基于推文与属性的社交网络用户重识别方法①
2018-01-08高伟,张敏
高 伟,张 敏
1(中国科学院大学,北京 100049)
2(中国科学院 软件研究所,北京 100190)
基于推文与属性的社交网络用户重识别方法①
高 伟1,2,张 敏2
1(中国科学院大学,北京 100049)
2(中国科学院 软件研究所,北京 100190)
大数据隐私安全正成为各界关注的热点. 攻击者通过识别用户不同网站的账户,可以构建用户的完整画像,对用户隐私形成威胁. 模拟评估攻击者的重识别能力是进行用户隐私保护的前提. 因此,本文提出一种高相似同天同行为算法. 该算法通过检测账户在不同网站是否存在多次同天发表相近或相同内容的行为,判断账户是否属于同一用户,并通过为用户属性构建一种权重计算模型,进一步提高用户重识别的准确率. 经过对两个国内主流社交网站的一万多用户进行实验,本文算法表现出良好的效果. 实验表明,即使不考虑用户社交关系,用户的推文与属性依然提供了足够的信息使攻击者将用户不同网站的账户相关联,从而导致更多的隐私被泄露.
社交网络; 用户重识别; 推文; 属性; 相似度
1 引言
目前社交网络已广泛普及. 截止2016年,全球最大社交网站facebook月活跃用户数已突破16.5亿,新浪微博、QQ月活跃用户分别突破了3.9亿、8.5亿,社交网络的迅猛发展为社会带来了巨大机遇. 在社交网络上,每天有大规模数据产生,如推文内容、签到信息、照片等. 随着“云计算”和“大数据”技术的不断深入,众多研究机构、高校、互联网公司开始广泛搜集这些碎片化信息,通过对这些大规模数据的建模分析,可以了解用户多维度的的画像,如购物习惯、兴趣爱好等,以此进行广告精准投放或者好友推荐等,具有极大的商业价值和实用价值.
但这同时也带来了用户隐私泄露的威胁. 攻击者采集用户不同网站的信息,通过对这些信息的链接并加以建模抽象,可构建用户的完整画像. 当攻击者对这些信息进行非法利用时,会严重破坏用户的隐私,甚至直接威胁到用户的人身财产安全. 因此,保护用户隐私就显得相当重要. 在此情形下为保护用户隐私,需首先了解,攻击者判定来源于不同社交网站的账户属于同一人所采用的技术手段,即用户重识别技术.
用户重识别就是通过采集多个社交网站的数据,通过对这些公开数据的比对,来识别用户不同网站账户的一种技术. 目前,用户重识别技术正受到国内外前所未有的关注. 2009年Jan[1]分别采用不同精度的匹配方法对Facebook和StudiVZ社交网站的用户姓名、生日、性别、高中、地址等进行了相似度计算,并结合权重完成了用户的重识别工作. 2013年Goga[2]提出了基于多社交网站大规模账户的相关性识别算法. 分别采用Jaro Distance、哈希感知算法等对用户姓名、用户头像及其他属性进行了相似度计算,最后采用机器学习方法进行用户的匹配. 2013年Goga[3]根据用户推文的地理位置、发表时间和内容风格对Twitter、Flickr、Yelp的用户展开重识别研究. 2014年Cecaj[4]根据用户电话记录与推文记录的发生时间差∆t和距离差∆s,对某地区的用户进行重识别. 基于社交关系的用户重识别主要根据用户在不同的社交网络有着相似的朋友圈这一经验,通过选定部分已知种子匹配用户,根据网络拓扑关系、图结点的度数等进行用户的重识别研究. 如2009年Narayanan[5]提出的基于种子匹配的重识别算法,2016年Zhou[6]提出的基于好友相似度的重识别算法FRUI. 2012年Bartunov[7]利用用户属性和社交关系综合计算了Facebook和Twitter的用户相似度.2013年Kong[8]将用户的发推地理位置变化规律、时间变化规律、推文内容关键字出现频率相结合,完成用户的匹配工作. Fu[9]利用用户属性、社交关系,采用图结点算法进行了用户重识别研究.
以上方案基于不同特征对用户重识别进行了研究,但在推文方面,用户重识别的准确率还较低,利用用户发布的大量推文进一步提高准确率仍有很大探索空间.此外,用户属性包含着一个人的重要信息,对用户重识别具有一定的意义. 然而随着社交网络的不断发展,用户的安全意识越来越强,很多用户的关键属性信息被隐藏,为这些仅存的属性信息构建权重计算模型,面临着较大的困难.
为解决以上问题,本文提出一种高相似同天同行为算法. 该算法通过检测账户在不同网站是否存在多次同天发表相近或相同内容的行为,判断账户是否属于同一用户. 此外,为利用用户属性进一步提高重识别准确率,本文构建了一种属性权重计算模型. 为评估所提算法的性能,本文以国内两个主流的社交网站(以下简称“Q”、“R”)作为实验对象,分别采集了 Q 网站的16173个用户的300余万推文、R网站的10027个用户的70余万推文,经人工标注了776对真实匹配用户.实验表明,本文所提算法有着良好的效果,明显优于其他模型.
2 用户重识别方法
本文提出的用户重识别方法主要基于用户发表的推文与用户属性,并在此基础上,将二者结合进行用户重识别. 首先,定义以下基本符号.
2.1 符号定义
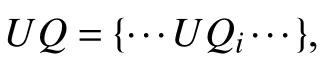

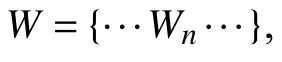
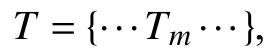

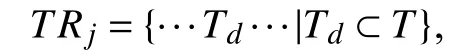
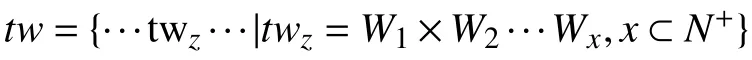
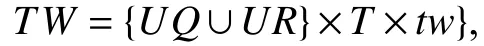
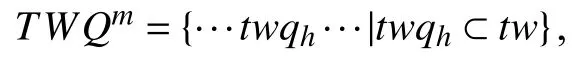

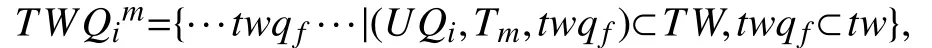

2.2 基于推文的用户重识别方法
推文内容与用户联系紧密,不同的用户其推文内容也显示出较大差异,因此在一定程度上,推文内容可以反映用户特征、代表用户身份. 基于推文的用户重识别方法包括四部分. 1) 推文向量及相似度计算方法.通过word2vec[10,11]工具训练获得每个词的向量,然后将推文中词的向量累加得到推文的向量,推文相似度采用推文向量夹角的余弦值来表示. 2) 高相似同天同行为计算方法. 很多用户都有在同一日期于不同社交网站发表相似推文的经历,因此在一定意义上,高相似的推文对可以为用户重识别提供线索. 该方法正是基于此思想,发现具有相同发推日期的高相似推文对. 3)热点事件处理方法. 在一些特殊节日、热点事件时,大量相似的推文会同时出现于不同的社交网站,将严重影响用户的重识别结果,因此该方法根据一定条件对与热点事件有关的推文记录进行删除,以降低其负面影响. 4) 高相似多推文计算方法. 用户在两个社交网站的推文在整体上具有一致的情感、用词习惯等,所以对于不同网站的账户,可以根据它们推文的整体相似度,展开用户重识别的研究工作.
2.2.1 推文向量及相似度计算方法
为计算推文相似度,需要首先将推文内容使用数字向量表示. 因此,推文相似度的计算就转化为数字向量的计算. 根据推文的特点,本文将按照图1所示流程进行推文向量的计算.
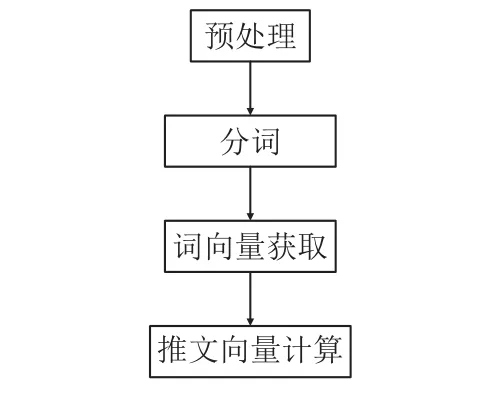
图1 推文向量计算图
预处理: 去除推文中的乱码、符号. 如果推文只包含乱码或者符号等非文字性语言,则不做处理.
分词: 采用ICTCLAS分词工具将推文分为单独的词.
词向量获取: 从已训练好的词向量表中获取对应词的数字向量. 该表中的词向量是利用Google的开源工具word2vec,经过对20G大规模维基百科语料训练而成,其包含每个词的50维度语义向量.
推文向量计算: 推文由词组成,其中每个词的向量为:
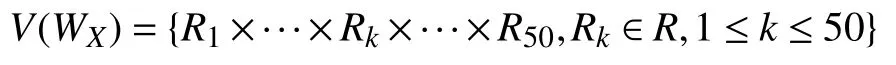
推文的向量由各个词的向量累加而成,即:
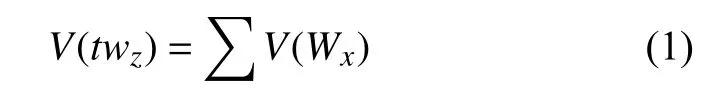
本文曾将每条推文看作一个文本,所有推文看作文档总数据集. 利用TF-IDF算法计算每个词在对应推文中的权重,将权重乘以对应词的向量得到该词在推文中的语义向量,然后将推文中所有的词向量累加,得到该推文的向量. 但在后续实验中,其效果与直接将词向量累加得到的推文向量所进行的实验效果几乎一致.经分析,其原因可能有以下两种: 1) 大部分推文属于短文本,用户在不同网站同天发表相近含义的推文时,用词基本一致,极少部分用词不一致的相似推文也只是一些非关键词不同,对用户重识别的影响很小. 2) 如果推文属于长文本,用户往往在另一个网站发表的是该推文的拷贝版本,二者完全相同. 所以,出于算法与系统的整体效率考虑,本文采用将词向量直接累加的结果来表示推文向量.

2.2.2 高相似同天同行为计算方法
为开展Q与R网站用户的重识别工作,定义以下概念:

(3) 高相似次数: 用户UQi与URj具有的高相似同天同行为推文对的总次数,称为该用户对的高相似次数.
基于推文的用户重识别研究方法需要首先计算Q网站每个用户UQi与R网站所有用户的高相似同天同行为,其原理如图2所示.
图2中白色部分与灰色部分对称,分别表示Q、R网站的推文信息. 其中白色部分从左至右的每一列分别表示: Q网站用户发推日期Tx列表、日期Tx对应的推文集合TWQx列表、推文集合TWQx包含的推文twqh列表. 其中“×”表示对推文集合计算笛卡尔积,然后计算结果集中每个推文对元素的相似度. 完成以上计算后,判断该推文对元素是否属于高相似同天同行为,是则保存,否则丢弃.
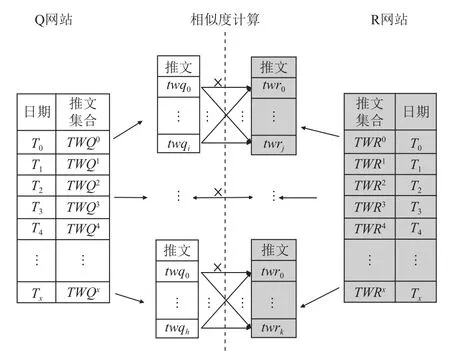
图2 所有用户的高相似同天同行为计算图
其伪代码算法如下:
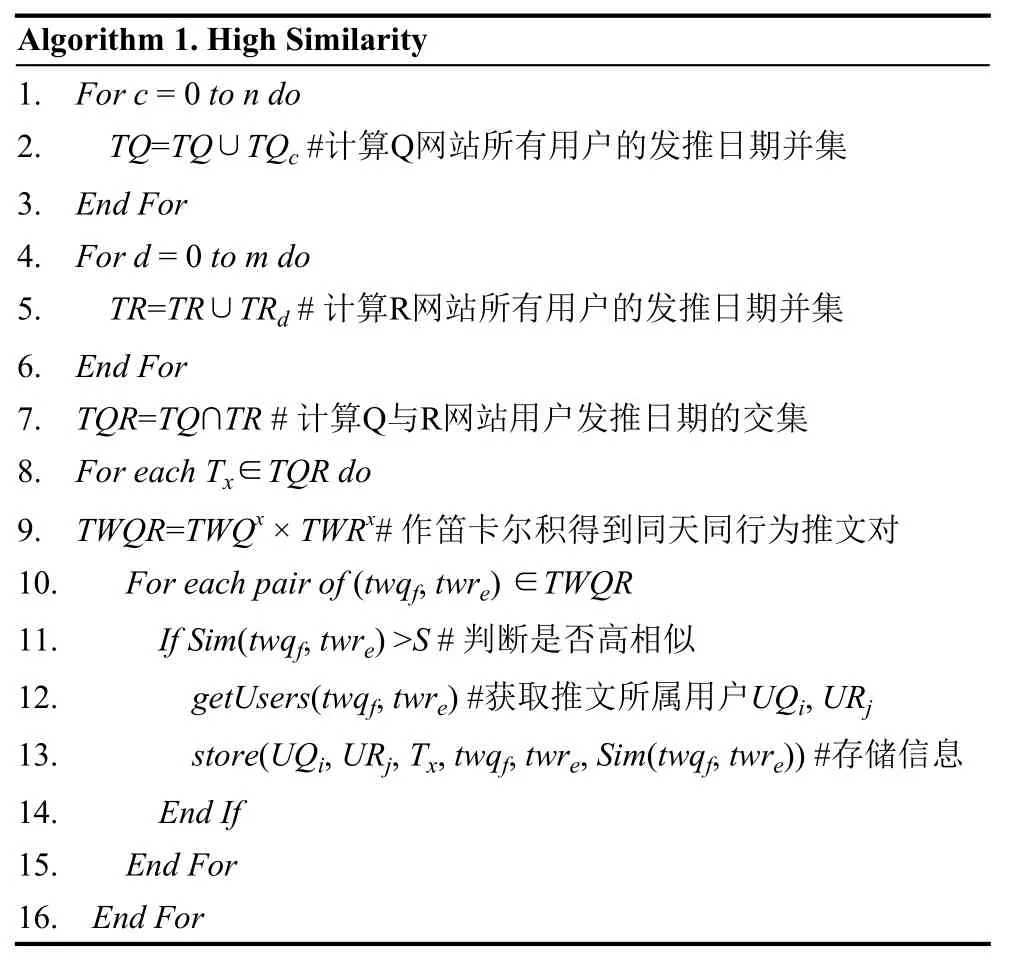
Algorithm 1. High Similarity 1.For c= 0to n do2. TQ=TQ∪TQc#计算Q网站所有用户的发推日期并集3.End For4.For d= 0to m do5. TR=TR∪TRd# 计算R网站所有用户的发推日期并集6.End For7.TQR=TQ∩TR# 计算Q与R网站用户发推日期的交集8.For each Tx∈TQR do9.TWQR=TWQx×TWRx# 作笛卡尔积得到同天同行为推文对10. For each pair of(twqf,twre) ∈TWQR11. If Sim(twqf,twre) >S# 判断是否高相似12. getUsers(twqf,twre) #获取推文所属用户UQi,URj13. store(UQi,URj,Tx,twqf,twre,Sim(twqf,twre)) #存储信息14. End If15. End For16.End For
经过以上计算,即可得到Q网站的每一个用户UQi与R网站所有用户的高相似同天同行为.
2.2.3 热点事件处理方法
在特殊节日、热点事件时,很多用户都会发表含义相近的推文于不同网站. 在这种情形下,一个用户会与很多用户存在高相似同天同行为,而大部分用户是非真实匹配用户. 如果以此为基础,根据用之间的高相似次数决定匹配用户,其结果很有可能是不准确的,同时这些过多的干扰数据,也会给系统的运行带来压力,增大损耗. 如图3所示的真实案例.
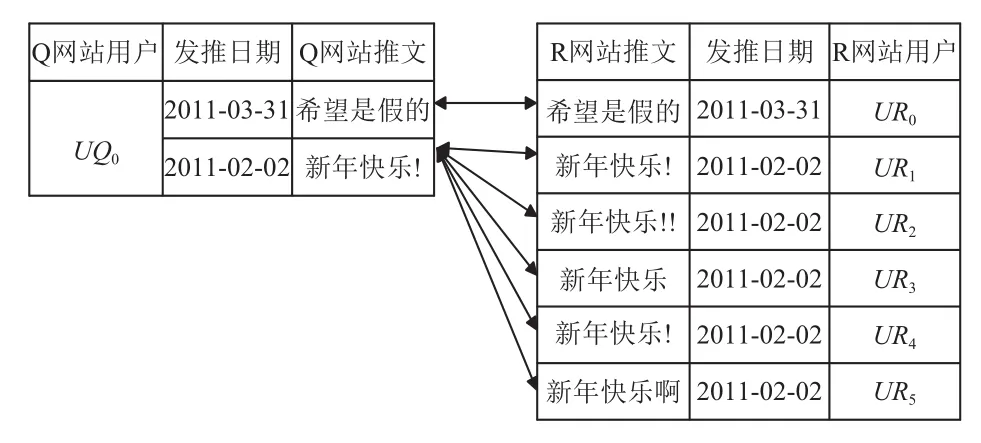
图3 用户UQ0经高相似同天同行为方法计算后的结果表
由图可知,Q网站用户UQ0共有两条推文产生高相似同天同行为,对应R网站的6个候选匹配用户,且高相似次数都为1. 按照常理判断,其最可能的匹配用户应该是UR0. 因为UR0与UQ0对应的高相似推文相对其它推文,出现率较低. 且其余候选匹配用户的发推日期均相同,推文互相之间也都是高相似的,所以对应的推文极有可能描述的是同一热点事件. 如果不对该类推文进行处理,算法随机选择匹配用户,能准确识别的概率仅为1/6,但如果将该类推文记录删除,算法就能准确识别UQ0的匹配用户.
因此,对热点事件进行处理很有必要. 首先需要明确热点事件的判定条件. 一般从网络角度而言,所谓热点事件,就是有大量网民都在同一时间段内发表有关该事件的推文、评论等. 所以,对于推文twz,判定其属于热点事件的条件为,由其产生的候选匹配用户数|CandidateUsersz|大于某个系数时,即可判定该推文属于热点事件. 即:

α: 热点事件系数(取值将在后续实验中确定). 含义: 如果发表于日期Tm的推文twz产生多于α个候选匹配用户,则该推文描述的内容属于热点事件.
当判定一条推文属于热点事件后,还需判定其是否满足相应处理条件,才能决定是否将其删除,否则可能会降低用户重识别结果的准确率. 例如: 假设图3中的用户UR0没有在2011-03-31发表如上推文,而是也在 2011-02-02 发表了类似“新年快乐”的推文. 此时,用户UQ0的候选匹配用户还是6个,都由推文“新年快乐!”产生,高相似次数也都为1,如果此时该推文满足热点事件的判定条件,将对应推文记录删除,则用户UQ0没有了匹配用户. 很明显,相对于删除前,算法的准确率反而有所下降. 因此,对于热点事件进行处理还需满足相应的处理条件.
假设Q网站用户UQi经过高相似同天同行为方法计算后,他在日期T0到Tm发表的推文产生了高相似同天同行为,且由这些推文产生的候选匹配用户对应的高相似次数分别为:
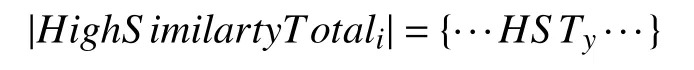
于日期Tx(0≤x≤m)发表的推文twz产生的候选匹配用户对应的高相似次数分别为:

当以上高相似次数满足如下条件时,推文twz对应的高相似记录应该被删除. 即:
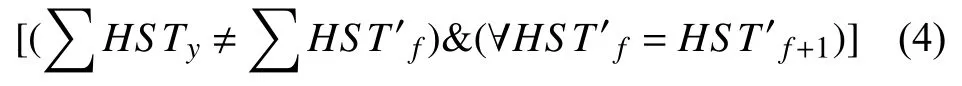
以上式子中左侧括号( )表示,由推文twz产生的候选匹配用户的高相似次数之和不等于用户UQi所有候选匹配用户的高相似次数之和,即除了推文twz产生候选匹配用户外,还有其他推文也产生了候选匹配用户; 右侧括号 ( )表示,由推文twz产生的候选匹配用户的高相似次数两两相等. 当以上两个条件都成立时,才可对推文twz的相应记录执行删除操作. 因为此时,由推文twz产生的候选匹配用户的高相似次数均相等,且除了该推文外,还有其他推文也产生了高相似同天同行为,所以执行删除操作后,不仅提高了算法的识别准确率,还有效降低了因这些干扰数据带来的系统损耗,提升了系统的整体运行效率.
经过高相似同天同行为计算方法、热点事件处理方法操作后,即可得到Q网站每个用户UQi与其候选匹配用户的高相似次数.
2.2.4 高相似多推文计算方法
Q与R网站属于类似的社交网站,用户经常在上面发表与生活、工作相关的推文. 因此如果两个网站的某用户属于同一个人,则他们于各自平台上的推文在整体上会展现出相似的情感、用词习惯、行文风格等特征.
根据调研,Q与R网站用户的人均推文数都较少,大部分用户的推文数小于50条,而每条推文的字数也很少,所以一个用户的推文总字数也相对不多,经统计,一般在500-2000之间. 推文的风格与用户的性格、发推时的心情、兴趣爱好有很大关系,所以推文的格式也比较零散、随意,且每条推文所表示的含义也不尽相同. 因此,如果将每个用户的所有推文看作一个整体,很难通过提取一个明确的主题来表示用户. 而word2vec工具在训练词向量时,充分的考虑了上下文,所以在一定意义上,词向量综合了该词多方面的因素.因此,根据推文特点,本文将对用户所有推文的词向量进行累加,将所得结果称为用户的多推文向量. 用户的相似度采用多推文向量的相似度表示,具体计算方式如下所示.
假设Q网站用户UQi与R网站用户URj的推文集合分别为:

则UQi与URj的多推文相似度为:
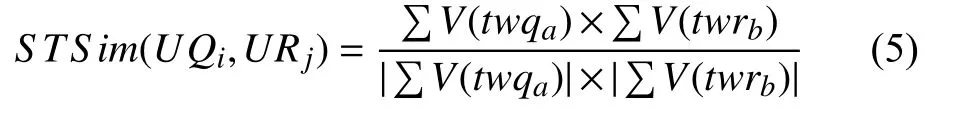
根据高相似次数、多推文相似度在重识别用户时所占的重要程度,分别赋予不同的权重,通过综合计算得到用户之间的相似度. 然后选择与用户UQi相似度最大的用户,作为其匹配用户.
2.3 基于属性的用户重识别方法
用户属性往往包含着一个人的重要信息,它在用户重识别领域扮演着重要角色. 本文将利用同时存在于Q与R网站的属性: 昵称、性别、生日、情感状态、家乡、所在地展开用户重识别研究. 其主要步骤如图4所示.
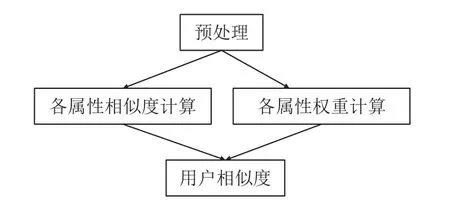
图4 基于属性的用户相似度计算流程图
预处理: 将属性处理为统一格式,如生日: yyyymm-dd、家乡: **省**市
各属性相似度计算:
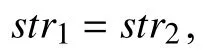
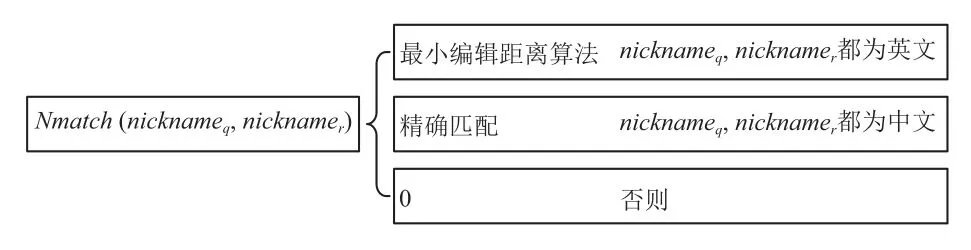
图5 昵称相似度计算规则图
对于英文昵称,由于其代表含义广泛,且很多属于用户自创,难以根据语义进行相似度度量. 因此本文采用流行的最小编辑距离算法计算其相似度. 对于中文昵称,由于Q网站的用户昵称往往非真实姓名,而R网站属于实名制社交平台,用户昵称往往是真实姓名,因此,二者相似度可比较性较小,本文采用精确匹配进行比较. 对于其它格式的昵称,本文不进行比较,将其相似度置为0.
(2) 性别、生日、情感状态、家乡、所在地: 由于这5项属性均由用户通过下拉列表选择,所以经过预处理后,均具有统一的格式. 因此,本文将采用精确匹配的方式计算其相似度.
各属性权重计算:
由于每个社交网站的定位不同,所以其开放程度也不同. 而开放程度的不同将直接影响用户属性填写的完整程度. 如微博是开放的社交网站,任何人均可访问其他用户的属性页面,所以出于隐私保护的目的,用户将生日、身份证号码等敏感属性选择空置或者隐藏,因此这些属性的填写率很低; 而像如昵称、性别等与用户隐私程度关联不密切的属性,填写率会相对较高.据此猜想: 一个社交网站中,如果用户的某项属性填写率越低,则说明该属性的隐私程度越高,在标识其身份的唯一性时,所占权重应该越大. 根据此猜想,用户各属性权重模型的构建,可分为以下三个步骤:
① 选择社交网站用户数据集;
② 统计各属性填写率;
③ 计算各属性权重——填写率倒数和归一化.
表1以R网站的数据集(共10027个用户)为例,计算各属性权重.

表1 R 网站的属性权重计算表
表1中,共包含6种属性,第二行的数字代表填写了对应属性的用户数,第三行表示经过计算后,每种属性的归一权重. 其中,各属性的归一权重计算方式如下:
① 填写率倒数和归一化,即:
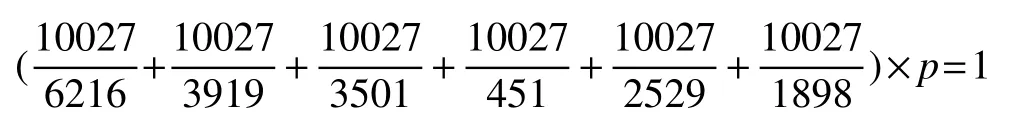
② 求得p,然后将属性填写率的倒数与p进行乘积计算,结果即为该属性的归一权重.
用户相似度:
根据以上内容,可求得每对属性的相似度大小及各属性在标识用户身份唯一性时所占的权重. 则基于属性的用户相似度可表示为:
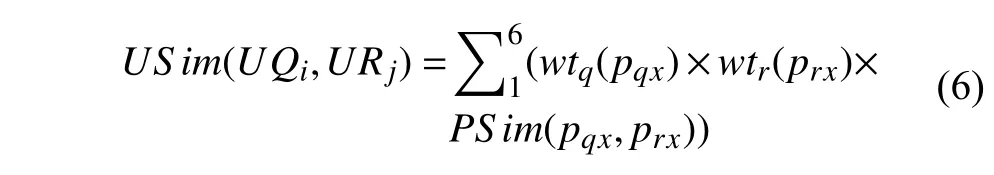

基于属性的用户重识别研究正是基于以上方法,计算Q网站的每个用户UQi与R网站的所有用户之间的相似度,然后将UQi的候选匹配用户按照相似度大小进行排序,选择排序最高者作为UQi的匹配用户.
2.4 基于推文与属性相结合的用户重识别方法
前面章节分别叙述了基于推文、属性进行用户重识别的详细方法. 本节将推文与属性相结合,共同进行跨社交网站的用户重识别研究.
在基于推文的用户重识别中,如果两个来自不同社交网站的用户在同一日期发表的推文属于高相似同天同行为,且推文内容与热点事件无关,则他们很可能属于同一人,而当这样的事件多次发生时,则他们属于同一人的概率几乎接近于1. 而多推文相似度虽然在一定程度上可以代表用户相似度,但也存在明显缺陷,例如一个用户的Q网站推文很多,而R网站推文很少,则它们的多推文向量将相差很大,所以较难取得准确匹配. 而在属性方面,由于同时出现于两个网站的各属性在标志用户身份的唯一性时,权重均很低,且在这6项属性中,很多用户会具有多项相同属性,所以单独使用属性进行用户重识别研究也难以取得良好效果.
因此,将推文与属性相结合进行用户重识别的研究,高相似次数对匹配结果的准确率贡献很大,而多推文相似度与基于属性的用户相似度贡献都较小. 因此,当计算用户之间的相似度得分时,本文将分别赋予它们0.8、0.1、0.1的权重,以表示它们在衡量用户相似度时的贡献. 因此当高相似次数为0时,用户之间的相似度理论上最大是0.2,这一值在衡量用户的相似度时,说服力很小. 所以本文将只对用户之间的高相似次数大于0的用户对计算相似度得分,然后将每个UQi用户的候选匹配用户按照分值大小进行排序,选择排序最高者作为UQi的最终匹配用户.
3 实验结果与分析
3.1 数据集
为评估所提算法的效果,本文以国内流行的社交网站Q、R作为实验对象. 首先对其进行数据采集,并人工标注真实匹配用户对,根据上述的用户重识别算法进行实验,统计识别结果中真实匹配用户的对数,以验证本文所提算法的可行性和有效性. 由于多推文相似度、基于属性的用户相似度在单独进行用户重识别时,效果较差,所以本文将它们与高相似同天同行为计算方法、热点事件处理方法相结合进行用户的重识别实验.
经调研,Q网站的主要用户群是18-28岁的年轻人,R网站则主要是大学生、研究生及部分白领等. 因此,几乎每个R网站的用户均同时拥有Q网站的账户,所以它们非常适合作为用户重识别实验的数据来源.根据需求,本文采集的数据主要包含两部分: (1) 推文信息; (2) 用户属性.
(1) 推文信息: 推文一般包含四类: 原创文字推文、原创多媒体推文、转发文字推文、转发多媒体推文.一般而言,原创推文在一定意义上唯一标识了用户身份,因此在推文方面,本文只采集原创文字推文与附带的发表日期.
(2) 用户属性: 在属性方面,本文只采集同时出现于两网站的6种属性: 昵称、性别、生日、情感状态、家乡、所在地. 其中,昵称由用户自创,可包含图形、表情、文字、特殊符号等. 而其余5项均通过下拉列表选择填入,具有固定的格式.
本文采用广度优先策略,通过爬虫进行数据采集.从种子用户开始,首先抓取其自身数据,再抓取其好友的数据,然后再抓取其好友的好友数据,通过该种子用户不断的向外延伸,访问不同的用户. 抓取的数据总量如表2所示,Q网站用户共抓取了16173个,以及这些用户的300余万原创文字推文,R网站用户共抓取了10027个,推文约75万. R网站推文数较少的原因可能有两点: (1) 近些年,R 网站业绩不断下滑,导致用户使用率较低; (2) 用户只在上学时使用 R 网站,一般年限为 3-7 年,而之后便不再使用. 在 R 网站中,大部分用户的主页是开放的,任何人均可访问. 而在Q网站中,大部分用户的空间设置了访问等级,如只对自己开放、只对其好友开放等,所以对于种子用户,其好友的空间往往可以访问,而其好友的好友空间,只有部分可以被访问,所以在采集的数据中,真实匹配用户数量较少,仅有人工标注的776对.

表2 数据集总量统计表
Q与R网站用户的单条推文长度与推文数一般都较小. 如由图6可知,长度为10-20个字的推文占比最大,且随着长度的增加,相应推文逐渐减少,当推文长度大于70时,相应推文变多,其原因是此统计数包含了长度大于70的所有推文. 因此可知,Q与R网站推文大部分都是短文本,不适合使用LDA等模型表示推文,所以本文以词向量累加的方式计算推文向量. 此外,Q网站推文的平均长度均大于R网站推文,其原因可能是: 相较于R网站,Q网站私密性更强,用户更愿意将推文发表于Q网站. 由图7可知,推文数小于50条的用户占比最大,且随着推文数的增加,相应用户逐渐减少. 经过对两图的综合统计可知,一个用户的原创推文总字数一般在500—2000左右. 且这些推文包罗万象,没有明确主题,所以很难通过对这些文字的总体建模,实现良好的用户重识别效果. 因此本文选择对单条推文进行研究,以克服这一困难.
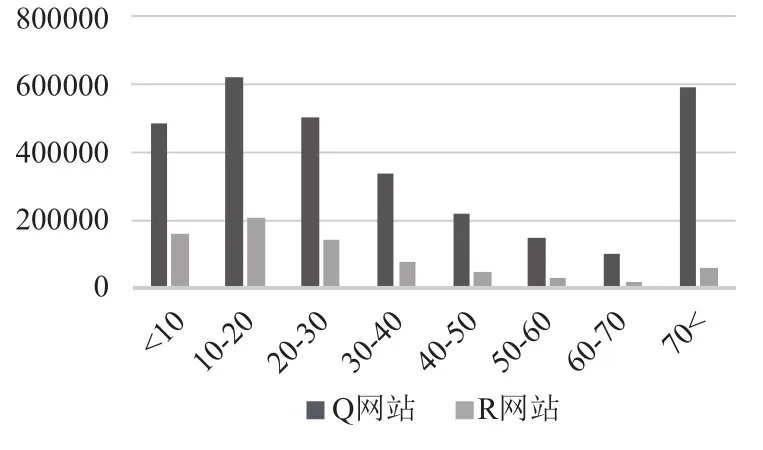
图6 每条推文字数统计图
图7 每个用户推文数统计图
图8 用户属性填写率
由于涉及隐私,导致每个用户对待属性的态度不同,因此填写情况也不同. 图8是用户属性填写率的统计图. 由于网站原因,爬虫只获取到Q网站的部分用户昵称,所以导致其填写率很低,而实际每个用户均有昵称,其填写率本该为1. 对于Q网站的用户生日,网站默认将未填写的用户生日置为1970-01-01,所以其填写率在统计时为1. 由于基于属性的用户重识别方法核心是计算每对属性的相似度,其可计算性由该对属性中填写率最低的那一项决定,而由图可知,各项属性的最低填写率都很低,且这6项属性都难以标识用户身份的唯一性. 因此只通过属性进行用户重识别的研究很难取得良好效果.
3.2 实验结果
根据热点事件的原理可知,热点事件系数是独立的,当数据集越大,得到的值越准确. 因此,本文使用全部数据集进行实验. 经实验发现,当热点事件系数取值为 4 时,准确识别数取得最大值,因此,本文将热点事件系数取值为4.
为确定相似系数的取值,本文分别选取包含100、500对真实匹配用户的数据集,使相似系数S从1以0.01的幅度依次递减至0.90进行实验,观察经多种处理后的准确识别数的变化趋势,实验结果如图9、10所示. 在图中,高相似表示只经过高相似同天同行为方法计算后的结果; 热点表示经过高相似、热点事件处理后的结果; 多推文表示经过高相似、热点、高相似多推文计算后的结果; 属性表示经过高相似、热点、多推文、基于属性的相似度计算后的结果.
图9 多种处理后准确识别数变化图(100对用户)
图10 多种处理后准确识别数变化图(500对用户)
由图9、10可知,当数据集分别包含100、500对真实匹配用户,相似系数取值 0.93、{0.94,0.93}时,准确识别数都达到了最大值,说明相似系数的取值不会随着数据规模的扩大而发生显著变化,均能在其取值为0.93时,使的准确识别数达到最大值. 因此,本文的相似系数S取值为0.93.
由上图还可得知,当相似系数取值不低于0.96时,热点事件处理方法、高相似多推文计算方法对准确识别数的提升效果较小,但当相似系数小于0.96时,它们对准确识别数的提升效果明显,尤其是多推文处理. 说明它们对重识别的效果有着良好的影响. 属性计算方法在相似系数变化的整个过程中,一直对重识别的结果有着积极作用.
在确定了各项系数的取值后,本文与Goga[3]的方法进行了对比. Goga根据推文的地理位置、发表时间、内容风格分别进行了用户重识别研究,由于本文数据不包含推文的地理位置,因此本文与Goga均只综合其余两项特征完成实验. 实验结果如图11至图14所示.图中本文方法简记为“HS”,Goga 方法简记为“Goga”.
图11、12是设定了相似系数S=0.93,准确率和召回率随高相似次数HST的变化图.
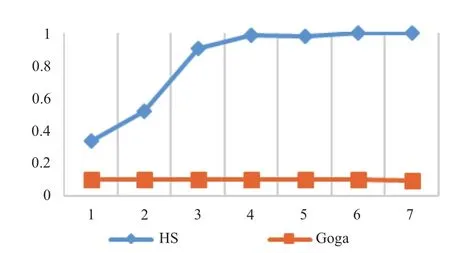
图11 准确率随高相似次数HST的变化图(S=0.93)

图12 召回率随高相似次数HST的变化图(S=0.93)
由图11、12可知,当相似系数取值 0.93时,本文方法的准确率迅速上升,当高相似次数HST=3时,准确率达90%,当高相似次数HST≥6时,准确率达到了100%,明显优于Goga. 但随着高相似次数HST的不断增加,本文方法的召回率也明显下降,当高相似次数HST=1 时,召回率最高,达到了 70.12%,此后下降趋势逐渐缓和. 当高相似次数HST≥4后,召回率低于Goga.
图13、14是设定了高相似次数HST≥3,准确率与召回率随相似系数S的变化图.
由图13、14 可知,当高相似次数 HST≥3,本文方法的准确率保持较高,均达到了90%以上,当相似系数S≥0.98时,准确率达到了100%,此后随着相似系数的减小,准确率也缓慢下降,整个变化过程明显优于Goga. 本文方法的召回率随着相似系数的增大一直趋于上升趋势,当相似系数 S≥0.94 时,Goga 的召回率优于本文方法,随着相似系数的减小,当 S≤0.93 后,本文方法的召回率优于Goga.

图13 准确率随相似系数 S 的变化图(HST≥3)

图14 召回率随相似系数 S 的变化图(HST≥3)
4 结语
针对社交网络领域的个人隐私保护问题,本文提出了一个基于推文与属性的高相似同天同行为用户重识别算法,其提出的多种方法可有效提高算法的准确率. 经过Q与R网站的1万多用户、300多万推文进行实验评估,该算法的准确率为33.84%,召回率为70.12%,明显优于Goga的方法. 且该算法可实现用户的精确重识别. 实验还揭示了当用户在不同网站发表相近或相同的内容达到3次及以上时,可以为攻击者提供足够的信息,将其不同网站的账户相关联,从而导致更多的隐私被泄露. 本文的研究方法有多个应用领域: (1) 隐私安全研究; (2) 广告精准投放; (3) 社交网站好友推荐等.
1Vosecky J,Hong D,Shen VY. User identification across multiple social networks. Proc. of the 1st International Conference on Networked Digital Technologies. Ostrava,Czech Republic. 2009. 360–365.
2Goga O,Perito D,Lei H,et al. Large-scale correlation of accounts across social networks [Technical Report]. TR-13-002. Berkeley,California,USA: International Computer Science Institute,2013.
3Goga O,Lei H,Krishnan SH,et al. Exploiting innocuous activity for correlating users across sites. Proc. of the 22nd International Conference on World Wide Web. Rio de Janeiro,Brazil. 2013. 447–458.
4Cecaj A,Mamei M,Bicocchi N. Re-identification of anonymized CDR datasets using social network data. Proc. of the 2014 IEEE International Conference on Pervasive Computing and Communications Workshops (PERCOM Workshops). Budapest,Hungary. 2014. 237–242.
5Narayanan A,Shmatikov V. De-anonymizing social networks. Proc. of the 30th IEEE Symposium on Security and Privacy. Washington,DC,USA. 2009. 173–187.
6Zhou XP,Liang X,Zhang HY,et al. Cross-platform identification of anonymous identical users in multiple social media networks. IEEE Trans. on Knowledge and Data Engineering,2016,28(2): 411–424. [doi: 10.1109/TKDE.2015.2485222]
7Bartunov S,Korshunov A,Park ST,et al. Joint link-attribute user identity resolution in online social networks. Proc. of the 6th International Conference on Knowledge Discovery and Data Mining,Workshop on Social Network Mining and Analysis. Beijing,China. 2012.
8Kong XN,Zhang JW,Yu PS. Inferring anchor links across multiple heterogeneous social networks. Proc. of the 22nd ACM International Conference on Information & Knowledge Management. San Francisco,California,USA. 2013.179–188.
9Fu H,Zhang A,Xie X. Effective social graph deanonymization based on graph structure and descriptive information.ACM Trans. on Intelligent Systems and Technology (TIST)-Regular Papers and Special Section on Intelligent Healthcare Informatics,2015,6(4): 49.
10Mihalcea R,Corley C,Strapparava C. Corpus-based and knowledge-based measures of text semantic similarity. Proc.of the 21st National Conference on Artificial Intelligence.Boston,Massachusetts,USA. 2006,1. 775–780.
11Islam A,Inkpen D. Semantic text similarity using corpusbased word similarity and string similarity. ACM Trans. on Knowledge Discovery from Data,2008,2(2): 10.
12Levenshtein VI. Methods for obtaining bounds in metric problems of coding theory. Proc. of the IEEE-USSR Joint Workshop on Information Theory (Moscow,1975). New York,USA. 1976. 126–143.
Method for Users Re-Identification across Social Networks Based on Tweets and Attributes
GAO Wei1,2,ZHANG Min2
1(University of Chinese Academy of Sciences,Beijing 100049,China)
2(Institute of Software,Chinese Academy of Sciences,Beijing 100190,China)
Big data Privacy security is becoming the hot spot in the various social industries,because attackers can build an integrate portrait to threaten privacy of users by identifying accounts in different sites. Simulation assessment of the attacker re-identification ability is the precondition of users’ privacy protection. Therefore,this paper proposes a high similarity algorithm in same day with same behaviors. The core idea of the algorithm is as follows: if a couple account issues similar or identical content on the same day,which also appears many times in different websites,then these two accounts may belong to a person with a high possibility. In addition,this paper builds a new weighting model for the users’ attributes to improve the accuracy of user re-identification. After the experiment on more than ten thousand users of the two major domestic social networking site,this algorithm proves to be effective. Experimental results show that even if attacker don’t consider users’ social relations,the users’ tweets,attributes,still provide enough information to make the attacker correlate their different accounts,which will lead to leak of more privacy.
social network; users re-identification; tweets; attributes; similarity
高伟,张敏.基于推文与属性的社交网络用户重识别方法.计算机系统应用,2017,26(12):94–103. http://www.c-s-a.org.cn/1003-3254/6101.html
国家自然科学基金重点项目(61232005); 国家自然科学基金(61402456)
2017-03-16; 采用时间: 2017-04-07
