大数据实验环境的部署,提出一种基于容器技术在单台或多台计算机上搭建Hadoop集群的方法,为短时间搭建分布式实验环境提供参考。
关键词:Docker;Hadoop;分布式;环境搭建
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2018)35-0024-03
1 背景
作为开源的大数据平台,Apache Hadoop已经形成了完善的生态圈。它集成了存储和数学数据,系统管理等功能,并在海量数据存储和处理,并行计算和数据挖掘领域具有交叉扩展功能。目前而言,Apache Hadoop已经成为大数据领域实际上的标准[1]。与此同时,Hadoop平台的多节点特性、复杂配置等特点,对大数据、Hadoop的学习人员带来了一些困难,例如计算机不够,或是配置失败只能重新开始配置,甚至在多处进行相同的复杂配置。
对于计算机不够的问题,学习人员有的借助学校的多台学生机,在上面安装Linux系统,以此搭建完整的Hadoop平台;有的在单台计算机上安装多台虚拟机进行配置,这对计算机性能有较高要求,并且对宿主机的硬件利用率较低,无法达到真实物理机的水平。而对于配置失败的问题,只能多次尝试,在搭建环境的过程中浪费较多时间。
Docker借助LXC(Linux Container)技术和AUFS(Advanced Union File System)技术,可以凭借极低的额外开销换取隔离性的运行环境。一台普通服务器就能运行数百个容器(Container)[2]。
2 Docker容器技术
Docker 是一个开源的应用容器引擎。Docker可以使用分层镜像标准化与内核虚拟化技术,将开放环境、依赖包体、应用软件等制作成镜像,并发布到任何一台安装有Docker的不限制系统的计算机上。
2.1 Docker的优势
Docker采用了LXC内核虚拟化技术,而不是对硬件虚拟层有较高依赖的传统虚拟化技术。它不提供指令解释机制和全虚拟化的其他复杂性,也不需要完整的硬件虚拟层,从而省去了虚拟化层调度硬件的开销。这使得Docker容器擁有高于传统虚拟机的资源利用率和执行效率,接近于真实的物理机[3]。
Docker采用了联合文件系统(UnionFS)技术,并对其变体也有较高兼容性,如AUFS、btrfs、vfs和DeviceMapper。这种通过创建图层进行操作的文件系统使得它能实现容器对基础镜像的共享。运行容器时,最底层的操作系统镜像作为只读层挂载,其上层设置有顶层的可写层供写入数据。通过这种图层结构,docker不仅可以将多个具有层级关系的应用服务集成为新的镜像,还可以将镜像部署到他处,而不需要重复安装。
基于以上两点,作为面向应用的虚拟化技术[4],docker在启动速度、磁盘占用、硬件资源利用率等方面有很大优势。
2.2 镜像与容器
在Docker技术中,镜像与容器是两个最为重要的概念。
镜像相似于虚拟机模板。以一个原生系统作为模板,然后在其中可以进行部署开发环境、安装应用、修改系统参数等操作,最后打包形成一个新的镜像。这种继承关系可以是多层的。
容器是基于镜像创建的实例。对容器而言,镜像是只读的。在运行容器时,将首先在镜像层之上新增一层,这一层是可写的。此时,对该容器一切操作都会保存到这个可写层的文件系统中,而不是镜像中。因此,基于相同的一个镜像可以创建多个彼此之间相互隔离的容器。
2.3 DockerSwarm
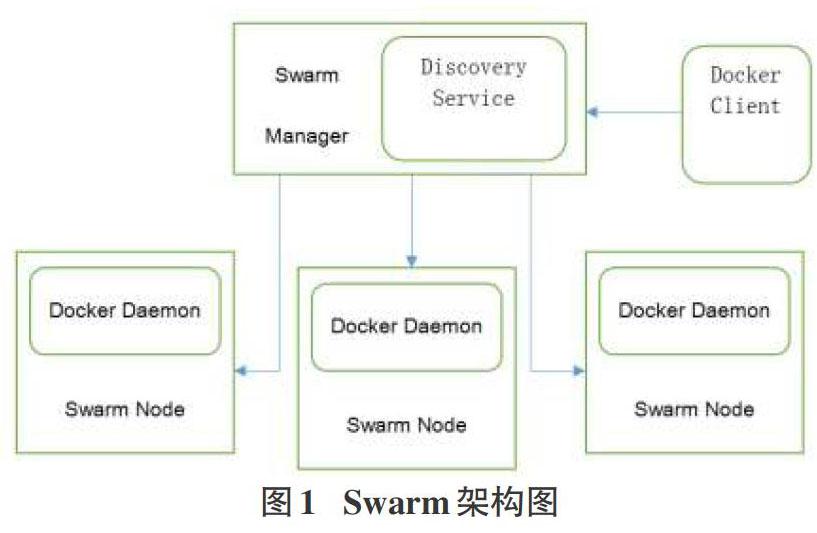
Swarm是一套集群管理工具。Docker Swarm能将若干Docker宿主机虚拟化为一台独立的Docker主机。Swarm使用了标准的Docker API接口,这意味着它兼容任何支持标准API的docker客户端。
Swarm daemon在整个架构汇中起到了路由器与调度器的作用。Swarm负责连通整个网络与分配任务。每当收到来自Client的请求时,Swarm将容器分配到空闲的或者合适的节点上。当Swarm的daemon进程意外中止时,其他节点依然会正常运行。而后,当Swarm进程恢复时,它会收集相关信息以重建集群日志。
图1为Swarm架构图。
2.4 DockerHub和Register
Docker Hub可看做官方提供的一个在线镜像仓库。DockerHub中存放了各种原生系统与用户们自行修改的定制系统与框架。Docker Register组件提供了一组API服务,用于镜像的存储、搜索、上传、下载等。任何个人或组织都可以在Docker Hub获取已经发布的镜像,或创建和发布自己的镜像,以供后续重复使用或分享给其他人使用。
2.5 Dockerfile
为了方便用户制作自己的镜像,Docker提供给用户两种方法:一种是基于官方镜像,按照生产环境的需求编写Dockerfile文件,以此作为依据生成新的镜像;另一种是基于官方镜像创建容器后进行相关环境的部署,然后使用commit命令将配置好的容器封装成一个新的镜像。
Dockerfile是基于DSL(Domain Specific Language,特定领域语言)的脚本, 由命令行组成。其中的每条语句都对应了一条Linux命令, Docker引擎则将这些语句翻译成对应的命令。相比于直接从Hub拉取镜像,Dockerfile脚本清晰地表明镜像相比于原生系统做了哪些配置, 如果需要进行其他修改, 只需要添加或修改Dockerfile中的命令即可。该文将使用这种方法制作镜像。
3 制作Hadoop镜像
在编码制作Hadoop镜像的Dockerfile文件时,主要有以下步骤:
1) 声明原始镜像;
2) 声明工作环境;
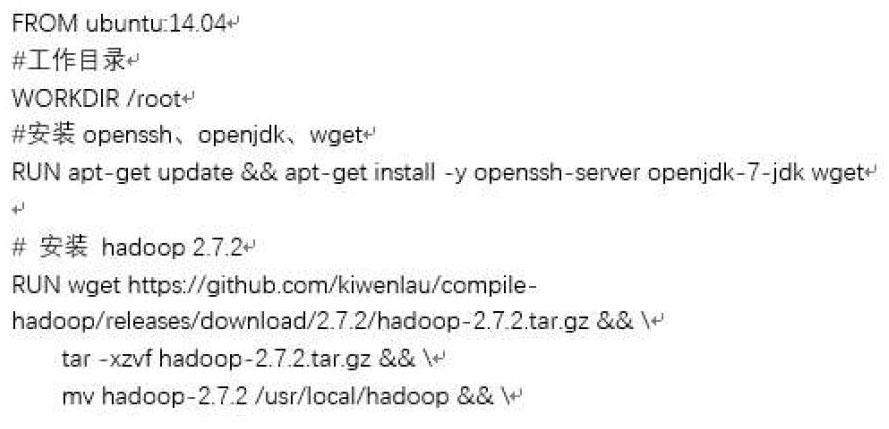
3) 安装openssh、openjdk、wget;
4) 安装Hadoop;
5) 配置环境变量;
6) 配置无密码访问;
7) 配置Hadoop,将下列修改好的配置文件拷贝至Hadoop目录;
8) 格式化namenode;
9) 如果要加入eclipse等应用,与上面同理。
4 分布式环境搭建
得益于进程级虚拟化技术, Docker以应用为中心, 轻巧便捷,适合用于需要横向扩展的应用。运行集成了Hadoop的容器,即可在計算机上快速部署Hadoop集群环境。
4.1 环境部署
1) 准备好一台或多台准备作为Hadoop节点的计算机,并在每台计算机上安装好Docker。
2) 在主节点(master)上获取Hadoop镜像,pull后面是制作好的镜像的名字。
3) 建立Swarm网络,在master节点运行以下命令,以此获得用于加入swarm网络的令牌。将获取的令牌整个粘贴到每个slave节点上运行。如果仅有一台计算机则可以跳过此步骤。
4) 为Hadoop集群创建一个专用网络。一般来说,实验不会直接使用swarm的默认网络,用以下命令新建一个hadoop专用网络。
4.2 启动容器服务
如果是多PC节点,则在主节点上运行以下命令,然后查看docker的运行服务列表。可以发现Hadoop的三个节点已经分别分配到三个PC节点上了。
如果只有一台PC,则在作为主节点(master)的容器上运行:
在每个作为从节点(slave)的容器上运行:
其中[slavename]替换成slave节点的名字。
4.3 启动并验证Hadoop
在master节点用ps命令查看并确认容器ID,而后用exec命令进入Hadoop集群的主节点。在每台计算机上使用ping命令,测试它们之间的网络是否正常;用ssh连接每个从节点以确认无密码访问是否正常。若无问题,则可以找到start脚本来启动Hadoop集群。
如果启动过程中没有生成错误日志,则可以认为集群运行成功。接下来测试启动过程是否出错。运行Hadoop自带的字数统计脚本(run-wordcount.sh),查看输出;用jps命令查看每个容器节点的进程确认是否正常。下图为验证结果:
5 镜像迁移
不同于传统的虚拟机环境或固定的集群环境,当Docker下的Hadoop集群需要进行迁移时,只需要将原环境打包成镜像发布到Docker Hub上,然后在新环境上下载,重新运行容器即可,极大简化了应用程序的安装与管理。
6 结束语
在大数据的学习与研究过程中,分布式环境是不可或缺的一部分。Docker可以在多种平台上搭建Hadoop集群,这为广大学习者节省了大量学习成本,且经长时间使用测试证明运行稳定,可供其他人进行参考。
参考文献:
[1] 孟小峰, 慈祥. 大数据管理:概念、技术与挑战[J]. 计算机研究与发展, 2013(1):146-169.
[2] 强焜. 基于Docker的旧机房虚拟化改造探讨[J]. 科技创新与应用, 2016(35):58.
[3] 谢超群. Docker容器技术在高校数据中心的应用[J]. 贵阳学院学报: 自然科学版, 2015,10(4):27-29.
[4] 汪恺, 张功萱, 周秀敏. 基于容器虚拟化技术研究[J]. 计算机技术与发展, 2015,25(8):138-141.
+[通联编辑:谢媛媛]
