“大数据时代,朋友近在咫尺”
2018-01-24曹瑛典
曹瑛典
研究背景
在大数据时代,面临数据海量、多样性和价值稀疏性等特点,能不能用某种方法快速找到与自己兴趣爱好相投的新朋友呢?能不能利用大数据分析解决潜在好友推荐的问题呢?
移动定位社交服务的出现为人们提供了一种全新的交友方式。这类应用通过将用户的位置数据在地图上可视化,让用户相互分享生活经历,结交新的朋友。潜在好友和位置推荐作为移动定位社交服务中最重要的一个功能,已经被应用到很多交友软件当中。但是,现有的一些交友软件的推荐功能仍然存在不足,推荐的潜在好友很多在现实生活中没有交集,与自己真正想要找到的朋友相差甚远;微信通过“附近的人”这一功能向用户推荐潜在好友,但该方法只是根据用户之间的距离远近进行推荐,找到的所谓“好友”与用户往往没有相同的兴趣爱好。
现有推荐方案的问题
现有的一些潜在好友及位置推荐系统主要局限于用户的网络行为。这些研究的注意力主要集中在用户的网络行为上,却忽略了用户在现实世界中的位置等信息。与网络行为相比,用户的现实行为更能体现出用户的喜好和社会属性。通过对比现有社交应用软件的潜在好友及位置推荐方案,单一的使用位置数据或用户网络行为进行推荐已经无法提高推荐成功率。因此,本文根据用户历史位置数据结合词频逆文本频率(Term Frequency Inverse Document Frequency,TF-IDF)算法思想计算用户的相似性,进而发现用户的兴趣位置,挖掘用户的爱好特点,最后实现潜在好友及位置推荐,提高推荐准确性。
本文的主要研究内容包括:挖掘用户停留位置;计算相似用户;通过计算对停留位置的访问频率提取用户感兴趣的位置,为用户位置推荐提供数据源;从前三步得到的相似用户列表和用户兴趣位置列表选取符合条件的结果为用户推荐潜在好友和位置。
算法思想与设计
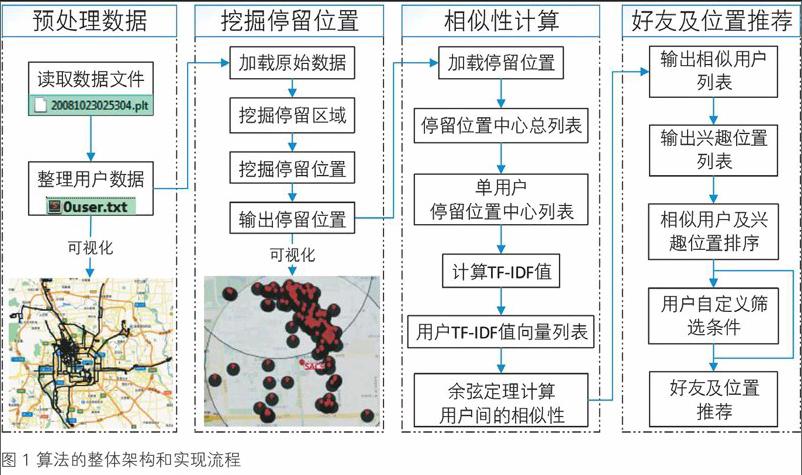
整体架构
算法的整体架构和实现流程如图1所示。首先从用户的原始位置数据中挖掘其停留区域,并从停留区域中挖掘用户的停留位置;然后采用TF-IDF算法计算出用户之间的相似性,并通过计算用户对于不同停留位置的访问频率,得出用户感兴趣的位置;最后从得到的相似用户列表和用户兴趣位置列表选取符合条件的结果,为用户推荐潜在好友和位置。
用户停留位置挖掘和相似性算法
原始的GPS位置数据对于用户而言意义并不大。因为一般人外出购物或者旅游时都会表述自己“要去”某一具体地点,而不会指出该地点的经纬度。同时,原始的GPS位置数据由于数据量大从而加大了算法处理难度。为了弥补这些缺陷,本文从原始的GPS位置数据中挖掘用户的停留区域。
由于挖掘出的用户停留区域范围太大,无法将其直接应用于用户的相似计算中,因此进一步从停留区域中挖掘停留位置,缩小原始位置数据的范围。停留位置是指用户活动的实际地点,即某用户在某区域内停留的时间超过某一特定阈值时,即为该用户的停留位置。
停留位置可以分为3种情况:情况一,某用户会经常从不同方向经过某一地点;情况二,某用户进入某一建筑一段时间后再从该建筑出来;情况三,某用户在某地段以很慢的速度行走。
用户的停留位置包括其中心点及相邻的邻居点,这些邻居点数据中隐藏着用户的停留位置,据此设计了停留位置挖掘算法。
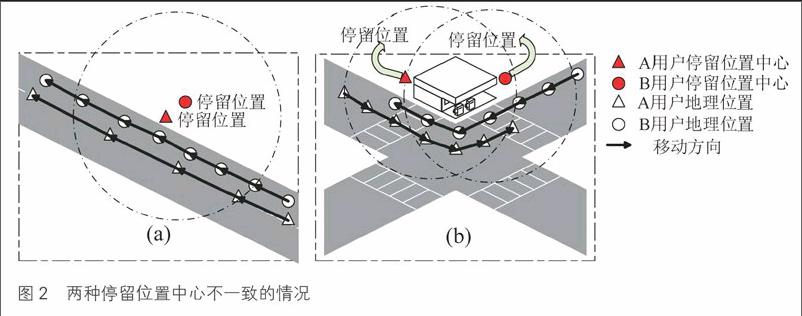
上述算法中处理停留位置的中心点是通过计算用户周边所有邻居点的平均值得出,这样将会导致同一个停留位置而位置数据却不一样。为了提高用户相似计算的有效性,本文将停留位置的中心进行了标准化处理。
计算结果有时会给出2种停留位置不一致,但实际上是同一个位置的情况。在图2(a)中,用户A和B都在同一道路上移动,而A与B由于速度不一样或者轨迹序列之间的距离间隙导致A与B的停留位置中心不一致;在图2(b)中,A与B都是围绕同一建筑移动,但是由于A与B移动的方向不同或者移动距离不一致导致停留位置中心不一致。
为了避免图2中的情況影响用户相似计算的有效性,将邻近的停留位置合并,取合并后的中心作为新的停留位置。假设每个停留位置都有一个范围r,以邻居点的平均值为圆心,半径r画圆,当邻近的2个停留位置所画的圆相交时,将这2个圆代表的停留位置中心合并成1个新的中心,并且用这个新的中心作为用户的停留位置。
进行用户相似计算时,本文借鉴了TF-IDF算法的思想。
本文中将每个停留位置中心对应成文本中的一个词,不同的停留位置中心对用户的重要性不同,因此利用TF-IDF算法计算停留位置中心对用户的重要性。由此得到每个用户的相似用户列表。
用户兴趣位置提取
根据地理学第一定律,地理位置和用户的行为具有重要关联关系。为了提取用户兴趣位置,需要对没有语义的原始GPS数据进行处理。通过百度地图API将由经纬度构成的GPS原始数据映射为现实中具有语义的地理位置名称,如某学校、某餐厅等。
接着通过计算用户停留位置的兴趣度获取用户的兴趣位置列表。用户对某一停留位置访问越频繁,代表用户对这个位置兴趣度越髙。
潜在好友与位置推荐策略
令潜在好友推荐。经过用户相似计算后,获得指定用户的相似用户列表,在此基础上使用相似矩阵表示用户之间的相似度。经过该处理后用户之间相似值的取值范围为[〇,1]。当需要查询某个用户的相似用户时,只需要查询该用户的行向量即可找到相似用户列表,根据该列表中的相似值大小给指定用户推荐潜在好友。
位置推荐。位置推荐主要是为用户提供符合其爱好的场所,并且这些场所是该用户从未访问过的。由于相似用户的社会属性相近,即相似的人会表现出相近的行为特点、爱好等,因此反过来通过用户相似计算,可以发现用户潜在的感兴趣位置。
实验及结果分析
挖掘停留位置实验
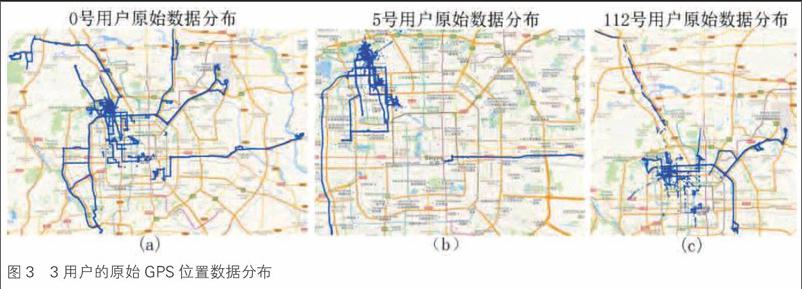
本文的实验数据来自微软亚洲研究院(Microsoft Research Asia)的GeoLife项目,该项目从2007年4月到2012年8月的5年时间里,采集了182名志愿者的GPS位置数据。采集器每隔1?5秒或者5?10米记录一次用户的GPS坐标点,共有2400多万条记录。endprint
GPS位置数据在采集过程中受用户的活动规律、活动范围等因素的影响,每个用户采集的数据集大小不一致。本文从MSData中选取记录条数在9万?50万的3个用户(0号、5号、112号用户),他们分别采集了173870、109046、90565个GPS点,将GPS位置数据在地图上进行了可视化,如图3所示。从该图中可以看出3个用户的数据分布大致相同,但是数据密度完全不同。
本文针对0号、5号、112号用户的原始数据集做了多次实验,完成对算法参数的设定,从而计算出这3个用户的停留区域。
用户相似计算实验
用户相似计算第一步将所有用户的停留位置中心进行标准化处理。在合并之前,由于采集的数据过于密集,导致很多停留位置会重叠。通过将停留位置合并后,减少了重叠的停留位置,不同的停留位置能更精确地代表其特定的区域范围,有利于用这些标准化处理后的停留位置计算用户之间的相似值。
为了验证用户相似计算算法的理论,本文选取与指定用户相似值最大和最小的用户停留位置在地图上显示,对比其停留位置的重合率。通过实验分析可以得出每一个用户的相似用户列表,该用户经过的地点与其他用户越相似,用户之间的相似值越大,他们的相似性越高。
结论与创新点
本文采用大数据分析技术,针对原始数据集进行数据清洗,引入TF-IDF算法思想,改进用户相似计算方法,提髙检测用户兴趣位置的准确性,提出全新的潜在好友与位置推荐策略,最终在建立用户相似矩阵的基础上,实现了潜在好友和位置的精准推荐。
本文通过一系列实验对提出的算法和策略思想进行了验證,通过实验分析
证明了潜在好友和位置推荐框架的精准和有效。
本文的主要创新点是:采用TF-IDF算法实现在位置大数据中相似用户的挖掘;首次提出将停留位置中心进行标准化,采用余弦定理计算用户相似度。该方法具有耗时短、占用资源少、高效的特点;用此方法可探索出基于用户相似计算的潜在好友及位置推荐策略。
该项目获得第31届全国青少年科技创新大赛创新成果竞赛项目中学组计算机科学一等奖。
专家评语
该项目选题具有先进性和新颖性。作者依据“喜欢在同一地点停留的人具有某种相同的兴趣或行为习惯”的假设,通过对用户的地理位置信息进行挖掘,找出兴趣或习惯相近的人进行推荐。这是一种比较新颖并有效的方法,值得尝试,值得注意的是,该方法要在大多数人愿意共享位置信息时才有效。整个工作比较完整,答辩表述清楚,回答问题切题。endprint
