云环境下电子商务网站商品智能推荐模型设计
2018-01-30陈海红
陈海红
摘要:随着电子商务的普及,商品智能推荐成为越来越多电子商务网站的“标配”。本文基于Abrjot算法提出了一种新的智能推荐模型,并利用MapReduce架构设计了推荐策略。本文还对新模型进行了仿真实验,结果表明,随着求解精度的增加,新算法连接和剪枝过程明显优于传统串行搜索。
【关键词】电子商务 Abrjot算法 MapReduce架构 智能推荐模型
1 引言
近年来,随着互联网的普及,电子商务已经走入寻常百姓家,人们足不出户,就可以在网络上买到自己心仪的商品。具有明确需求的用户可以通过电子商务网站的搜索引擎查找想买的商品,但据Amazon统计,這样的客户只有16%,更多的用户只是在网站上盲目浏览,“尝试”遇到自己想不到但认为有用的商品。据Amazon的数据,由于使用了个性化推荐系统,其网站的销售额在2016年提高了30%。
目前,国内外电子商务的推荐研究工作主要集中在以下几个方而:
(1)推荐算法的基础性研究。文献[1]全而介绍了现有主要的推荐方法,分析了各自的优势与不足,总结了该领域目前所而临的主要问题,为推荐技术的研究勾勒出一条清晰的主线,为相关研究者提供有益的参考。作者将现有的主流算法归类为四种,即:协同过滤推荐算法、基于内容的推荐算法、基于图结构的推荐算法以及混合算法。作者在文中还介绍了评分估计方法和推荐算法评价准则。
(2)推荐效率和推荐质量的平衡性研究。在任何系统中,实现效率和实现质量都是一对天然存在的矛盾,在商品自动化推荐领域也不例外[2]。基于内容的推荐方法犹豫需要分析用户数据的内容信息,会占用大量计算资源,从而导致分析效率降低,但随之带来的就是推荐质量的提高:而近年来兴起的基于协同过滤技术的推荐算法,由于其不需要分析对象的特征属性,可以在准确率不降低的前提下提高推荐效率而得到学者们的关注。为解决上述两种技术存在的不足,人们提出基于知识的推荐技术,这种推荐技术由于不依靠客户商品评分数据,解决了数据量不足的问题,提高了推荐质量。
(3)推荐系统的规模性研究。从现有文献看,推荐算法针对某特定网站的研究较多,而通用性的推荐算法研究并不多。到目前为止,绝大多数电子商务推荐技术及系统研究均是基于特定网站的,不能满足大规模网站的推荐应用。Chiu等人提出的而向通用电子商务社区的推荐系统可以较广泛应用于文中定义的智能社区。本文的研究在第三部分中展开。
本文剩余部分如下:第二部分介绍本文拟使用的算法模型:第三部分利用该模型设计推荐策略;第四部分进行仿真实验;最后是本文小结。
2 模型理论基础与设计思路
使用递归方法,可以提高云环境下具备动态性和模糊性的用户推荐算法的准确性,同时可以减少噪音。
2.1 Abrjot算法
文献[5]提出的Abrj ot算法用户挖掘关联规则,该算法使用逐层搜索的迭代算法,缩小了聚类的范围。该算法由链接和剪枝两个步骤组成。链接,顾名思义就是将不同的信息节点连接在一起,首先找出一个信息点Lk,利用前一个信息点Lk-1通过自连接运算构成K*序列集合Ck,作为用于数据提取的候选集。然后是剪枝,顾名思义就是把无用信息删除掉,对于Ck中包含的元素,Ck只包含所有的频繁k*序列集,通过对DB的遍历扫描计算,得到Ck候选集合元素的数量。从而可以确定Lk和Lk-1。
2.2 利用MapReduce实现自动化推荐模型建立
自动化推荐有多种手段和方法,既可以利用传统的关联技术、机器学习,也可以采用数据挖掘、模糊决策等,这取决于数据量和样本本身的数据质量。如果数据量较大,建议采用数据挖掘的方法更有效果。本文假设的应用环境是中高数据吞吐量电子商务网站,因此选择MapReduce这种数据挖掘技术。MapReduce采用分布式策略处理大量用户行为数据,从而可以提高处理效率,可以充分利用其迭代式的运算框架满足数据挖掘分析的需求。
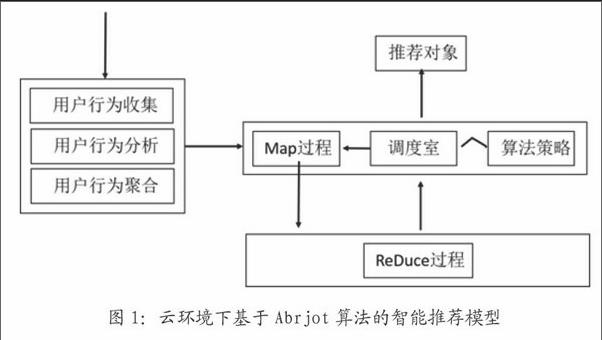
假设用户访问站点的访问数据均为开放状态,本文将利用用户访问行为轨迹,建立一种基于用户行为特征分析的云环境下的用户商品推荐机制。在这种机制中,用户终端首先收集用户访问电子商务网站的行为轨迹信息,按照既定规则进行数据预处理后传输至用户行为分析模块。用户行为数据分析模块调用用户浏览历史轨迹记录,采用统计学聚合分析,利用分布式模型对时问片段内的工作状态和心理预期进行定性刻画。任何调度模块收到任务管理模块的请求后可以进行动态资源分配。模型如图1所示。
众所周知,MapReduce是一种对大数据进行分布式处理的分析算法。为了提高计算效率,MapReduce首先将海量数据切分为小数据集,提交到分布式的计算节点进行并行处理。在本文中,MapReduce将新算法中的剪枝和链接阶段转化为Map和Reduce两个函数。在MapReduce平台里,一个作业的输入数据集合被切分为多个独立的小数据集合,交由映射过程并行处理,从而提高了计算效率。
3 利用模型的推荐策略设计
现有的关联规则算法都关注算法的准确性,却忽略了算法的计算效率。在实际推荐过程中,推荐的效率是至关重要的一个因素,用户极有可能会在1秒内对推荐等待产生放弃心理。因此,充分考虑计算效率的推荐策略才有意义。
3.1 Map过程
利用Hadoop平台中的MapReduce任务调度等待响应机制,可以计算出主节点和从节点的闲置状态,从而可以自动调度空闲节点进行计算,一次响应计算请求,提高计算效率。
3.2 Reduce过程endprint
Reduce
{
for every direct ansewrt∈D
{
For anyone itemx∈t
fx,count++
Ifx,count++ Delete x: } } = {xlx∈n x.count≥minsup) return for (k=2, L_k-l≠φ;k++){ =Gen_Abrjot (,min_sup);; While every answer t ∈?D? {//count theelements in D =subset(,t);; while things c∈c,count___; retum } 4 仿真實验 实验环境: 平台:Hadoop 0.20.0开发环境; 硬件配置: Core2 E77500 Dual-core Processor 4GBRAM; 软件配置: Ubuntu Linux 11.10, Hadoop-0.20.0, JDK16。 按照Hadoop部署手册,首先将Abrjot算法Jar包部署到实验平台,将Hadoop中自带的FIFO的配置节点替换为新的配置文件。为了按照Hadoop模式运行,本实验选择9台PC机作为C,luster,其中有8台PC作为从节点服务器。实验分别采用FIFO传统调度算法和本文所提出的算法,在HDS这个基准测试程序中进行Abrjot变化实验,以及用户特征行为获取,输出初始规则集。为了比较并行算法和传统串行算法对JOB的影响,设置JOB精度为8个组,再根据Cluster的当前作业负载确定每组中JOB的数量。 5 结论 本文针对云环境下推荐算法的研究方向展开讨论,构建了一种基于Abrj ot算法的MapReduce推荐模型,并进行了仿真实验进行横向性能分析,结果表明,新算法在求解精度越高时有明显的优势。 参考文献 [1]杨博,赵鹏飞.推荐算法综述[J].山西大学学报,2011,34(03): 337-350. [2]Kouichi. An Idea of the Agent-based Information Recommending System Using the Statistical Information. IEEE.2000:143-146.
