ARIMA模型在平均工资预测中的应用
2018-02-25李媛
李媛


摘要 将数据挖掘技术中的时间序列分析方法应用于职工平均工资预测中,以中国劳动统计年鉴1985-2010年的数据为研究对象,基于ARIMA模型的时间序列方法对平均工资进行预测,通过对数据序列进行平稳性检验、单位根检验,运用差分的方法将序列转化为平稳序列,分析模型建立的可行性。对模型进行参数估计,运用AIC准则筛选合适模型,预测2 011-2 015年我国城镇就业人员平均工资,将预测值在合理误差范围内的模型进行残差白噪声检验,得出最终模型,从实用层面评估了预测模型的建模方法和预测数据的可信度。
【关键词】工资预测 时间序列分析 ARIMA模型 数据挖掘
工资是劳动者劳动收入的主要组成部分,是衡量收入、分配与劳动力发展水平的重要指标,也是国家宏观经济调控的杠杆,是劳动力布局、产业结构调整的参考依据。有效进行平均工资预测,为劳动经济决策提供依据,对研究劳动经济发展趋势有重要意义,因此,必须进行工资预测。现如今很多专家学者运用多种方法对工资进行预测,如线性回归法、指数平滑法、Logistic模型等。将就业人员平均工资按年计,构成一个时间序列,称为工资时间序列,对其可用时间序列分析的方法建模和预测。
时间序列是系统中某变量的观测值按时间顺序(时间间隔相同)排列成一个数值序列,展示研究对象在一定时期内的变动过程。通过处理预测目标本身的时间序列数据,获得事物随时间的演变特性与规律,进而预测事物的未来发展。时间序列分析就是从中寻找和分析事物的变化特征、发展趋势和规律,它是系统中某一变量受其他各种因素影响的总结果。时间序列数据区别于普通资料的本质特征是相邻观测值之间的依赖性,或称自相关性。本文尝试运用时间序列数据分析中常用的ARIMA模型对我国城镇单位就业人员平均工资进行分析并做出预测。
1 ARIMA模型
1.1 平稳性检验
根据ARIMA算法的建模步骤,可知ARIMA模型是以平稳随机序列为前提的,因此需先检验平均工资的平稳性。本文选用1980到2010年的数据建立模型,以此对2011-2015年平均工资进行预测,并与实际值进行比较。
建立ARIMA模型前,先做序列图,分析发现因我国平均工资逐年增加,为非平稳时间序列。
1.2 单位根检驗
接下来进行单位根检验,采用ADF检验法,得出序列相应的检验式是:
AYt= 0.1940Yt_1+0.2700AYt_1 - 0.7257AYt_1
因为ADF=4.8889,分别大于1%、5%、10%三个显著性水平的临界值-2.6501、.1.9534、-1.6098,表明我国1980-2010年平均工资序列yt存在单位根,是一个非平稳序列。
在此情况下,继续对平均工资的一阶差分进行单位根检验,得出ADF=2.7545,分别大于1%、5%、10%三个显著性水平的临界值-3.6999、-2.9763、-2.6274,表明我国1980-2010年平均工资一阶差分序列D(Y)存在单位根,是一个非平稳序列。
因此,继续对平均工资的二阶差分进行单位根检验,得图1。
因为ADF=-5.9091, 分别小于1%、5%、10%三个显著性水平的临界值-4.3393、.3.5875、-3.2292。判断平均工资二阶差分序列D(Y-2)是一个平稳序列。
1.3 ARIMA时间序列模型建立
由于我国平均工资水平一直增长,因此判定为无周期,可采用ARMA(p,q)模型。需计算平稳时间序列的样本自相关系数(ACF)和偏自相关系数( PACF),然后依此来估计p、q值。
做出二阶差分后序列D(Y,2)滞后12期的ACF图和PACF图,得图2。
由图2可看出自相关系数和偏相关系数均为拖尾,初步识别该模型ARMA(p,q)。
1.4 ARIMA模型参数估计
选用最佳准则函数定阶法,即AIC准则,在模型参数极大似然估计的基础上,对模型的阶数和相应参数给出一组最佳估计。AIC准则是在给出不同模型的AIC计算公式基础上,选取使AIC达到最小的那一组阶数为理想阶数。列举比较选择法知,可能拟合的模型为ARMA(p,q)。
因此对差分序列D(Y,2)分别估计下面若干模型:
AR(1) AR(2) AR(3) MA(1) MA(2) MA(3)MA(4) MA(5) MA (6) ARMA(1,1) ARMA(1,2)ARMA(1,3) ARMA(1,4) ARMA(1,5)ARMA(1,6) ARMA(2,1) ARMA(2,2) ARMA(2,3) ARMA(2,4) ARMA(2,5) ARMA(2,6)ARMA(3,1) ARMA(3,2) ARMA(3,3) ARMA(3,4)ARMA(3,5) ARMA(3,6)
对AR(1)模型进行拟合,从模型的整体拟合效果来看,调整后的决定性系数,AIC和sc准则都是选择模型的重要标准。得出AIC=14.84753, SC=14.94269。
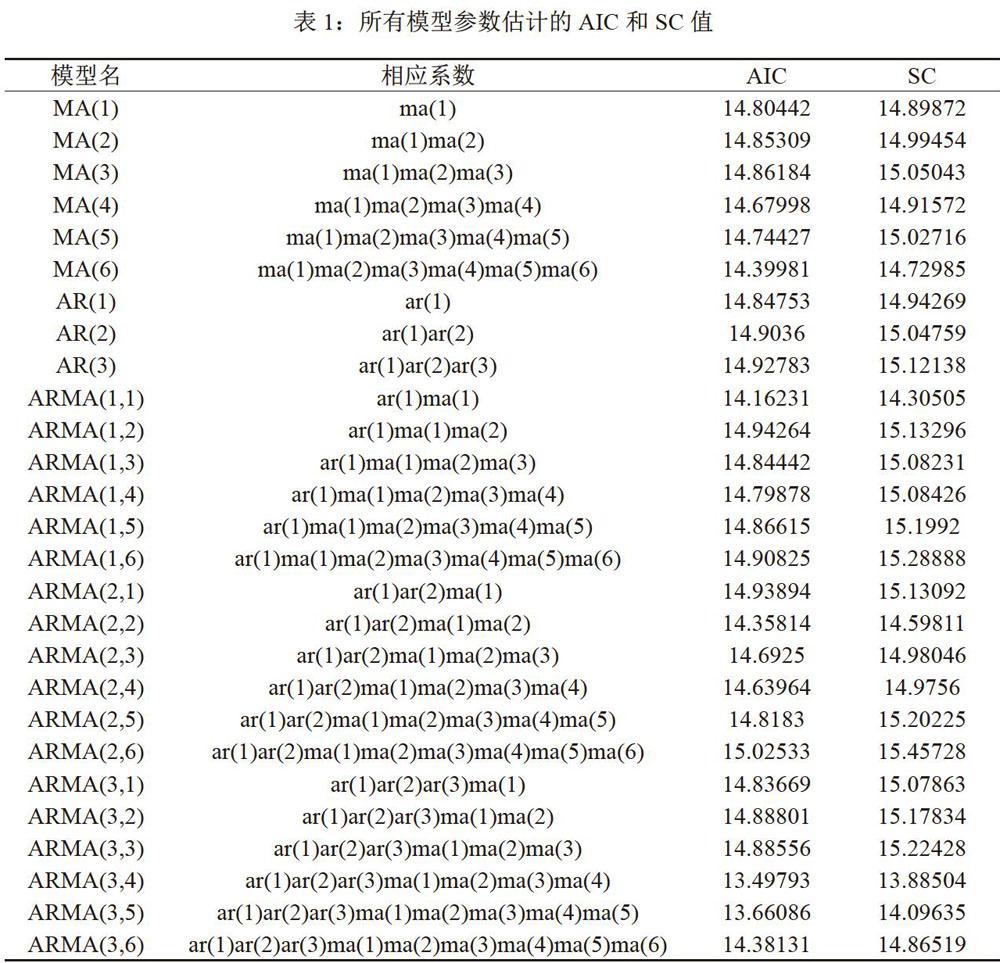
同理,对其他模型进行相应参数估计,得到模型参数估计的AIC和SC如表1所示。
由表1可知, 模型ARMA(1,1)、ARMA(2,2)、ARMA(3,4)、ARMA(3,5)、ARMA(3,6)的AIC和SC值比较小。由于原始序列做了二阶差分后才平稳,因此,选择对ARIMA(1,2,1)、ARIMA(2,2,2)、ARIMA(3,2,4)、ARIMA(3,2,5)、ARIMA (3,2,6)这5个模型进行预测。
1.5 模型预测结果
各模型对应的预测值及误差如表2。
由表2可看出,模型ARIMA(1,2,1)、ARIMA(2,2,2)、ARIMA(3,2,4)、ARIMA(3,2,5)相对误差较少,因此,初步选定这4个模型作为预测模型。
1.6 残差白噪声检验
参数估计后,需对模型残差序列進行白噪声检验,若残差序列不是白噪声序列,意味着残差序列还存在有用信息没有提取,需进一步改进。
检验模型ARIMA(1,2,1),生成残差序列的自相关分析图,存在P值小于0.05,不是白噪声序列,则不平稳。
再检验模型ARIMA(3,2,4),生成残差序列的自相关分析图,发现所有P值大于0.05,是白噪声序列,则平稳。
同理, 检验模型ARIMA(2,2,2)、ARIMA(3,2,5),均存在P值小于0.05,不是白噪声序列,则不平稳。
因此,最终选择模型ARIMA(3,2,4)做为预测模型,其对应的2011至2015年平均工资预测值依次为:41609、46722、51994、57915. 64232。
2 结论
运用模型ARIMA(3,2,4)对2011-2015年的平均工资进行预测,并与实际值比较,发现其误差介于-0.4546%至3.5516%之间,证明此模型具有较高精准性。当然,任何一种预测方法都是建立在一定假设条件基础之上,而任何一种假设条件都难以包含现实世界中的所有复杂关系,相对而言,此模型对于中短期平均工资预测精确度较高。
本文所建模型是依靠滞后信息建立的平均工资预测模型,可以不用考虑数据采集成本。最终所选模型的p为3,q为4,是符合模型建立的简单原则的。但在采用列举比较选择法时,所选模型数据有限,因此在更加精准的预测平均工资水平上,还需要进一步尝试、思考和研究。
参考文献
[1]国家统计局人口和就业统计司,人力资源和社会保障部规划财务司,中国劳动统计年鉴2016 [M].北京:中国统计出版社.2017.
[2]马慧慧.Eviews统计分析与应用[M].北京:电子工业出版社,2016.
[3]周英,卓金武,卞月青,大数据挖掘系统方法与实例分析[M],北京:机械工业出版社,2016.
[4]韩绍庭,周雨欣,多元线性回归与ARIMA在中国人口预测中的比较研究[J].中国管理信息化,2014,17 (22):100-102.
[5]张良均,杨坦,肖刚,徐圣兵.MATLAB数据分析与挖掘实战[M].北京:机械工业出版社,2015.
[6]池启水,刘晓雪.ARIM模型在煤炭消费预测中的应用分析[J].能源研究与信息,2007,23(02):117-123.
[7]易丹辉.时间序列分析:方法与应用[M],北京:中国人民大学出版社,2 011.
[8]汤志浩,张璐,基于平均工资预测的数学模型[J],湖南工程学院学报,2015,25 (03): 42-45.
[9][美] Daniel T.Larose, ChantalD. Larose著,王念滨,宋敏.裴大茗译.数据挖掘与预测分析(第2版)[M].北京:清华大学出版社,2017.
[10]李生彪.基于阻滞增长模型的山东省职工的年平均工资预测[J].时代金融,2013,543:124-125.
