大数据时代下爬虫技术应用与研究
2018-02-23黄文杰,姚庚梅
黄文杰,姚庚梅
摘 要:随着互联网快速发展和大数据时代的来临,Web数据逐渐庞大,如何有效并快速地从互联网上获取到用户自身需要的信息是亟需解决的问题,网络爬虫技术应运而生,它是搜索引擎抓取系统的重要组成部分。文章是以标讯快车项目为研究目标,依托本学院在大数据方面的研究优势,结合该院IT特色,具有较强的实际意义和社会意义。
关键词:JavaScript;网络爬虫;Web信息抓取
中图分类号:TP391.3 文献标志码:A 文章编号:2095-2945(2018)06-0037-03
Abstract: With the rapid development of the Internet and the advent of big data era, it is urgent to solve the problem of how to get the information needed by users from the Internet effectively and quickly. Network crawler technology emerges as the times require, it is an important part of search engine grab system. This paper is based on the standard express project as the research goal, relying on the research advantage of big data in this college, combined with the IT characteristics of the institute, has a strong practical and social significance.
Keywords: JavaScript; WebCrawler; Web information scraping
1 網络爬虫的研究现状与分析
搜索引擎的原理是根据用户提交的关键词返回一组URL地址,通过关键词相似度进行优先级排序,用户通过浏览Web页面来寻找所需信息。但这种利用人工的方式来定位信息,仍然有缺乏统一管理的缺点,而且搜索结果精确度不高。此时,网络爬虫(Web crawler)技术的出现至关重要,网络爬虫是目前搜索引擎的重要组成部分,它的基本原则是在不影响服务器执行效率和不造成致命冲击的前提下,提高爬虫的爬行速度,扩大数据下载量以及提升抓取信息的准确率,这项技术的关键点为消除任何影响爬虫爬行效率的障碍,令爬虫达到高效且准确无误。
1.1 网络爬虫效率瓶颈分析
网络爬虫效率受到制约的主要因素有:网络延时和爬虫运行效率;爬虫系统功能模块设计不良;爬虫算法和功能模块之间协同工作效率低;网页服务器适应性差等。
1.2 动态网页的信息抓取
首先,动态网页是通过更新网站后台数据库,从服务器中传递参数而生成的网页。本爬虫采用的方法是通过对动态网页进行解析,对网页数据中进行信息处理并建立索引数据库,重新定义一个自定义标准接口,当爬虫开始对该网页进行抓取前,对网页的URL地址进行判断,若判断该动态网页符合自定义标准接口,爬虫方可开始通过HTTPS的方法下载网页,并建立和导入数据库。
1.3 网页的更新
本项目在更新网页数据库时,通过判断网页属性是否改变来进行更新,利用JavaScript在任何时候都能对任何对象的属性进行动态的增、删、查、改的特性,无需修改爬虫代码而直接进行网页数据的更新抓取。
1.4 JavaScript算法实现
JavaScript语言是一种基于对象的编程语言,本作品使用JavaScript语言进行编程的原因是:JavaScript与其他面向对象的语言不一样,它只有对象的概率,并没有类,它的对象来源于其自身内部的对象,主机环境中的对象和用户创建的对象。本爬虫构建出JavaScript程序的对象层,方法层和语句层,逐层利用语句之间的数据依赖关系。利用函数对JavaScript程序控制全局变量的赋值语句中的左右值,参与语句中的谓词的影响和对象多态继承。利用JavaScript 动态进行时定义对象,实现对网页数据的统一封装。
2 系统设计与应用
2.1 项目设计原理
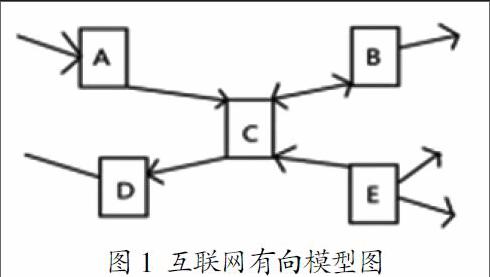
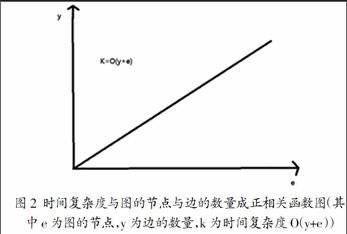
整个Internet互联网就像一张庞大而有向的蜘蛛网,每个网页就像蜘蛛网里的节点,网页相互有向指向其他网站页面的地址,从而构成了互联网。如图1所示,矩形A、B、C、D、E代表网站的页面,箭头代表网页间相互指向URL地址的关系,所以,当爬虫在抓取网页的时候,将会使用有向遍历的算法进行遍历(即下文提出的深度优先策略和广度优先策略)。本作品的主要研究方法在于依据客户要求,对标讯快车平台实施爬虫技术,在抓取网页的时候,使用广度和深度并行的抓取策略,提高其抓取速度。当使用广度和深度优先策略时,其时间复杂度与图的节点与边的数量成正相关关系,即与网页的规模直接相关。(如图2所示)。网络爬虫最理想的设计模型是高速、准确、有针对性地遍历网站中所有网页信息,而要达到这样的设计标准往往使用单一算法是无法实现的,需要对网页数据资源进行针对性的评估后合理地调度,然后对该网络资源设定优先值,优先处理价值高的资源,滞后处理价值低或冷门的资源,再对其进行组合运用算法和爬虫策略。
2.2 项目实现方式
本作品研究的基本思路是针对大数据应用,通过对海量词汇的对比,使用爬虫技术获取到目标客户关注的内容,下载到云平台,再通过程序分析,将所需的数据提取分离出来,提供给目标客户,帮助目标客户进行多维度检索、资质精准匹配、招标代理监测、询价采购、甲方监测等。本研究项目在访问一个站点时,会首先判断URL地址和网页属性,确定需要访问的范围,若判断不超时,则判定该站点为可用网页,继续进行解析,若判断为超时,则将该站点视为无效网页。本爬虫通过初始化客户提供的URL种子,利用HTTP通信下载的方式访问URL对应的页面和下载XML文档,然后解释网页所有的URL提取网页信息并保存网页上的所有数据。爬行循环从解析出的URL挑选出其中一个进行爬行,一个链接一个链接跟踪下去,直到把网页所有的URL爬完为止。本爬虫在读取URL页面时,会首先对URL地址和网页属性进行判断,若程序判断该网页为动态网页,则会自定义接口对其进行适配;若判定超时或出错则默认为该URL页面数据丢失或过期失效,将无效链接URL加入到错误队伍中。反之,就继续读取和解析网页的信息内容。
2.3 项目应用
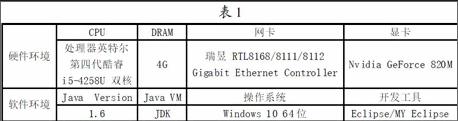
标讯快车是为了配合公共招投标市场、优化采购商和供应商进行全球性贸易的权威电子媒体机构,响应《中华人民共和国招标投标法》而应运而生的专业平台。标讯快车可及时发布国内3000家招投标代理网站保证项目信息,覆盖了大部分国家财政性投资项目和社会投资项目。到目前为止,项目组成员已经通过该公司提供的虚拟桌面,完成了标讯快车平台超过2000个代理网站的爬虫,对抓取的数据进行分析处理,并建立了相应的云项目,为用户极大地减轻了招投标的时间成本,使用户可根据自己的需求精准定制行业信息。独特性方面,由于是针对具体大数据应用项目标讯快车来实施爬虫策略,能让团队成员更及时的对代码优化的结果进行测试和调试。消除重复處理。消除重复处理的主要目的是避免爬虫在遇到页面相互形成环路的网站上反复执行而死循环的情况。因此,本爬虫在访问页面时会进行判断处理,并对已经访问过的URL队列进行base标记,对未访问的URL队列不进行标记。受限范围。当爬虫在访问一般网站时,经常会遇到加密数据或权限的问题,加密数据是无法抓取下来的,有些网页则需要管理员权限才能访问,但本爬虫是针对政府招标网页进行数据抓取,所以一般不存在以上受限问题。无效或过期链接。检查过期或无效的链接也是一个很重要的过程,这样做不仅能提高网页数据的使用率,还可以保证搜索文件的成功率。爬虫效率分析。本项目系统是在实验室的硬件、软件环境下完成的,基本情况如表1所示。本爬虫在进行信息抓取时会构造四个不同的栈堆,分别是等待栈堆,运行栈堆,错误栈堆,完成栈堆。一个初始URL从抓取开始到结束要经历4个过程,为了避免爬虫重复爬行陷入死循环,每一次URL从等待栈堆转送到运行栈堆前,都会先与完成栈堆进行比较,进行消除重复的处理。
2.4 项目成果
使用普通爬虫与本研究项目进行比较,本次采用的比较方法为控制变量法,抓取的网页保护华中,华北,东北,华南四个区域超过600个县级市的政府采购网页,总网页数目2500个。通过比较发现,普通爬虫在12小时处理的网页总数为1407个,本研究爬虫在12小时处理的网页总数为2132个,效率提升超过15%,所有网页并未全部下载的主要原因有读取网页数据超时,系统判断发现无效网页而被舍弃。在爬行过程的最后阶段,爬虫的抓取效率开始下降,其中原因主要是随着时间的推移,爬虫程序开始占用系统资源;硬件环境由于发热开始降频。除了在标讯快车项目实施本项目研究的爬虫技术外,我们还力求与其他行业的公司合作,为互联网的爬虫技术作出贡献,把有效的数据检索、数据匹配、数据监测等信息提供给目标客户手中。
3 结束语
通过改进网络爬虫自身结构设计和调整策略选择来提高爬虫系统的效率,从而消除目前爬虫工作效率低的瓶颈。目前越来越多的科研人员投入到网络爬虫的研究中,针对爬虫策略和爬虫方式的改进方案也逐渐被提出并广泛采用。
参考文献:
[1]李应.基于Hadoop的分布式主题网络爬虫研究[J].软件导刊,2016(03).
[2]刘红梅.垂直搜索引擎主题爬虫搜索策略研究[J].科技信息,2013(08).
