分布式K-means聚类算法研究与实现
2018-02-05李斌,李蓉,周蕾
李 斌,李 蓉,周 蕾
(国网宁夏电力公司信息通信公司,宁夏 银川 750001)
0 引言
随着互联网数据量呈指数增长,传统的数据挖掘算法已经不能适应海量数据。传统的数据挖掘算法使用数据仓库模型把所有数据汇总到中心节点,并在汇总数据的基础上运行数据挖掘算法[1]。这种方式存在很多局限的,比如中心节点的性能瓶颈、数据隐私泄露等问题。为了缓解这些问题,分布式数据挖掘成为了热点研究领域[2]。分布式数据挖掘方法是为了解决在合理时间内无法在单机环境完成某些复杂问题而存在的[3]。分布式数据挖掘具有单机数据挖掘无法达到的优点:首先,有效地解决了数据增多带来地存储、计算方面压力,其次,降低计算瓶颈,将复杂的计算工作改为局部实现再汇总的形式。
现有主流的分布式数据挖掘技术的实现方法大体可以分为以下几类:基于MPI的并行数据挖掘算法研究[4],是在消息传递接口MPI集群基础上实现的分布式数据挖掘算法,以多线程调用的形式实现多机调用执行,但无法有效地协调节点之间任务的调度以及节点的存储和任务分配[5];基于 Agent主体的非集中式数据挖掘技术,是以本节点的数据为基础运行数据读写任务,对于本地数据有一定的安全性保护,但同时也引出了关键问题:局部结果的整合[6]。对这一问题的研究,专家设计并给出多种解决方案。典型的解决方案包括:PADMA(parallel data mining agents)、BODHI( Beseizing knowledge through distributed heterogeneous induction)、JAM(Java agents for meta-learning)等;基于网格的分布式数据挖掘方法[7],提供了可以用来计算和数据管理的基础设施,为在分布式环境下运行数据挖掘算法提供了必备的硬件条件,然而基于网格的数据挖掘方法的资源调度和作业分配是离不开人为干预的;基于云的分布式数据挖掘算法,侧重于使用虚拟化技术为用户提供个性化平台、服务、资源等。近年来,基于云计算的数据挖掘算法是当今分布式数据挖掘最为流行的发展方向,已经投入使用的Hadoop平台为分布式数据挖掘算法的实现奠定了坚实基础[8-9]。
K-means算法是一种常用的数据挖掘算法,在数值聚类[10]、地图聚类[11]、文本聚类[12]、图像聚类[13-14]方面都有广泛的应用。但是串行K-means的时间复杂度比较高,处理能力存在局限性,此外,K-means算法固有的缺点,即需要事先确定聚类个数K,且K的确定容易受主观因素影响,会造成局部最优,导致聚类质量的下降。本文利用分布式计算环境 Hadoop2.x中的 MapReduce编程模型对K-means进行分布式研究和实现,且利用Canopy算法对K-means进行优化,Canopy算法无需实现确定聚类个数,而是通过计算对象间的相似度进行划分,可以解决K-means聚类个数主观确定的缺点。
1 K-means和Canopy聚类算法
1.1 K-means聚类算法的基本思路
K-Means在随机选取K个簇中心点的基础上,计算样本中其他点与这K个簇中心点的距离,实现样本点的分类,分到同一类的样本点再更新簇中心点。由此不断循环直到K个簇中心不变。K个簇中心点是k-Means算法中的输入参数,新的簇中心会根据当前分类的簇按照欧拉公式来计算得到。k-Means算法的目的是让每个簇内的数据点尽量靠近本簇中心,远离其他簇中心。在迭代计算的时候,k-Means把每个数据点分配给距离最近的簇中心群,直至新计算出的簇中心点与上一步生成的簇中心点一致,停止迭代,输出所属类别。
1.2 Canopy聚类算法的基本思路
Canopy算法是一种快速的聚类算法,但在准确度方面比较逊色,作为一种“粗”聚类,其流程可以概述为:
①对于数据集S,有阈值t1和t2,且t1>t2,②S中任选一点x,作为Canopy的候选点,从数据集S中删除点x,
③计算数据集中所有点到x的距离,
④距离小于t1的点归为x,距离小于t2的点归于x类并从数据集S中删除,距离大于t1的点,新建Canopy,从数据集S删除,
⑤重复第二步到第五步直至数据集S为空或者满足最大迭代次数要求。
2 分布式K-means聚类算法设计
2.1 分布式K-means聚类算法设计与实现
分布式数据挖掘算法k-Means聚类算法的实现思想为:
第一步,将数据分到不同的节点上,每个节点只对本地数据进行计算;
第二步,根据全局变量计算本地数据所属的簇;
第三步,根据各个数据点所属的簇,计算出该簇的中心,若与全局簇中心点一致,则输出分类结果;若不一致则用新计算出的簇中心来更新全局簇中心点,则重复第二步,直至新计算出的簇中心点与全局簇中心点一致。
可见,在分布式K-means聚类算法中,每次迭代的算法执行相同的操作,因此,可通过MapReduce编程模型加以实现,分别执行相同的 Map操作和Reduce操作。分为3部分函数:Map函数、Combine函数和Reduce函数:
Map函数对数据集分块,并计算各个数据点到K个中心点的距离,重新标记每个点的所属类别。输入为数据记录文件,输出为每个数据点的所属类别:

输入:聚类文件split输出:<所属类别,数据点>获取簇中心信息;计算本地文件中每一个数据点到簇中心的距离;得到data所属的簇id:
Combine函数根据Map函数的结果完成对本地文件中的簇中心的重新计算。输入为<类别,数据记录>,输出为<类别,局部类中心>:

输入:
Reduce函数是汇总所有节点的结果,根据类别id对重新计算新的簇中心:
整体流程如如图1所示。
2.2 改进的分布式K-means聚类算法设计与实现
K-Means算法存在的不足主要有:聚类个数K根据经验判断,没有理论依据,对于初学者难以准确判断;初始簇中心选取是随机的,会造成局部最优解;离群点对聚类结果的干扰,造成聚类质量的下降。基于这些不足的存在,加入Canopy算法进行优化,Canopy算法的输出为 k-cluster,可以为k-Means算法确定K个聚类及其类中心点。Canopy算法执行过程中,通过对 Canopy的建立,可以删除包含数据点数目较少的Canopy,这些点往往是离群点。
改进的分布式 k-Means聚类算法是将 Canopy算法作为k-Means算法输入,为k-Means算法确定k值、初始聚类点、离散点,来提高 k-Means聚类算法的质量。其算法流程是:对于数据集,首先进行数据集划分成若干子集,然后在每个子集内计算
中心点并按照距离重新进行划分,进而确定簇数以及初始簇心;之后利用K-means算法进行迭代计算,收敛出聚类结果。如图2所示。
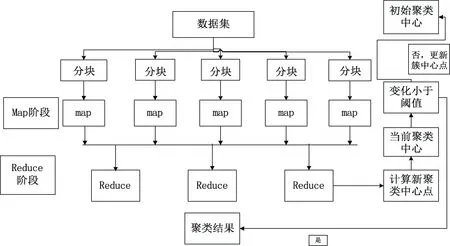
图1 分布式k-Means算法流程图Fig.1 The flow of distributed K-means algorithm
利用 MapReduce模型,Canopy中心点生成的Map函数和Reduce函数设计如下:

Map函数

Reduce函数
利用MapReduce模型,K-means的Map函数和Reduce函数设计如下:将得到的key-value对

Map函数

Reduce函数
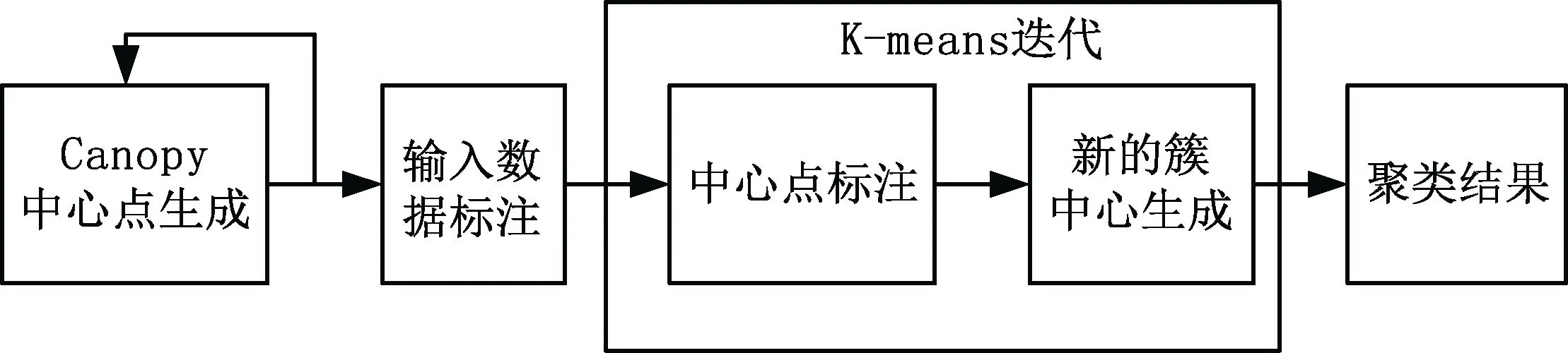
图2 改进的分布式K-means算法流程Fig.2 The flow of improved distributed K-means algorithm
3 实验验证
3.1 实验环境和数据集
实验是在实验室搭建的Hadoop平台上运行的。平台由四台虚拟机构成的虚拟化平台,使用XenServer的服务器虚拟化平台来管理计算机。每台机器的部署环境如表1所示。
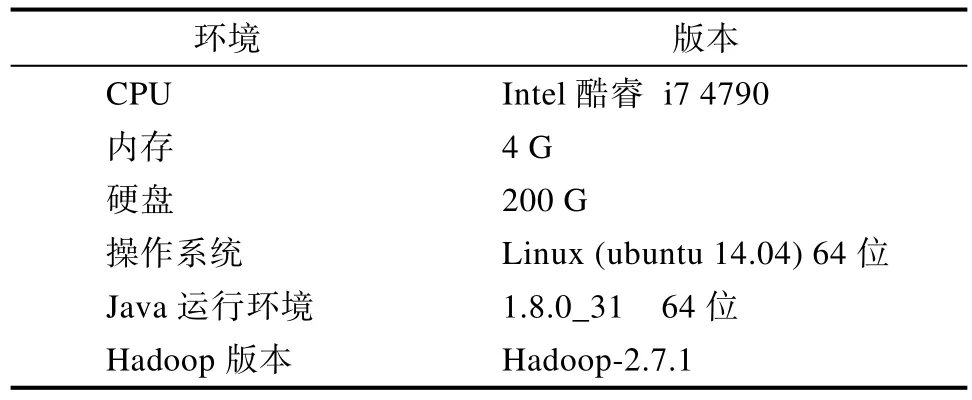
表1 系统部署环境Tab.1 System deployment environment
实验采用的数据是阿里巴巴天池比赛中新浪微博互动预测大赛的数据[15],该数据包括 2014年 7月至2014年12月期间的微博用户转发数、点赞数、评论数以及对应的微博博文内容。实验中构造了40 M、80 M、160 M、320 M、400 M等5个不同大小的数据集。
3.2 实验结果
根据本文搭建的Hadoop平台,包括一个master,三个slave。首先,确定k-Means聚类算法的K个簇初始点,将样本数据分配给各slave节点,将数据分块,在每一个节点计算局部Canopy,各局部Canopy经 reduce函数汇总计算得到全局数据 Canopy。将Canopy文件在master上为各slave端发送,将其作为整体簇中心初始点,同时这些初始簇中心创立全局文件并广播给所有 slave节点,全局文件包括cluster_id,cluster_center,data_number;slave根据接收到的全局文件,判断本机数据所属的簇类别即cluster_id,每一个 slave将其数据按照
表2为改进的分布式k-Means聚类和传统k-Means聚类在40 M、80 M、160 M、320 M、400 M等5个不同大小的数据集的效率对比。
从表2可以看出,分布式k-Means聚类算法由于其算法的迭代运算很多,在新计算出来的簇中心与原来全局变量簇中心不一致的情况下,需要重复迭代运算。因此,在执行小文件的分布式 k-Means聚类算法时无法体现其性能上的优越性。而一旦数据集规模加大,在单机执行大文件k-Means算法时,很容易造成电脑崩溃,而分布式k-Means算法却可以通过多台主机同时运行来进行聚类运算,体现出分布式的性能优势。
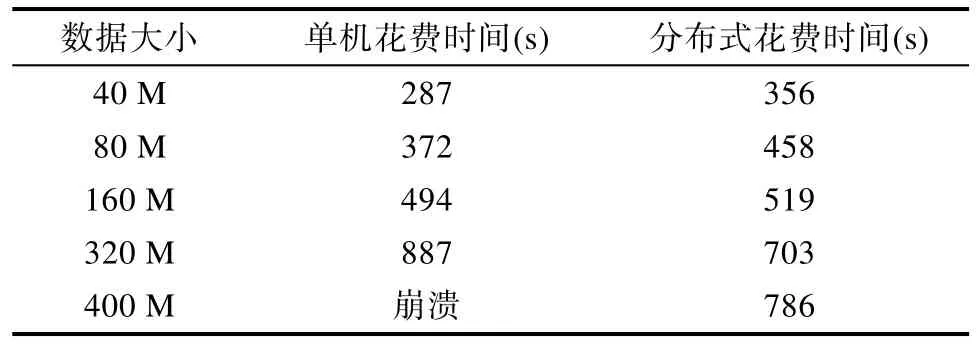
表2 效率对比Tab.2 Efficiency comparison
4 总结
本文利用MapReduce模型研究与实现了分布式K-means聚类算法。分别在单机环境和分布式环境进行了效率对比,可以得出结论:分布式数据挖掘算法在小数据量时无法显示优越性,而对大文件进行处理时,其优越性明显。具体原因是:当有小文件需要处理的时候,每次map只会处理少量的数据,但是会存在大量的Map任务,对Hadoop平台的运行是不利的。但在应对大数据量时,分布式K-means算法就会体现出巨大的优势。
此外,数据挖掘算法的实现是离不开迭代运算的,迭代运算中文件的频繁存取为 Hadoop带来很大的压力,这时基于内存的 spark可以更好的缓解这一问题,但是 spark对于机器内存要求较高。纵观行业背景,实时计算的需求越来越迫切,支持实时计算的storm和基于内存的分布式计算环境spark将成为今后研究的重要方向。
[1] M M Sufyan Beg& C P Ravikumar. Application of Parallel and Distributed Data Mining in e-Commerce[J]. Iete Technical Review, 2015, 17(4): 189-195.
[2] Kargupta H, Park B.Dary H, et al Collective data mining.a new perspective toward distributed data analysis[M]. Advances in Distributed and Parallel Knowledge Discovery.[S.1.]: AAAI/MIT Press.1999: 133-184.
[3] Ninama H. DISTRIBUTED DATA MINING USING MESSAGE PASSING INTERFACE [J]. Review of Research, 2013.
[4] 吕婉琪, 钟诚, 唐印浒, 等. Hadoop分布式架构下大数据集的并行挖掘[J]. 计算机技术与发展, 2014(01): 22-25.
[5] Stankovski V, Swain M, Kravtsov V, et al. Grid-enabling data mining applications with DataMiningGrid: An architectural perspective[J]. Future Generation Computer Systems, 2008,24(4): 259–279.
[6] 余永红, 向晓军, 高阳, 等. 面向云服务的数据挖掘引擎的研究[J]. 计算机科学与探索, 2012, 06(1): 46-57.
[7] Mario C, Hiram G P, Alessia S. Data mining and life sciences applications on the grid[J]. Wiley Interdisciplinary Reviews Data Mining & Knowledge Discovery, 2013, 3(3):216-238.
[8] 王书梦, 吴晓松. 大数据环境下基于MapReduce 的网络舆情热点发现[J]. 软件, 2015, 36(7): 108-113.
[9] 李冠辰. 一个基于hadoop 的并行社交网络挖掘系统[J].软件, 2013, 34(12): 127-131.
[10] 杜淑颖. 基于大型数据集的聚类算法研究[J]. 软件, 2016,37(01): 132-135.
[11] 杨婷婷, 王雪梅. 基于百度地图的改进的K-means 算法研究[J]. 软件, 2016, 37(01): 76-80.
[12] 陈磊磊. 不同距离测度的K-Means 文本聚类研究[J]. 软件,2015, 36(1): 56-61.
[13] 陈慧, 龙飞, 段智云. 一种基于小波零树编码和K-mean聚类的图像压缩的实现[J]. 软件, 2016, 37(02): 33-34.
[14] 郑金志, 郑金敏, 汪玉琳. 基于优化初始聚类中心的改进WFCM 图像分割算法[J]. 软件, 2015, 36(4): 136-142.
[15] https://tianchi.aliyun.com/competition/raceOssFileDownload.do?spm=5176.100068.555.1.tPkxq4&file=weibo_predict_dat a(new).zip&raceId=5.http://www.cnblogs.com/ywl925/archi ve/2013/08/16/3262209.html.
