基于深度学习的图像识别算法研究
2018-01-13衣世东
◆衣世东
(信息工程大学 河南 450002)
0 引言
随着科技的不断发展,智能手机、数码相机等电子设备逐渐普及,人们获取图像的手段也越来越丰富。如何从海量的图像中提取到有用的特征信息,进而对图像进行辨别变得十分重要。2006年深度学习算法的提出,凭借其强大的数学表征能力,迅速成为图像识别领域的研究热点。深度学习通过深度神经网络构建算法,能够对图像特征进行分层提取,并且通过大量数据训练自动学习特征,提取全局特征和上下文信息的能力,极大推动了图像识别技术的发展。
近些年来,用于图像识别的深度学习算法不断取得突破,算法模型不断涌现。主要有早期的深度信念网络(Deep Belief Nets,DBN)、去噪自动编码机(DenosingAutoencoder)、三元因子玻尔兹曼机、深度玻尔兹曼机及卷积神经网络等。本文梳理了深度学习的基本原理,基于深度学习的图像识别算法的研究现状及性能对比,并展望了深度学习在图像识别领域的发展方向。
1 深度学习的原理及发展历程
1.1 深度学习的基本原理
深度学习通过模拟人类大脑处理信息的分层机理,构建一个包含不少于3层的隐含层的架构模型,逐层对输入样本提取特征,最后输出能够正确还原该样本。
设一个系统 S包含了 n层网络结构,各层分别标记为S1,S2,S3,…Sn,系统的输入为I,输出为O,则该系统的深度学习网络结构数学表达式可以简单表示为:I=>S1=>S2=>S3…=>Sn=>O,如果得到的输出O与输入I相等,则表示I经过逐层变换之后,得到的O与I之间包含的数据没有改变,每一层Si都是输入I的另外一种表示。在实际的深度学习模型中,输入I经过每一层都会丢失部分信息,所以需要不断调整系统的参数,使得O与I之间的误差尽可能的小,从而获取I的每一层近似的特征表示S1’,S2’,S3’,…Sn’。
利用这种深层网络系统可以很好地进行图像识别,其中I表示输入的原始图像,经过逐层提取图像特征,最终输出O实现图像的分类识别。第Si层的输出作为第Si+1层的输入,第Si+1层的特征比第Si层的特征具有更高的区分性,并且通过训练调整各层参数使输入与输出的结果接近,最后利用分类器对O中的特征进行分类识别。
1.2 深度学习的发展历程
深度学习起源于人工智能,主要模拟人脑的神经网络,采用多个非线性变换结构对已知数据进行高层次的抽象建模,并对未知事件作出预测和决定。20世纪80年代以来,随着适用于多层感知器的反向传播算法的提出,有效解决了人工神经网络的非线性分类和学习问题,神经网络迎来了大发展。
2006年,加拿大多伦多大学的Hinton教授提出了深度置信网络(deep belief network,DBN),该网络由一系列受限波尔兹曼机(Restricted Boltzmann Machine,RBM)构成,采用无监督的逐层贪婪训练提取特征,获取多个层级的深度网络结构,通过有监督的调整训练,避免网络收敛到局部最小值。该研究成果的发表,掀起了深度学习的发展热潮。2012年的 ImageNet挑战赛上,Hinton教授的研究小组采用基于CNN的检测模型Alexnet一举夺得冠军,使得深度学习在图像识别领域的应用取得巨大成功,Google、Facebook、Microsoft、百度等科技巨头纷纷成立研究机构继续开展深度学习领域的研究。
2 基于深度学习的图像识别算法研究及性能对比
2.1 基于深度学习的图像识别算法的基本原理
由于图像数据可以认为是一组二维像素值输入,而卷积神经网络(Convolutional Neuron Networks,CNN)由若干个卷积层及全连接层组成,并且包括相关权值和池化层,CNN的这种结构能够充分利用数据的二维结构,使得识别图像具有较高的准确率。CNN还使用标准的反向传播算法进行训练,具有较少的参数估计,相较其他深度模型也更容易训练。
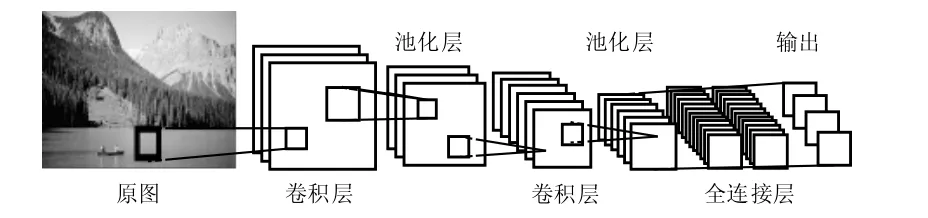
图1 基于CNN的图像识别的模型图
如图1所示为基于CNN的图像识别基本模型。首先该模型对输入图像进行区域划分,之后将图像输入 CNN网络进行特征提取和识别,最后根据图像特征进行分类。
2.2 基于深度学习的图像识别算法的研究进展
(1)区域卷积神经网络(Region CNN)算法
区域卷积神经网络(R-CNN)算法首先利用Selective Search将图像划分为2000个统一分辨率的分块,之后输入CNN提取特征值,再经分类器进行分类识别,找到最终的特征窗口,最后使用回归器精细修正特征窗口的位置。文献[14]针对传统基于深度学习的图像识别候选窗选择随机识别速度慢及准确率不高等问题,将RCNN方法引入检测领域,一举将PASCAL VOC 2010上的检测准确率从35.1mAP提升到了53.7mAP。
(2)空间金字塔池化算法
空间金字塔池化(Spatial Pyramid Pooling,SPP)算法引入SPP层进行提取特征。首先SPP-Net对待检测的图像划分出2000个候选窗,之后采用金字塔空间池化将整幅待检测图像送入 CNN网络,提取固定长度的特征向量,最后采用支持向量机(Support Vector Machine,SVM)算法进行特征向量的分类识别。由于SPP-Net算法将所有的卷积只计算一次,解决了R-CNN算法中特征提取重复计算的问题,因此检测效率大大提高。文献[15]中在同等条件下与 R-CNN进行比较发现识别速度大幅提高,将R-CNN的识别准确率从58.5mAP提高到59.2mAP,而且速度快了24倍。
(3)快速R-CNN算法
快速R-CNN(Fast R-CNN)算法引入一个简易的SPP层——感兴趣池化层(Region of Interest Pooling Layer)进行特征提取。Fast R-CNN首先对输入图像提取出 2000个左右的区块,通过CNN中的卷积层和池化层生成特征映射,在最后一个卷积层上对每个RoI求映射,并引入RoI池化层统一大小。经过两个全连接层之后得到两个输出向量:一个是分类函数,使用softmax函数进行目标识别;另一个是用回归模型进行边框位置大小的微调。
RoI池化层的输入是N个特征映射和R个RoI(R>>N)。N个特征映射来自于最后一个卷积层,每个特征映射大小均为H×W×C。每个RoI是一个元组(n, r, c, h, w),n是特征映射的索引,n∈{0, ... ,N-1},(r,c)是RoI左上角的坐标,(h, w)是高与宽。池化层的输出是最大池化过的特征映射,大小为 H′×W′×C(H′≤H,W′≤W)。对于RoI,网格大小近似为h/H′×w/W′,这样就有H′W′个输出映射,其大小取决于RoI的大小。
文献[16]实验证明,在相同情况下Fast R-CNN比R-CNN的训练速度快8.8倍,测试时间快213倍,比SPP-Net训练速度快2.6倍,测试速度快10倍左右。
(4)Faster R-CNN算法
Faster R-CNN算法引入区域建议网络(Region Proposal Network,RPN)替代R-CNN中候选框提取法,采用了RPN+Fast R-CNN的方法。Faster R-CNN首先利用RPN对图像进行候选框提取,之后采用Fast R-CNN的方法对RPN提取的特征框进行检测并识别图像中的目标。
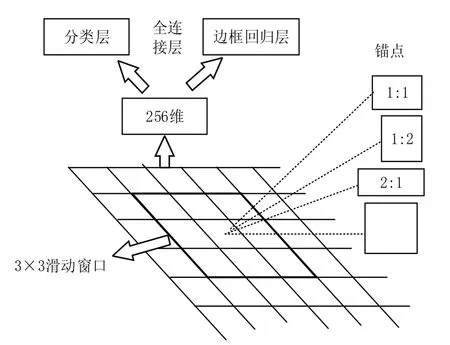
图2 RPN流程图
RPN流程如图 2所示,这里以 ZF模型为例。首先 Faster R-CNN使用一个3×3的滑动窗口在末端卷积得到的特征图上进行卷积,生成一个长度为256维的低维向量,最后将该向量送到两个全连接层分别用于分类和边框回归,同时 3×3的滑动窗口对应每个特征区域同时预测输入图像的3种尺寸和长宽比,称为锚点。
文献[17]测试的该算法在简单网络目标检测速度达到了17FPS,在VOC 2007上检测准确率达到了59.9%,复杂网络检测速度可达5FPS,准确率为73.2%。
(5)YOLO算法
YOLO网络借鉴了GoogLeNet分类网络结构,首先将输入图像分成若干个网格,每个格子负责检测划分到该格子中的物体。若某个物体中心位置的坐标落入到某个格子,那么这个格子就负责检测出该物体。每个格子的输出包含物体的边界框信息及物体类别的概率信息。因此,输入图像只要经过一次检测,就会得到图像中所有物体的位置及其所属类别的置信概率。
文献[20]中描述该方法基础版的检测速度可达45FPS的实时检测,快速版检测速度可高达155FPS,并且背景误差率低。
(6)SSD算法
SSD网络分为两个部分,包括一个去掉与分类相关层的图像分类基础网络和卷积特征层。卷积层的特征图选取大小随机,以便能够检测出不同尺度的物体。卷积特征层获取到的每个特征图上的每个点,按照不同的分类和长宽比生成k个默认框。
新增加的每个卷积层的特征图都会通过一些小的卷积核操作,得到对应的默认框相对不同物体类别 (c1,c2,…,cp) 的偏移及其置信度。在大小为 m×n, 具有 p通道的特征图上,若使用的卷积核为3×3×p,则对于一个特征图上k个默认框中的每一个点,需要计算出c个类别,还有这个点相对于它的默认框的4个偏移值。在特征图中的每一个点上,需要有(c+4)×k个卷积滤波器。对于一张m×n大小的特征图,会有(c+4)×k×m×n个输出结果。
文献[22]验证了SSD 相比较于其他单结构模型(如YOLO)能够取得更高的精度,在VOC 2007测试中,当输入大小为300×300的图像时,SSD在GPU中能够以46FPS取得74.3%的mAP。当输入图像大小为512×512时,SSD能够以22FPS取得了76.8%的mAP。
(7)各算法的比较分析
R-CNN算法采用了滑动窗口的方法进行候选框提取,再用CNN对候选框进行图像特征提取,最后用SVM分类器进行图像分类;SPP-Net取消了候选框大小固定的限制,可以对任意尺寸的特征进行池化;Fast R-CNN、Faster R-CNN则分别用分类+回归和RPN代替了SVM和特征框提取,更好地加速了训练和识别的速度。YOLO与R-CNN类似,但是通过共享卷积特征方法提取候选框和目标识别;SSD则采纳了RPN和YOLO的特长,能够达到更高的识别精度。各算法的具体性能对比如表1所示。

表1 各识别算法性能对比
3 深度学习在图像识别领域的未来发展
随着深度学习的发展以及图像识别领域需求量的不断增加,未来深度学习在图像识别的发展趋势会越来越优化,越来越智能。本文提出了未来深度学习在图像识别领域的一些发展方向:
3.1 模型层次不断增加,结构日趋复杂
深度学习需要对图像的目标特征进行逐层建模,如果网络模型的深度不够,其所需要的计算单元会呈指数增加,而随着图像识别复杂度的增加,需要将图像划分成越来越多的局部区域,这就需要不断加深模型层次。通过多个层次的特征学习,模型学到的特征越来越全局化,越来越真实的还原图像,例如,AlexNet获得ImageNet 2012冠军时所用的网络使用了5个卷积层、3个pool层和2个全连接层。ILSVRC2014的冠军GoogLeNet使用了59个卷积层、16个 pool层和 2个全连接层。2015年,微软的ResNet更是使用了152个卷积层,模型的深度和复杂度可见一斑。
3.2 训练数据的规模迅速增加
由于深度学习模型越来越复杂,需要的特征也越来越多,这就需要大量的训练数据来提升分类或预测的准确性。目前,深度学习算法的训练数据普遍都是几十万、上百万级别,对于Google、Facebook、Microsoft、百度等科技巨头来讲,其训练数据则是千万、甚至数亿级别,ImageNet全库已经收集将近2.2万个类别共约1420万幅图像,但是现有的图像数据依然不能满足日益增长的训练需求。
3.3 模型的识别效率和检测精度越来越高
随着深度学习模型的不断发展,图像识别效率和准确率都有了大幅度的提升。早期的R-CNN模型在GPU上处理一张图片需要13s,CPU上则需要53s,其在PASCAL VOC 2007上的检测准确率可达53.7%。而2015年的Faster R-CNN模型在简单网络目标的检测速度达到了17FPS,复杂网络环境下也可到5FPS,准确率可达78.8%。2016年的YOLO模型在保证检测准确率不下降的前提下,可以达到45FPS的检测速度。模型识别效率和检测精度不断提高。
4 结束语
近些年来,随着深度学习领域的研究不断深入,极大地推动了图像识别技术的研究进展,图像识别技术的研究和应用突飞猛进。世界各大科技公司纷纷投入巨资收购和建设以图像识别为主要课题的智能团队。可以预见,在未来的数年内,深度学习将会在理论、算法和应用等各方面进入高速发展的时期,也必将对图像识别领域和其他相关行业产生深远的影响。
[1]王晓刚.图像识别中的深度学习[J].中国计算机学会通讯,2015.
[2] Hinton G E,Osindero S,Teh Y W.A fast learning algorithm for deep belief nets[J].Neural Computation,2006.
[3] Vincent P,Larochelle H,Bengio Y,et al.Extracting and composing robust features with denoising autoencoder s[C]//Proc eedings of the 25th International Conference on Machine Learning,New York,Ny,Usa,2008.
[4] Ranzato M A,Hinton G E.Modeling pixel means and covariances using factorized third-order boltzmann machines[C]//IEEE Conference on Computer Vision and Pattern Recognition,SanFrancisc,CA:IEEE,2010.
[5] Salakhutdinov R,Hinton G E.Deep boltzmann machines[C]//International Conference on Artificial Intelligence and Statistics,2009.
[6] Deng L,Abdel-Hamid O,Yu D.A deep convolutional neural network using heterogeneous pooling for trading acoustic invariance with phonetic confusion[C]//Acoustics,Speech and Signal Processing(ICASSP),2013 IEEE International Conference on.IEEE,2013.
[7] Y Bengio,A Courvile,P Vincent.Representation learning:A Review and New Perspectives[C]//IEEE Trans. PAMI,special issue Learning Deep Architectures,2013.
[8] Rumelhart D E,Hinton G E,Williams R J.Learning representations by back-propagating errors[J].Nature,1986.
[9] Mohamed A R,Dahl G,Hinton G E.Deep belief networks for phone recognition[C]//NIPS 22 Workshop Deep Learning for Speech Recognition,2009.
[10] Salakhutdinov R,Mnih A,Hinton G E.Restricted Boltzmann machines for collaborative filtering[C]//Proceedings of the 24th International Conference on Machine Learning,ACM,2007.
[11] Krizhevsky A,Sutskever I,Hinton G E.ImageNet classification with deep convolutional neural networks[C]//Neural Information Processing Systems,2012.
[12]LeCun Y,Bottou L,Bengio Y,et al.Gradient-based learning applied to document recognition[C].Proceedings of the IEEE,1998.
[13]Scherer D,Müller A,Behnke S.Evaluation of pooling operations in convolutional architectures for object recognition[C]//International Conference on Artifical Neural Networks,2010.
[14]Girshick R,Donahue J,Darrell T,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[C]//International Conference on Computer Vision and Pattern Recogintion(CVPR),2014.
[15]He K M,Zhang X Y,Ren S Q,et al.Spatial pyramid pooling in deep convolutional networks for visual recognition[C].IEEE Transactions on Pattern Analysis & Machine Intelligence,2015.
[16]Girshick R.Fast R-CNN[C]//International Comference on Computer Vision(ICCV),2015.
[17]Ren S Q,He K M,Girshick R,et al.Faster R-CNN:towards real-time object detection with region proposal networks[C].IEEE Transactions on Pattern Analysis & Machine Intelligence,2015.
[18]Zeiler M D,Fergus R.Visualizing and understanding convolutional networks[C].European Conference on Computer Vision,2014.
[19]Szegedy C,Liu W,Jia Y,et al.Going deeper with convolutions[C]//International Conference on Computer Vision& Pattern Recogintion(CVPR),2015.
[20]Redmon J,Divvala S,Girshick R,et al.You only look once:unified,real-time object detection[C]//International Conference on Computer Vision & Pattern Recogintion(CVPR),2016.
[21]Simonyan K,Zisserman,A.Very deep convolutional networks for large-scale image recognition[C]//International Conference on Learning Representations(ICLR),2015.
[22]Liu W,Anguelov D,Erhan D,et al.SSD:single shot multiBox detector[C]//European Conference on Computer Vision(ECCV),2016.
[23]He K M,Zhang X Y,Ren S Q,et al.Deep residual learning for image recognition.[C]//International Conference on Computer Vision & Pattern Recogintion(CVPR),2016.
