基于卷积神经网络的图像检索
2018-01-26霍璐
霍璐

摘 要: 针对图像检索存在的问题,如图像存储量大,图像提取特征与人类感知的语义鸿沟,图像检索时间长等,提出了一种新的深度哈希方法。通过卷积神经网络融合局部特征与全局特征进一步缩小了图像的语义鸿沟,使得融合特征与编码相互影响,相互调节。同时通过限定编码位数,使得图像存储量大大减少,检索时间缩短。实验证明,该方法胜过之前提出的方法,使用卷积神经网络进行融合特征编码是完全可行的。
关键词: 图像检索; 卷积神经网络; 图像编码; 哈希算法
中图分类号:TP319 文献标志码:A 文章编号:1006-8228(2018)01-63-03
Image retrieving with convolutional neural network
Huo Lu
(College of Computer Science, Hangzhou Dianzi University, Hangzhou, Zhejiang 310018, China)
Abstract: Aiming at the existing problems of image retrieval, such as large image storage, the semantic gap between the extracted feature of image and human perception, long time of image retrieval etc., a new deep hashing method that learns the compact binary representation of images is proposed. The local features and global features are combined by convolutional neural network to narrow the image semantic gap and make the combined features interact with the coding. At the same time, by limiting the number of coded digits, the storage capacity of the image is greatly reduced and the retrieval time is shortened. Experiments show that the proposed method is better than the previous ones, and the convolution neural network is completely feasible for the fusion of feature coding.
Key words: image retrieval; convolutional neural network; image coding; hash method
0 引言
20世纪70年代时期,已经出现图像搜索的研究,主要是基于文本的图像检索技术,使用一些特定的词来描述图像的特征,用户通过进入一层层的目录找到自己想要的图片。相似图像搜索发展为对文本的相似语义搜索。图像标签每次都需要人工手动输入,这可能会带有一定的主观性与不精确性。
到了20世纪90年代时期,开始出现了基于内容的图像检索技术。用户将图片进行一定的預处理之后,通过提取一定的特征,与数据库中已有的特征进行比较,最终得出相似图像搜索结果。
以下综述用到的一些主要方法。
利用颜色特征低层语义图像特征表示为直方图[1],使用直方图的图像检索技术是当纹理特征等低层语义图像特征提取出来之后建立直方图,将检索图像的直方图与图像库中已有的直方图进行比较。使用直方图进行图像检索,具有比较直观、计算量较小等优点,其缺点在于,使用其进行分类准确度较低,对位置变化和旋转不敏感。
SIFT(Scale-invariant feature transform)[2],SURF(Speeded Up Robust Features)[3]等局部特征的提取,使用局部特征SIFT进行图像检索是建立一些特征向量,通过比较与图像库中特征向量的距离,找到匹配的图像。SIFT的优点是即使改变旋转角度,亮度,和拍摄视角都可以实现不错的检测效果,但是SIFT的实时性不强,对边缘平滑的图像和模糊图像检测的特征点较少。
关联反馈[4],是用户给出一张图片,计算机通过默认的特征度量,给出最初的搜索结果,用户对搜索结果进行评价,确定其相关还是不相关,之后再通过一些机器学习算法进行更新,重新生成搜索结果,用户再对其进行评价,如此循环,直至用户对相应的搜索结果满意。其优点在于,根据用户的反馈,可以提高匹配的准确度。其缺点在于,算法效率不高且需要大量的反馈。
哈希算法在此处可分为数据依赖型哈希如SH[5](Spectral Hashing)、ITQ[6](iterative quantization)、HDML[7](hamming distance metric learning)、STH[8](Self-Taught Hashing)和数据独立型哈希,如LSH[9](Locality-Sensitive Hashing)和其变种。哈希算法对每个图像进行哈希编码,通过距离函数来比较图像的相似度。其优点在于搜索速度较快,所需的存储空间较少,其缺点是输出是一个二进制序列,丢失了部分特征信息,可能相似搜索的准确度会下降。
卷积神经网络所提取的深度特征和复杂的、需要进行很大调整的现有方法相比,有很大优势。同时,卷积神经网络中从不同层提取到的不同特征对检索性能有着不同的影响。更加特别,从更深层提取到的特征能够产生更加可信的相似度度量和更加丰富的图像信息。从不同层结合的特征映射增加了输入到比较靠后层之间的可变性并且提升了其检索效率。endprint
1 相關内容
早期的图像特征提取几乎均为人工手动提取,具有一定的主观性。卷积神经网络可认为是一个自动的图像特征提取器,随着卷积层的加深,视觉词汇的复杂度也逐步提升,并具有一定的轮廓特征。利用这些特征进行哈希编码,使得语义相同的图像具有相同或相似的哈希编码序列,语义不同的图像具有差异性较大的哈希编码。且使用较短的哈希编码来表示多个图像的语义特征。通过一定的相似度度量函数来比较哈希编码得出图像是否相似。
传统的监督型哈希编码一般包含两个步骤:
①手工提取特征;
②进行hash学习。
一般这两个步骤被分为两个独立且互补相关的过程,其编码的好坏不能反向影响提取的特征,其特征有可能也不适用于进行哈希编码,一般得到的编码效果比较差。
基于此,我们在此处提出的改进是:将特征提取与哈希编码相融合,使其尽可能的相互影响,相互制约。
2 基于卷积神经网络的图像检索
本文的网络结构是在caffenet的基础上进行修改,对于其他网络结构也是使用同样的原则进行修改。conv1,conv2,conv3,conv4,conv5为对应的卷积层,pool1,pool2为对应的pooling层,fc6,fc7,fc9,latent1,latent为对应的全连接层。Fc9层神经元个数对应最后的分类个数。latent层和latent1层的神经元数为对应的全局编码个数和局部编码个数。除latent,latent1层,其他层的激活函数均采用relu函数。局部特征取卷积神经网络较为中间的卷积层conv5。通过使用pooling和PCA我们实现了局部编码。全局编码我们在此处通过隐层来实现图像的特征编码,其中,全局特征编码直接对应其分类loss,需要学习的hash function通过一个隐层在CNN的图像表示和分类输出之间。
ωg为f7层与latent层之间的权值,对于给定的图像Ii,f7层对应的输出值为,的计算如公式⑴所示。
⑴
其中,为K1维向量(对应全局编码位数),为偏置值,σ(·)为激活函数。
对于给定的图像Ii,conv5层对应输出值为,(x,y)代表对应feature map中空间位置latent_1层的输入的计算如公式⑵所示。
⑵
其中,之后经过PCA降维至K2维向量。
特征融合层的输出Oi如公式⑶所示。
⑶
其中,[,]表示两向量进行拼接。
3 实验部分
我们主要使用的数据集是cifar10,cifar10可以分为10类,其中包含了60,000张3232的彩色图像,训练图像为50,000张,测试图像为10,000张。
DeCAFNET证明了在imagenet中训练好的卷积神经网络模型提取到的卷积特征应用到不同的数据集上同样可以起到很好的分类效果,这种从大数据集上学习到的有效知识应用到小数据集上的方法称之为迁移学习,因此,我们可以使用imagenet中训练好的权重进行微调。
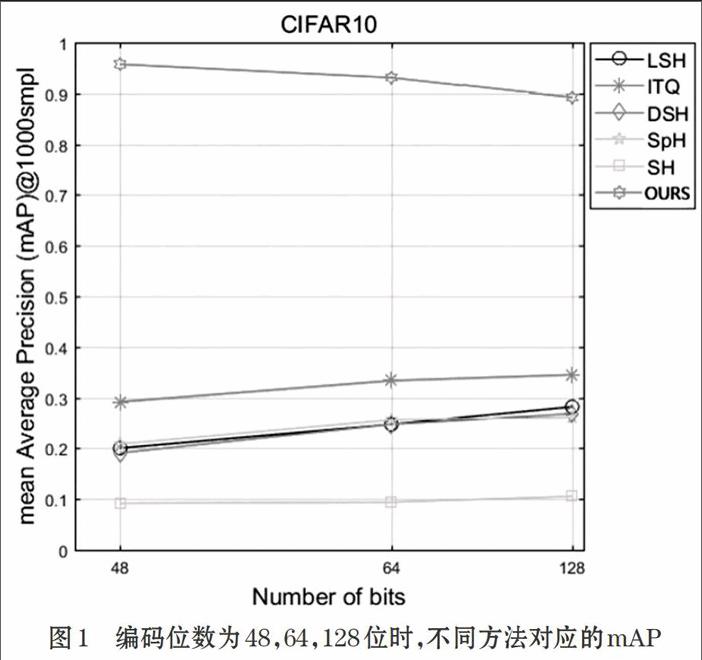
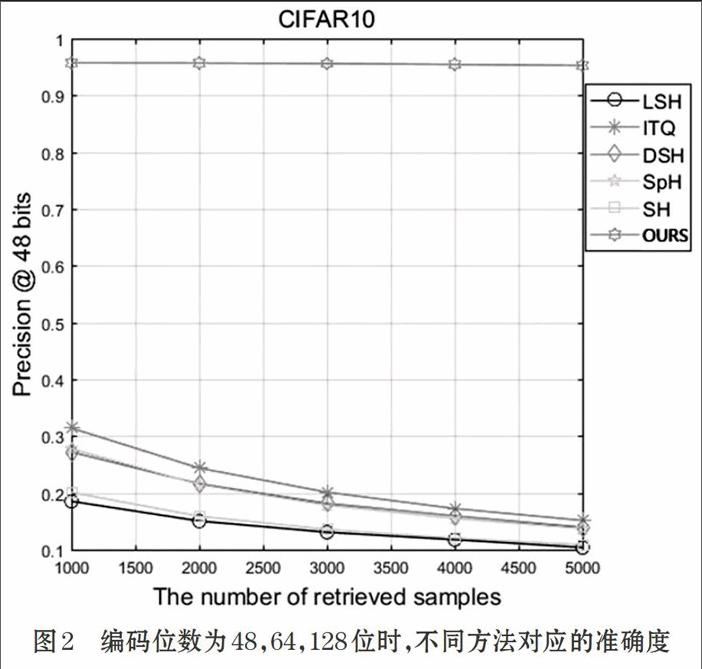
将我们的方法与传统的哈希方法进行比较(LSH,ITQ,DSH,SpH和SH). 由于它们均使用手工提取的特征去产生压缩编码。其检索性能将会被提取的特征影响。然而,在我们的方法中,特征提取和编码可以相互影响。
如图1,图2所示,通过与传统哈希编码进行对比,我们可以得出结论:本文提出的方法比传统哈希编码要好。我们可以看出我们的方法取得了很大的提高。
4 结束语
在本文中,我们提出了一种深度哈希模型。通过该模型,我们可以同时进行特征融合和哈希编码。通过卷积神经网络,融合局部特征与全局特征,进一步缩小了图像的语义鸿沟,其计算复杂度和运算所需的存储量大大减小。同时通过限定编码位数,使得图像存储量大大减少,检索时间缩短。
通过实验证明,我们的方法胜过之前提出的方法;同时也证明,使用卷积神经网络进行融合特征编码是完全可行的。接下来,我们将继续研究融合特征编码各部分之间的影响,并考虑将我们的模型使用在其他的应用上。
参考文献(References):
[1] Deng Y, Manjunath B S, Kenney C, et al. An efficient color
representation for image retrieval[J]. IEEE Transactions on Image Processing A Publication of the IEEE Signal Processing Society,2001.10(1):140-147
[2] Lowe D G. Distinctive Image Features from
Scale-Invariant Keypoints[J].International Journal of Computer Vision,2004.60(2):91-110
[3] Bay H, Tuytelaars T, Gool L V. SURF: Speeded Up Robust
Features[J]. Computer Vision & Image Understanding,2006.110(3):404-417
[4] Rui Y, Huang T S, Ortega M, et al. Relevance feedback: a
power tool for interactive content-based image retrieval[J]. IEEE Transactions on Circuits & Systems for Video Technology,1998.3312(5):644-655
[5] Weiss Y, Torralba A, Fergus R. Spectral Hashing[C].
Conference on Neural Information Processing Systems, Vancouver,British Columbia, Canada, December. DBLP,2008:1753-1760
[6] Gong Y, Lazebnik S. Iterative quantization: A procrustean
approach to learning binary codes[C]//IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society,2013:817-824
[7] Norouzi M, Fleet D J, Salakhutdinov R. Hamming Distance
Metric Learning[C]// Neural Information Processing Systems,2012.
[8] Zhang D, Wang J, Cai D, et al. Self-taught hashing for fast
similarity search[C]//International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM,2010:18-25
[9] Indyk P. Approximate nearest neighbors: towards
removing the curse of dimensionality[J].Theory of Computing,2000.11:604-613endprint
