个性化推荐算法综述
2018-01-24孙光浩刘丹青李梦云
孙光浩 刘丹青 李梦云
摘要:在现有文献统计下个性化推荐算法可以分为如下三类:基于内容的推荐(Content-based Recommendation)、基于协同过滤的推荐(CollaborativeFilteringbasedRecommendation),以及混合型推荐系统(Hybrid Recommendation)。其中,基于协同过滤的推荐因其对专家知识依赖度低以及可以利用群体智慧等特点,得到了最为深入也最为广泛的研究,它又可以被分为多个子类别,主要包括基于用户的协同过滤(User-based CF),基于物品的协同过滤(Item-based CF),以及基于模型的协同过滤(Model-based CF),等。其中基于模型的推荐是一类方法的统称,它指利用系统已有的数据和用户历史行为,学习和构建一个模型,进而利用该模型进行用户偏好建模、预测与个性化推荐,根据具体应用场景和可用数据的不同,这里的模型可以是常用的奇异值分解等矩阵分解模型,也可以是主题模型、人工神经网络、概率图模型、组合优化甚至深度学习等机器学习模型。在下面的部分,我们将在如上几个方面对个性化推荐系统的研究现状进行具体的介绍。
关键词:推荐算法;协同过滤;个性化
1研究背景
随着互联网的迅速发展,个性化推荐系统已经逐渐成为各种网络应用中不可缺少的核心功能,并以各种各样的方式影响着人们日常生活的方方面面:电子商务网站中的购物推荐引擎为用户提供可能感兴趣的商品推荐;社交网络中的好友推荐为用户寻找潜在的好友关注;视频网站中的视频推荐为用户提供最可能点击的视频推荐;新闻门户网站中的内容推荐为用户提供最有信息量的新闻——个性化推荐技术已经是支撑互联网智能的基础技术之一。
2国内外现状
互联网的快速发展开启了人类活动线上化的进程,越来越多传统上只能在线下完成的任务变得可以方便快捷地在互联网上完成。已经深入人们日常生活中的电子商务就是这一进程的典型代表,例如阿里巴巴、京东商城、亚马逊网络商城等电子商务网站的普及,使得人们不必走出家门即可购买自己所需要的商品,并且可以在更多的备选商品中进行挑选。不仅限于电子商务应用,社交网络平台如新浪微博和Facebook的兴起使得人们可以在互联网上交友、沟通、获取实时资讯;在线叫车服务如滴滴和Uber的发展使得用户不再需要线下街头打车;在线P2P借贷服务如宜信和Prosper使得用户线上借贷和理财成为可能;在线房地产业务如Zillow和Airbnb的发展则使传统的房地产业务逐步线上化;在线自由职业平台如猪八戒网和亚马逊MTurk的迅速发展甚至使得自由职业者在线工作和任务分配成为可能。
2.1基于内容的推荐
首先收集和标注特征信息并对用户和物品构建内容画像(Profile),例如电影的类型、导演、主演,用户的年龄、性别、内容偏好,等等。在此基础上,基于内容的推荐通过用户画像和物品画像的特征匹配算法进行个性化的推荐。在理论与方法方面,Debnath等研究了特征权重的选取方法及其对推荐效果的影响;Martinez等将语言学模型运用到基于内容的推荐当中,从而允许用户以自然语言描述自身的兴趣爱好并获得个性化的推荐;Blanco和Gemmis等将语义网与基于內容的推荐相结合,利用语义网所蕴含的精确的特征关系为用户提供推荐;Noia等进一步将最新的开放连接数据(LinkedOpellData)项目语义网应用于个性化推荐;Zenebe等将模糊集理论应用于用户和物品特征集合的匹配过程从而为用户提供基于内容的推荐;Cramer等则在基于内容的推荐背景下研究了系统透明度对用户信任和接受度的影响。在实际应用方面,Mooney等研究并推出了基于内容的图书推荐系统;Cano推出了基于内容的音乐推荐系统;Basu等研究了社交关系信息在推荐系统中的应用,Cantador等则进一步将基于内容的推荐应用于社会化标签系统(Social Tagging System),从而为用户推荐最可能感兴趣的对象进行标签标注;Chen等研究了基于内容的电子商务系统;Phelan和Kompan等则研究了基于内容的新闻推荐系统。
2.2基于协同过滤的推荐
基于协同过滤的推荐是推荐系统中广泛使用的推荐技术,与基于内容的方法不同,协同过滤的核心思想在于借助其他用户的历史行为(群体智慧)来为当前用户给出推荐,而不仅仅是考虑当前用户自身的特征偏好。基于协同过滤进行推荐的思想一般认为最早出现在GroupLens的新闻推荐系统中,该工作也就是后来人们所说的基于用户的协同过滤方法,除此之外,该工作也第一次提出了用户物品评分矩阵的补全预测问题,并且这一问题在Herlocker中得到了进一步的形式化,并在Breese中得到了实验验证,影响了推荐系统今后十几年的发展方向;Sugiyama等将基于用户的协同过滤用于个性化搜索任务中并取得了不错的效果。
Sarwar等研究了协同过滤技术在电子商务网站中的应用,并发现由于在基于用户的协同过滤中需要计算用户之间的两两相似度,使得在电子商务等用户数庞大的网站中计算量成为了一大瓶颈。为了解决该问题,Sarwar等进一步提出了基于物品的协同过滤,利用物品的相似度来进行协同过滤式推荐,该方法在亚马逊的个性化推荐系统中得到了重要的应用,并且至今仍然是许多电子商务网站推荐系统的基础之一;由于基于用户和基于物品的协同过滤都涉及到用户和物品相似度的计算,两者一般可以统称为基于近邻的推荐方法(Neighbourbased Recommendation);Herlocker等对通过选择不同的相似度计算函数,对基于用户的协同过滤方法的实际效果进行了分析和验证;Karypis则在Top-N推荐列表任务中对基于物品的协同过滤进行了实验验证和效果评价;Huang等对比了不同的协同过滤算法在电子商务网站应用场景下的效果和效率;Basu和Kautz等最早讨论了社交网络与协同过滤的结合,从而使得社交推荐成为可能;Massa和O'Donovan等研究了用户之间的信任关系在协同过滤相似用户选择过程中的应用,提出了信任敏感的(Trust-aware)协同过滤算法和研究方向,并开发了信任敏感的推荐系统实际应用模型Moleskiing。endprint
为了进一步解决相似度计算量大的问题,Lemire等提出了著名的SlopeOne系列算法将协同过滤的回归函数简化,在大大降低计算时间和存储需求的同时,取得与原始基于近邻算法相当甚至更好的效果;O'Connor等提出利用物品聚类来降低相似度计算的复杂度;Gong等尝试和比较了分别对用户和物品进行聚类的效果;而George等则采用互聚类(Co-Clustering)的方法对用户和物品同时进行聚类,并在此基础上寻找近邻;Ma等基于相似度阈值过滤提出了一种寻找近邻并计算预测打分的加速算法;Zhou和Zhao等则研究和实现了基于Hadoop的并行化相似度计算和协同过滤方法。
随着2007年Netflix矩阵预测大奖赛的兴起,推荐系统的研究进入了一个新的高潮。由于在矩阵分解在预测效果上的明显优势,大量的矩阵分解算法得到深入的研究和扩展,这既包括对主成分分析(Principle Component Analysis)算法、奇异值矩阵分解(Singular Value Decomposition)算法和非负矩阵分解(Non-negative Matrix Factorization)算法等已有矩阵分解算法的应用和扩展,也包括一些新算法的提出和研究,例如最大间隔矩阵分解(Maximum Margin Matrix Factorization)算法和概率矩阵分解(Probabilistic Matrix Factorization)算法,等等。
2.3冷启动问题
冷启动问题(Cold-start)是协同过滤式推荐系统所面临的重要问题之一。当新用户刚刚加入系统时,由于其只有很少甚至没有历史行为记录,使得协同过滤算法难以对其进行偏好建模,例如在基于用户的协同过滤当中,冷启动用户由于没有历史打分记录,造成无法为其计算相似近邻用户。同样的问题也存在于基于物品的协同过滤算法中,新加入的物品由于几乎没有用户打分,使得难以被算法推荐出来。Gantner等通过学习属性特征映射来解决冷启动问题;Zhang等利用社会化标签来缓解冷启动问题;Bobadilla等则研究了神经网络学习算法在冷启动问题中的应用;Leroy等对冷启动的关联预测(Link Prediction)问题进行了研究;Ahn等提出了一种启发式的相似度计算方法来解决新用户冷启动的问题;Zhou等提出了功能矩阵分解模型(Functional Matrix Factorization),利用决策树和矩阵分解的结合在冷启动过程中为用户选择合适的物品进行打分,从而尽可能准确地理解用户的偏好。与冷启动问题紧密相关的是协同过滤的数据稀疏性问题,相对于系统中规模庞大的物品总数,评价每个用户有过交互行为的物品只是很少的一部分,数据的稀疏性为用户偏好建模带来了挑战。Wilson等通过实例研究了数据稀疏性问题在推荐系统中的影响;Huang等嘗试利用关联规则挖掘来解决数据稀疏性问题;Papagelis等利用用户信任关系来缓解稀疏性;Feng等研究了神经网络在稀疏数据背景下推荐问题中的应用;Zhang等提出了矩阵的块对角结构,通过矩阵的块对角变换增加局部密度从而直接缓解稀疏性问题;Zhang等进一步分析了矩阵分解的解空间性质,并提出了增广矩阵分解算法用以解决数据稀疏性的问题。由于推荐系统是许多互联网应用中的重要部分,协同过滤也因此在各种应用场景下得到了丰富的应用。除了典型的电子商务推荐系统之外,Das等利用协同过滤技术实现谷歌新闻推荐系统;Ma等利用协同过滤方法研究了社交网络推荐中的一系列重要问题,包括基于社交网络信任关系的推荐、基于社会化正则项的推荐、基于概率化矩阵分解的社交网络推荐、基于上下文信息的社会化推荐、以及显式和隐式信息在社会网络推荐中的应用,等等;Lekakos、Liu和Jeong等研究了协同过滤技术在电影推荐中的应用;Celma、Eck、Wang等研究了音乐推荐技术及系统;Tewari、Cui等研究了在线图书推荐;Zheng等研究了在线服务推荐系统;论文引用推荐是协同过滤推荐应用的另一个重要领域,He、Caragea、Zarrinkalam等对此进行了深入的研究。
2.4混合型推荐系统
基于内容的推荐其优点是没有冷启动的问题,但是用户和物品画像的构建需要大量的时间和人力;而基于协同过滤的推荐通过利用群体的智慧对用户和物品进行画像和建模,但是也存在冷启动、数据稀疏性等不足之处。为了结合两者的优点而同时规避两者的缺点,研究界提出了混合型推荐系统,对基于内容和基于协同过滤两种方法的结合成为混合型推荐系统的主流,在实际系统中得到了广泛的应用,现在大多数实际中的推荐系统都是综合多种推荐算法而构建的混合型推荐系统。根据算法融合方式不同,混合型推荐策略可以分为加权融合、场景切换、结果混合与重排序,、特征组合、算法级联、算法元层次融合等。
Burke等将基于知识的专家系统与协同过滤结合,较早提出了混合型推荐系统的概念;ClayPool等进而将基于内容和协同过滤的推荐相结合用于新闻推荐的任务;Wang等基于相似度融合的方法对传统的用户协同过滤和物品协同过滤进行了结合;Good等提出结合个人助理(Personal Agents)的协同过滤框架;Pennock等将基于近邻的协同过滤与基于模型的方法相结合;Melville等提出了基于内容增强(Content-boosted)的协同过滤方法;Kim和Cho等研究了基于决策树的混合推荐模型;Popescul和Yoshii等研究了混合型推荐的概率化方法;近年来,Campos等又将贝叶斯概率框架应用于混合型推荐系统中;Burke等研究了异构网络和数据环境下的混合型推荐算法;Choi等研究了用户隐式反馈与行为模式的结合;Renckes等考虑了用户隐私保护在混合型推荐中的体现;Sun等研究了基于排序学习的混合型推荐;Huang等基于用户物品关系图提出了一种融合内容和协同过滤的混合型推荐方法。
在应用方面,斯坦福大学的研究人员首先推出了混合型推荐系统Fab,首次采用了内容和协同过滤结合的方法;Prasad和Li等研究了电子商务网站背景下混合型推荐的应用;Yu等利用混合型推荐实现了基于手机的上下文相关多媒体内容推荐系统;Yoshii和Donaldson等则对混合型推荐策略在音乐推荐中的应用;Lekakos和Salter等基于内容和协同过滤研究了电影推荐;Vaz等基于协同过滤和作者排序实现了一个在线图书推荐系统;Lucas等对在线旅游产品的推荐进行了研究;Sobecki等利用协同过滤和菜谱内容实现了在线菜谱教程推荐系统;随着MOOC等在线学习平台的兴起,Chen、Tang、Khrib和Bobadilla等研究了基于混合型推荐策略的在线课程推荐系统。
3存在问题
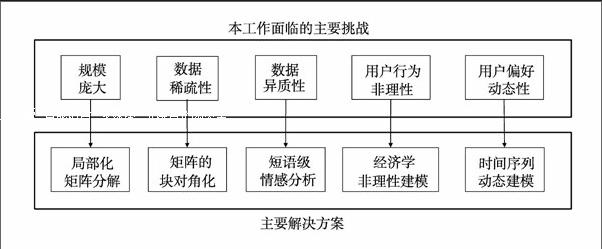
个性化推荐技术的主要研究对象丰富多变,概括而言包括两大部分:其一是广泛存在于各种互联网应用中的被推荐物品,包括商品、视频、音乐、电影、新闻、金融产品、工作任务等方方面面;其二便是购买、消费和操作这些物品的网络用户。用户与物品之间交互方式的多样性、行为记录的丰富性、兴趣偏好的动态性,为个性化推荐技术的研究及其解释带来了诸多挑战。如图所示。
4结语
为了解决相关问题,学术界和产业界都进行了一定的探索,例如在亚马逊等电子商务推荐系统中往往简单地给出“购买了该产品的用户也购买了”等简单的模板式推荐理由;在社交网站下相关的推荐系统中,则可以看到诸如“你的好友也查看了该内容”等基于社交关系的推荐理由。然而,过度简化的一成不变的推荐理由难以为用户提供个性化的解释,降低了用户对推荐理由的信任度。然而在实际系统中,用户提及某一主题时并非一定是在表达正面情感,而在很多情况下恰恰相反是在表达负面情感,因此纯粹基于主题的方法往往在描述用户兴趣偏好时有所偏差。本文对个性化推荐算法的关键技术做了系统介绍,对核心算法进行了综述,为实现具体领域内个性化推荐做铺垫。endprint