结合TFIDF方法与Skip-gram模型的文本分类方法研究
2018-02-23邬明强张奎
邬明强 张奎


摘要 随看时代的发展,各种各秤的数据信息不断涌现,如何正确有效地对各种类别信息加以分类、区分,是一个很有研究价值的问题。本文在传统的TFIDF模型的基础上,结合了Skip-gram模型,通过对给定语料库的文本进行类别训练,得到了文本的类别向量,接着计算出文档向量和各类别向量的相似度对文本进行分类。实验证明,该方法在给定的语料库范围内,取得了较好的测试性能,准确率、召回率、F1明显优于余弦定理方法。
【关键词】TFIDF模型 Skip-gram模型 文本分类
1 引言
随着计算机不断普及,因特网进入了大数据时代,海量的各种类型的数据信息不断涌现,给我们提供方便的同时,也带来了一定的挑战:如何有效地组织和管理这些信息,并且快速、准确、全面地从中找到用户所需要的信息是一个亟待解决的问题。这里就用到了文本分类术。
文本分类是指用电脑对文本集按照一定的分类体系或标准进行自动分类标记,从而为每一个文档确定一个类别。主要包括预处理、索引、统计、特征抽取、分类器、评价等步骤。
在过去几十年里,国内外学者提出及改进了一系列关于文本分类的算法,其中比较著名的如k近邻分类( k-NN)、朴素贝叶斯分类、支持向量机(SVM)及TFIDF等,现如今仍然被一些学者采用。传统的方法由于技术不太成熟,所以准确性仍有待提高。
本文结合TFIDF方法和Skip-gram模型的方法实现文本分类,既能考虑到词汇在相应文档的重要性,又能体现词和词之间的语义关系,文本分类效果较好。
2 方法
2.1 TFIDF方法简介
TFIDF方法是一种基于词频与逆文档频率的统计方法,主要用来评估一个字词对于文件集或语料库中的一份文档或一个类别的重要程度。它的思想为:如果某个词或者短语在一个类别中出现的频率较高,并且在其他类别中很少出现,则认为此词或者短语具有很好的类别区分能力,这种方法主要用来分类。其中TF被称为.词频,用来衡量词w在文档d中出现的频率,而IDF被称为逆文档频率,它代表了词w的类别区分能力,包含词w的文档越少则该值越大。TF和IDF的计算公式如下式(1)和式(2)所示。
2.2 Skip-gram模型介绍
Skip-gram以此得到词向量。而词向量的基本思想是将每个词映射成一个k维实数向量,Skip-gram模型是Mikolov等人提出的一种可以在大规模数据集上进行训练的神经网络语言模型。本文的做法是使用Skip-gram模型在语料库上进行训练,一般在1000维一下。Mikolov等人指出相比于传统的语言模型,基于神经网络语言模型NNML得到的词向量对词的表示更加准确,这种模型可以快速地完成对数十亿词的大规模数据的训练,进而来得到词向量在词语上的表示,这种表示方法能够使结果更加准确。利用词向量对词语进行表示后,可以方便地通过向量来计算词和词之间的相似度,然后再进一步根据相似度值的大小,对文本的类别进行判断。
使用Skip-gram模型得到的词向量在词语的表示上比传统方法更准确,它还能通过加法组合运算挖掘词与词之间的语义关系,能够很好地弥补TFIDF方法在语义表示上的不足。
2.3 本文分类方法及过程
2.3.1 本文文本分类方法
首先,计算出tfidf值最大的若干个词语,然后把这些词语转化成当前文本的词向量表示形式,接着计算出当前文本的词向量和其中一类的文本类别向量的余弦相似度值,接着用该值和给定的文本类别的阈值相比较,根据比较结果来对该文本进行分类。
2.3.2 分词和去除停用词
因为分类方法中主要用到词的权重和词的语义关系,所以对于一篇给定的文档,我们先要进行分词,分词操作是中文信息处理的基础,本文用到的分词工具为中科院研制的ICTCLAS,它是一种汉语词法分析系统,分词精度达到了98.45%,是当前比较流行的汉语词法分析器。它主要以句子为单位对其中的词语进行切分,切分的同时带有词性标注,通过该词语标注的词性能够更加方便地对词语和文章进行研究。
分词后还需进一步进行去除停用词,停用词主要指存在文章中的一些频率比较高的词,但是对表示文章的主题没有作用或没有影响的一些词,比如常见的有“的”、“在”、“接着”、“于是”、“但是”等一些词及常用的标点符号。这一类词主要有语气助词、副词、介词、连词等,它们本身没有明确的意义,但是可以用来连接一个完整句子。本文选取了519个停用词,这些词放在一个停用词表中。在文本分类工作中,为了提高分类的准确率、减少一些噪音的干扰,可以在文章分词完毕后,根据提前设定好的停用词表去除文本中的一些停用词。本文的停用词表是存放在一个记事本文件中,分词完毕后利用java语言中的正则表达式和字符串的相关概念对当前文档中的停用词进行了去除。
2.3.3 计算tfidf值
根据前面所提到的tf和idf公式,分别计算某个词在当前文档出现的次数、语料库中包含该词的文档数量及语料库中所有文档数,进而得到某个词的tfidf值,给定一篇参与计算的文本,首先从中选取N个词,这N个词能够代表文章的语义,利用上面的公式共同计算出每一个词语的tfidf值,然后从中挑选出n个tfidf最大的值作为当前文档的特征词。由于人工选取特征词的个数一般为3~7个,所以為了方便这里取n的值为5,由于这些词能够很好地体现它在该篇文档中的重要程度,所以我们可以把它们作为当前文档主题词。
2.3.4 文本的向量化表示
接下来将对每一个这样的词语进行词向量表示,根据向量的加法原则,可以将原本独立的词向量累加得到文档的词向量,这样就得到了该篇文档的向量表示,这样得到的向量表示实质是经过TFIDF模型加权后的向量表示。
根据文档的主题词,分别统计其在语料库中所占的权重值,构成了不同的词向量,设语料库中总共有s篇语料,分别存放在s个记事本文件中,那么第i个词的词向量可以表示为(vil,vi2,…,vis),根据向量的加法规则将主题词的词向量相加并归一化处理,就得到了当前文档的词向量表示。假设当前文档归一化的向量为vt。
2.3.5 文本类别的向量表示
对于给定语料库中提前训练好的文本类别,分别转换成词向量表示形式,同样地,根据向量相加规则求和并进行归一化处理,可以计算出当前文档类别的类别向量表示。
先选取某一类别的文档,这里假设有N1篇,对于其中的每一篇文章,统计出词频最大的N个词,然后分别计算出对应的tfidf值,再选取n个tfidf最大的词作为当前文章的主题词,N1篇文档共有N1*n个主题词,它们共同构成了该类别文档的主题词。设某个主题词在当前类别语料库中的权重分别为vwl,vw2,…,vwNl,那么该主题词对应的词向量为v= (vwl,vw2,…,vwNl),类似地,可以得出其它主题词的词向量。把相应的词向量相加并归一化就得到了当前文档类别的类别词向量。假设计算出的当前这种类别的文档的类别词向量为vs。为了让它的维数和文本向量的维数一致,需要对文本类别向量的维数做适当扩展。
2.3.6 相似度计算
要计算当前选定的文本是否属于现在这个类别时,可以根据余弦定理算出文本向量和类别向量的相似度值即可。设该文本和该类别文本的相似度为sim,如式3所示。
2.4 分类
设文本分类的阈值为6,6的值是根据训练得到的。当sim>=δ,说明该文本与当前类别的相似度较大,这种情况下可以判断出该文本属于当前这个类别;当sim<δ,说明该文本与当前类别相似度较小,该文本不属于当前这个类别,在这个基础上,继续用本文挡的词向量和其它类别的类别向量做相似度运算,如计算的值等于或者超过了阈值δ,则可以判定当前文档属于这个类别。否则继续按照该算法去计算相似度值,进一步对文档进行归类。算法流程如图1所示。
3 实验
3.1 语料选取
本文选取了搜狗新闻的相关语料,其中旅游类、教育类、军事类各100篇,一共300篇作为测试语料。
3.2 测试
采用java语言,同一类的100篇文本分别存储到对应的记事本,为了提高训练速度,程序中也采用了批处理的方法,根据前面提到的计算文本类别向量的方法,首先分别计算出同类别每篇文章中tfidf最大的几个值,存储到一个记事本文档中,在计算该类别文本向量时将记事本中的内容读出,最终得到了文本类别向量。
测试方法如下:用旅游类的100篇文本和旅游类的类别向量计算相似度,教育类和军事类的200篇文本和旅游类的类别向量计算相似度,同样地,其它两类文本分别和相应的类别向量计算相似度,再用不同类的其它200篇文本和该类别文本计算相似度。最终得到一系列相似度值。采用准确率、召回率、F1值作为评判标准。根据训练的结果对选取了一定的相似度闽值进行测试。通过测试过程可以看出,同类的文本相似值比较接近,而不同类的文本计算出的相似度值明显偏小。
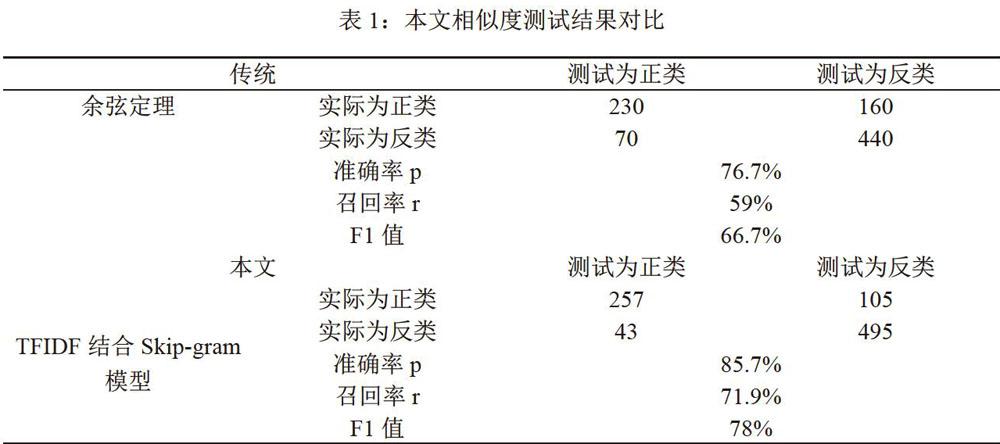
测试结果如表1所示。
可以看出,融合了tfidf方法和Skip-gram模型计算相似度上的优势。
3.3 分类
本文根据训练的情况,分别选取了相应的相似度阈值δ1,δ2,δ3。
给定一篇文本,利用本文的方法和给定类别词向量计算相似度,如果相似度值大于等于该阈值,则可以判定当前文本属于给定的类别,否则不属于该类别。
4 结论
本文在判断文本类别时,利用了TFIDF和Skip-gram相结合的方法来计算,同时考虑了词汇在文本中的重要程度,也兼顾了词与词之间的语义关系,很好体现了Skip-gram模型通过词向量预测上下文的应用,实验证明,该方法在一定范围内是很有效的。
由于选取的语料比较少,同时用到的语料参差不齐,导致测试结果的准确性受到一定的影响。接下来将不断寻找新的语料库,并对语料进行进一步的筛选,同时逐步提高语料的规模,再选取一些更加有效的方法作为文本相似度的训练器,给相似度的实际测试奠定良好的基础。
参考文献
[1]冯园园,短文本分类技术及其场景应用研究[D].硕士学位论文,2017 (01).
[2]张谦,高章敏,刘嘉勇,基于Word2Vec的微博短文本分类研究[J].信息网络安全,2017,18 (01):57-62.
[3]黄承慧,印鉴,候昉,一种结合词项语义信息和TF-IDF方法的文本相似度量方法[J].计算机学报,2011,34 (05): 856-864.
[4]武永亮,赵书良等,基于TF-IDF和余弦相似度的文本分类方法[J],中文信息学报,2017, 31(05):139-145.
[5]李天彩,王波,毛二松等.基于Skip-gram模型的微博情感倾向性分析[J].计算机应用与软件,2016,33 (07):114-117.
[6]熊富林,邓怡豪,唐晓晟.Word2vec的核心架构及其应用[J].南京师范大学学报(工程技术版),2015,15 (01): 43-48.
[7]张群,王红军,王倫文.词向量与LDA相融合的短文本分类方法[J].现代图书情报技术,2016 (12):26-35.
[8]黄贤英,李沁东,刘英涛,结合词性的短文本相似度算法及其在文本分类中的应用[J].电讯技术,2017,57 (01): 78-81,
[9]李妍坊,许歆艺,刘功申.面向情感倾向性识别的特征分析研究[J],计算机技术与发展,2014 (09):33-36.
