Hadoop的两大核心技术HDFS和MapReduce
2018-02-25李港刘玉程
李港 刘玉程
摘要 本文主要介绍分布式处理框架Hadoop的两大核心技术HDFS和MapReduce,使读者对Hadoop框架有一个基本的了解。
【关键词】Hadoop HDFS MapReduce 分布式数据存储 分布式数据处理
2008年9月4日《自然》(Nature)杂志刊登了一个名为“Big Data”的专辑,大数据这个词汇开始逐渐进入大众的视野,云计算、大数据、物联网技术的普及人类社会迎来了第三次信息化的浪潮,数据信息也在各行各业中呈现爆炸式的增长。根据全球互联网中心数据,到2020年底,全球的数据量将达到35ZB,大数据时代正式到来了,大数据的4V特性:多样化( Variety)、快速化(Velocity)、大量化( Volume)、价值密度低(Value)使得对大数据的存储和处理显得格外重要,Google、Microsoft包括国内的阿里巴巴、百度、腾讯等多家互联网企业的巨头都在使用分布式处理软件框架--Hadoop平台。
1 Hadoop平台简述
Hadoop是Apache基金会旗下的开源分布式计算平台,为用户提供了系统底层透明的分布式基础架构。随着大数据相关技术的发展,Hadoop已发展成为众多子项目的集合,包括MapReduce. HDFS. HBase. ZooKeeper.Pig、Hive、Sqoop等子项目。
HDFS是Hadoop集群中最基础的部分,提供了大规模的数据存储能力;MapReduce将对数据的处理封装为Map和Reduce两个函数,实现了对大规模数据的处理;HBase (HadoopDatabase)是一个分布式的、面向列数据的开源数据库,适合于大规模非结构化数据的存储
Zookeeper提供协同服务,实现稳定服务和错误恢复;Hive作为Hadoop上的数据仓库;Pig是基于Hadoop的大规模数据分析平台,提供类似SQL的查询语言Pig Latin; Sqoop主要用来在Hadoop和关系数据库之间交换数据。其中最重要的两大核心技术为:HDFS和MapReduce,下文将对这两大核心技术做重点介绍。
2 HDFS技术
HDFS (Hadoop Disrributed File System)是Hadoop中的分布式文件系统,是对Google的GFS (Google File System)的开源实现。HDFS的一个最重要的设计思想是“一次写入,多次读取”访问方式,将大规模数据切分成Block数据块进行存储,简单的系统设计使得HDFS只能完成数据的写入和读取,不能对数据进行修改,利用大量的廉价硬件设备实现并行读写和大规模数据存储。
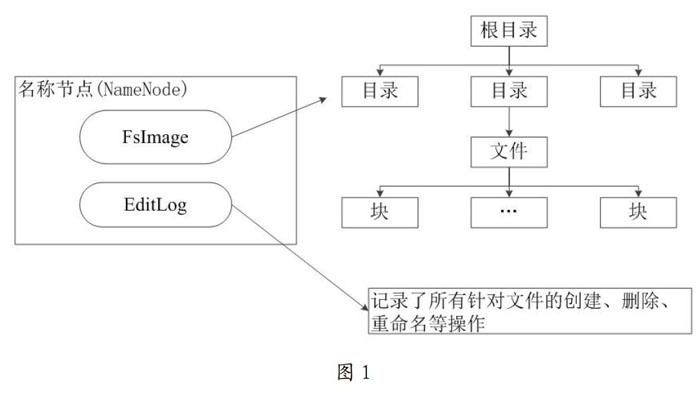
HDFS采用主从设计结构,通常一个HDFS集群中包含一个名称节点(NameNode)和若干个数据节点( DaraNode)。名称节点负责管理文件系统的命名空间,它保存了Fslmage和EditLog两个核心的数据结构如图1所示。
Fslmage记录了所有数据节点中文件的元数据信息,EditLog作为系统日志文件保存了所有针对文件的各种操作信息。名称节点记录了每个数据块所存储的数据节点的位置信息,但是每次系统重启时会重新加载这些信息动态更改和保存这些信息。Fslmage中的信息会在名称节点启动时将其加载到内存中,然后执行EditLog中所保存的操作信息使得内存中的元数据信息一直保持最新状态。
数据节点主要负责对数据的存储和读取,根据客户端或名称节点的调度完成对数据的存储和查询,并定期将自己所保存的数据块的信息发送给名称节点。每个数据节点中的数据会被保存在各自节点的本地Linux文件系统中。
3 MapReduce技术
MapReduce是谷歌公司的核心计算模型,Hadoop框架中的MapReduce是对谷歌公司的MapReduce的开源实现,是为了解决大规模数据的高效处理问题,将运行在大规模集群上的并行计算过程高度地抽象成两个函数:Map和Reduce。MapReduce将存储在分布式文件系统中的大规模数据集切分成许多独立的分片( split),这些分片可以被多个Map任务并行处理。MapReduce設计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”,大大减少了网络传输开销。
MapReduce分布式并行编程使程序员只关注Map和Reduce函数的实现,而不需要处理分布式存储、工作调度、负载均衡等问题,这些问题均由MapReduce框架进行处理,Map和Reduce函数都是以键值对的形式作为输入,按照一定的映射规则再通过键值对进行输出。
Map函数的输入来自分布式文件系统的文件块,可以是二进制文件也可以是文档文件,Map函数将其输入按照规则转换为键值对,键和值的类型是任意的,键并不能作为唯一标识,一个Map任务也可以生成多个相同键的键值对。
Reduce函数就是将输入的具有多个相同键的键值对以某种方式组合起来,输出处理后的键值对,将输入结果合并成一个文件。
4 结束语
大数据作为继云计算、物联网之后IT行业又一颠覆性的技术,备受人们关注,Hadoop作为存储处理大规模分布式系统框架提供了分布式存储的HDFS和分布式处理的MapReduce,也包括其他的子项目,Hadoop的生态国会越来越完善,大数据技术必将引领IT行业走向新的巅峰。
参考文献
[1]林子雨,大数据技术原理与应用 概念、存储、处理、分析与应用[M].北京:人民邮电出版社,2016.
[2]夏靖波,云计算中Hadoop技术研究与应用综述[J].计算机科学,2016 (11):43.
