SAP系统环境下通过软件优化方式高速处理大批量数据的方法
2018-02-25王建文

摘要 目前采用SAP产品的通常为大型企业,这些企业的数据特点体现为数据表多、数据量大、数据关系复杂。有关技术人员在二次开发工作中,都无法避免超大数据量的运算,而硬件升级的办法(比如采用SAP HANA系统)则以投资大、周期长困扰着相关企业。本文将以某单位的异常订单监控程序为例,介绍直接通过软件优化,高速处理超大数据量信息的方法。
【关键词】SAP ABAP算法优化 大批量数据处理
1 引言
在信息化系统的深化应用过程中,许多企业都面临着如何快速处理海量数据的问题。以某单位的SAP ERP为例,其财务数据量以亿记,物料、工艺数据量以千万记,其它业务数据量也多以百万记,如果无法快速地对这些数据进行计算,这些海量数据中蕴藏的价值就得不到有效地利用。
SAP公司提供的HANA系统或者其它实施公司的硬件升级方案,效果虽然明显,但成本通常在千万以上、实施周期以年计。故本文将以实例介绍低成本、短周期,依靠软件优化方式快速处理大批量数据的方法。
2 背景
2.1 传统处理大批量数据的方法及其局限性
第一种常用处理大批量数据的方法是中间表方式。以财务月结为例,如果直接利用原始凭证信息生成月结表速度将非常缓慢。所以最好的办法是,每月关账时运行后台程序(可参考本人论文《利用SAP PORTAL平台实现门禁信息查询》第二章),将计算结果存入中间表,等到需要月结或年度报表时,直接利用中间表生成报表。这种方法用户体验好,缺点是时效性不强。
第二种常用处理大批量数据的方法是分批处理。以人力资源的组织结构为例,大型企业的组织节点(SAP中将人员也视为组织节点,以便于生成组织树)达到几十万个,生成组织结构图极其缓慢。于是我们将每个节点及其以下三层算作一个“批次”,首先仅展开根节点及其以下三层,如果用户双击某个节点,再展开这个节点下面三层,以此类推。这是因为用户真正要查看的组织和人员往往只占所有组织节点的很小一部分,大量数据对于用户而言是无用的,排除无用数据的计算可以大幅增加数据处理速度。
2.2 异常订单监控任务的特点
某单位的异常订单监控任务,具有四个特点:涉及数据庞大、计算逻辑复杂、及时性要求高、无用数据少。这决定了传统的中间表方法和分批计算的方法此处并不适用,只能另辟蹊径。
3 SQL语言优化方法
3.1 合理减少连接( JOIN)数据表的数量
如果将所有表格进行连接( JOIN),形成的笛卡尔积最高可达到10^56次方。要加快取数速度,首先要减少连接表的数量,一些跟输入条件没有直接关系的数据表,最好排除出主SQL语句,然后另行处理。
本程序的输入条件包括工厂、订单类型、分厂、生产订单、物料号、WBS号、工作中心、交货时间,与之有关的表格为AFKO、AFPO、AUFK、AFVC、CRHD、PRPS,
故这6个表格需要在主SQL语句中互相连接。此时主SQL的数据明显减少。而其它数据表则另行用单独的SQL写入各自对应的临时内表,再通过READ TABLE方法填入主内表(若内表键值己排序,按键值二分法查找速度会更快)。
另外,如果我们只想用READ TABLE判断某行数据是否存在,而不需要读取该行数据,可以在READ TABLE最后增加TRANSPORTING NO FIELDS关键字,进行加速。
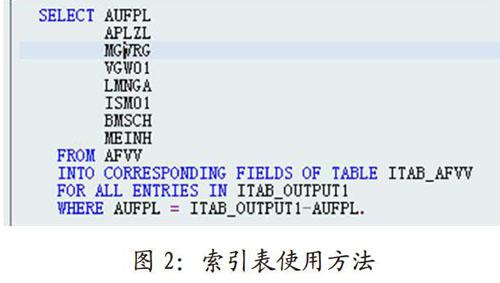
对于那些数据量大的表(如AFVV含2100多万条数据,MAKT含200多万条数据),直接读取不仅慢而且占用大量内存空间,故需要索引表的协助。如图1,我们用索引表ITAB OUTPUT1复制了主内表ITABOUTPUT的数据(含有我们需要的数据的键值),按工艺路线号( AUFPL)排序,再删除重复的工艺路线号,就可以得到工艺路线号的索引表。
如图2,我们用索引表ITAB OUTPUT1作为条件,快速从AFVV表中读取需要的工序数据,而主内表则可在循环中通过READTABLE快速从临时内表ITAB AFVV中填补上每行的工序数据。使用索引表需要注意两点
(1)索引表为空时,取数速度反而比普通SQL更慢,所以应避免索引表为空;
(2)索引表做“等于”比较时速度很快,但是做“不等于”比较时,会让数据库各行遍历比较索引表各行,非常耗时,所以应避免“不等于”比较。
另外,出于节省内存空间的考虑,使用完的索引表和临时内表应该及时清空。
3.2 强化筛选条件
SQL对数据的筛选有两处,一处为连接( JOIN)后面ON的条件,一处为WHERE条件。前者会首先执行,可以有效避免数据表做笛卡尔乘积,但它们的逻辑比较简单,通常是键值的计算,很难把逻辑做强。我们通常强化的是后面的WHERE条件。
若仅仅以输入条件(见2.1节)作为筛選条件,其单次取数耗时依然在5分钟以上。在东电的业务中,工作中心数据、物料数据均跟工厂编号存在逻辑关联(例如工作中心编码和分厂编码存在对应关系),同时工序控制码、订单类别、项目编号也可以增加约束条件(例如外协工序和说明工序,就不用考虑报工的问题),故我们可通过增强筛选条件的方式减少不必要的取数工作。
如图3,尽管输入条件只有8个,但我们底层代码的筛选条件却多达15个,将SQL取数时间从5分钟以上缩减到3秒以内。
注意:
(1)筛选条件中应避免通配符的使用;
(2)各企业数据规范不同,故增强筛选条件的方式也会不同,需要根据实际情况进行选择。
3.3 使用游标( CURSOR)
SQL语言取数时会将数据临时存到内存的结果集,而游标就是指向结果集的指针。本身逐行操作是慢于普通SQL的,但是由于SAP的内存管理机制,特定情况下游标反而体现出性能优势。
一旦物理內存不足,SAP系统会向SWAP请求扩展空间,此时运算会变得很慢。如果连扩展空间都不足,则会报内存错误,甚至无法正常取数。游标在这时不仅能保证取数正常,还快于一般的SQL。如图4所示。
注意:
(1)只有数据量特别大而筛选条件较少时,显式游标的性能优势才能体现出来;
(2) -般情况应避免使用游标;
(3)游标使用后需要关闭,否则会内存泄漏。
3.4 使用提示( HINTS)
ABAP语言也支持在SQL中使用提示(HINTS),我们可以通过提示设定检索数据表的索引、连接顺序、索引表、SQL执行方式等工作。
通过事务代码sell表找到需要优化的数据表,通过转到.>索引即可创建或管理该数据表的提示索引。图5例子中,我们为了二级成本核算在CSKS表增加了Z01索引,在SQL语句的FROM后增加“%HINTSORACLE'INDEX(”CSKS””CSKS~Z01”)”,就可以用Z01中的字段代替键值进行检索,从而加速。
注意:索引的设计非常依赖各个业务单位的数据规范和技术人员的个人经验,所以一般不推荐使用。
4 针对逻辑代码的优化
4.1 避免递归和多重循环
在对SQL语言进行优化后,我们获得的主内表数据从25万行缩减到了10万行。虽然主内表的行数明显减少,但是要快速处理这些数据,依然不得不对逻辑代码进行优化。传统上软件工程师用递归或多重循环的方式处理联合订单,我根据业务逻辑设计了用标志位代替递归和多重循环的算法。
我们将订单状态和工序状态,抽象为了4个类型,当我们按订单号从大到小排列时,循环就会按照从上层到下层的顺序遍历这些订单行,并标记其订单状态、工序状态、子订单状态、子工序状态。而我又将错误类型抽象为5个类型,并列出了状态与错误类型的对应关系。
根据状态与错误的对照关系,我们可以有效判断各行是否出错,出错类型是什么。我们对数据的判断和分类,只需要一次循环加一些READ TABLE操作即可完成。使用标志位还有两个优点:
(1)编号有扩展性,可适应追加需求;
(2)当标志位满足不进行后续计算的条件时,就可以直接省略后续计算。
根据不同的业务逻辑,工程师可以采用不同方式回避递归和多重循环的存在。标志位这种方式与控制工程的原理类似,是适用性比较广的方式。
4.2 使用字段符号( FIELD-SYMBOLS)
ABAP循环默认使用工作区指向循环的各行,工作区是单独开辟的内存地址。如果我们修改各行数据,需要先修改工作区,然后再通过逻辑条件寻址,再修改内表所处的内存地址,一旦内表过大,这种计算方式就会非常缓慢。字段符号(FIELD-SYMBOLS)是直接指向内表各行的指针,允许我们直接修改内表以节省寻址时间。如图6所示。
4.3 谨慎使用删除和修改操作
ABAP中对内表进行删除(DELETE)和修改( MODIFY)操作,使用WHERE语句作为判定条件,其原理是遍历内表,找到符合条件的行,再进行操作。因为需要遍历内表,在内表特别庞大时这种操作极其缓慢。对于这类操作,第一是尽量不使用,第二是必须使用时尽量在循环外使用,第三是必须在循环内使用时应使用索引(INDEX)而不是判定条件。
对于删除操作,可以先在循环时将要删除的行做好标记,然后再在循环外统一删除。在图7中,我就是在循环外统一删除了DESCRIPT__ NO为-l(即需要删除的标记)的所有行。这样也便于计算行序,因为ABAP中每次删除操作后,行序都会重新置O,不利于使用索引进行定位。对于修改操作来说,可使用字段符号(见4 2节)避免大部分有关操作。
对于不得不在循环中使用的删除或者修改操作,需要使用索引。在图8中,我们利用INDEX关键字,直接用索引找到内表的对应行进行修改,避免了复杂的匹配运算。另外,我们可以利用TRANSPORTING语句限制要修改的数据有哪些,也可以加快计算速度。
4.4 字符串计算优化
订单状态和工序状态,本质是多个状态构成的字符串,所以这类程序必然涉及到字符串计算。合理使用&&计算代替拼接( CONCATENATE)计算,使用CS、NS等基础计算代替分割( SPLIT)和寻找(FIND)计算,都可以有效地进行计算加速。
比如,当我判断订单状态是否包含是否为交货(DLV)时,需要判定订单状态字符串是否包含“DLV”这个状态。传统做法是用空格分割字符串再分别比较,或者遍历字符串寻找“DLV”状态。而优化算法的伪代码可写成“IFSTTXT CS 'DLW AND STTXT NS 'PDLW'(即当前状态文本包含DLV字符串但不含PDLV字符串),速度会比分割比较或者遍历寻找快得多。
需要注意的是,ABAP语言在进行字符和数字之间的计算时,会在底层进行格式转换计算,速度是比较慢的。故设计程序时最好避免字符和数字间的运算。
5 辅助工具
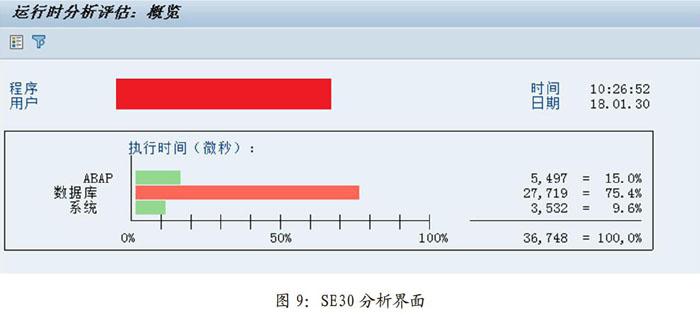
如图9所示,若程序员无法凭借经验判断程序哪个节点比较耗时,则可借助SAP自带的程序运行时间分析工具(事务代码se30),该工具可以协助程序员看到各个节点的耗时和耗时比重;若程序员希望看到数据库操作的细节性能,则可以使用事务代码ST05追溯SQL的运行轨迹。通过对程序各部分执行效率的分析,我们就可以采取有针对性的优化。
此外,ABAP语言提供了“GET RUNTIME FIELD tl”(tl为程序员定义的整型变量)这种语句,该语句可获取程序当前时间(时间单位为微秒)。程序员可以在不同位置安插该语句,然后通过获取的时间差值来评估程序的效率。
6 结语
异常订单监控程序在优化前运行时间超过36分钟,而在优化后运行时间压缩到5分钟左右,对于用户体验提升巨大。技术人员可以根据情况选择本文的算法优化或2.1节介绍的方法高速处理大批量数据。在提升系统效率、挖掘数据资源方面,软件优化的方法跟硬件升级的方法一样,都是可行且有效的。
参考文献
[1]兔宝.SAP ABAP游标的使用(示例)[OL] http://blog. csdn. net/szlaptop/article/details/8565285.
[2] Twilight.ABAP MODIFY语句如何高性能修改内表中多条数据[OL].http://bbs.sapclub. cc/thread-490-1-1. html.
[3]王建文.利用SAP PORTAL平台实现门禁信息查询[J].中国管理信息化,2016,19 (01).
