基于3D-CNN的暴力行为检测①
2018-01-08YahyaKhan
周 智,朱 明,Yahya Khan
(中国科学技术大学 信息科学技术学院,合肥 230022)
基于3D-CNN的暴力行为检测①
周 智,朱 明,Yahya Khan
(中国科学技术大学 信息科学技术学院,合肥 230022)
大量的研究行为识别方法集中在检测简单的动作,如: 步行,慢跑或者跳跃等; 针对于打斗或者动作复杂的攻击性行为则研究较少; 而这些研究在某些监控场景下非常有用,如: 监狱,自助银行,商场等. 传统的暴力行为识别研究方法主要利用先验知识来手动设计特征,而本文提出了一种基于3D-CNN结构的暴力检测方法,通过三维深度神经网络直接对输入进行操作,能够很好的提取暴力行为的时空特征信息,从而进行检测. 从实验结果可以看出,本文方法能较好地识别出暴力行为,准确率要高于人工设计特征的方法.
动作识别; 暴力检测; 深度学习; 卷积神经网络
随着监控系统的大量使用,视频数据出现爆发性的增长. 监控系统的作用是进行目标检测以及异常行为检测. 随着数据的急剧增长,传统的依靠人工监控已愈发困难,且效率低下. 因此,依靠人工智能的监控系统的研究成为了热点,其中,对于人的暴力行为的检测是重要的研究方向.
由于暴力行为的动作比起简单的跑,跳行为[1,2]要复杂很多,所以也是相关研究中的难点. 目前,针对于暴力行为检测,许多通用的方法都是通过特征点提取,比如说光流、梯度、颜色等,在使用分类器如SVM,HMM 等,进行暴力检测. Nam[3]等人提出火焰、血液等特征来检测暴力行为. Bermejo[4]等人利用STIP对暴力行为进行分类. Tai[5]等人对光流向量进行计算,进而检测暴力行为. Martin[6]等人使用多尺度的局部二相模式直方图进行暴力检测. Wang[7]使用了基于轨迹分析的暴力行为识别方法. 综上所述,传统的暴力行为识别主要是采用基于人工设计特征的方法,虽然识别准确率较高,但是也具有某些缺陷,如: 耗时较高,易受噪声干扰依赖特定数据集等. 近年来,以CNN[8,9]为代表的深度学习算法取得了快速发展,Ji[10]等人首次提出了一种时空卷积神经网络用来进行人体动作识别. Karpathy[11]等人建立了一百万视频的行为分析数据集,通过多种CNN结构训练视频,进而来判断行为类别.
针对于此,本文采用基于3D-CNN的暴力行为识别方法. 该方法基于深度学习,无需手动提取特征,通过3D-CNN模型自动学习特征,识别暴力行为.
1 3D-CNN 模型
1.1 CNN和动作表示
一般,在视频中应用CNN的一个简单的方法是对每一帧图片用CNN来识别,如图1所示. 但是传统的2D-CNN结构没有考虑时间维度上的特征信息. 因此,Ji[8]等人首次提出的3D-CNN模型用来进行动作识别.通过在CNN的卷积层进行3D卷积,从而能够在空间以及时间维度上都能学习有用的特征,如图2所示.
3D-CNN是将视频中的连续帧作为一个时空立方体,以此作为CNN网络的输入,用3D卷积核对时空立方体进行操作,从而提取空间和时间上的特征信息.选取不同的卷积核对立方体进行卷积,就能得到多种时空特征.
1.2 3D-CNN模型结构
Tran[12]等人提出了一种3D深度卷积神经网络的框架-C3D模型. 本文提出了将C3D模型运用于暴力行为检测的方面,并且在原始的C3D进行了改进,从而能更有效地检测暴力行为. 本文模型结构如图3所示,模型共有 8 个卷积层,5 个最大池化层,2 个全连接层,最后加上一个SoftMax层. 所有的3D卷积核大小都是3*3*3,时间和空间维度的步长都为1,Padding为1. 每个卷积层的卷积核个数可以在图2中看出. 每个池化层的滤波器大小都是3维的,除了Pool1的滤波器大小是1*2*2,其他的Pool层滤波器大小都是2*2*2.
网络的输入视频大小是171*128*16,通过对输入进行中心裁剪得到尺寸为112*112*16. 在Conv1a层中采用3*3*3大小的卷积核作用输入层,卷积核步长为1*1*1,激活函数为ReLu函数. 选取64种不同的卷积核,这样共得到 64 个 Feature Map. 其计算过程如下:


图1 2D 卷积

图2 3D 卷积
在卷积层Conv1a后面是降采样层Pool1,采用2*2*1大小的滤波器对Conv1a层的每个特征图进行降采样,步长为 2*2*1,这样做可以使特征图变小,简化网络的计算复杂度. 其计算过程如下所示:

同样地,卷积层Conv2a和池化层Pool2所采用的的连接方式和计算方式的原理与Conv1a和Pool1相同,Feature Map 个数为 128 个. 随后的 3 个层数都是两个卷积层后面加一个池化层,Feature Map个数分别为256,512以及256个. 在Pool5层后面有两个全连接层,全连接层神经元个数为512个和100个,全连接层后面都接有一个dropout层来减轻网络过拟合,最后一层是SoftMax层来进行分类.

图3 本文 3D-CNN 模型
1.3 模型融合
一般来说,不同的输入可以训练得到不同的模型,其预测的结果是不同的. 因此在本文中考虑不同的模型之间的组合会对结果产生影响. RGB图主要反映图像的表观信息,故可以提取图像的其它信息来更好地反映图像内容,并以此作为模型的输入,通过不同的输入构造多个不同的3D CNN模型,在分类阶段,进行模型融合,计算每个模型的输出,通过求平均等方法得到最终的预测结果.
光流信息能很好地反映运动目标的方向及速度信息,可以通过提取图像的光流信息,得到光流图谱.

图4 光流图谱


上式中,n表示区域内的像素点数目 (n=m2),Ix和Iy表示区域内的光流变量的空间梯度,It为区域内光流变量的时间梯度. 求解上述方程:


2 实验结果与分析
在本节中,为了评估模型的有效性,我们在暴力行为数据集HockeyFight上进行测试,HockeyFight数据集包含1000个冰球比赛的片段,其中包括暴力视频和正常比赛视频各 500 个片段,如图5 所示. 同时,我们也采用自己准备的ATM数据集进行实验,ATM数据集同样也包含1000个ATM机取款的片段,其中也包括抢劫暴力视频和正常取款视频,如图6所示. 以下是实验结果的说明.
HockeyFight数据集: 包括 1000 个视频片段,每个片段包含连续32帧图片,我们以连续16帧作为一个样本,共有2000个样本. 我们随机选择800个打斗样本和800个正常样本,作为训练集,剩余的作为测试集.我们设置初始学习率为0.03,batchsize为30,每次随机批处理30个片段,分别在不同迭代次数下,进行了对比实验,如表1所示.

图5 HockeyFight数据集视频片段

图6 ATM 数据集视频片段
从表1可以看出,在迭代次数为8000时,检测准确率最高,当迭代次数低于8000次的时候,模型训练不够充分; 当高于8000次的时候,模型会出现过拟合,准确率都会下降. 图7表示本文3D-CNN模型的ROC曲线图,可以看出本文模型能够有效地检测出视频中的暴力场景.

表1 C3D 模型在 HockeyFight数据集的准确率
同时,为了进一步验证模型的有效性,我们与多种手工提取特征的算法进行对比,文献[4]中提出了两种行为特征描述子STIP和MoSIFT,并且在Hockey数据集上进行验证,结果如图8所示.
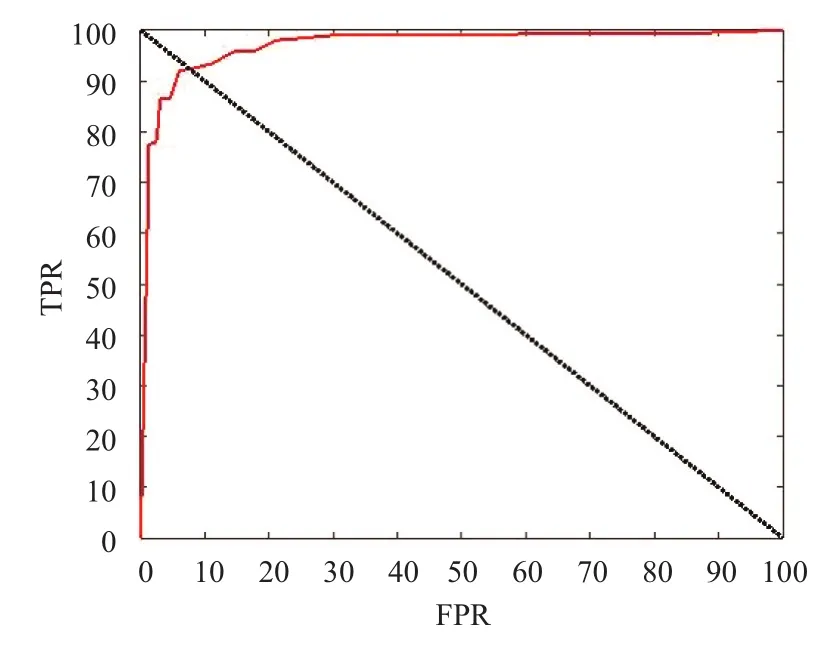
图7 HockeyFight数据集 ROC 曲线图

图8 算法准确率对比
图8中,本文模型在HockeyFight数据集上的准确率达到了93.8%,而文献[4]中的三种方法的准确率分别为 88.6%,90.9%,91.7%,由上可知,本章提出的模型检测准确率高于提出的所有方法. 此外,STIP和MoSIFT特征都属于手工提取特征,本文利用深度学习的方法,直接对输入进行操作,无需依靠经验手工提取特征,并且耗时也要比STIP和MoSIFT等传统特征要好.
考虑到不同的模型以及模型组合对实验结果的影响,我们也做了相关实验,对比模型分别为: RGB 图像训练的模型,RGB+光流图(FLOW)训练的模型. 分别选取准确率最高的数据进行对比,如表2所示.
从表中可以看出,RGB+FLOW模型融合在一定程度上可以提高准确率,最高准确率达到了94.4%,要高于使用RGB图像构建的3D-CNN模型的最高准确率.可见合适的模型融合能够有效地提高识别准确率. 本文中只对比了RGB+FLOW模型的融合,事实上,也可以选择其它合适的模型进行组合.

表2 模型组合在 HockeyFight数据集的准确率
ATM数据集: 场景是ATM机自助取款银行. 我们以连续16帧作为一个样本,数据集中包含了1500个训练样本,其中打斗样本 700 个,正常样本 800 个; 500个测试样本,其中打斗样本200个,正常取款样本300个.我们设置学习率为0.3,batchsize为20. 表3所示本文方法在ATM数据集上的实验结果.

表3 C3D 模型在 ATM 数据集的准确率
我们可以看出,在迭代次数为1500次的时候,准确率最高达到了96.8%. 此外,我们也采用STIP(HOG)方法对ATM数据集进行了验证,选取效果最好的准确率,将结果与本文方法作为对比,如表4所示.

表4 本文算法与 STIP 比较
通过表3和表4可以看出,我们提出的算法在ATM数据集上的表现也要好于STIP算法,因此,本文的算法在暴力行为检测中要优于文献提出的三种手工设计特征: STIP(HOG),STIP(HOF),MoSIFT.
3 结语
本文提出了一种基于3D-CNN的暴力行为检测方法,与传统的基于人工合计特征的暴力行为检测相比,本文基于3D卷积神经网络自动提取时空特征,检测效果要好于手工设计的特征,也要好于2D维度的CNN模型. 另外,本文方法还对不同模型的组合进行了对比实验,实验结果表明合适的模型组合能有效地提高检测准确率. 随着相关视频数据的增长,基于3D-CNN的方法在检测精度方面将更具优势.
1胡琼,秦磊,黄庆明. 基于视觉的人体动作识别综述. 计算机学报,2013,36(12): 2512–2524.
2郑胤,陈权崎,章毓晋. 深度学习及其在目标和行为识别中的新进展. 中国图象图形学报,2014,19(2): 175–184.
3Nam J,Alghoniemy M,Tewfik AH. Audio-visual contentbased violent scene characterization. Proc. of 1998 International Conference on Image Processing. Chicago,IL,USA.1998. 353–357.
4Nievas EB,Suarez OD,García GB,et al. Violence detection in video using computer vision techniques. Proc. of the 14th International Conference on Computer Analysis of Images and Patterns. Seville,Spain. 2011. 332–339.
5Martin V,Glotin H,Paris S,et al. Violence detection in video by large scale multi-scale local binary patterns dynamics. MediaEval 2012 Workshop. Pisa,Italy. 2012.
6Hassner T,Itcher Y,Kliper-Gross O. Violent flows: Realtime detection of violent crowd behavior. Proc. of 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. Providence,RI,USA. 2012.1–6.
7Wang H,Kläser A,Schmid C,et al. Action recognition by dense trajectories. Proc. of 2011 IEEE Conference on Computer Vision and Pattern Recognition. Colorado Springs,CO,USA. 2011. 3169–3176.
8Geng YY,Liang RZ,Li WZ,et al. Learning convolutional neural network to maximize Pos@Top performance measure.arXiv:1609.08417,2016.
9Li QF,Zhou XF,Gu AH,et al. Nuclear norm regularized convolutional Max Pos@Top machine. Neural Computing and Applications,2016: 1–10,doi: 10.1007/s00521-016-2680-2.
10Ji SW,Xu W,Yang M,et al. 3D convolutional neural networks for human action recognition. IEEE Trans. on Pattern Analysis and Machine Intelligence,2013,35(1):221–231. [doi: 10.1109/TPAMI.2012.59]
11Karpathy A,Toderici G,Shetty S,et al. Large-scale video classification with convolutional neural networks. Proc. of the IEEE Conference on Computer Vision and Pattern Recognition. Columbus,OH,USA. 2014. 1725–1732.
12Tran D,Bourdev L,Fergus R,et al. Learning spatiotemporal features with 3D convolutional networks. Proc. of 2015 IEEE International Conference on Computer Vision. Santiago,Chile. 2015. 4489–4497.
Violence Behavior Detection Based on 3D-CNN
ZHOU Zhi,ZHU Ming,Yahya Khan
(School of Information Science and Technology,University of Science and Technology of China,Hefei 230022,China)
A large number of research behavioral methods are focused on detecting simple actions such as walking,jogging,or jumping,while less research is on violence or aggressive behavior,but these studies are useful in some surveillance scenarios,such as: Prison,self-help banks,shopping malls and so on. Traditional methods of violent behavior recognition research mainly use a priori knowledge to manually design features. In this paper a violence detection method based on 3D-CNN structure is proposed. The three-dimensional deep neural network directly manipulates on the input,which can be a good extraction of violent behavior of time and space characteristics of information. It can be seen from the experimental results that this method can identify the violent behavior better than the characteristics of hand-craft features.
action recognition; violent detection; deep learning; convolution neural network
周智,朱明,Yahya Khan.基于 3D-CNN 的暴力行为检测.计算机系统应用,2017,26(12):207–211. http://www.c-s-a.org.cn/1003-3254/6152.html
中科院先导项目课题(XDA06011203)
2017-03-18; 修改时间: 2017-04-10; 采用时间: 2017-05-08
