基于分数阶微分的TV-L1光流模型的图像配准方法研究
2018-01-08张桂梅孙晓旭刘建新储珺
张桂梅 孙晓旭 刘建新 储珺
基于分数阶微分的TV-L1光流模型的图像配准方法研究
张桂梅1孙晓旭1刘建新2储珺1
图像的非刚性配准在计算机视觉和医学图像分析中有着重要的作用.TV-L1(全变分L1范数、Total variation-L1)光流模型是解决非刚性配准问题的有效方法,但TV-L1光流模型的正则项是一阶导数,会导致纹理特征等具有弱导数性质的信息模糊.针对该问题,将G-L(Grnwald-Letnikov)分数阶引入TV-L1光流模型,提出基于G-L分数阶微分的TV-L1光流模型,并应用原始–对偶算法求解该模型.新的模型用G-L分数阶微分代替正则项中的一阶导数,由于分数阶微分比整数阶微分具有更好的细节描述能力,并能有效地、非线性地保留具有弱导数性质的纹理特征,从而提高图像的配准精度.另外,通过实验给出了配准精度与G-L分数阶模板参数之间的关系,从而为模板最佳参数的选取提供了依据.尽管不同类型的图像其最佳参数是不同的,但是其最佳配准阶次一般在1∼2之间.理论分析和实验结果均表明,提出的新模型能够有效地提高图像配准的精度,适合于包含较多弱纹理和弱边缘信息的医学图像配准,该模型是TV-L1光流模型的重要延伸和推广.
分数阶微分,Grnwald-Letnikov,TV-L1模型,光流场,弱纹理,非刚性配准
分数阶微积分理论在图像处理中的应用在最近几年才引起学者的关注,越来越多的学者把分数阶微积分应用到图像处理中,并在图像去噪、图像增强、小波变换、图像奇异性特征提取、图像融合、图像分割、图像边缘提取等方面取得了一些初步成果.文献[1]认为分数阶微分算子选择合适的阶次,在增强图像的过程中可以大幅提升边缘和纹理细节,并且可以非线性保留图像平滑区域的纹理信息.文献[2]利用分数阶微分阶次在(0,1)区间时,具有弱导数的性质,利用分数阶微分算子对含弱噪声的图像进行边缘检测,成功解决了整数阶梯度算子对噪声敏感的问题,避免了噪声的影响,准确检测噪声图像的边缘.文献[3]将分数阶积分理论引入图像去噪,构造分数阶积分模板对图像进行滤波去噪,该方法能够在提高峰值信噪比的同时更好地保留图像边缘和纹理信息.文献[4]将分数阶微积分引入奇异值分解用于人脸识别,该方法在人脸变化剧烈时相对于传统方法具有更好的分类效果.文献[5]将分数阶微分引入全变分模型用于图像修复领域,该方法对空域和频域损坏的图像,特别是对图像细节信息的修复,都具有更好的修复效果,在提高视觉效果的同时还提高了峰值信噪比.文献[6]将分数阶微分引入图像分割领域,提出一种具有分数阶次拟合项的活动轮廓模型,分数阶拟合项能够更加准确地描述图像,并且对噪声具有鲁棒性,该方法对噪声图像、医学图像和红外图像都有很好分割效果.受以上文献启发,分数阶微积分能够非线性地增强或者保留图像的纹理细节信息,本文将分数阶微积分引入图像配准领域.
图像配准是图像处理的一个基本问题,用于将不同时间、不同传感器、不同视角及不同拍摄条件下获取的两幅或者多幅进行匹配,目的是寻求一种空间变换,使一幅图像与另一幅图像上的对应点达到空间上的一致,用以纠正图像的形变.图像配准是近年来图像处理领域的研究方向之一,在遥感图像处理、医学图像分析,计算机视觉等领域有着广泛的应用.图像配准的方法根据待配准目标的类型可以将其分为刚性配准和非刚性配准.刚性配准只适用于不存在变形的配准,但现实生活中大多数形变是非刚性的,如在医学图像处理领域,大多数情况下,人体组织的形变是非刚性的,因而非刚性配准更具有重要研究意义[7−9].目前最著名的非刚性配准是基于光流场模型的Demons算法[7−9].其将图像的配准过程可以看作从源图像流动到目标图像的过程,即配准所求解的位移场可以看作光流场模型求解的速度场,因此可以通过求解光流场进行图像配准.如文献[10]提出基于光流场理论的Demons算法,其思想是将配准看作浮动图像像素点在参考图像灰度梯度驱动下向参考图像移动的过程,文献[11]在经典Demons算法基础上提出了主动Demons算法,该算法利用参考图像和浮动图像的灰度梯度作为共同驱动力驱动像素点向对方对应像素点移动,配准精度有所提高,但该类算法在图像灰度均匀及弱纹理区域配准精度较低,优化易陷入局部最小从而导致配准速度缓慢.文献[12]将Horn-Schunck(H-S)光流场模型引入图像配准,由于Horn-Schunck模型采用的光滑性约束无法保持图像的不连续性,而在医学图像配准中,允许位移场的不连续性是必要的,如呼吸运动,膈膜产生严重变形,而肋骨仍然是刚性形变,这时光滑位移场就不足以适用这种复杂的运动.另外,Horn-Schunck模型的二次数据项对亮度异常值不具有足够的鲁棒性.针对上述缺点,Pock等[13]提出了基于变分方法的TV-L1(Total variation-L1)光流模型,该模型能够保持图像的不连续性,即在图像演化过程中可以有效保持图像的边缘等特征信息,而且数据项采用光流的L1范数增强了配准的鲁棒性.文献[14]则具体描述了文献[13]方法的实现过程.文献[15]应用可变形配准方法得到比刚性配准、快速Demons配准和快速自由形状配准算法等更准确的效果.但是文献[13−15]对具有弱导数性质的纹理特征等信息的保持仍然不够理想.
虽然TV-L1模型相对H-S模型有了很大提升,能够在扩散过程中保持边缘信息,但对具有弱导数性质的纹理细节等信息的保持仍不够理想,并且在模型最小化过程中造成计算上的困难,主要原因是正则项和数据项在零点处都不可微,一个有效的方法是在零点处增加了一个极小值,然而新引入的项会造成收敛很慢并且会模糊位移场.本文的研究对象主要为存在弱边缘和弱纹理等特征的图像,如医学图像,在成像过程中由于受到电磁环境,成像设备,以及人体结构的差异等客观因素的影响,会造成图像存在弱纹理、弱边缘,所以要求配准方法能较好保持图像的边缘和纹理特征.而分数阶微分算子具有弱导数的性质,通过合理选择其阶次,可以达到保持弱边缘和弱纹理的特性,基于此,本文尝试将G-L分数阶微分理论引入到TV-L1光流模型中,用于图像的非刚性配准,以提高该模型的配准精度.
1 基本理论
1.1 Horn-Schunck(H-S)光流场模型[16]
假设图像上的像素点(x,y)在t时刻的灰度值为I(x,y,t),经过较小的Δt时刻后该点位置为(x+Δx,y+Δy),该点灰度值为I(x+Δx,y+Δy,t+Δt),根据光流场的亮度恒定假设得到光流约束方程[16]

即Ixu+Iyv+It=0,其中
在图像配准中,只取Δt时刻前后的两帧图像,U=(u,v)T为求解的速度场矢量,即配准要求解的位移场矢量,但是位移场矢量有两个变量,而通过亮度恒定假设只能得到一个约束方程,不足以求解x和y方向的位移u和v,这就是光流场求解的病态问题.因此要求解光流场模型还需对位移场矢量附加另外的约束.
Horn等创造性地在光流约束的基础上加上光滑性约束,该约束假设物体的运动速度在大多数情况下是局部光滑的,特别是目标在无形变的刚性运动时,各邻近像素点应具有相同的运动速度,即相邻点的速度变化率为0,因而将光流场的求解转化为能量泛函极小值问题:

第一项为正则项,惩罚光流场中大的变化以获得光滑的速度场,第二项为数据项,即基本光流约束,假设对应点运动前后灰度值不变,λ为正则化参数,是与正则项和数据项相关的一个权重参数.
由于H-S模型正则项采用光滑性约束,导致无法保持位移场的不连续性,会在图像的演化过程中产生严重模糊而丢失重要信息,数据项采用二次项惩罚偏差,对处理亮度异常值不具有鲁棒性.
1.2 TV-L1光流场模型
为了克服Horn-Schunck光流模型的缺点,Pock[13]等提出了基于变分方法的TV-L1光流模型,并且由于在实际问题中,光流约束并不会一直成立,即图像亮度恒定假设对于很多真实图像并不适用,如在光照条件变化大,图像亮度恒定假设存在较大误差,Pock等引入变量w对光流约束加以改进,通过w对光照变化建模得到:

其中,ρ(u,v,w)=Ix(u−u0)+Iy(v−v0)+It+βw,参数β为光照变化项权重因子,u0和v0为已知的位移场,该模型用非二次正则项|∇u|+|∇v|替换了H-S模型的正则项|∇u|2+|∇v|2,并用L1范数的数据项|ρ(u,v,w)|替换了H-S模型的数据项(Ixu+Iyv+It)2.虽然与H-S模型相比改动较小,但是配准精度有了很大的提升.首先全变分正则项保持了位移场的不连续性,在扩散过程中保护边缘信息不被模糊,这个替换后的正则项与与著名的ROF(Rudin、Osher、Fatemi)模型[17]的正则项相同,而ROF模型在具有很好去噪效果的同时还能保持边缘信息不被模糊,正是因为采用了非二次正则项.其次,数据项使用稳健的L1范数对亮度的变化不及H-S模型敏感.
虽然TV-L1模型相对H-S模型有了很大提升,能够在扩散过程中保持边缘信息,但对具有弱导数性质的纹理细节等信息的保持仍不够理想,并且在模型最小化过程中导致了计算上的困难,主要原因是正则项和数据项在零点处都不可微,一个有效的方法是用可微的来近似替代|∇u|,然而,极小值ε会导致收敛很慢并且会模糊位移场.本文尝试将分数阶微分来代替TV-L1模型中的一阶导数,并采用文献[18]的方法来求解基于分数阶微分的TV-L1光流场模型.
2 基于G-L分数阶微分的TV-L1光流场模型
分数阶微积分在17世纪提出,在19世纪得到了迅速发展,期间提出了许多关于分数阶微积分的定义,最著名的有R-L(Riemann-Liouville)定义、G-L(Grnwald-Letnikov)定义和Caputo定义.其中G-L和R-L定义在数值运算时可以转化为卷积积分形式,因此适用于信号处理领域,而Caputo定义适用于分数阶微分方程的初边值问题,多用于实际工程领域.而G-L定义在计算时较R-L定义更加准确,因此我们从G-L定义出发推导出本文算法所需要的分数阶微分算子,对TV-L1算法进行改进,用于图像的非刚性配准.
2.1 离散分数阶微分算子

式中,f(x)是实函数,为广义二项式系数,Γ(x) 为 Gamma 函数,m为正整数,m值越大,二项式系数值越趋于0.当α=1,m≥2时,cαm=0,式(4)变为一阶差分,即为传统梯度算子.
为简化起见,所用图像尺寸均为N×N 二维矩阵,用X 表示欧几里得空间RN×N,对于X 中的任意变量定义X 中的内积:

定义矢量空间Y=X×X,分数阶梯度算子∇αu为矢量空间Y中的一个矢量:

其中

对于Y中任意的变量p=(p1,p2),分数阶散度算子的离散形式为

定义Y中的内积:

容易得到式(5)和式(9)满足如下性质:

为方便计算,本文根据G-L定义的分数阶导数在特定离散情况下与某种卷积积分的离散化形式相同这一个特点,将分数阶导数转化为卷积积分的形式.若记卷积核函数为

则式(7)可看作为式(12)的一个离散化近似,
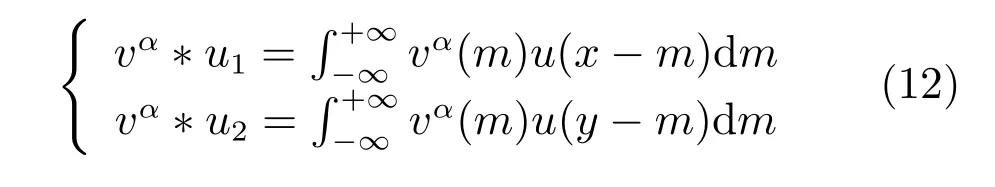

这样算法中涉及分数阶微分的运算便转化为卷积与相关运算.在具体计算时,采用4个方向的分数阶微分掩模算子W1、W2、W3、W4,从而可以控制图像的上下左右4个方向的扩散程度,W1如图1所示.其中W1 是沿x负方向的掩模算子,W2∼W4依次顺时针与x负方向夹角为 90°、180°、270°.

图1 分数阶微分模板Fig.1 Diあerential template
2.2 分数阶TV-L1光流场模型
本文将G-L分数阶微分引入TV-L1光流模型,代替其中的一阶微分,得到分数阶TV-L1光流场模型(Fractional TV-L1,记为FTV-L1):

将模型转化为离散形式得到:

其中

参数α是个实数,当α=1时,该分数阶TV-L1光流场模型即可看作文献[13]提出的一阶TV-L1光流场模型,所以分数阶TV-L1光流场模型实际上是整数阶TV-L1光流场模型的一个扩展和延伸.
2.3 分数阶TV-L1模型的求解
文献[18]提出了有效且准确的一阶原始–对偶算法来求解变分问题,且证明了以O(1/N)的速率收敛.本文应用文献[18]的方法求解本文提出的FTV-L1光流场模型.文献[18]的TV-L1光流模型迭代方法如下:对于一类问题的原始形式:

先变换为其的原始–对偶形式,再进行迭代,得到下式:
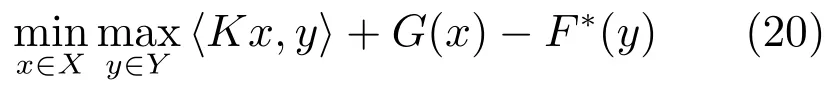
其中,F∗为F的凸共轭.
步骤1.初始化:τ,σ>0,0=x0.
步骤2.迭代更新xn,yn,n:

分数阶TV-L1光流模型的离散形式为

引入对偶变量p,q,z∈Y,则分数阶TV-L1模型的原始–对偶形式如下:

根据式(12)的性质,式(25)可变换为

其中,P,Q,Z分别为变量p,q,z的凸集,定义如下:

式中,‖·‖∞表示无穷范数:对‖q‖∞和‖z‖∞同理可得.
凸集P,Q,Z是L2球体内的点集,式(26)中函数δP(p)、δQ(q)和δZ(z)分别为集合P,Q,Z的指示函数,它们的表达式如下:

由式(21)和(22)知,该迭代方法的关键是求解(I+σ∂F∗)−1和 (I+τ∂G)−1两个算子. 对比式(26)和式(20)可知,F∗(p,q,z)= δP(p)+δQ(q)+δZ(z),G(u,v,w)=λ‖ρ(u,v,w)‖1, 下面将应用上述迭代方法来最小化式(15),求解分数阶TV-L1模型.具体求解步骤如下:
步骤1.
1)先求解式(21)中的(yn+σK¯xn):

2) 再求解式 (21) 中的 (I+σ∂F∗)−1,由于F∗(p,q,z)为集合P,Q,Z 的指示函数,把集合P,Q,Z内的点按欧几里得距离分别投影至L2球内:

步骤2.
1)先求解式(22)中的(xn−τK∗yn+1):

2)再求解式 (22)中的 (I+τ∂G)−1,因为G(u,v,w)=λ‖ρ(u,v,w)‖1是L1范数, 而L1范数是连续不光滑的,为方便描述,定义ai,j=(∇Ii,j,β),|a|2i,j=|∇I|2i,j+β2:

步骤3.返回步骤1.
由于FTV-L1光流模型是个非凸优化问题,光流约束仅对小位移有效,为了使其对大位移的情形也适用,本文对上述模型应用从粗到精的配准策略,避免模型在极小化过程中陷入局部极小值.具体方法为:取降采样因子为2,建立高斯图像金字塔,对每一层图像极小化FTV-L1模型(式(15)),求其位移场.从最粗一层开始,直到最精一层.每一层求得的位移场作为下一层图像求解的初值.第一层,初始化位移场(u,v)为0,光照变化变量w初始化为0,对偶变量(p,q,z)初始化为0.对于每一层金字塔图像的位移场求解过程,如上述三个迭代步骤.由于本文使用4个方向的分数阶微分模板进行求导操作,故计算过程中关于位移场(u,v,w)的离散梯度算子及关于对偶变量(p,q,z)的离散散度算子变化如下:

用式(33)替代原来的整数一阶前后差分算法.
2.4 实验参数的设置
本文实验中迭代次数取50时,模型已经达到收敛,此处迭代次数设置为50是因为经过多次实验发现,在迭代次数为50时,灰度均方差(Mean square error,MSE)和峰值信噪比(Peak singnal to noise ratio,PSNR)均达到了收敛,故选择了迭代次数为50.如图2(a)和图2(b)所示为Lena图像的迭代次数与灰度均方差MSE和峰值信噪比PSNR的关系曲线,在迭代次数为42时,已达到了收敛.应用其他图像重复进行多次实验,发现迭代次数均在50次内能达到收敛.
另外还有三个参数β、λ和α.β值控制着光照项对模型的影响,由于本文模型是基于光流强度保持恒定的假设,但实际情况中,由于光照变化等原因,光流强度往往不会保持恒定,所以增加β项来稍微改进光流约束项,β值应取较小值,经过多次实验本文选取β为0.01.
正则化参数λ是影响着正则项和数据项的权重,由于光流模型的正则项起惩罚光流场中大的变化以获得平滑光流场的作用,若λ值大,则对光流约束项的影响越大,即光流约束只要存在一点偏离,都会导致该泛函发散;反之,若λ越小,则对光流约束项的影响越小.总之,λ的大小决定正则化的强度,决定了模型解的倾向,较大的λ倾向于满足正则项约束,较小的λ倾向于满足光流约束,本文的λ值则在两种极端中寻找某种平衡.一般λ值建议在10∼100之间,本文经过多次实验,选取λ值为40.

图2 迭代次数的选择Fig.2 Choice of iteration number
下面分析分数阶微分阶次α的选取,对于可积函数f(x),其傅里叶变换为根据傅里叶变换的性质,其阶导数为把阶次从整数阶扩展到分数阶可得:


图3 分数阶微分算子幅频特性曲线Fig.3 The amplitude-frequency curve of fractional diあerentiator
从图3可以看出,当阶次小于1时,与整数1阶相比,分数阶微分算子对中低频部分的幅值有所提升,而对高频部分的幅值则有所压缩,随着阶次的变大,对中低频部分的提升幅度越来越小,对高频部分的压缩也减弱.当阶次大于1时,与整数1阶相比,分数阶微分算子对中低频部分的幅值由提升变成了压缩,阶次越大,压缩越大,而对高频部分的幅值则变成了提升,阶次越大,提升越大.当阶次小于1时,可看作一个对中低频增强放行,对高频压缩放行的滤波器,而当阶次大于1时,可看作一个高通滤波器.在图像处理中,图像的平滑区域对应着信号的低频部分,图像的纹理信息对应着信号的中低频部分,图像的轮廓和噪声对应着信息的高频部分,总之根据实际图像处理中目的不同选取不同的阶次区域,而根据本文模型可知,我们希望阻止中低频部分通过滤波器而非放行,从而达到保持纹理细节信息的目的,故阶次的合理区间建议选择在1∼2之间.但针对不同的图像,其最佳参数不相同.分数阶微分相对于整数阶微分的优势是可以有目的地控制微分后的值大于或者小于整数阶微分后的值,但这是通过某个像素点周围的众多像素点共同参与计算实现的,若模板宽度过小,则参与计算的像素点就少,体现不了分数阶微分的优势,但模板取得过大,又会起到光滑平均的作用,因此要在两者之间平衡,需要经过多次实验取得最佳值.所以本文分数阶模板中的阶次和模板宽度都是通过实验确定,并且对于不同的图像,其最佳的参数都是不同的,需要通过多次实验确定.
3 实验结果与分析
本文选用标准库图像Lena和真实大脑图像Brain1、Brain2(两种不同类型的)进行测试,如图4所示.图4中第一行为参考图像,第二行为与第一行对应的浮动图像,即变形图像.为了证明本文方法的有效性,从定性和定量两个方面来评价配准精度.定性评价即观察视觉效果,比较配准后的图像和原始图像的差异以及通过二者差值图像黑色区域所占大小来评价,定量评价则通过配准后图像和原始图像的灰度均方误差MSE(Mean square error)和峰值信噪比PSNR(Peak signal to noise ratio)来评价.
灰度均方误差定义如下:

峰值信噪比定义如下:

其中,I1是t时刻的图像,即参考图像,I是经过配准后的图像,m×n为像素个数.理想情况下MSE值应为0,表示两幅图像同一位置上点的灰度值相同.PSNR值越大越好,表示配准后图像越逼近参考图像.
本文实验所使用的计算机环境为:Intel Core i3-2130CPU,3.40GHZ,内存4GB,操作系统为64位Windows 7.0,程序使用R2012b版Matlab实现.
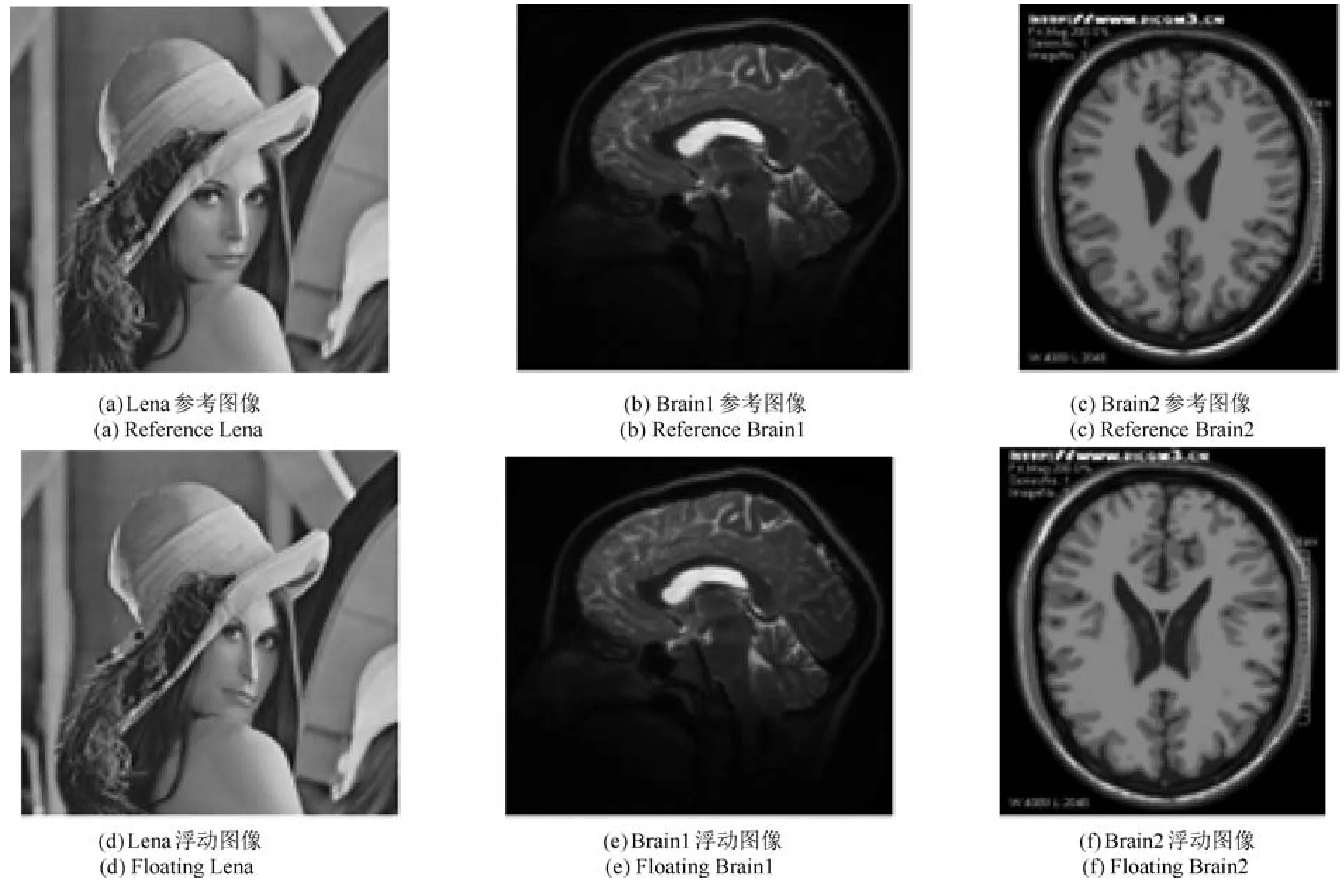
图4 实验图像(其中第一行为参考图像,第二行为与参考图像对应的浮动图像)Fig.4 Experimental images(The fi rst line are reference images,the second line are fl oating images corresponding to reference images)
3.1 标准库图像实验
本次实验选用图4(a)所示的Lena作为参考图像进行实验,为了证明本文方法有效性,对Lena图像进行扭曲形变,如图5(a)所示,Lena图像头发处发生了明显扭曲变形.图5展示了TV-L1算法和本文算法最佳阶次配准的视觉效果.图5(b)为TV-L1算法配准后的图像,图5(c)∼(e)分别是本文算法取最佳阶次三个不同的模板宽度所对应的配准结果图,从图中可得图5(b)中的Lena图像眼角处以及头发处出现了信息丢失,而对比本文算法配准后的配准图片图5(c)、图5(d)和图5(e)在对应处效果则要好很多,并未出现明显信息丢失.图5(f)是TV-L1算法配准后的差值图像(配准后的图像与输入图像的差值图像),图5(h)∼(j)是本文算法取最佳分数阶阶次和三个不同模板宽度时所对应的差值图像.如果两幅图像完全配准,理论上其差值图像应该全黑,即表示配准后图像与参考图像相同,所以差值图像黑色区域越多越好,通过对比可知,图5(h)∼(j)相对图5(g)黑色区域明显多很多,从而也证明了分数阶微分TV-L1配准算法能够较好地提高配准精度.在分数阶阶次为1.2时,模板宽度k为2(即为5×5)时,配准效果达到最佳.但是,对于不同的图片,最佳的实验参数仍然需要进行多次实验人工选定.
为了得到最佳的模板参数,我们进一步进行实验,依据灰度均方误差MSE和峰值信噪比PSNR来分析模板的参数α,k对配准的影响.图6(a)展示了均方误差(MSE)和阶次α与模板宽度k的关系,MSE值越小表示配准精度越高,图6(b)展示了峰值信噪比(PSNR)和阶次α与模板宽度k的关系,PSNR值越大表示配准精度越高.图6(a)和图6(b)中三条曲线分别是在模板大小参数k取1、2、3时的MSE值和PSNR值,当阶次α等于1时,即为TV-L1算法的实验结果.为方便观察,TVL1算法和本文算法最佳阶次下不同模板的MSE值和PSNR值已列在表1和表2中.从图6(a)中可以看出,MSE最小值并不是在阶次α等于1的时候,阶次从0.1开始,随着阶次的增大,MSE呈现减小的趋势,当α值在1.2处时,MSE值达到最小,这是因为当α小于1时,纹理等中低频信息丢失,图像纹理细节模糊,导致图片配准精度降低,而当α大于1时,纹理细节信息被阻止通过滤波器从而达到保持纹理的效果,但当α过大时,会导致高频信号如边缘信息模糊,从而配准精度降低,所以存在一个最佳阶次,使中低频信号和高频信号达到一个平衡,而此次实验的最佳阶次为1.2.图6(b)中PSNR值最高的阶次也不在α为1处,原因同上.通过实验得知,在分数阶阶次α等于1.2,模板宽度k等于2(即为5×5)时,配准效果达到最佳.不过,对于不同的图片,最佳的实验参数仍然需要进行多次实验人工选定.同时也能得到结论:一阶微分并不能有效地刻画位移场中的具有弱导数性质的纹理细节等信息,而近年来的研究也表明分数阶微分比整数阶微分具有更好的描述纹理信息能力,所以用分数阶微分来代替整数阶微分在TV-L1算法中的应用,能够获得更高的配准精度.

图5 Lena图像实验(第一行为浮动图像和配准后图像,第二行为差值图像.(a)为浮动图像,(b)∼(e)为配准后的图像;(b)TV-L1方法;(c)本文方法(α=1.2,k=1);(d)本文方法(α=1.2,k=2);(e)本文方法(α=1.2,k=3);(f)∼(j)分别为第一行图像与参考图像(图4(a))的差值图像)Fig.5 Lena image(The fi rst line is fl oating image and registered image,the second line is diあerence image.(a)Floating image,(b)∼(e)are registered images,(b)TV-L1,(c)Our method(α =1.2,k=1),(d)Our method(α =1.2,k=2),(e)Our method(α =1.2,k=3),(f)∼(j)are diあerence images)

图6 配准精度与模板参数间的关系曲线Fig.6 Curve between registration accuracy with mask parameters
3.2 真实图像实验

图7 Brain1图像实验(第一行为浮动图像和配准后图像,第二行为差值图像.(a)为浮动图像,(b)∼(e)为配准后的图像;(b)TV-L1方法;(c)本文方法(α=1.3,k=1);(d)本文方法(α=1.3,k=2);(e)本文方法(α=1.3,k=3);(f)∼(j)分别为第一行图像与参考图像(图4(b))的差值图像)Fig.7 Brain1 image(The fi rst line is fl oating image and registered image,the second line is diあerence image.(a)Floating image,(b)∼(e)are registered images,(b)TV-L1,(c)Our method(α =1.3,k=1),(d)Our method(α =1.3,k=2),(e)Our method(α =1.3,k=3),(f)∼(j)are diあerence images)
本次做了两组实验,选用脑部图像,如图4中Brain1和Brain2,将参考图像与浮动图像配准.该两组浮动图像相对于参考图像只有轻微变形,人眼辨识已稍显困难,但通过参考图像和浮动图像的差值图像还是可以看出大量白色区域存在,如图7所示.图7(g)是TV-L1算法配准后图像图7(b)与参考图像Brain1的差值图像,图7(h)、(i)和(j)分别是本文算法不同参数下的配准图像与参考图像Brain1的差值图像,通过比较可以发现,本文算法的差值图像白色区域有较大减少,并且当α=1.3,k=2时,MSE值达到最小,PSNR值达到最大,也证明本文算法相比TV-L1算法具有更高的配准精度,为了方便观察,TV-L1算法和本文算法最佳阶次下不同模板的MSE值和PSNR值已列在表1和表2中.同理,为了进一步验证本文方法的有效性,再次选用了Brain2图像重复上述实验,实验结果如图8所示和表1及表2所示.多组实验结果表明本文的配准方法较原始的TV-L1方法配准精度得到较大的提高.

图8 Brain2图像实验(第一行为浮动图像和配准后图像,第二行为差分图像.(a)为浮动图像,(b)∼(e)为配准后的图像;(b)TV-L1方法;(c)本文方法(α=1.3,k=1);(d)本文方法(α=1.3,k=2);(e)本文方法(α=1.3,k=3);(f)∼(j)分别为第一行图像与参考图像(图4(c))的差值图像)Fig.8 Brain2 image.The fi rst line is fl oating image and registered image,the second line is diあerence image((a)lf oating image,(b)∼ (e)are registered images,(b)TV-L1,(c)Our method(α =1.3,k=1),(d)Our method(α =1.3,k=2),(e)Our method(α =1.3,k=3),(f)∼(j)are diあerence images)

表1 参考图像和配准图像的均方误差(MSE)Table 1 Mean square error(MSE)of reference image and registered image

表2 峰值信噪比(PSNR)Table 2 Peak signal to noise ratio(PSNR)
4 结论
将G-L分数阶微分引入到TV-L1光流模型中,提出了一种新的基于分数阶微分的全变分方法(FTV-L1)来解决图像的非刚性配准问题.结合全变分能量方程的对偶形式来极小化FTV-L1光流模型获得位移场.融合G-L分数阶的TV-L1光流模型能够解决图像灰度均匀,弱纹理区域配准结果中的信息模糊的问题,这是因为分数阶微分比整数阶微分具有更好的细节描述能力,可以有针对性地选择合适的阶次对具有弱导数性质的信息如纹理信息进行抑制或者非线性保留,因此可以提高图像的配准精度.另外,通过实验给出了配准精度和阶次、模板宽度的关系,从而为最佳模板参数的选取提供了依据,尽管不同类型的图像其最佳参数是不同的,但是其最佳配准阶次一般在1∼2之间.理论分析和实验结果均表明,本文的方法可用于弱纹理和弱边缘图像的非刚性配准,提高图像配准的精度,是TV-L1光流场模型的一个重要延伸和扩展.
但是不同图像配准的最佳阶次需要不断测试,因而是比较耗时和费力的.今后可以研究自适应G-L分数阶TV-L1的非刚性图像配准算法.此外本文的分数微分掩模是二维的,要完成三维图像的配准,还需将其扩展到三维空间.
1 Pu Yi-Fei,Wang Wei-Xing.Fractional diあerential masks of digital image and their numerical implementation algorithms.Acta Automatica Sinica,2007,33(11):1128−1135(蒲亦非,王卫星.数字图像的分数阶微分掩模及其数值运算规则.自动化学报,2007,33(11):1128−1135)
2 Chen Qing,Liu Jin-Ping,Tang Zhao-Hui,Li Jian-Qi,Wu Min.Detection and extraction of image edge curves and detailed features using fractional diあerentiation.Acta Electronica Sinica,2013,41(10):1873−1880(陈青,刘金平,唐朝晖,李建奇,吴敏.基于分数阶微分的图像边缘细节检测与提取.电子学报,2013,41(10):1873−1880)
3 Pu Y F,Siarry P,Zhou J L,Liu Y G,Zhang N,Huang G,Liu Y Z.Fractional partial diあerential equation denoising models for texture image.Science China Information Sciences,2014,57(7):1−19
4 Liu J,Chen S C,Tan X Y.Fractional order singular value decomposition representation for face recognition.Pattern Recognition,2008,41(1):378−395
5 Zhang Y,Pu Y F,Hu J R,Zhou J L.A class of fractionalorder variational image inpainting models.Applied Mathematics and Information Sciences,2012,6(2):299−306
6 Ren Z M.Adaptive active contour model driven by fractional order fi tting energy.Signal Processing,2015,117:138−150
7 Xue Peng,Yang Pei,Cao Zhu-Lou,Jia Da-Yu,Dong En-Qing.Active demons non-rigid registration algorithm based on balance coeきcient.Acta Automatica Sinica,2016,42(9):1389−1400(薛鹏,杨佩,曹祝楼,贾大宇,董恩清.基于平衡系数的 Active Demons非刚性配准算法.自动化学报,2016,42(9):1389−1400)
8 Zhang Gui-Mei,Cao Hong-Yang,Chu Jun,Zeng Jie-Xian.Non-rigid image registration based on low-rank Nystr¨om approximation and spectral feature.Acta Automatica Sinica,2015,41(2):429−438(张桂梅,曹红洋,储珺,曾接贤.基于Nystr¨om 低阶近似和谱特征的图像非刚性配准.自动化学报,2015,41(2):429−438)
9 Yan De-Qin,Liu Cai-Feng,Liu Sheng-Lan,Liu De-Shan.A fast image registration algorithm for diあeomorphic image with large deformation.Acta Automatica Sinica,2015,41(8):1461−1470(闫德勤,刘彩凤,刘胜蓝,刘德山.大形变微分同胚图像配准快速算法.自动化学报,2015,41(8):1461−1470)
10 Thirion J P.Image matching as a diあusion process:an analogy with Maxwell′s demons.Medical Image Analysis,1998,2(3):243−260
11 Wang H,Dong L,O′Daniel J,Mohan R,Garden A A,Ang K K,Kuban D A,Bonnen M,Chang J Y,Cheung R.Validation of an accelerated ‘demons’algorithm for deformable image registration in radiation therapy.Physics in Medicine and Biology,2005,50(12):2887−2905
12 Palos G,Betrouni N,Coulanges M,Vermandel M,Devlaminck V,Rousseau J.Multimodal matching by maximisation of mutual information and optical fl ow technique.In:Proceedings of the 26th Annual International Conference of the IEEE Engineering in Medicine and Biology Society(IEMBS).San Francisco,CA,USA:IEEE,2004.1679−1682
13 Pock T,Urschler M,Zach C,Beichel R,Bischof H.A duality based algorithm for TV-L1-optical- fl ow image registration.Medical Image Computing and Computer-Assisted Intervention-MICCAI 2007.Berlin Heidelberg:Springer-Verlag,2007.511−518
14 P´erez J S,Meinhardt-Llopis E,Facciolo G.TV-L1 optical fl ow estimation.Image Processing on Line,2013,3:137−150
15 Yip S S F,Coroller T P,Sanford N N,Huynh E,Mamon H,Aerts H J W L,Berbeco R I.Use of registration-based contour propagation in texture analysis for esophageal cancer pathologic response prediction.Physics in Medicine and Biology,2016,61(2):906−922
16 Horn B K,Schunck B G.Determining optical fl ow.In:Technical Symposium East.Washington,D.C.,USA:International Society for Optics and Photonics,1981.319−331
17 Rudin L I,Osher S,Fatemi E.Nonlinear total variation based noise removal algorithms.Physica D:Nonlinear Phenomena,1992,60(1−4):259−268
18 Chambolle A,Pock T.A fi rst-order primal-dual algorithm for convex problems with applications to imaging.Journal of Mathematical Imaging and Vision,2011,40(1):120−145
19 Cafagna D.Fractional calculus:a mathematical tool from the past for present engineers.IEEE Industrial Electronics Magazine,2007,1(2):35−40
Research on TV-L1Optical Flow Model for Image Registration Based on Fractional-order Diあerentiation
ZHANG Gui-Mei1SUN Xiao-Xu1LIU Jian-Xin2CHU Jun1
In computer vision and medical image analysis,non-rigid image registration is a challenging task.TV-L1(Total variation-L1)optical fl ow model has been proved to be an eあective method in the fi eld of non-rigid image registration.It can solve the problem of fuzzy edge caused by smooth displacement fi elds of Horn-Schunck,but its fi rst-order derivative in regularization term leads to fuzzy texture information with weak derivative property.Aiming at the problem,this paper introduces G-L(Grnwald-Letnikov)fractional diあerentiation to TV-L1optical fl ow model,and proposes a new TV-L1optical fl ow model based on fractional diあerentiation,and then fi nds the solution of the model using primal-dual algorithm.In this paper we use Grnwald-Letnikov fractional order diあerential instead of the fi rst-order derivative in the regularization term for its better ability of detail description than fi rst-order′s.Then we purposefully control to retain or inhibit the texture information with weak derivative nature,thus improving the registration accuracy.Experimental results show that the proposed method has a better registration accuracy in registration of texture information with weak derivative,and that it can be considered an important extension and generalization of TV-L1optical fl ow modes.
Fractional diあerential,Grnwald-Letnikov,TV-L1(Total variation-L1)model,optical fl ow,weak texture,non-rigid registration
Zhang Gui-Mei,Sun Xiao-Xu,Liu Jian-Xin,Chu Jun.Research on TV-L1optical fl ow model for image registration based on fractional-order diあerentiation.Acta Automatica Sinica,2017,43(12):2213−2224
2016-04-29 录用日期2016-10-05
April 29,2016;accepted October 5,2016国家自然科学基金(61462065,61661036),江西省自然科学基金 (20151BAB207036),江西省科技支撑计划重点项目(20161BBF60091)资助
Supported by National Natural Science Foundation of China(61462065,61661036),Natural Science Foundation of Jiangxi Province(20151BAB207036),and the Key Science and Technology Support Program of Jiangxi Province(20161BBF60091)
本文责任编委张长水
Recommended by Associate Editor ZHANG Chang-Shui
1.南昌航空大学江西省图像处理与模式识别重点实验室 南昌330063 2.西华大学机械工程学院成都610039
1.Key Laboratory of Jiangxi Province for Image Processing and Pattern Recognition,Nanchang Hangkong University,Nanchang 330063 2.School of Mechanical Engineering,Xihua University,Chengdu 610039
张桂梅,孙晓旭,刘建新,储珺.基于分数阶微分的TV-L1光流模型的图像配准方法研究.自动化学报,2017,43(12):2213−2224
DOI10.16383/j.aas.2017.c160367

张桂梅 南昌航空大学江西省图像处理与模式识别重点实验室教授.主要研究方向为计算机视觉,图像处理与模式识别.
E-mail:guimei.zh@163.com
(ZHANGGui-Mei Professor at the Key Laboratory of Jiangxi Province forImage Processing and Pattern Recognition,Nanchang Hangkong University.Her research interest covers computer vision,image processing,and pattern recognition.)

孙晓旭 南昌航空大学江西省图像处理与模式识别重点实验室硕士研究生.主要研究方向为图像处理与计算机视觉.
E-mail:sunxiaoxu@outlook.com
(SUN Xiao-Xu Masterstudent attheKey Laboratory ofJiangxi Province for Image Processing and Pattern Recognition,Nanchang Hangkong University.His research interest covers image processing and computer vision.)

刘建新 西华大学机械工程学院教授.主要研究方向为图像处理与机器视觉.本文通信作者.
E-mail:jamsonliu@163.com
(LIU Jian-Xin Professor at the School of Mechanical Engineering,Xihua University. His research interest covers image processing and machine vision.Corresponding author of this paper.)

储 珺 南昌航空大学江西省图像处理与模式识别重点实验室教授.主要研究方向为图像处理与计算机视觉.
E-mail:chujun99602@163.com
(CHU Jun Professor at the Key Laboratory of Jiangxi Province for Image Processing and Pattern Recognition,Nanchang Hangkong University.Her research interest covers image processing and computer vision.)
