多粒度粗糙集粒度约简的高效算法
2018-01-08胡善忠何明慧
胡善忠,徐 怡,2,何明慧,王 冉
(1.安徽大学 计算机科学与技术学院,合肥 230601; 2.计算智能与信号处理教育部重点实验室(安徽大学),合肥 230039)
多粒度粗糙集粒度约简的高效算法
胡善忠1,徐 怡1,2*,何明慧1,王 冉1
(1.安徽大学 计算机科学与技术学院,合肥 230601; 2.计算智能与信号处理教育部重点实验室(安徽大学),合肥 230039)
针对已有多粒度粗糙集粒度约简算法效率较低的问题,提出一种多粒度粗糙集粒度约简的高效算法(EAGRMRS)。首先,以决策信息系统为对象,定义决策类下近似布尔矩阵,该矩阵能够将粒度约简过程中过多且有重复的集合运算转换为布尔运算,基于该矩阵给出计算决策类下近似算法和计算粒度重要度算法。然后,针对计算粒度重要度时存在冗余计算的问题,提出粒度动态增加时快速计算粒度重要度的算法,并在此基础上,提出EAGRMRS,该算法的时间复杂度为O(|A|·|U|2+|A|2·|U|),其中|A|表示粒度集合大小,|U|表示决策信息系统中实例数。在UCI数据集上的实验结果验证了所提算法的有效性和高效性,并且随着数据集的增大,EAGRMRS相较于多粒度粗糙集粒度约简的启发式算法(HAGSS)效率优势更加明显。
多粒度粗糙集;布尔矩阵;信息系统; 重要度;粒度约简
0 引言
粗糙集理论是波兰数学家Pawlak[1]提出的能有效处理不精确、不一致和不完备数据的方法,目前,粗糙集理论已广泛用于机器学习、数据挖掘、特征选择等领域[2-4]。从粒计算的角度看,经典的粗糙集模型是基于单粒度和单层次的,无法从多粒度、多层次的角度分析和处理问题。为了使粗糙集能够更好地解决实际问题,Qian等[5]提出了多粒度粗糙集,在多粒度粗糙集中,目标决策可以通过多个粒度空间中的信息粒进行刻画,因此可以从多个角度、多个层次出发分析问题并获得更加满意、合理的求解。此后,许多学者提出了基于多粒度粗糙集的扩展粗糙集模型,例如,多粒度优势关系粗糙集、多粒度模糊关系粗糙集、邻域多粒度粗糙集、多粒度决策理论粗糙集、可变多粒度粗糙集等[6-10]。这些多粒度粗糙集的扩展模型对粗糙集理论具有重要的推广作用。
在多粒度粗糙集中,粒度约简是一个重要问题,通过粒度约简能够在保持信息系统决策能力不变的前提下,选择一个无冗余的粒度空间子集。为了对多粒度粗糙集进行粒度约简,Qian等[5]首先提出了启发式的粒度约简算法,该算法首先基于整个粒度空间对所有粒度按照粒度重要度大小进行排序,然后按序将粒度加入约简集直到获得一个粒度约简结果,但是该算法并没有给出每步粒度选取时的启发式函数,且在算法的最后并没有进一步对约简集进行冗余粒度的反向消除,获得的约简结果可能存在冗余粒度。张明等[10]提出了可变多粒度粗糙集粒度约简算法,该算法在获得一个粒度约简集之后也没有进一步对约简集进行冗余粒度的反向消除,所以约简结果也可能存在冗余粒度。桑妍丽等[11]发展了一种适合悲观多粒度粗糙集的粒度约简算法,虽然该算法效率较高,但并不适用于乐观多粒度粗糙集。此后,Yang等[12]提出了一种多粒度粗糙集粒度约简的启发式算法,该算法能获得约简率较高的约简结果,但约简效率并不高。然而,在实际应用中,面对的往往是数据量很大的决策信息系统,此时,如何提高多粒度粗糙集粒度约简的效率就成为了一个关键问题。
为了提高多粒度粗糙集粒度约简的效率,本文定义了决策类下近似布尔矩阵,该矩阵能简化多粒度粗糙集粒度约简过程中决策类下近似的计算,基于该矩阵给出了计算决策类下近似算法和计算粒度重要度算法,并提出了粒度动态增加时快速计算粒度重要度算法来优化粒度约简过程中粒度重要度的计算。在此基础上,本文提出了一种多粒度粗糙集粒度约简的高效算法(Effective Algorithm for Granulation Reduction of Multi-granulation Rough Set, EAGRMRS),最后通过实验验证了本文所提算法的有效性和高效性。
1 相关概念
在本章,介绍本文用到的相关知识。

定义2[5]设信息系统IS=(U,AT,V,f),B⊆AT,对于X⊆U,X的下、上近似集合和边界域定义为:
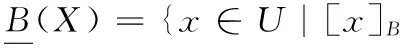
(1)

(2)
(3)
其中[x]B是x在B上的等价类。

为了能够从多粒度、多层次的角度分析和处理问题,Qian等[5]提出了多粒度粗糙集。本文中用上标O(Optimistic)表示乐观的语义,用上标P(Pessimistic)表示悲观的语义,以此来区分乐观多粒度粗糙集和悲观多粒度粗糙集。
定义3[5]设信息系统IS=(U,AT,V,f),A={A1,A2,…,Am}是AT的m个属性子集族。对于∀X⊆U,X关于A的乐观多粒度下近似和乐观多粒度上近似分别定义如下:

[x]A2⊆X∨…∨[x]Am⊆X,x∈U}
(4)
(5)
定义4[5]设信息系统IS=(U,AT,V,f),A={A1,A2,…,Am}是AT的m个属性子集族。对于∀X⊆U,X关于A的悲观多粒度下近似和悲观多粒度上近似分别定义如下:

[x]Am⊆X,x∈U}
(6)
(7)
定义5[13]设决策信息系统DIS=(U,C∪D,V,f),A={A1,A2,…,Am}是C的m个属性子集族,决策属性D导出的划分为U/D={X1,X2,…,Xr}。用粒度集A表示U/D的近似质量(也称为依赖度),定义为:
(8)
2 多粒度粗糙集的粒度约简
目前,为了满足不同的需要,已经有许多不同的约简定义[14-16]被提出,一个常用的定义是保持决策信息系统的正域不变。
定义6[11]设决策信息系统DIS=(U,C∪D,V,f),A={A1,A2,…,Am}是C的m个属性子集族,决策属性D导出的划分为U/D={X1,X2,…,Xr},则基于A的乐观下近似分布函数定义如下:
(9)
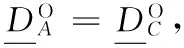

定义8[11]设决策信息系统DIS=(U,C∪D,V,f),A={A1,A2,…,Am}是C的m个属性子集族,给定粒度集A′,∅⊂A′⊆A,X∈U/D。
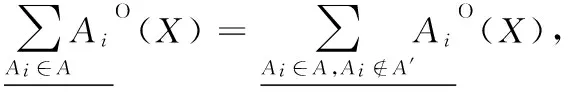
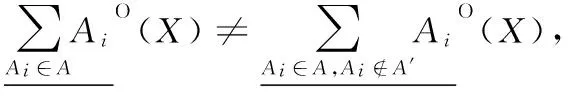
定理1[11]设决策信息系统DIS=(U,C∪D,V,f),A={A1,A2,…,Am}是C的m个属性子集族,A′⊆A,则:
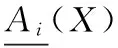
根据定义3,该定理显然成立。由该定理可知,在乐观多粒度粗糙集中,随着粒度空间的增大,下近似中对象的个数增加。在悲观多粒度粗糙集中,也可以得出类似的结论,随着粒度空间的增大,下近似中对象的个数减少。因此,可以利用下近似中对象个数的变化来衡量粒度的重要性。
定义9[12]设决策信息系统DIS=(U,C∪D,V,f),A={A1,A2,…,Am}是C的m个属性子集族。
1)A′⊆A,∀Ai∈A′,定义在粒度集A′上,Ai关于D的粒度重要度为:
Sigin(Ai,A′,D)=abs(γ(A′,D)-γ(A′-Ai,D))
(10)
2)A′⊆A,∀Ai∈A-A′,定义在粒度集A′上,Ai关于D的粒度重要度为:
Sigout(Ai,A′,D)=abs(γ(Ai∪A′,D)-γ(A′,D))
(11)
其中:abs(N)表示N的绝对值。在粒度约简的过程中,一般以粒度重要度为启发来设计粒度约简算法。
3 多粒度粗糙集粒度约简的高效算法
3.1 决策类下近似布尔矩阵
粒度约简中计算粒度重要度时要多次求不同粒度集合下决策类的下近似,为了将过多且有重复的集合运算转换为布尔运算来提高效率,本文定义了决策类下近似布尔矩阵并给出了根据决策信息系统求决策类下近似布尔矩阵的算法。
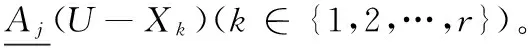
该定理显然成立,对于∀x∈U,x仅可能属于决策类Xk(x∈Xk)的下近似,也就是说x最多属于一个决策类的下近似。
定义10 设决策信息系统DIS=(U,C∪D,V,f),U={x1,x2,…,xn},A={A1,A2,…,Am}是C的m个属性子集族,决策属性D导出的划分为U/D={X1,X2,…,Xr},定义决策类下近似布尔矩阵为M=(M_m(i,j)),其中M_m(i,j)表示第i行第j列的元素(1≤i≤n,1≤j≤m),元素定义如下:
(12)
其中xi∈Xk(k∈{1,2,…,r})。
决策类下近似布尔矩阵包含|U|行、|A|列,|U|表示决策信息系统中的实例数,|A|表示粒度集合大小。
显然,决策信息系统的决策类下近似布尔矩阵包含了所有对象在每个粒度上是否属于对应决策类下近似的信息。这样,求某个决策类在某个粒度集合上的下近似时我们只需要进行布尔矩阵元素的0、1判断,不需要再进行集合运算。因此,该矩阵可将粒度约简中的集合运算转化为布尔运算。以完备决策信息系统为对象,本文给出计算决策类下近似布尔矩阵的算法。
算法1 计算决策类下近似布尔矩阵算法。
输入 决策信息系统DIS=(U,C∪D,V,f),粒度空间A={A1,A2,…,Am};
输出 下近似布尔矩阵M。
1)
设置M←∅,i←1,j←1;
2)
计算U/D={X1,X2,…,Xr};
3)
Fori=1 to |U|
Forj=1 tom
If [xi]Aj⊆Xk
M_m(i,j)=1;
Else
M_m(i,j)=0;
Endif
Endfor
Endfor
4)
输出M。
该算法的复杂度为O(|A|·|U|2),建立了上述决策类下近似布尔矩阵以后,粒度约简算法中计算粒度重要度时,可以基于该矩阵快速计算决策类在任意粒度上的下近似,这个过程只需要简单地判断矩阵中元素M_m(i,j)的取值。若M_m(i,j)=0,则对象xi在粒度Aj上不属于x所在决策类Xk的下近似;若M_m(i,j)=1,则对象xi在粒度Aj上属于x所在决策类Xk的下近似,避免了过多并且耗时的集合运算。
下面以文献[17]中的决策信息系统为例,说明构建决策类下近似布尔矩阵的过程。
例1 给定一个决策信息系统DIS=(U,C∪D,V,f),如表1所示,其中:U={x1,x2,x3,x4,x5,x6}为对象集,A={{a1},{a2},{a3},{a4},{a5},{a6}}为粒度空间。

表1 一个完备决策信息系统Tab. 1 A complete decision information system
首先,根据决策属性导出划分为U/D={{x1,x2,x3},{x4,x5,x6}},令X1={x1,x2,x3},X2={x4,x5,x6}。
然后,对于每个对象xi计算其在每个粒度{aj}上的等价类[x]{aj}并判断是否包含于对应的决策类,若是,设置矩阵M对应的位置M_m(i,j)=1,否则设置M_m(i,j)=0。对于对象x1,[x1]{a1}={x1,x3,x5,x6}⊄X1,设置M_m(1,1)=0;[x1]{a2}={x1,x5}⊄X1,设置M_m(1,2)=0;[x1]{a3}={x1,x3,x4,x5}⊄X1,设置M_m(1,3)=0;[x1]{a4}={x1,x4,x5,x6}⊄X1,设置M_m(1,4)=0;[x1]{a5}={x1,x4,x5,x6}⊄X1,设置M_m(1,5)=0;[x1]{a6}={x1,x2,x3}⊂X1,设置M_m(1,6)=1。类似,可以计算出x2,x3,x4,x5,x6在粒度{a1},{a2},{a3},{a4},{a5},{a6}上的等价类并判断是否包含于对应的决策类,最终,可以建立如下决策信息系统的决策类下近似布尔矩阵:
接下来以乐观多粒度粗糙集为例,给出基于决策类下近似布尔矩阵计算决策类下近似算法和基于决策类下近似布尔矩阵计算粒度重要度算法。
算法2 基于决策类下近似布尔矩阵计算决策类下近似算法。
输入 决策信息系统DIS=(U,C∪D,V,f),粒度空间A={A1,A2,…,Am},Xk∈U/D,决策类下近似布尔矩阵M=(M_m(i,j));
输出Xk的下近似集合L。
1)
设置L←∅,j←1;
2)
∀xi∈Xk,
Forj=1 tom
IfM_m(i,j)=1
L←L∪{xi},break;
Endif
Endfor
3)
输出L。
然后利用算法2计算决策类下近似,根据定义9易得下面乐观多粒度粗糙集基于决策类下近似布尔矩阵计算粒度重要度算法。
算法3 基于决策类下近似布尔矩阵计算粒度重要度算法。
输入 决策信息系统DIS=(U,C∪D,V,f), 粒度空间A={A1,A2,…,Am},决策属性D导出的划分U/D={X1,X2,…,Xr},决策类下近似布尔矩阵M=(M_m(i,j)),A′⊆A,∀Ai∈A;
输出 在粒度集A′上,Ai关于D的粒度重要度SigO。
1)
设置D′←∅,D″←∅,k←1;
2)
Fork=1 tor

Endfor
3)
IfAi⊆A′
A″=A′-Ai;
Else
A″=A′∪Ai;
Fork=1 tor

Endfor
4)
基于D′和D″,根据定义9计算SigO;
5)
输出SigO。
3.2 快速计算粒度重要度算法
文献[18]中对粒度动态变化时如何快速计算某个对象集的下、上近似进行了研究,提出了一个在粒度动态变化时快速计算下、上近似的算法。而在粒度约简算法中,选取当前重要度最大的粒度加入约简集,就涉及粒度动态增加时计算决策类的下近似,基于决策类下近似布尔矩阵,参考文献[18]可以设计算法来优化计算粒度重要度过程中决策类下近似的计算。
定理3[18]设决策信息系统DIS=(U,C∪D,V,f),A={A1,A2,…,Am}是C的m个属性子集族,X⊆U,有:

(13)

(14)

以乐观多粒度粗糙集为例,基于决策类下近似布尔矩阵,根据定理3给出粒度动态增加时快速计算决策类下近似算法和粒度动态增加时快速计算粒度重要度算法。
算法4 粒度动态增加时快速计算决策类下近似算法。


1)
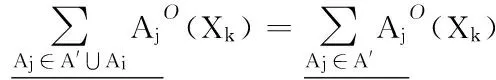
2)

IfM_m(t,i)=1

Endif
3)

基于算法4,得出如下粒度动态增加时快速计算粒度重要度的算法。
算法5 粒度动态增加时快速计算粒度重要度算法。
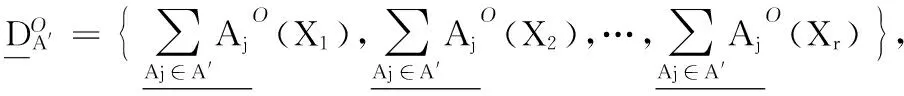
输出 在粒度集A′上,Ai关于D的粒度重要度SigO。
1)

2)
A″=A′∪Ai;
Fork=1 tor
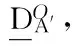

Endfor
3)
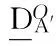
4)
输出SigO。
悲观多粒度粗糙集中快速计算粒度重要度算法类似,在此不再赘述。
3.3 EAGRMRS
粒度约简算法的基本过程如下:首先获得一个原始粒度空间下不可除去的粒度集合(粒度约简核),然后以这个粒度集为起点,以粒度重要度为启发,每次选择当前粒度空间下最为重要的粒度加入到约简粒度集中,直到其下近似分布与原始粒度空间下近似分布一致。
算法6 多粒度粗糙集粒度约简的高效算法(EAGRMRS)。
输入 决策信息系统DIS=(U,C∪D,V,f),粒度空间A={A1,A2,…,Am},决策属性D导出的划分U/D={X1,X2,…,Xr};
输出 粒度约简集REDO。
1)
设置REDO←∅;
2)
利用算法1建立决策类下近似布尔矩阵M;
3)
对于∀Ai∈A,利用算法3计算Sigin(Ai,A,D),
IfSigin(Ai,A,D)≠0
REDO=REDO∪Ai;
Endif
令COREO=REDO;
4)

Do

IfSigout(Ak,REDO,D)=max{Sigout(Ai,REDO,D):Ai∈A-REDO}
REDO=REDO∪Ak;
Endif
Untilγ(REDO,D)=γ(A,D);
5)
∀Ai∈REDO-COREO
Ifγ(REDO-Ai,D)=γ(A,D)
REDO=REDO-Ai;
Endif
6)
输出REDO。
算法复杂度分析:第2)步时间复杂度为O(|A|·|U|2),第3)步时间复杂度为O(|A|2·|U|),第4)步时间复杂度为O(|A|2·|U|),所以算法6的时间复杂度为O(|A|·|U|2+|A|2·|U|)。悲观多粒度粗糙集粒度约简的高效算法与乐观多粒度粗糙集粒度约简的高效算法类似。
4 实验结果与分析
文献[12]提出了一种多粒度粗糙集粒度约简的启发式算法(Heuristic Approach to Granular Structure Selection, HAGSS),其中计算决策类下近似可以参考文献[5]。将本文所提算法EAGRMRS与算法HAGSS进行比较,比较两种算法的运行效率以及运行效率与数据集包含的数据量的关系。
选用UCI机器学习库中的4个数据集进行测试,数据集具体信息见表2,其中:数据集Zoo、Chess是完备的,数据集Audiology、Mushroom有缺失的属性值,是不完备的。对于不完备的数据集等价关系将不再适用,本文中用容差关系来处理不完备的数据集[14]。

表2 实验中使用的UCI数据集Tab. 2 UCI datasets used in the experiment
多粒度粗糙集中一个粒度可能包含多个属性,为了模拟多粒度的情况,对于表2中的数据集,从第一个属性开始,分别以每1、2、3、4、5个属性构成一个粒度,若数据集的条件属性个数不能被1、2、3、4、5整除,最后余下的属性构成一个粒度,实验结果如图1所示。

图1 不同数据集上不同算法粒度约简的运行时间Fig. 1 Running time of granulation reduction for different algorithms on different datasets
粒度大小就是构成一个粒度的属性个数,对于同一个数据集,因为条件属性一定,所以当选取的粒度大小越大,所组成的粒度空间就越小。从图1中可以看出,在所有数据集上,算法EAGRMRS进行粒度约简的运行时间均少于算法HAGSS,且随着粒度大小变小,也就是粒度空间变大时,HAGSS运行效率下降较为明显,而算法EAGRMRS运行效率较为稳定。所以,本文所提算法在约简效率和稳定性方面都优于算法HAGSS。
接下来,为了比较算法EAGRMRS和算法HAGSS的约简效率与数据集包含的数据量的关系,取粒度大小为3时,四个数据集的约简时间如图2所示。
由表2可知,编号为1、2、3、4的数据集包含的数据量是递增的,由图2可知,随着数据集包含的数据量越大,算法HAGSS的运行时间增加得较快,而算法EAGRMRS的运行时间增加较慢,所以在对数据量较大的决策信息系统进行粒度约简时,本文所提算法效率优势将更加明显。
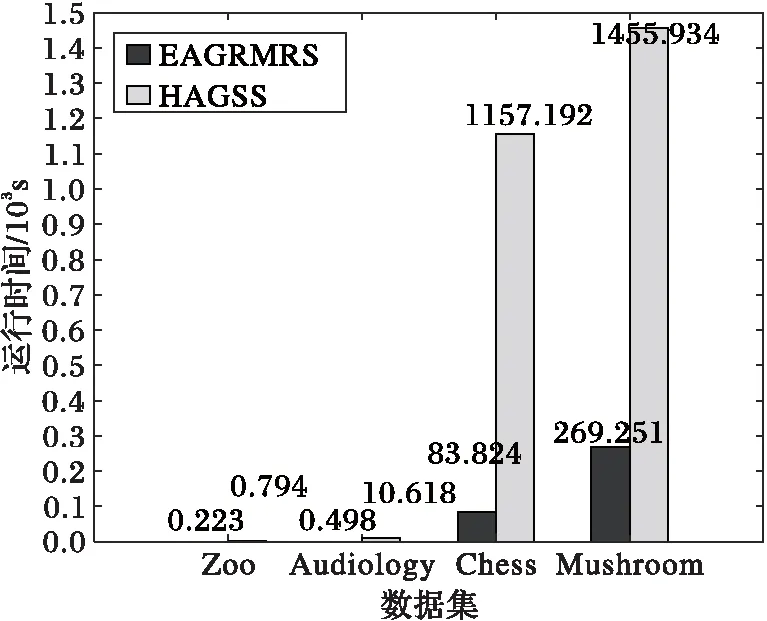
图2 不同算法在不同数据集上的运行时间Fig. 2 Running time of different algorithms on different datasets
5 结语
本文以决策信息系统为对象,定义了决策信息系统决策类下近似布尔矩阵,该矩阵能简化多粒度粗糙集粒度约简过程中决策类下近似的计算,基于该矩阵给出了计算决策类下近似算法和计算粒度重要度算法。此外,针对计算粒度重要度时存在冗余计算,基于决策类下近似布尔矩阵提出了粒度动态增加时快速计算粒度重要度算法,在此基础上,提出了一种多粒度粗糙集粒度约简的高效算法(EAGRMRS)。在UCI数据集上的实验结果验证了本文所提算法的有效性和高效性。粒度约简能够获得保持决策信息系统决策能力不变的粒度空间子集,如何在粒度约简之后对每个粒度中的属性进行进一步的约简,并对约简后的决策信息系统进行规则提取是接下来要研究的问题。
References)
[1] PAWLAK Z. Rough sets [J]. International Journal of Computer & Information Sciences, 1982, 11(5): 341-356.
[2] HU Q H, CHE X J, ZHANG L, et al. Rank entropy based decision trees for monotonic classification [J]. IEEE Transactions on Knowledge & Data Engineering, 2012, 24(11): 2052-2064.
[3] SRINIVASA K G, VENUGOPAL K R, PATNAIK L M. A soft computing approach for data mining based query processing using rough sets and genetic algorithms [J]. International Journal of Hybrid Intelligent Systems, 2008, 5(1): 1-17.
[4] 白鹤翔,王健,李德玉,等.基于粗糙集的非监督快速属性选择算法[J].计算机应用,2015,35(8):2355-2359.(BAI H X, WANG J, LI D Y, et al. Fast unsupervised feature selection algorithm based on rough set theory [J]. Journal of Computer Applications, 2015, 35(8): 2355-2359.)
[5] QIAN Y H, LIANG J Y, YAO Y Y, et al. MGRS: a multi-granulation rough set [J]. Information Sciences, 2010, 180(6): 949-970.
[6] XU W H, SUN W X, ZHANG X Y, et al. Multiple granulation rough set approach to ordered information systems [J]. International Journal of General Systems, 2012, 41(5): 475-501.
[7] YANG X B, SONG X N, DOU H L, et al. Multi-granulation rough set: from crisp to fuzzy case [J]. Annals of Fuzzy Mathematics and Informatics, 2011, 1(1): 55-70.
[8] LIN G P, QIAN Y H, LI J J. NMGRS: Neighborhood-based multigranulation rough sets [J]. International Journal of Approximate Reasoning, 2012, 53(7): 1080-1093.
[9] QIAN Y H , ZHANG H, SANG Y L, et al. Multigranulation decision-theoretic rough sets [J]. International Journal of Approximate Reasoning, 2014, 55(1): 225-237.
[10] 张明,唐振民,徐维艳,等.可变多粒度粗糙集模型[J].模式识别与人工智能,2012,25(4):709-720.(ZHANG M, TANG Z M, XU W Y, et al. Variable multigranulation rough set model [J]. Pattern Recognition and Artificial Intelligence, 2012, 25(4): 709-720.)
[11] 桑妍丽,钱宇华.一种悲观多粒度粗糙集中的粒度约简算法[J].模式识别与人工智能,2012,25(3):361-366.(SANG Y L, QIAN Y H. A granular space reduction approach to pessimistic multi-granulation rough sets [J]. Pattern Recognition and Artificial Intelligence, 2012, 25(3): 361-366.)
[12] YANG X B, QI Y S, SONG X N, et al. Test cost sensitive multigranulation rough set: model and minimal cost selection [J]. Information Sciences, 2013, 250(11):184-199.
[13] 张明,程科,杨习贝,等.基于加权粒度的多粒度粗糙集[J].控制与决策,2015,30(2):222-228.(ZHANG M, CHENG K, YANG X B, et al. Multigranulation rough set based on weighted granulations [J]. Control and Decision, 2015, 30(2): 222-228.)
[14] DAI J H, WANG W T, TIAN H W, et al. Attribute selection based on a new conditional entropy for incomplete decision systems [J]. Knowledge-Based Systems, 2013, 39(2): 207-213.
[15] MIAO D Q, GAO C, ZHANG N, et al. Diverse reduct subspaces based co-training for partially labeled data [J]. International Journal of Approximate Reasoning, 2011, 52(8): 1103-1117.
[16] QIAN J, MIAO D Q, ZHANG Z H, et al. Hybrid approaches to attribute reduction based on indiscernibility and discernibility relation [J]. International Journal of Approximate Reasoning, 2011, 52(2): 212-230.
[17] 鞠恒荣,周献中,杨佩,等.测试代价敏感的粗糙集方法[J].系统工程理论与实践,2017,37(1):228-240.(JU H R, ZHOU X Z, YANG P, et al. Test-cost-sensitive based rough set approach [J]. System Engineering — Theory and Practice, 2017, 37(1): 228-240.)
[18] YANG X B, QI Y, YU H L, et al. Updating multigranulation rough approximations with increasing of granular structures [J]. Knowledge-Based Systems, 2014, 64(1): 59-69.
This work is partially supported by the National Natural Science Foundation of China (61402005), the Natural Science Foundation of Anhui Province (1308085QF114), the Higher Education Natural Science Foundation of Anhui Province (KJ2013A015), the Open Foundation of Key Laboratory of Intelligent Computing and Signal Processing at Anhui University of Ministry of Education of China.
HUShanzhong, born in 1990, M. S. candidate. His research interests include rough set theory, granular computing, data mining.
XUYi, born in 1981, Ph. D., associate professor. Her research interests include intelligent information processing, granular computing, rough set theory.
HEMinghui, born in 1991, M. S. candidate. His research interests include neural network, rough set theory.
WANGRan, born in 1993, M. S. candidate. His reseach interests include recommender system, rough set theory.
Effectivealgorithmforgranulationreductionofmulti-granulationroughset
HU Shanzhong1, XU Yi1,2*, HE Minghui1, WANG Ran1
(1.CollegeofComputerScienceandTechnology,AnhuiUniversity,HefeiAnhui230601,China;2.KeyLaboratoryofIntelligentComputingandSignalProcessing,MinistryofEducation(AnhuiUniversity),HefeiAnhui230039,China)
Aiming at the low efficiency problem of the existing granulation reduction algorithms for multi-granulation rough set, an Effective Algorithm for Granulation Reduction of Multi-granulation Rough Set (EAGRMRS) was proposed. Firstly, the lower approximation Boolean matrix of decision classes was defined by using the decision information system as the object. The defined matrix could be used for converting redundant and repeated set operations into Boolean operations in the process of granular reduction. Based on this matrix, the algorithm for computing lower approximation of decision classes and the algorithm for computing the important measure of granularity were presented. Then, focusing on the problem of redundancy calculation when computing the important measure of granularity, a fast algorithm for computing the important measure of granularity with dynamic increasing of granularity was presented. On the basis, the EAGRMRS was proposed. The time complexity of the proposed algorithm isO(|A|·|U|2+|A|2·|U|), in which |A| is the size of granulation set, |U| is the number of instances in decision information system. The experimental results on UCI datasets show that, the proposed algorithm is effective and efficient, the efficiency advantage of EAGRMRS is more obvious over Heuristic Approach to Granular Structure Selection (HAGSS) for multi-granulation rough set when the dataset increases.
multi-granulation rough set; boolean matrix; information system; important measure; granulation reduction
2017- 06- 16;
2017- 09- 07。
国家自然科学基金资助项目(61402005);安徽省自然科学基金资助项目(1308085QF114);安徽省高等学校省级自然科学基金资助项目(KJ2013A015);安徽大学计算智能与信号处理教育部重点实验室课题项目。
胡善忠(1990—),男,安徽安庆人,硕士研究生,CCF会员,主要研究方向:粗糙集理论、粒计算、数据挖掘; 徐怡(1981—),女,安徽滁州人,副教授,博士,主要研究方向:智能信息处理、粒计算、粗糙集理论; 何明慧(1991—),男,山西晋中人,硕士研究生,主要研究方向:神经网络、粗糙集理论; 王冉(1993—),男,安徽合肥人,硕士研究生,主要研究方向:推荐系统、粗糙集理论。
1001- 9081(2017)12- 3391- 06
10.11772/j.issn.1001- 9081.2017.12.3391
(*通信作者电子邮箱xuyi1023@126.com)
TP18
A
