基于Storm的车辆实时展示系统
2018-01-20张博
张博


摘要:随着汽车保有量的不断增长,城市交通网络也变得日益臃肿。如何实时准确地掌握交通现状,减少交通拥堵,提高出行效率,是智慧交通的核心所在。该文针对传统车辆分析平台实时性较差、呈现方式不直观等缺点,设计了一种基于大数据实时流式处理技术的三维展示系统。系统分为数据采集、数据分发、实时处理以及三维展示几个部分。为保证系统并发量,采用高吞吐量的Kafka作为数据分发模块,同时引入Storm对Kafka中数据进行消费、处理,通过WebSocket推送至Web页面,页面采用WebGL技术将车辆数据实时展示。与传统系统相比,该系统具有高吞吐、低延时、准确直观等特点,可帮助解决一系列交通问题。
关键词:实时处理;三维;Storm;WebGL
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2018)31-0101-03
1 背景
社会的飞速发展促进了城市车辆的需求增加,随之带来了车辆数据的爆发式增长。我们虽可借助Hadoop相关技术完成车辆数据的大规模处理,但是分批次处理作业的模式使得其很难实现秒级的延时。针对批量处理数据存在的问题,实时处理方式应运而生。
Twitter的Storm是一个开源的实时流式计算框架,比其他流计算产品更具优势。该文基于Storm设计并实现了一种车辆实时展示系统,可实时处理并展示大量车辆数据。
2 相关技术
2.1 Storm流式处理框架
Storm是一套分布式、可靠、可容错的用于处理流式数据的框架,其流式处理作业被分发至不同类型的组件,每个组件负责一项简单的、特定的处理任务。相对于Hadoop,Storm能够实现可靠的无边界流式数据的实时处理,弥补了Hadoop批处理所不能满足的实时要求。同时,Storm还具有以下几个特点:
1)编程简单:开发人员只需要关注应用逻辑,类似于Hadoop提供的Map和Reduce原语,Storm也对数据的实时计算提供了简单Spout和Bolt原语。
2)高性能,低延迟:相比较批处理框架,可毫秒级响应数据。
3)分布式:可以轻松应对单个节点无法处理的海量数据。
4)可扩展:Storm的处理作业是分布在多个节点之间,随着数据量和计算量的增长,可水平扩展系统。
5)容错:如果某个节点出现故障,主节点会将任务重新分配至其他可用节点。
6)消息不丢失:Storm会保证每条消息均被处理,如果失败,会尝试重新处理此消息。
2.2 WebGL
WebGL是一种3D绘图协议,这种绘图技术标准允许把JavaScript和OpenGL ES 2.0结合在一起,从而为HTML5 Canvas提供硬件3D加速渲染,这样Web开发人员就可以借助系统显卡来在浏览器里更流畅地展示3D场景和模型,还能创建复杂的导航和数据视觉化。WebGL技术标准免去了开发网页专用渲染插件的麻烦,可被用于创建具有复杂3D结构的网站页面,甚至可以用来设计3D网页游戏等等。
3 系统设计
根据系统需求,对系统进行分层设计,主要包括数据采集、数据分发、实时处理以及三维展示,系统架构如图1所示。
1)数据采集:前端设备所采集到的车辆原始数据。
2)数据转发:Kafka顺序存储了采集设备发送来的消息,并按不同Topic分类,等待着Storm进行拉取消费。
3)实时处理:Storm消费Kafka中数据,并进行数据标准化、数据推送、数据存储等几个步骤。
4)三维展示:Web页面接收到WebSocket推送的数据后,实时绘制车辆。
4 系统实现
4.1 数据采集
数据采集层主要功能为汇聚前端采集设备的原始数据,并通过TCP长连接將数据推送至Kafka集群中。在发送消息之前,会对消息进行分类,即指定Topic。在发送消息的过程中,加入了监听、异常处理等机制,避免数据重发、漏发,保证数据准确性。
4.2 数据分发
数据分发层向下接收采集设备推送的海量数据,向上又要及时为高性能、低延时的Storm集群提供数据,因此对消息框架的吞吐能力有很高要求。最终该系统采用Kafka作为数据分发层的实现。Kafka是一个高吞吐量的分布式发布订阅消息系统。类比Kafka官网图例,数据分发层结构如图2所示。
一个Kafka集群会包含producer,broker,consumer等角色。broker为消息中间处理节点,一个Kafka节点就是一个broker,多个broker组成了Kafka集群。producer为生产者,负责发布消息到broker,对于该系统,采集设备即为producer。consumer为消费者,向broker读取、消费消息,该系统中的consumer为Storm集群。
在数据分发层与实时处理层之间,还有一层分布式协调服务Zookeeper。通过Zookeeper的集群协调,可以充分保证大型集群的良好运行。
4.3 实时处理
实时处理层会不停去拉取、消费Kafka中的数据,并对多种Topic类别的数据进行标准化、推送、入库等处理。为应对海量数据的高并发,该系统并没有使用传统的JAVA多线程等方式,而是采用了Storm实时流处理系统。类似Hadoop集群,Storm也有一些基本组件。Storm集群分为控制节点(Master)和工作节点(Worker),在这两种节点上分别运行着后台程序Nimbus和Supervisor。Nimbus负责分配任务(也就是Topology)给各个工作节点,Supervisor则负责管理每个具体的工作节点。实际在工作节点上运行的是Spout或Bolt。系统中Storm的处理流程如图3所示。
Spout从外部源读取数据,并用Storm中的数据结构Tuple将数据发给Bolt,Bolt为逻辑处理单元,进行一系列处理后,再调用emit()方法将数据以Tuple格式发射出去。
在该系统中,KafkaSpout为数据源,它从Kafka集群中读取消息,并发送给carNormalizerBolt;因为数据来源于Kafka中的不同Topic,格式有所不同,所以在carNormalizerBolt里做数据标准化的处理。我们定义一个标准的Car类JavaBean,将消息的各个字段赋值给Car类,并进行字段补全或是丢弃等异常处理,之后将Car类发射给carSourceBolt;在carSourceBlot里,主要调用http接口将Car类发送至页面对应的Web后台,同时将Car类发射给carSaveBolt;carSaveBolt通过获得数据库连接池中的实例,将Car类持久化存储至MySQL数据库,方便Web页面查询展示。
构建处理流程的拓扑代码如下:
//配置Kafka集群信息
BrokerHosts brokerHost = new ZkHosts(zkHost);
SpoutConfig carSpoutConfig = new SpoutConfig(brokerHost, carTopic, zkRoot, "data-car");
carSpoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
//使用Kafka数据源作为Spout
KafkaSpout carSpout = new KafkaSpout(carSpoutConfig);
//新建一个Topology
TopologyBuilder builder = new TopologyBuilder();
//建立拓扑结构
builder.setSpout("kafkaCarSpout", carSpout, 3);
builder.setBolt("carNormalizerBolt", new CarNormalizerBolt(), 2)
.shuffleGrouping("kafkaCarSpout");
builder.setBolt("carSourceBolt", new CarSourceBolt(),2)
.shuffleGrouping("carNormalizerBolt");
builder.setBolt("carSaveBolt", new CarSaveBolt(), 2)
.shuffleGrouping("carSourceBolt");
4.4 三维展示
为能更准确、直观的展示实际路况的车辆信息、流量信息等,展示层通过WebGL模拟实际的三维场景,并实时绘制车辆。系统展示层采用B/S架构,前后端分离设计。展示层逻辑如图4所示。
Storm集群将标准化的数据以Http接口方式传递给后台,后台程序接收到数据后,通过WebSocket把数据推送至前端页面。js脚本取得数据后,调用车辆绘制接口完成实时展示功能。绘制接口由WebGL相关js封装成类,向外提供。同时,页面还具有查询功能,即通过调用后台接口,将Storm集群存储至MySQL的数据以表格方式展现。
5 系统测试
通过系统测试,我们可以与系统的需求进行比较,从而发现系统的缺陷与不足。
5.1 功能测试
首先进行功能测试。功能测试主要有两点:
1)测试系统是否能从采集设备获取到车辆数据,并通过Storm标准化并实时展示在三维场景中。登录系统,等待三维场景加载完成后,采集到的车辆信息(如车型、车辆颜色等)实时展示在场景中,功能截图如图5。
2)测试系统是否能从MySQL数据库中查询到采集的车辆数据。在页面中选择时间段、车辆类型、采集设备等相关条件,点击查询,即可查到采集的车辆数据。数据查询结果界面如图6。
从功能测试结果来看,该系统已完成了汇聚采集設备数据、标准化数据并实时三维展示、数据存入数据库并可查询等一系列功能。
5.2 性能测试
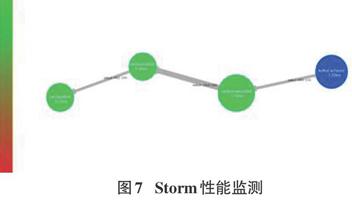
通过查看Storm集群提供的性能监测页面我们可以发现,kafkaCarSpout、carNormalizerBolt、carSourceBolt及carSaveBolt处理每条Tuple的速度分别为3.29ms、1.16ms、0.38ms和0.73ms,如图7所示。可见Storm能以10ms内的响应速度处理采集设备的每条采集数据。
6 总结与展望
该文主要介绍在海量数据的应用背景下,如何利用大数据技术解决传统车辆分析平台存在的问题。最终,该文采用Kafka、Storm等大数据框架传输、处理数据,通过WebGL对道路车辆的实时绘制,为大数据车辆分析,缓解拥堵等决策提供有力支持。
参考文献:
[1] 杨杰, 朱邦培, 吴宏伟. 基于Storm的高速公路实时交通指数评估方法的研究与实现[J]. 计算机应用研究, 2017, 34(9): 2707-2713.
[2] 亓开元, 赵卓峰, 房俊, 等. 针对高速数据流的大规模数据实时处理方法[J]. 计算机学报, 2012, 35(3): 476-490.
[3] 王雅琼, 杨云鹏, 樊重俊. 智慧交通中的大数据应用研究[J]. 物流工程与管理, 2015, 37(5): 107-108.
[4] 张春风, 申飞, 张俊, 等. 基于 Storm 的车联网数据实时分析系统. 计算机系统应用, 2018, 27(3): 44-50.
[5] Maarala AI, Rautiainen M, Salmi M. et al. Low latency analytics for streaming traffic data with Apache Spark[C]. IEEE International Conference on Big Data. Santa Clara, CA, USA.2015: 2855-2858.
