基于随机矩阵理论的高维数据特征选择方法
2018-01-08孙凌峰李玉诺宋宝燕
王 妍,杨 钧,孙凌峰,李玉诺,宋宝燕
(1.辽宁大学 信息学院,沈阳 110036; 2.荣科科技股份有限公司 智慧城市开发部,沈阳 110027)
基于随机矩阵理论的高维数据特征选择方法
王 妍1,杨 钧1,孙凌峰1,李玉诺2,宋宝燕1*
(1.辽宁大学 信息学院,沈阳 110036; 2.荣科科技股份有限公司 智慧城市开发部,沈阳 110027)
传统特征选择方法多是通过相关度量来去除冗余特征,并没有考虑到高维相关矩阵中会存在大量的噪声,严重地影响特征选择结果。为解决此问题,提出基于随机矩阵理论(RMT)的特征选择方法。首先,将相关矩阵中符合随机矩阵预测的奇异值去除,从而得到去噪后的相关矩阵和选择特征的数量;然后,对去噪后的相关矩阵进行奇异值分解,通过分解矩阵获得特征与类的相关性;最后,根据特征与类的相关性和特征之间冗余性完成特征选择。此外,还提出一种特征选择优化方法,通过依次将每一个特征设为随机变量,比较其奇异值向量与原始奇异值向量的差异来进一步优化结果。分类实验结果表明所提方法能够有效提高分类准确率,减小训练数据规模。
随机矩阵;特征选择;去噪;奇异值;相关矩阵
0 引言
随着数据获取技术的发展,高维数据广泛应用在智能电网[1]、图像处理[2]、无线通信[3]等领域中。对于包含了大量冗余信息和噪声的高维数据,通常先采用特征提取和特征选择[4]对其进行降维。根据特征子集评估策略的不同,传统的特征选择可分为三类[5]:Filter模型、Wrapper模型和Embedded模型。Filter模型仅依赖数据的内在特性来选择特征,而不依赖任何具体的学习算法指导。Wrapper模型则需要一个预先设定的学习算法,根据特征子集在学习算法上的表示来确定特征子集。Embedded模型则是在学习算法的目标分析过程中进行变量选择,将其作为训练过程的一部分。这三种模型都是通过相关性度量来选择特征, 但是对于高维数据,得到的相关矩阵中会存在大量噪声。
随机矩阵理论(Random Matrix Theory, RMT)[6]通过比较随机的多维序列统计特性,可以体现出实际数据对随机的偏离程度,并揭示实际数据中整体关联的行为特征。韩华等[7]研究了相关矩阵和随机矩阵特征值的统计性质来去除相关矩阵中的噪声。Plerou等[8]研究了相关矩阵的特征向量分布和相关矩阵的优化。徐心怡等[9]利用随机矩阵,提出了一种相关性分析方法,验证了RMT在处理复杂系统中的海量数据时具有优越的性能。对于奇异值特征选择,Freedman等[10]研究了奇异值分解在局部相似性的应用。Varshavsky等[11]提出了基于奇异值分解的无监督特征选择方法,将奇异值作为识别特征,能够通过较大的奇异值快速确定特征。Banerjee等[12]提出一种基于奇异值熵的特征选择方法,但是可能无法丢弃具有恒定值的均匀无关的特征。然而以上这几种基于奇异值分解的特征选择方法并没有考虑到噪声奇异值对特征选择的影响。
因此,本文提出一种基于RMT的高维数据特征选择方法(Feature Selection method of high dimensional data based on RMT, RMFS),通过比较原始数据的相关矩阵和随机数据的相关矩阵在奇异值上的差异,去除原始相关矩阵的噪声,同时充分利用奇异值分解后的子矩阵来消除特征之间的冗余性,更好地实现特征选择。本文又提出一种特征选择优化方法——RMFS-O(Optimization for RMFS),依次将每一个特征设为随机变量,得到随机特征矩阵,通过计算其与原始特征矩阵在奇异值上的差异,进一步优化特征选择结果。最后UCI数据集上的分类实验在分类准确率和特征选择数量上表明了本文方法的高效性。
1 随机矩阵理论
一个以随机变量为元素的矩阵称为随机矩阵。当随机矩阵的行数和列数趋于无穷大,且行列比值保持恒定时,随机矩阵的经验谱分布(Empirical Spectral Distribution,ESD)函数具有很多优良的特性,如半圆律(Semi-Circle Law)、M-P 律(Marchenko- Pastur Law)、单环定理(Single Ring Theorem)等。虽然理论上当矩阵维数趋近无穷能满足随机矩阵的收敛性,但是在规模比较适中的矩阵(维数从几十到几百)中,也能观察到相当精确的渐近收敛结果[13]。这也是RMT能被用于处理实际高维数据的前提。M表示随机矩阵,根据RMT定义,则有:
M=EET/L
(1)
其中:E是一个N×L的随机矩阵,其满足均值是0、方差为1。M就是Whishart矩阵,该矩阵在数学上已经有了详细的研究。令Q=N/L,当Q固定,L→∞,随机矩阵M的特征值的概率密度P(λ)为:
(2)
(3)
(4)
其中:λmax和λmin分别是M的最大和最小特征值。RMT指出,通过相关矩阵C与随机矩阵M的性质,把C分为两个部分:一部分是符合随机矩阵的部分(随机噪声),一部分是差异部分(真实信息),从而对相关矩阵进行改进,去除相关矩阵中的噪声。
2 特征选择
2.1 算法描述
在特征选择中,相关性度量的方法有很多,如互信息(Mutual Information, MI)、对称不确定性(Symmetric Uncertainty, SU)、信息增益(Information Gain, IG),本文采用互信息作为度量标准。设有原始N×L数据矩阵D,其中特征集合F={f1,f2, …,ft},类集合S={s1,s2,…,sk},通过式(5)构建互信息矩阵M,当k较小时,无法很好地满足随机矩阵的特征,因此需要对M进行增广,复制m次, 即M=[M,m(M)],为了保持初始的行列比,这里m=(L-1)2/(N*k)-1。
(5)
为了保证一般性,对矩阵M按式(6)、(7)进行规范化、中心化再标准化,得到矩阵Md。接着根据式(8)计算得到t×t的特征相关矩阵C。然后对C按式(9)进行奇异值分解。
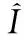
(6)
(7)
C=MdMdT
(8)
C=UΛV
(9)
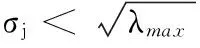
Cnew=UΛnewV
(10)
然后再对Cnew进行奇异值分解得到Unew和Vnew,Cnew中的每个元素Kij表示任意两个特征对初始类的相关程度,Vnew中的每个元素Eij是每个特征对新类的相关程度。接下来对去噪后的相关矩阵进行特征选择,特征选择的目标是去除与类不相关的特征和相互冗余的特征。经过去噪的结果可知,共保留了j-1个奇异值,因此在这里共选择j-1个特征,因此可以根据式(11)计算每一个特征的重要度,其中F(i)表示第i个特征的重要度,得到集合F={f1,f2, …,fi},接着对F(i)进行降序排序,选择前j-1个重要度最大的特征,从而完成特征选择。
(11)
基于RMT的特征选择方法的步骤描述如算法1所示。
算法1 基于RMT的特征选择方法。
输入 数据D;
输出 选择出的n个特征。
1)根据式(5)计算互信息矩阵M;
2)根据式(6)、(7)将M进行规范化;
3)生成和M形式一样的随机矩阵E;
4)根据式(8)计算M和E特征相关矩阵;
5)将M进行奇异值分解,将符合随机矩阵预测的奇异值置为0,同时获取特征选择的数量n;
6)根据式(10)还原相关矩阵;
7)对新的相关矩阵进行奇异值分解,获取分解矩阵V;
8)根据式(11)计算特征重要度并降序排序,选择前n个特征值。
2.2 特征选择优化
通过算法1,选出n个特征,现在可以通过随机矩阵进行进一步优化。通过将每一个特征设为随机变量,计算随机特征矩阵奇异值向量与原始特征矩阵奇异值向量的相关系数,相关系数越大则说明该特征与随机变量相关程度越高,因此保留相关系数较小的特征。具体做法为:假设现在有特征集合F={f1,f2, …,fn},k个类,首先进行原始特征矩阵M的奇异值计算,先按式(5)计算得到互信息矩阵D,接着对D按式(6)~(9)进行规范化、标准化、计算相关矩阵、奇异值分解,得到M的n个奇异值组成的奇异值向量e,用εk表示其中的每一个元素;然后进行随机特征矩阵的奇异值向量计算,依次将每一个特征设为随机变量,得到n个随机矩阵(M1,M2,…,Mn)。和计算原始特征矩阵的奇异值向量类似,计算出每一个随机矩阵Mi(1≤i≤n)的奇异值向量ei,用εik表示其中的每一个元素。对于每一个奇异值向量ei,通过式(12)计算其与原始特征奇异值向量e的差di,对di取整,对di≠0的特征fi进行保留,完成特征选择优化。
(12)
特征选择优化方法的步骤描述如算法2所示。
算法2 特征选择优化方法。
输入 数据M;
输出 选择出的t个特征。
1)通过式(5)~(9)计算出M的奇异值向量e;
2)依次将M中的每一个特征用随机变量代替,得到随机特征矩阵Mi;
3)根据步骤1)计算Mi的奇异值向量ei;
4)通过式(12)计算e与ei的差di;
5)对di取整,将di≠0的特征保留。
3 实验结果与分析
3.1 实验数据集
为了说明本文提出的特征选择方法的有效性,通过分类实验来验证。选取UCI机器学习知识库上8个数据集和2个人脸数据集FERET、 Yale进行实验。表1是对数据集的描述,数据集中的实例数从101到5 744,特征数从17到1 024,其中前7个数据集相对属于高维数据集。
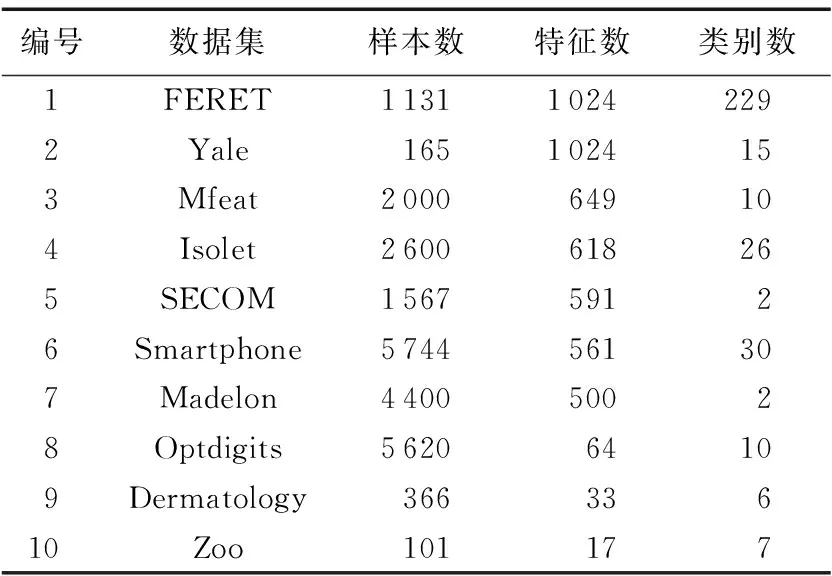
表1 实验中用到的数据集Tab. 1 Datasets used in the experiments
3.2 RMFS与RMFS-O在高维数据中的表现
实验在64位Windows 7系统、8 GB内存、主频2.93 GHz的Core i7- 870的PC上运行,采用python3.6、scikit-learn工具包。使用经典的MDL(Multi-Interval Discretization for classification Learning)[14]方法对数据进行离散化,采用1-NN、CART(Classification and Regression Tree)、Naive Bayse三种分类器,选择FCBF(Fast Correlation-Based Filter solution)[15]、mRMR(max-Relevance and Min-Redundancy)[16]、IG(Information Gain)[17]、CFS(Correlation-based Feature Selection)[18]、sSR(supervised Simple Ranking)[12]这5种选择方法与本文所提出的特征选择方法RMFS、RMFS-O进行对比。在给定的数据集上进行10折交叉验证,各个算法在1-NN、CART、Naive Bayes三种分类器上的准确率分别如表2~4所示,其相应的选择特征数如表5所示。表中,W/T/L表示在10个数据集上,本文所提的两个方法的综合性能高于/持平/弱于该特征选择方法的个数。同时在每一个数据集上较高的准确率以粗体表示。
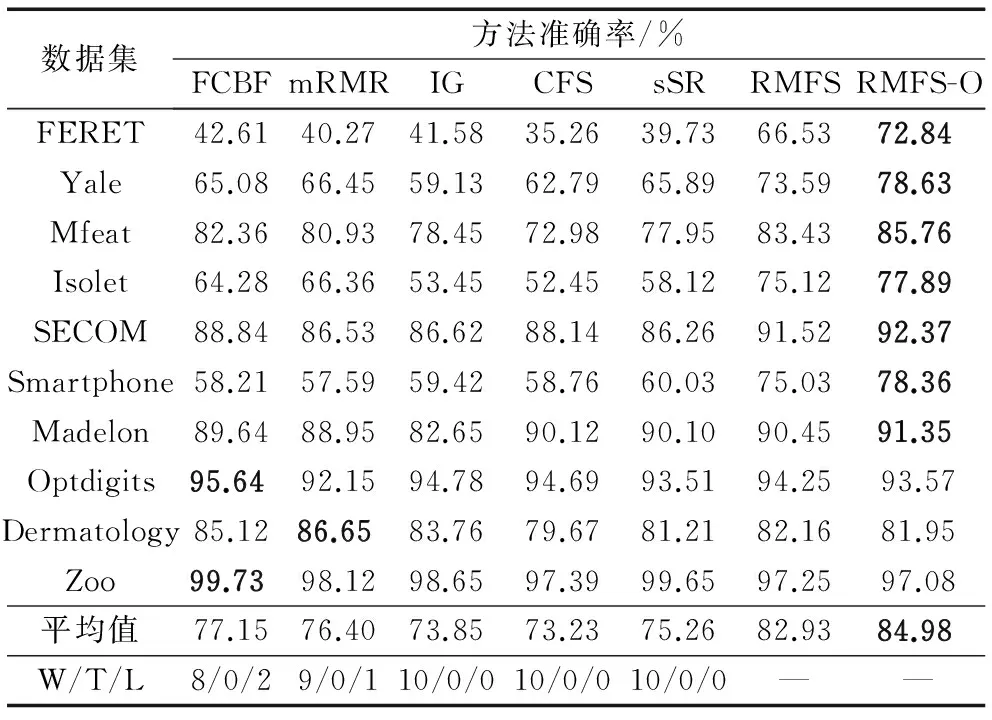
表2 1-NN分类器上的准确率Tab. 2 Classification accuracy with 1-NN classifier
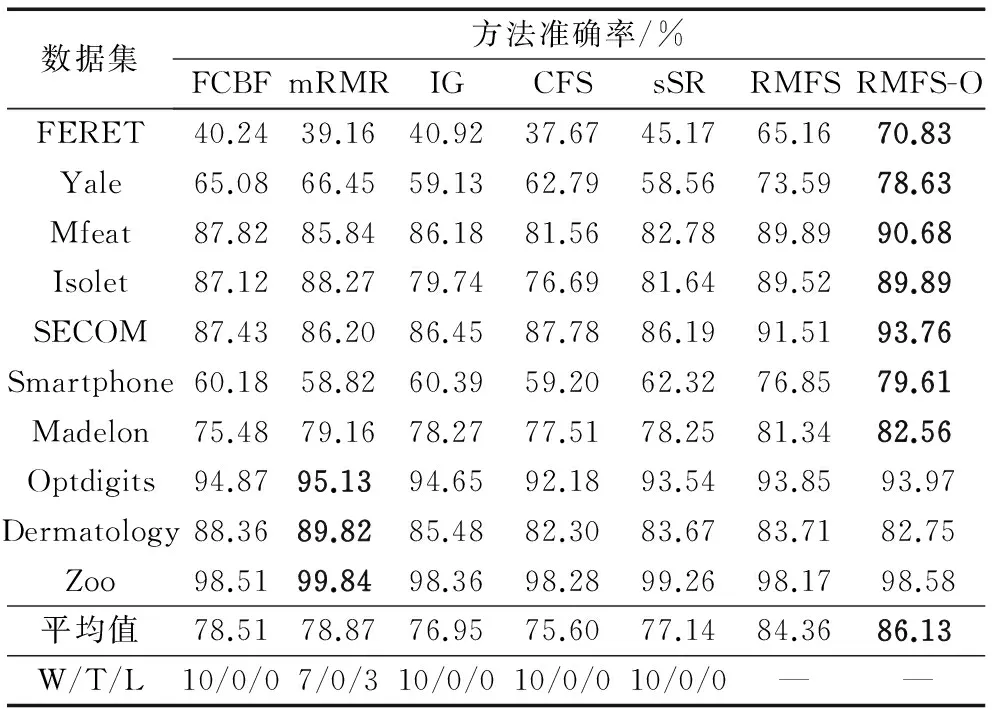
表3 CART分类器上的准确率Tab. 3 Classification accuracy with CART classifier
由表2~4可以看出,本文所提的特征选择方法在三个分类器上整体胜率是66.67%,在平均准确率上的胜率是100%。
由图1可知,在前7个高维数据集上,本文提出的RMFS和RMFS-O在平均准确率上相比FCBF、mRMR、IG、CFS、sSR分别提高为:12.30%,16.33%;13.77%,17.86%;19.90%,24.22%;19.70%,24.00%;15.49%,11.92%。
由图2可知,在特征选择的数量上,本文提出的方法也明显优于对比方法,RMFS和RMFS-O相比对比方法分别提高为:60.99%,70.00%;61.55%,70.44%;60.89%,69.93%;57.12%,67.03%;48.83%,58.41%。因此,本文方法既减少了数据规模,又保证了分类的正确率。
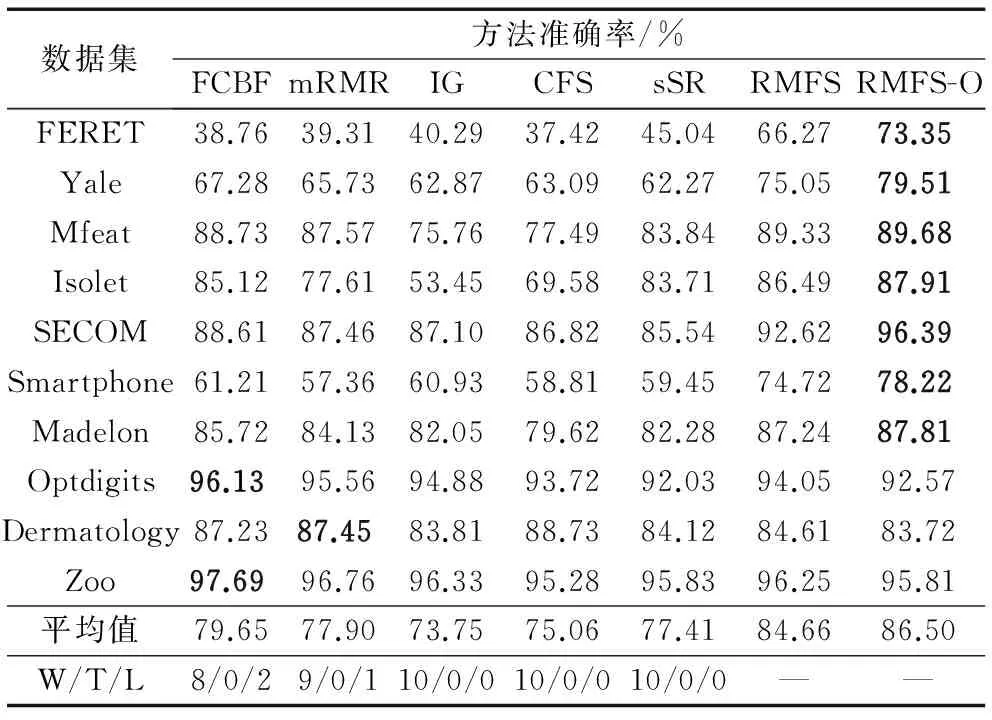
表4 Naive Bayes分类器上的准确率Tab. 4 Classification accuracy with Naive Bayse classifier
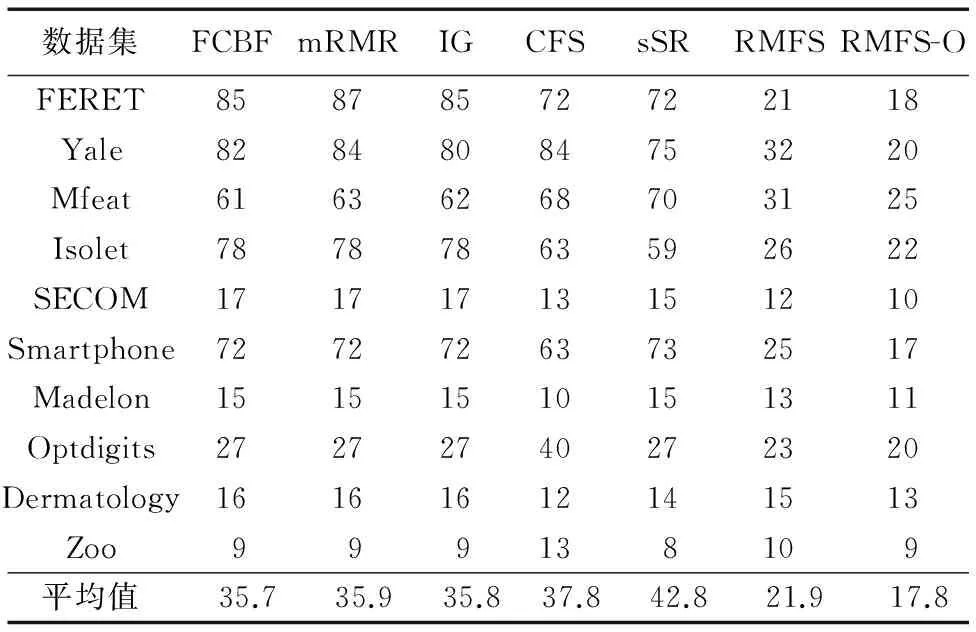
表5 不同方法的选择特征数Tab. 5 Selection feature number of different methods

图1 前七个数据集相对准确率Fig. 1 Relative accuracy of the first seven datasets
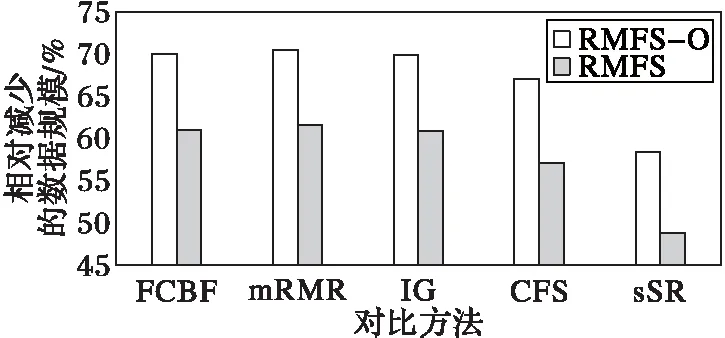
图2 相对减少的数据规模Fig. 2 Relative reduction of data size
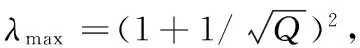
然而由图4可知,在后3个相对低维数据集上,RMFS和RMFS-O并没有取得很好的效果,在平均准确率上相比对比方法分别降低为:2.76%,2.25%;2.55%,2.04%;1.29%,0.77%;0.27%,-0.25%;0.52%,-0.18%。这是因为数据维数较低,不能很好地满足RMT所要求的大于数百维。
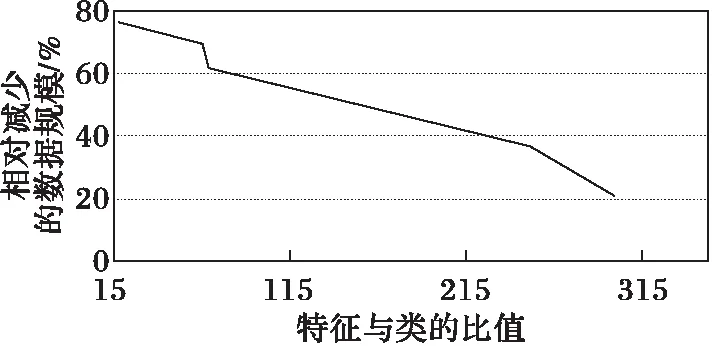
图3 前七个数据集特征与类的比对特征选择的影响Fig. 3 Influence of ratio of feature to class on feature selection of the first seven datasets
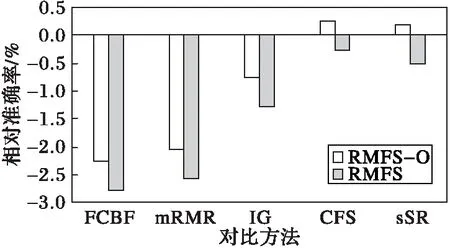
图4 后三个数据集相对准确率Fig. 4 Relative accuracy of the last three datasets
4 结语
本文提出一种基于RMT的特征选择方法,考虑到高维相关矩阵中会存在大量噪声,其通过随机矩阵来预测相关矩阵中噪声奇异值并进行去除,同时直接得到特征选择的数量,通过特征与类的相关性和特征之间的冗余性完成特征选择。本文又提出一种特征选择优化方法,通过依次将每一个特征设为随机变量从而进一步进行缩小训练矩阵规模。分类实验结果表明,所提方法能够显著改善高维相关矩阵,快速定位特征选择的数量,提高分类精度。本文方法需要的数据维度较高(一般大于数百维),在几十维以下的低维数据上表现不佳,这将是接下来的研究方向。
References)
[1] 严英杰,盛戈皞,王辉,等.基于高维随机矩阵大数据分析模型的输变电设备关键性能评估方法[J].中国电机工程学报,2016,36(2):435-445.(YAN Y J, SHENG G H, WANG H, et al. The key state assessment method of power transmission equipment using big data analyzing model based on large dimensional random matrix [J]. Proceedings of the CSEE, 2016, 36(2): 435-445.)
[2] SINGH D A A G, BALAMURUGAN S A A, LEAVLINE E J. A novel feature selection method for image classification [J]. Optoelectronics and Advanced Materials — Rapid Communications, 2015, 9(11/12): 1362-1368.
[3] JIN X, WANG J T, ZENG P. End-to-end delay analysis for mixed-criticality wireless HART networks [J]. IEEE/CAA Journal of Automatica Sinica, 2015, 2(3): 282-289.
[4] BENNASAR M, HICKS Y, SETCHI R. Feature selection using joint mutual information maximisation [J]. Expert Systems with Applications, 2015, 42(22): 8520-8532.
[5] ZHAO Z, MORSTATTER F, SHARMA S, et al. Advancing feature selection research [EB/OL].[2017- 04- 10]. http://eprints.kku.edu.sa/65/1/ZhaoEtAl.pdf.
[6] JOHANSSON K. Shape fluctuations and random matrices [J]. Communications in Mathematical Physics, 2000, 209(2): 437-476.
[7] 韩华,吴翎燕,宋宁宁.基于随机矩阵的金融网络模型[J].物理学报,2014,63(13):431-440.(HAN H, WU L Y, SONG N N. Financial networks model based on random matrix [J]. Acta Physica Sinica, 2014, 63(13): 431-440.)
[8] PLEROU V, GOPIKRISHNAN P, ROSENOW B, et al. Random matrix approach to cross correlations in financial data [J]. Physical Review E, Statistical, Nonlinear, and Soft Matter Physics, 2002, 65(6 Pt 2): 066126.
[9] 徐心怡,贺兴,艾芊,等.基于随机矩阵理论的配电网运行状态相关性分析方法[J].电网技术,2016,40(3):781-790.(XU X Y, HE X, AI Q, et al. A correlation analysis method for operation status of distribution network based on random matrix theory [J]. Power System Technology, 2016, 40(3): 781-790.)
[10] FREEDMAN G, FATTAL R. Image and video upscaling from local self-examples [J]. ACM Transactions on Graphics, 2011, 30(2): Article No. 12.
[11] VARSHAVSKY R, GOTTLIEB A, LINIAL M, et al. Novel unsupervised feature filtering of biological data [J]. Bioinformatics, 2006, 22(14): e507-e513.
[12] BANERJEE M, PAL N R. Feature selection with SVD entropy: some modification and extension [J]. Information Sciences, 2014, 264: 118-134.
[13] QIU R C, ANTONIK P. Smart Grid and Big Data: Theory and Practice [M]. Hoboken, NJ: Wiley Publishing, 2015: 48-51.
[14] FAYYAD U M, IRANI K B. Multi-interval discretization of continuous-valued attributes for classification learning [C]// Proceedings of the 1993 13th International Joint Conference on Artificial Intelligence. San Francisco, CA: Morgan Kaufmann, 1993: 1022-1027.
[15] YU L, LIU H. Feature selection for high-dimensional data: a fast correlation-based filter solution [C]// ICML’03: Proceedings of the Twentieth International Conference on Machine Learning. Menlo Park: AAAI, 2003: 856-863.
[16] PENG H C, LONG F H, DING C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(8): 1226-1238.
[17] YANG Y M, PEDERSEN J O. A comparative study on feature selection in text categorization [C]// Proceedings of the 14th International Conference on Machine Learning. San Francisco, CA: Morgan Kaufmann, 1997, 97: 412-420.
[18] HALL M A. Correlation-based feature selection for discrete and numeric class machine learning [C]// Proceedings of the 17th International Conference on Machine Learning. San Francisco, CA: Morgan Kaufmann, 2000: 359-366.
This work is partially supported by the National Natural Science Foundation of China (61472169, 61472072, 61528202, 61501105), the Special Prophase Project on the National Basic Research Program (973) of China (2014CB360509), the Science Research Normal Fund of Liaoning Province Education Department (L2015204).
WANGYan, born in 1978, Ph. D., associate professor. Her research interests include database, cognitive data processing, Internet of things.
YANGJun, born in 1992, M. S. candidate. His research interests include machine learning, data minning.
SUNLingfeng, born in 1993, M. S. candidate. His research interests include big data processing.
LIYunuo, born in 1978, M. S. His research interests include big data processing, smart city.
SONGBaoyan, born in 1965, Ph. D., professor. Her research interests include database theory, big data processing.
Featureselectionmethodofhigh-dimensionaldatabasedonrandommatrixtheory
WANG Yan1, YANG Jun1, SUN Lingfeng1, LI Yunuo2, SONG Baoyan1*
(1.CollegeofInformation,LiaoningUniversity,ShenyangLiaoning110036,China;2.SmartCityDevelopmentDepartment,BringSpringScience&TechnologyLimitedCompany,ShenyangLiaoning110027,China)
The traditional feature selection methods always remove redundant features by using correlation measures, and it is not considered that there is a large amount of noise in a high-dimensional correlation matrix, which seriously affects the feature selection result. In order to solve the problem, a feature selection method based on Random Matrix Theory (RMT) was proposed. Firstly, the singular values of a correlation matrix which met the random matrix prediction were removed, thereby the denoised correlation matrix and the number of selected features were obtained. Then, the singular value decomposition was performed on the denoised correlation matrix, and the correlation between feature and class was obtained by decomposed matrix. Finally, the feature selection was accomplished according to the correlation between feature and class and the redundancy between features. In addition, a feature selection optimization method was proposed, which furtherly optimize the result by comparing the difference between singular value vector and original singular value vector and setting each feature as a random variable in turn. The classification experimental results show that the proposed method can effectively improve the classification accuracy and reduce the training data scale.
random matrix; feature selection; denoising; singular value; correlation matrix
2017- 05- 04;
2017- 06- 26。
国家自然科学基金资助项目(61472169,61472072,61528202,61501105);国家973计划前期研究专项(2014CB360509);辽宁省教育厅科学研究一般项目(L2015204)。
王妍(1978—),女,辽宁抚顺人,副教授,博士,CCF会员,主要研究方向:数据库、感知数据处理、物联网; 杨钧(1992—),男,安徽合肥人,硕士研究生,主要研究方向:机器学习、数据挖掘; 孙凌峰(1993—),男,山东潍坊人,硕士研究生,主要研究方向:大数据处理;李玉诺(1978—),男,辽宁庄河人,硕士,主要研究方向:大数据处理、智慧城市; 宋宝燕(1965—),女,辽宁铁岭人,教授,博士,CCF会员,主要研究方向:数据库理论、大数据处理。
1001- 9081(2017)12- 3467- 05
10.11772/j.issn.1001- 9081.2017.12.3467
(*通信作者电子邮箱bysong@lnu.edu.cn)
TP391.1
A
