弱监督军事实体关系识别
2018-01-18李煜甫黄蔚胡国超
李煜甫,黄蔚,胡国超
(华北计算技术研究所北京100083)
随着信息指挥系统的广泛应用,军事文本的撰写、传递、审阅、管理、批阅、展示等各个环节已经基本实现了电子化,极大地提高了指挥的效率。但是,现有系统无法对记述式的军事文本进行深层的语义解析,极大地限制了信息指挥系统决策功能的发挥。通过识别军事文本中的军事命名实体,并抽取其相互关系,自动解析信息指挥系统中军事文本的语义,从而构建军事知识库,辅助指挥人员进行更有效的决策。
目前国内的实体关系识别研究方向主要集中在有监督[1]和弱监督机器学习上[2]。有监督关系识别[3]中,肜博辉等在2017年提出一种基于多通道卷积神经网络模型[4]。甘丽新等在2016年提出依存句法关系进行组合获取关系特征和句法依赖动词特征,再使用SVM进行关系抽取[5]。弱监督关系抽取[6]中,贾真等在2015年提出一种基于自扩展和朴素贝叶斯的句子分类器,然后利用条件随机场模型训练关系抽取器[7]。张春云等在2015年提出一种语义最短依存路径模式的bootstrapping模型,用触发词[8]的模式识别实体关系[9]。
由于军事文本自身特殊性,不能依据大量人工进行标注,这就极大地限制了使用传统有监督机器学习和深度学习的方法对军事文本中命名实体关系识别研究。且现有实体关系特征词提取方式较为单一,仅仅将实体前后若干词作为特征词。并不能依据海量文本提取出目标实体对之间的潜在特征信息。于是,本文提出一种基于Word2vec和FPGrowth相结合的弱监督军事实体关系识别技术。通过自扩展技术进行关系词扩充,使用FPGrowth方法挖掘实体关系的潜在特征词,并用Word2vec模型表征关键词与特征词之间的关系。最后提出一种浅层关系矩阵对实体关系进行分类。
1 关系识别准备工作
1.1 设计框架
军事文本有着行文标准,措辞严谨,语义二义性少的特点。对与实体关系的描述中不会存在着正反相差特别大的词语。由于本文主要处理的实体是人员,舰船,飞机,机构等。故提出3种实体关系:“敌对”,“协同”和“伴随”。
基于上述特点,文中提出一种基于word2vec和FPGrowth的弱监督军事实体关系识别方法。具体流程分为获取军事文本数据、数据预处理、训练word2vec、初始关系种子词选择、找出关系特征词、判断实体关系、扩充关系种子词。其中,关系特征词是用来进行关系识别的特征词,关系种子词是用来判断特征词的分类情况。方法流程图如图1所示。

图1 方法流程图
1.2 种子词选择
Word2vec模型[10]是一种能够将词表征为词向量的高效模型。通过训练后可以将词语映射成一个K维的实数向量,最主要的是能够通过词语之间的距离(一般使用余弦距离)来判断它们在语义层面的相近程度。因此,文中使用word2vec模型训练出来的词向量进行语义层面的分析。
对于word2vec模型中任意两个词向量,一般来说只要余弦距离大于0.5,就可以认为这两个词有一定关系。若大于0.6,这两个词就是近义词。若大于0.7,这两个词就是同义词。
本文提出的方法支持自定义多种关系。由于本文主要处理的实体是人员,舰船,飞机,机构等。故提出 3 种实体关系[11]:“敌对”,“协同”和“伴随”。“敌对”关系是不同派系之间因为立场的不同而产生的关系;“协同”关系是同级别之间的相同立场的关系;而“伴随”关系是上下级之间关系。其他的关系都是在此3种关系之下延伸出的子关系,例如:“A飞机”是隶属于“B舰船”,它们之间是隶属关系,也是伴随关系。“A人员”是“B舰船”的指挥长,它们之间是指挥关系,也属于伴随关系。故给军事实体设定敌对、协同和伴随着3种关系。
敌对关系中:以“对立”作为起始种子词,通过word2vec模型化为向量后余弦距离最近的10个词分别是:“还击”,“冲突”,“敌对”,“打击”,“矛盾”,“对立”,“制衡”,“孤立”,“对抗”,“抵抗”等。将这十个词作为敌对关系的初始种子词。
协同关系:以“与”作为起始种子词,通过word2vec模型化为向量后余弦距离最近的10个词分别是:“与”,“同时”,“及其”,“、”,“及”,“和”,“以及”,“一起”,“共同”,“携手”等。将这 10 个词作为协同关系的初始种子词。
伴随关系:以“指挥”作为起始种子词,通过word2vec模型化为向量后余弦距离最近的10个词分别是:“指挥”,“调度”,“指令”,“调集”,“协同作战”,“护送”,“巡防”,“命令”,“调遣”,“救援”等。将这 10个词作为伴随关系的初始种子词。
1.3 关系特征词提取
频繁项集发掘算法[12]用于发掘多个集合中经常出现在同一个集合中的频繁项。对于实体关系对来说,可以用找出符合条件的最大频繁项作为此实体对间的关系特征词。从而能将仅仅依靠句子级别的实体关系识别转化为依靠多文章、多特征的关系识别[13]。
首先对一篇文章来说。先找出其中含有的所有实体。再找出其中实体与实体之间可能包含关系的短语,对其中的短语进行分词和去停用词处理,得到多个(实体A,实体B,实体特征词)三元组。
以“A舰船对位于太平洋的B舰船进行了警告。”为例:找出其中的实体A舰船,B舰船。接着根据实体将句子进行短语划分。将实体A之后,实体B之前的特征短语划分到当前实体下,并对特征短语进行去分词与去停用词,如图2所示。

图2 实体关系候选词
此句构成3元组(A舰船,B舰船,{对,位于,太平洋,进行,警告})。此三元组分别表示实体A,实体B,以及实体之间特征词。
通过得到的初始三元组,找出其中实体对一致的三元组,使用FPGrowth算法找出其中的潜在特征词。以“A舰船对位于太平洋的B舰船进行了警告。”和“A舰船对B舰船进行了警告和驱赶。”为例。可以得到两个三元组:
(A舰船,B舰船,{对,位于,太平洋,进行,警告})
(A舰船,B舰船,{对,进行,警告,驱赶})
此时符合支持率的最大频繁项是{对,进行,警告}。可以组成一个三元组(A舰船,B舰船,{警告,对,进行})。可以看出,三元组中的第三项就是此实体对间的关系词集合,也就是A舰船与B舰船之间的关系特征词。
2 军事实体关系识别
2.1 构建关系矩阵
找出军事实体三元组后,就可以进行实体关系识别。文中提出了一种非传统机器学习的分类方法,通过计算得到一个关系分类矩阵,然后通过判断矩阵中最大项来进行种子词扩充和关系识别。
对于三元组中关系集合的每个词语,可以看成一个K维的向量。用αi来表示第i个词语的词向量。而对于“敌对”关系,可以用矩阵表示,其中βj表示敌对簇中第j个词语的词向量。然后计算αi与矩阵每一列的余弦角。也就是:
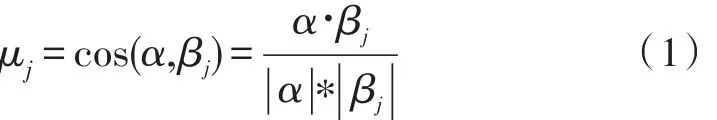
可以得到一个表示词αi与关系簇的关系向量,用[μi1,μi2,…,μik]表示。对于实体与实体之间的多个词语求与此关系簇之间的平均余弦距离,得到向量,其中,n是实体对间词语的个数。并且其中的每一项的平均值μˉi=(μi1+μi2+…μik)k,表示实体对间第i词语对该关系簇的平均余弦距离(0~1之间)。
当已知向量μ,η和θ。首先要先找到此实体与实体间的所有关系词中最能代表此关系的词。此时需要对向量μ,η和θ做加法,得到一个新的向量δ=μ+η+θ。分别用μ,η和θ除以δ对应列。即:

找出矩阵M中值最大的一项,以ηiδi为例:ηiδi对应的列,也就是第i列所对应的词,就是此实体对关系词中最能表示关系的词,且其对应的行,也就是对应的η,即“协同”关系。
找出向量η对应的ηi,若ηi的值大于0.5,则将ηi对应的词wi添加到“协同”关系种子备选词中。进一步判断是否将此关系词加入到“协同”种子中。
对于实体关系的程度,可以依据可靠度可以判断实体关系的程度。对于实体关系的可靠度,用最终选取的关系词对应的来表示。
2.2 种子关系词扩充
Bootstrapping是一种自扩展技术[14],通过少量标注信息[15],不断得到新的信息[16]。首先,选出不同关系的关系种子词各十个。然后依据关系种子词来进行军事实体对间关系判别。
对于这些种子备选词,计算其中的熵。用关系词αk与“敌对”关系的关系向量[μk1,μk2,…,μkn]为例。

其中:

若Entropy(W)的值大于等于0.9*log2n,则将此词语添加到当前关系种子词中。因为n个情况的最大熵[17]就是log2n,如果当前加入的这个词的信息熵不小于0.9倍的最大熵,则说明这个关系词不会使此关系种子偏差过大。
3 实验及分析
选取30万篇军事文本。通过分词器对30万篇军事文章进行分词,然后写入到一个文档中。文档中的每一行就是一篇已经分好词的文章,词与词之间以空格隔开。最后通过word2vec模型对此处理好的文档进行计算。将词向量模型维度设为256,窗口大小设为5,迭代次数设为10次。训练好的word2vec模型可以得到一个有202 196个词和202 196个256维的词向量文本。
虽然本文提出的方法支持自定义多种关系。但是由于本文主要处理的实体是人员,舰船,飞机,机构等。故提出3种实体关系[5“]:敌对”“,协同”和“伴随”。

表1 关系种子词
对表1中提出的30个不同关系种子词的词向量通过PCA降维,可以得到一个2*30的矩阵,通过可视化可以看出这30个词的分布情况。

图3 训练前的种子词分布情况
如图3所示,其中圆形的点是协同关系词,正方形点是伴随关系词,星形的点是敌对关系词。可以看出,这三种关系的关系词很清晰的划分成了3个簇[7]。

图4 训练后的种子词分布情况
通过本文提出的方法对1 000篇军事文本进行测试,可以得到3个被扩充的种子词簇。对这些种子词进行可视化。通过PCA算法将种子词的维度降到3维,如图4所示。可以看出其中分成了3个簇。其中十字的点是敌对种子簇,圆形的点是协同种子簇,星形的点是伴随种子簇。

表2 word2vec模型训练语料对关系识别的影响
由表2数据来看,通过Word2vec模型与Bootstrapping和FPGrowth方法进行实体关系识别。其中对Word2vec模型训练有两种方式,一种是通过30万篇各类别文章进行训练,最终得到的关系识别准确率为85.3%,一种是通过30万篇军事文本进行的训练,得到的准确率为92.1%。
虽然通过各类型的文本进行训练的word2vec模型具有一定的泛化能力,但是对于军事领域的实体关系识别,选择带有针对性的军事文本训练的模型效果更为理想。

表3 频繁项集词语选择对关系识别的影响
由表3数据来看,通过Word2vec模型与Bootstrapping和FPGrowth方法进行实体关系识别。其中对FPGrowth的频繁项的提取有3种方法,一种是提取实体与实体之间的词与作为一个集合,最终得到的准确率为90.2%,效果相对较差。一种是提取实体之间的词与实体之后的所有词语作为一个集合,最终得到的准确率为92.1%,效果最好。一种是选取全句中所有词语作为一个集合,最终得到的准确率为91.9%,效果也不错。可以看出,选择实体间词语和实体后词语作为频繁项集中一项进行特征词提取效果最好,但是与其他方法相差不大。
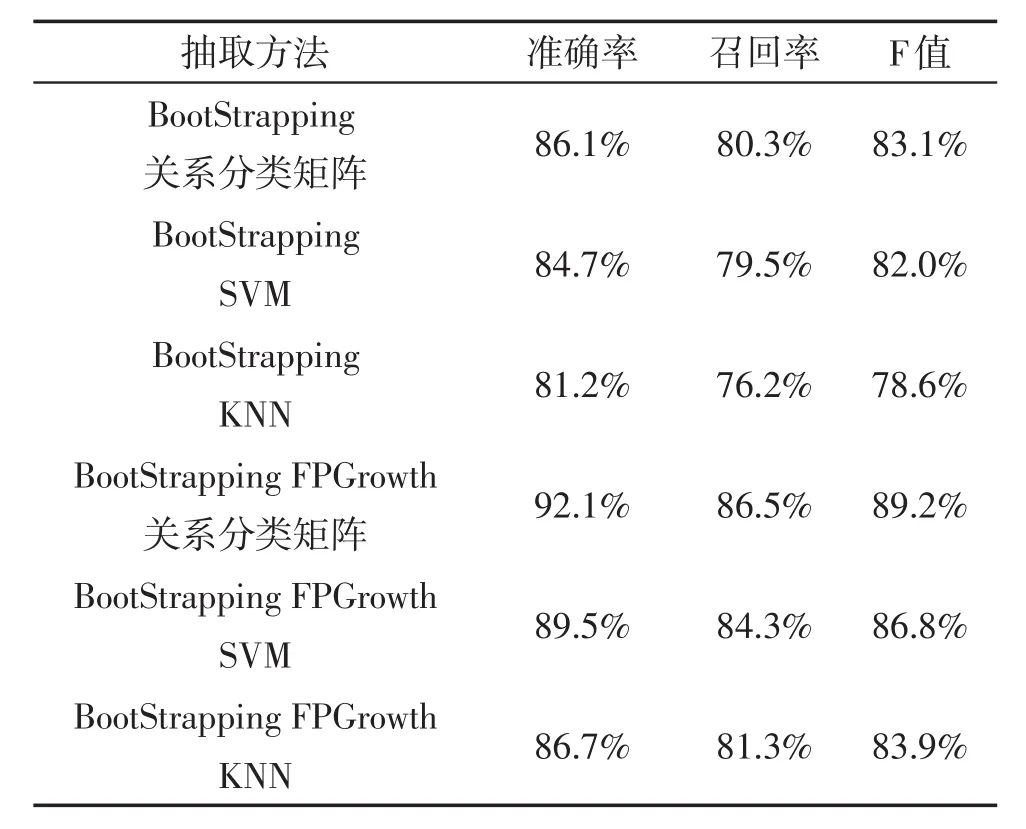
表4 实体关系识别评价表
由表4数据来看,通过牟晋娟提出的BootStrapping与SVM方法的F值为82%。通过BootStrapping与KNN的识别方法F值为78.6%。BootStrapping与SVM的识别方法F值为82.0%。文本提出的通过BootStrapping与FPGrowth识别方法的F值为89.2%。
可以看出,通过一次FPGrowth方法可以准确表征出军事实体之间关系特征词,并且由于军事文本的表述严谨,措词严格,语义二义性少。依据关系分类矩阵进行判断,能极大地提高实体关系识别的准确率。

表5 与卷积神经网络进行比较
由表5可以看出,本文提出的方法与肜博辉等提出的多通道卷积模型进行对比。若不进行FPGrowth提取特征词,单纯的依靠实体前后个两个词进行卷积的效果并不是很理想。通过卷积神经网络和FPGrowth进行的实体关系识别,与本文提出的方法准确率相差不大,但是却需要大量人手进行标注。而本文提出的弱监督军事实体关系识别并不需要手工标注,只需要给出少量的初始种子词即可。这种方式可以应用于许多没有标注语料的新领域中。
4 结束语
文中提出一种基于word2vec和FPGrowth的弱监督实体关系识别技术。通过自扩展技术进行关系词扩充,使用word2vec模型表征关键词与特征词之间的关系,并用FPGrowth方法对实体关系进行潜在特征词抽取。最后依据关系分类矩阵对实体对关系进行分类。其中,改变了实体关系特征词提取的方式,由取出实体前后若干词作为特征词改为依靠FPGrowth提取最大频繁项作为特征词;还有就是能够处理自定义的多种关系,不仅仅限于本文提出的“协同”,“伴随”,“敌对”。最终通过与同类弱监督和深度学习之间的对比实验可以看出,文中提出的方法有效。
[1]周亦,周明全,王学松,等.大数据环境下历史人物知识图谱构建与实现[J].系统仿真学报,2016,28(10):2560-2566.
[2]Surdeanu M,Tibshirani J,Nallapati R ,et al.Multi-instancemulti-lable learning for relation extraction[C]//Proc of the EMNLP 2012//Stoudsburg,PA:ACL,2012:455-465.
[3]Li L,Jin L,Jiang Z,et al.Biomedical named entity recognition based on extended Recurrent Neural Networks[C]// IEEE International Conference on Bioinformatics and Biomedicine.IEEE,2015:649-652.
[4]肜博辉,付琨,黄宇,等.基于多通道卷积神经网的实体关系抽取[J].计算机应用研究,2017(3):689-692.
[5]甘丽新,万常选,刘德喜,等.基于句法语义特征的中文实体关系抽取[J].计算机研究与发展,2016,53(2):284-302.
[6]秦兵,刘安安,刘挺.无指导的中文开放式实体关系抽取[J].计算机研究与发展,2015,52(5):1029-1035.
[7]贾真,何大可,杨燕,等.基于弱监督学习的中文网络百科关系抽取[J].智能系统学报,2015(1):113-119.
[8]牟晋娟,包宏.中文实体关系识别研究[J].计算机工程与设计,2009,30(15):3587-3590.
[9]段利国,徐庆,李爱萍,等.实体词语义信息对中文实体关系抽取的作用研究[J].计算机应用研究,2017,34(1):141-146.
[10]Zhang D,Xu H,Su Z,et al.Chinese comments sentiment classification based on word2vec and SVM perf[J].Expert Systems with Applications,2015,42(4):1857-1863.
[11]刘华伟.基于神经网络的物联网实体信息交互关系识别[J].电脑知识与技术,2017,13(4):175-177.
[12]J.Suresh1 P R C T.Generating associations rule mining using,Apriori and FPGrowth Algorithms[J].International Journal of Computer Trends&Technology,2013,4(4):887-892.
[13]杨宇飞,戴齐,贾真,等.基于弱监督的属性关系识别方法[J].计算机应用,2014,34(1):64-68.
[14]张奇,金培权,岳丽华.基于CRF的网页动态关系抽取研究[J].中国科学技术大学学报,2010,40(11):1197-1202.
[15]张素香,李蕾,秦颖,等.基于Boot Strapping的中文实体关系自动生成[J].微电子学与计算机,2006,23(12):15-18.
[16]段宇锋,朱雯晶,陈巧,等.朴素贝叶斯算法与Bootstrapping方法相结合的中文物种描述文本语义标注研究[J].现代图书情报技术,2014,30(5):83-89.
[17]王风娥,谭红叶,钱揖丽.基于最大熵的句内时间关系识别[J].计算机工程,2012,38(4):37-39.
