基于RNN结构下的字母级别语言模型的研究与实现
2018-01-13郭邵忠
◆刘 辰 郭邵忠 殷 乐
(信息工程大学四院 河南 450001)
0 引言
随着人工智能技术的发展,RNN模型被广泛应用在语音识别,机器翻译和文本生成等领域,并取得了举世瞩目的效果。Recurrent Neural Network (RNN)是一种能学习向量到向量之间映射关系的强力模型,它适用于时序数据集上。但由梯度爆炸和梯度消失的问题的存在,使得RNN结构难于训练。在学者们的努力下,提出了Long Short-Term Memory (LSTM)模型,解决了梯度消失的问题。梯度爆炸问题相对梯度消失复杂的多,Mikolov与Pascanu通过强制约束梯度范数解决了该问题。Cho 等人提出名为lstm的一种新的改进型Gated Recurrent Unit (GRU),在语言模型的实际应用背景中,两种实现方法效果不分伯仲。
在natural language processing (NLP)任务中,语言模型是一项基础工作。语言模型是一个单纯的、统一的、抽象的形式系统,语言客观事实经过语言模型的描述,比较适合于电子计算机进行自动处理,因而语言模型对于自然语言的信息处理具有重大的意义。
神经语言模型Neural Language Models (NLM)通过将词的参数化作为向量,并将其用作神经网络的输入,取得了很好的效果。
虽然NLM比以往的基于统计的语言模型性能表现出色,但是该模型不能分辨出词根,词缀或者分词等信息,例如 like和unlike两词应在embedding时候空间位置距离比较接近,这个功能上述模型无法实现。因此,训练集中没有或者出现几率特别小的词,模型无法理解。实际应用中,尤其在俄文语境下,词态变化繁复,使得模型训练成本增大,性能下滑。为了克服上述不足,本文设计了一种char-level语言模型,该模型的输入是一个个字符。同Botha and Blunsom 2014; Lu-ong,Socher,andManning2013相比下,我们的模型不需要词素标注,将字母一个个输入模型就可以。同 Dos SantosandZadrozny 2014比较,我们的模型不需要word-embedding,只需要 char-embedding。我们的模型适用于多种语言,中文的汉字也可以视为char,此时在softmax函数中加入分层功能,运行速度会明显提高。
1 模型
1.1 循环神经网络语言模型
若V是所有word的集合,w是V中的任意一个元素(1个word),语言模型可以描述如下:若wi∶t= [w1,…,wt]是历史出现的word序列,那么语言模型就是描述wt+1出现可能和各个可能的概率情况的工具。
数据首先经过向量化操作(char-embedding),而后经过Highway层,再经过RNN层后会通过一个softmax函数,它将计算输出端的各个可能性大小,并通过评价函数和同训练数据相匹配的正确结果来复核评估网络输出,最后通过bp算法来校正网络参数。如图1。

图1 模型各模块情况
1.2 循环神经网络层
循环神经网络是一种节点定向连接成环的人工神经网络。这种网络的内部状态可以展示动态时序行为。不同于前馈神经网络的是,RNN可以利用它内部的记忆来处理任意时序的输入序列,这让它可以更容易处理如不分段的手写识别、语音识别等。神经网络专家如 Jordan,Pineda.Williams,Elman等于上世纪 80年代末提出的一种神经网络结构模型。即循环神经网络(Recurrent Neural Network,RNN)。这种网络的本质特征是在处理单元之间既有内部的反馈连接又有前馈连接。从系统观点看,它是一个反馈动力系统,在计算过程中体现过程动态特性,比前馈神经网络具有更强的动态行为和计算能力。在每个时间脉冲 t,需要输入一个向量Xt,并结合上一时间脉冲t-1的隐藏状态向量ht-1,计算出当前时间脉冲下的输出向量ht。
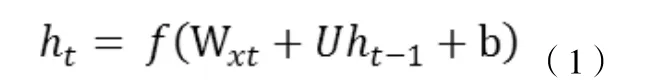
nn.Linear(inputDimension, outputDimension, [bias = true])
在理论上,RNN可以追溯所有的历史隐藏状态向量ht,并以之计算当前时间脉冲输出。在实际应用时候,使用上述 vanilla RNN模型由于梯度下降和梯度爆炸等问题的存在,难以学习到long-range dependencies 。也就是说,这种模型在短句语义理解上较为出色,而且实现简单,计算量小,但是遇到较长句,就容易丢失前序信息。Long short-term memory (LSTM)应运而生。该模型具体思想就是在 vanilla RNN模型内加入一个 cell向量,这样,每一个时间脉冲下,LSTM模型就获得了3个输入向量:xt,ht-1,ct-1。简明表达LSTM每个时间脉冲计算公式如下:
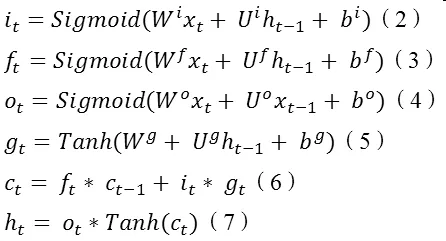
这里的Sigmoid运算符在torch框架上对应nn.Sigmoid,Tanh运算符对应nn.Tanh,‘*’运算符对应nn.CMulTable()(),ct等式中运算符‘+’对应nn.CAddTable()()。
1.3 Highway Network
当语言模型输入端为字符时,在 RNN模型的基础上使用Highway Network可以很大程度提高精度,当语言模型输入为word时无明显效果。在本文中,我们采用1或2层的Highway Network,具体公式如下:

2 实验设定
语言模型评价函数如下:

NNL是在网络训练过程产生的评价数据,T为训练时间。English Penn Treebank (PTB),是一个标准的英语语言模型测试集,我们将在这个测试级上评估实验结果。

表1 PTB测试集情况
实验数据集如表 1所示,其中|V|是语料中的总词汇量,|C|是字符数目,T是训练集中的token数量。Data-s是Peen Treebank库,Data-L是News-Commentary库,该库中有一些非英语符号,所以字符种类较多。

表2 各个网络层参数配置
表2所示为实验模型各层次网络参数设置。Small模型采用1层的Highway激活函数是Relu(),而后通过LSTM模块(2层,每层300单元)。Large模型Highway模块设为2层,激活函数不变,LSTM模块也是2层,每层设为600单元。
只有2G显卡情况下,large数据集上lstm个数每层最大不能超过600,实验结果也证实了每层600个lstm单元已经能够满足实验需要,盲目加大数目对结果的影响不明显。
本文考虑实验的灵活性,将输入模块设计为两种输入模式:字符模式和单词模式。该模型可以转换为word-level 语言模型,只需更新参数转换输入,而后进行单词级别的语言模型训练。
实验优化。在试验中,遍历25epochs训练集,在Data-S训练集中使用batch-size = 20,在Data-L中使用batch-size = 100,这两组数字都是其他论文中使用该数据集的经验数字,在本次试验中效果良好。
在参数初始化阶段,采取了随机初始化,并且控制参数初始化的范围在[-0.05,0.05]这样可以避免产生的模型‘偏激’,难以训 练 。 在 LSTM 的 input-to-hidden(highway之 后)和hidden-to-output(softmax()之前)使用了dropout规则,设定参数为 0.5,这样提高了训练精度。我们限定梯度更新的速率,避免训练结果偏激,若梯度更新的L2范数大于5那么更新时最大可用更新幅度设为5.0。
3 实验结果
图2是训练loss与测试loss对比图(LSTM-Char in Data-S),图中可见训练过程中参数收敛正常,测试收敛正常,训练效果显著,在最后的全集测试中,取得(PPL=92.418545711755)的评价结果。

图2 训练以及测试曲线

表3 训练结果
表3所示为最终实验结果(PPL数值越小越好)。其中前四行为本文所做工作,最后两行为现阶段经典模型实验结果。从模型的评价来看,我们实现的 LSTM-Word-Large模型稍逊色于LSTM-2 (Zaremba 2014)但我们使用的lstm单元个数少于他们。整体结果来看,我们模型实现已经达到了上游水平。
4 结论
本文实现了一种char-level的语言模型,语言模型是自然语言处理的一个基础工作,是学习深度学习框架入门的良好课题。一些trciks在提高结果精度显得特别重要,可以说有些操作直接影响到了结论。想要做一个好用的语言模型比较困难,具体应用的语境下必须取得好的数据,再结合结构的研究和一些技巧才能达到可用的要求,而好用的要求更需要深入的研究和探索。本实验更换输入数据也会输出一些有意思的东西,例如输入唐诗300首,也可以自动做唐诗,其结果也是刚刚达到了‘说人话’的水平。下一步的改进目标是尝试在模型中加入更多网络信息,类似于Net Embedding的做法。Word Embedding与Net Embedding相互借鉴是一个趋势。
[1] Bengio Y, Simard P, Frasconi P. Learning long-term dependencies with gradient descent is difficult.[J]. IEEE Transactions on Neural Networks,1994.
[2]Surhone L M, Tennoe M T, Henssonow S F. Long Short Term Memory[J]. Betascript Publishing,2010.
[3]Pascanu R, Mikolov T, Bengio Y. On the difficulty of training recurrent neural networks[C]// International Conference on International Conference on Machine Learning. JMLR.org,2013.
[4] Chung J, Gulcehre C, Cho K H, et al. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling[J]. EprintArxiv,2014.
[5]Bengio Y, Schwenk H, Senécal J S, et al. Neural Probabilistic Language Models[J]. Journal of Machine Learning Research,2003.
[6] Mikolov T, Karafiát M, Burget L, et al. Recurrent neural network based language model[C]// INTERSPEECH 2010,Conference of the International Speech Communication Association, Makuhari, Chiba, Japan, September. DBLP,2010.
[7] Botha J A, Blunsom P. Compositional Morphology for Word Representations and Language Modelling[J]. Computer Science,2014.
[8]Luong T, Socher R, Manning C D. Better Word Representations with Recursive Neural Networks for Morphology[C]// Conference,2013.
[9] Santos C N D, Guimarães V. Boosting Named Entity Recognition with Neural Character Embeddings[J]. Computer Science,2015.
[10] Bengio Y, Simard P, Frasconi P. Learning long-term dependencies with gradient descent is difficult.[J]. IEEE Transactions on Neural Networks,1994.
[11] Srivastava R K, Greff K, Schmidhuber J. Training very deep networks[J]. Computer Science,2015.
[12]Marcus M P, Marcinkiewicz M A, Santorini B. Building a large annotated corpus of English: the penntreebank[M]. MIT Press,1993.
[13] Hinton G E, Srivastava N, Krizhevsky A, et al. Improving neural networks by preventing co-adaptation of feature detectors[J]. Computer Science,2012.
[14]Zaremba W, Sutskever I, Vinyals O. Recurrent Neural Network Regularization[J]. EprintArxiv,2014.
[15]骆小所.语言的接缘性及其分支学科[J].云南师范大学学报(哲学社会科学版),1998.
[16]雷铁安, 吴作伟, 杨周妮.Elman递归神经网络在结构分析中的应用[J].电力机车与城轨车辆,2004.
