基于MapReduce的商品品牌热度时空分析
2017-12-27陈厚铭
李 帅,陈厚铭, 盛 剑,樊 红*
(1. 武汉大学测绘遥感信息工程国家重点实验室,湖北 武汉 430079;2.中国烟草总公司贵州省公司,贵州 贵阳 365000)
基于MapReduce的商品品牌热度时空分析

李 帅1,陈厚铭2, 盛 剑2,樊 红1*
(1. 武汉大学测绘遥感信息工程国家重点实验室,湖北 武汉 430079;2.中国烟草总公司贵州省公司,贵州 贵阳 365000)
品牌热度分析是传统商业智能中的重要分析方法,不同品牌的商品销量空间分布特征对于商业决策具有重要的参考价值。面对大数据量和海量组合方式,计算性能瓶颈开始显现。传统的基于关系型数据库的简单数据分析手段难以处理大规模的商业数据,现有的基于MapReduce的大规模分布式计算引擎已经能够满足大数据并行处理的需求。为了解决以上问题,设计了基于HDFS的数据存储机制和MapReduce处理算法来解决品牌热度统计问题,实现对大体量离线商业数据的高效率品牌热度时空分析。
MapReduce;品牌热度分析;商业智能
随着各行各业数字化水平的提高,商业数据规模的爆炸性增长推动了大数据技术的迅速发展,利用并行计算来实现大体量商业数据有效挖掘以获得有价值的辅助商业决策的规则成为研究和应用的热点问题[1]。大数据和云计算技术的出现为商业智能提供了高效率、高可用性、高可拓展性的解决方案。Hadoop是Google MapReduce框架的一个开源实现,它提供了一个扩展性较强的针对大数据集分析的分布式文件存储和并行数据分析实现[2],已经成为我国工业界及学术界用来进行云计算的最标准平台[3]。品牌热度统计是商业智能中的一个重要方面,通过分析制定商品不同品牌在不同地域的销售情况,可以了解品牌销售的地域分布模式,从而提供商业决策支持。本文通过基于Hadoop系统的二次开发提出一种品牌热度统计问题的分布式存储和计算方案。
1 关键技术
1.1 Hadoop
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,由一个分布式文件系统(Hadoop Distributed File System,简称HDFS)和一个分布式计算模型(MapReduce)组成。Hadoop提供了很好的解决方案,使开发者能够利用低廉的硬件来搭建高吞吐量、高并行、高可用的大数据管理和处理系统[4]。
1.2 YARN
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是谷歌的Hadoop 2.x版本提出的一种新的通用资源管理器,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。YARN通过资源管理将作业调度和作业监控进行分离,大大提高了系统性能和可靠性[5]。
1.3 HDFS
HDFS即分布式文件存储系统,它是分布式计算的存储基础,具有高容错性,可以部署在普通的硬件设备上,用来存储海量数据集,并且提供了对数据读写的高吞吐率[6-8]。
1.4 MapReduce
MapReduce是Google公司2004年提出的一个并行编程模型,通过统一的资源管理将数据分割成若干份映射成为键值对,通过一个管理者(Master)向不同的工作者(Worker)进行任务分配,对任务进行并行处理,最后将结果通过Reduce进行归并,写到相应的输出文件中,如图1[9]。

图1 MapReduce执行过程概述[8]
2 Hadoop数据分析平台设计
利用服务器搭建有3个节点的Hadoop系统,同时按照数据安全性原则,对所抽取的商品销售数据进行3次备份,防止数据损坏造成的损失,系统架构如图2。

图2 系统架构图
基础支撑层提供系统的底层数据存储和分布式处理以及地图服务支持。主要利用Hadoop 2.7.2 和百度地图云服务。
数据层提供数据的存储支持,利用HDFS和HBASE对ETL处理后的卷烟销售数据和品牌热度数据进行存储;对于传统的关系型数据利用Oracle数据库进行存储;对于框架数据和门店GPS数据利用shape等空间文件格式进行存储。
应用支撑层主要提供了数据处理平台,包括针对分布式计算的MapReduce大数据处理引擎、针对统计分析的R数据挖掘、针对空间查询的百度云检索等。
应用层主要根据应用场景需求进行平台功能设计,利用SSH架构实现了数据展示、基础分析、统计分析、空间分析并制作了示范应用。
用户层提供了用户的访问界面,本平台的设计对象是商务数据的专业分析人员。
2 实验和实验成果
本文实验数据包括贵州省2010~2016年某行业销售数据,共计320 887 920条记录。品牌挖掘的实验主要包括两个步骤:数据预处理和挖掘程序的分布式运行。
2.1 数据预处理和HDFS导入
数据预处理包括数据清洗、数据提取和数据转换等工作。
首先需要构建数据表达模型,根据中文文本分类方法进行转化。目前中文文本分类方法可分为两种类型:第一种方法来自于机器学习理论,它根据文本的外在特征进行分类,是目前最主流的分类方法,通过构建向量空间模型通过向量运算进行求解。第二种是基于语义的分类方法[10]。本文采用将卷烟销售的事务数据处理成为文本数据,然后根据卷烟的品牌名文本特征对数据进行分类。由于销售数据主要通过扫码和手工录入,所以存在一部分的数据冗余、错误、残缺现象。针对文本研究目的,利用ODI(Oracle Data Integrator)在Oracle数据库平台上进行ETL和清洗,获得预处理数据记录260 842 856条、目标字段12个。为了适应MapReduce的处理要求,利用Java Map接口将数据从关系型数据处理为键值对(Key-Value)数据。本文研究的是不同品牌销量在空间地域上的分布情况,所以研究时需要进行3个指标的标定,分别是销售时间、销售地点、卷烟品牌名,利用品牌编号、销售地编码和卷烟编号这3个变量建立数据索引。数据预处理流程如图3。

图3 数据预处理
2.2 系统构建和程序运行
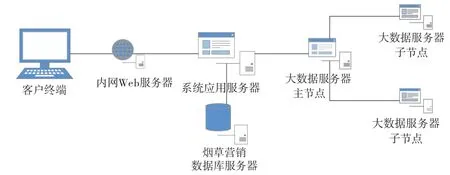
图4 贵州省烟草营销大数据系统架构
构建系统如图4所示。在原有数据的基础上,周期性(每天)从卷烟销售的数据库中抓取数据进行自动处理添加增量。在系统的应用服务器上通过Java Ganymed-SSH2 API向服务器发送命令,将数据文件利用Hadoop shell存入HDFS中。根据已经建立的数据索引调用MapReduce API进行处理。数据分布式处理流程如图5。

图5 数据分布式处理流程
1)利用Java Map接口根据研究指标建立数据索引,再将这些数据索引读入,存储在HDFS上,由HDFS自动按照系统设置生成两份最终一致的备份。
2)将文件拆分为splits,并由MapReduce框架自动完成分割,将每一个split分割为<key,value>对。
3)每一对<key,value>调用一次map函数,处理后生产新的<key,value>对,由Context传递给reduce处理。
4)Mapper对<key,value>对按key值进行排序,并执行Combine过程,将key值相同的value进行合并。按照研究要求,分别按照时间和地点对不同品牌记录进行归并计数,生成具有新键值的品牌-统计数键值对,传送给Mapper,得到Mapper的输出结果。
4)reduce处理,处理后将新的<key,value>对输出,并且将输出结果对应的索引映射回销售数据,获得统计结果,在HDFS存储的同时写入Oracle数据库中的结果表。
2.3 比较利用Hadoop进行品牌热度分析的效率提升
分别比较直接利用SQL和利用hadoop的效率差异:

s e l e c t b r a n d_n a m e,y m d,c i t y_n a m e,c o u n t(*) c t f r o m V_O R D E R_L I N E g r o u p b y b r a n d_n a m e,y m d,c i t y_n a m e w h e r e s t r(y m d,4)=2 0 1 5 o r d e r b y c t d e s c
选取2015年共计5 681万条进行SQL查询,运行时间为2 min 20 s,利用MapReduce配合ETL进行数据分析,共用36 s,效率提高约3/4。
2.4 贵州省烟草销售品牌热度排名
表1给出了贵州省4 a(2013~2016)综合销售数据品牌排名,表2 给出了指定地域为贵阳市的销售排行前10的品牌偏好,表3给出了贵阳市2016年热度前10名品牌对比。

表1 贵州省2016综合销售数据品牌排名

表2 指定地域的品牌偏好

表3 贵阳市2015~2016年热度前10名品牌对比
2.5 基于商户GPS数据的热点图制作
商户GPS数据作为贵州省数据中心新型数据来源,为商户订单、销售数据赋予了空间维度的特征,传统以时间为维度的数据得以向空间维度拓展。通过对GPS数据进行清理,去除空坐标、错误坐标后,与订单、销售数据相关联,利用数据分组统计手段对不同订购商店的订购情况进行汇总后,利用GIS空间插值制作热力图,由此可将烟草销售的区域特征直观地展现在地图上,帮助用户从空间维度来宏观了解烟草销售的热点及空间变化。图5给出了黔南州烟草订购热力图,越明亮的地区烟草订购量越大,反之越暗淡的地区,烟草订购量越小。
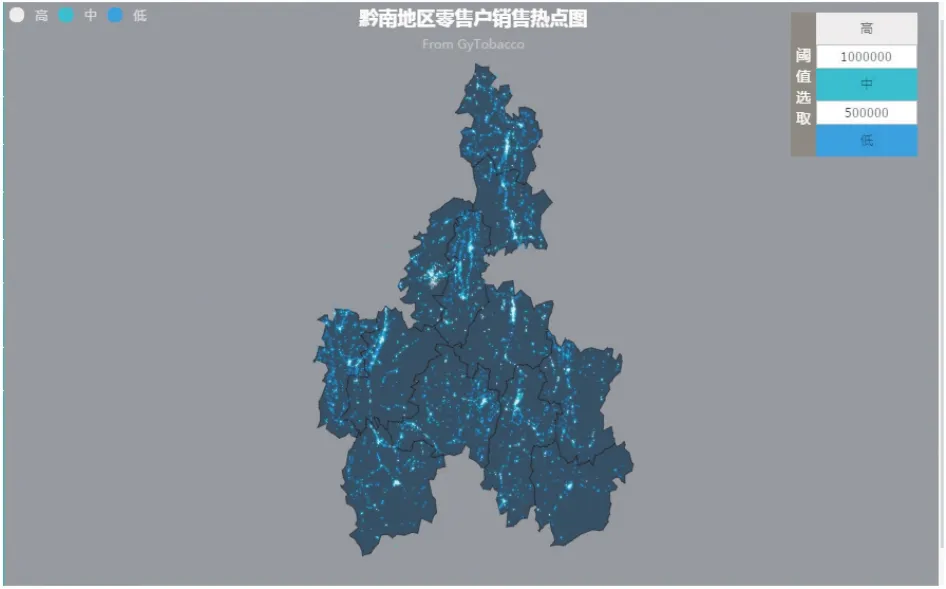
图6 黔南州烟草订购热力图
3 结 语
通过建立基于MapReduce的品牌热度统计方法,探索一种安全可靠的分布式数据存储方案和高效快捷的数据处理方法,将Hadoop成熟的大数据存储和处理系统应用到商业数据的分析和挖掘过程。相比于传统的基于关系型数据库的ETL和分析应用,利用基于HDFS的数据存储和基于MapReduce的品牌热度分析,提高了数据存储的可靠性和安全性,提高了离线数据挖掘的速度和准确性。
本实验只获得全省卷烟销售品牌热度的宏观结果,没有针对某一品牌或者某一商户进行方案定制;在空间数据的利用上,只是简单利用行政区编码进行了区域标定,有待引入空间统计学的相关知识进行深化。
[1]熊忠阳.面向商业智能的并行数据挖掘技术及应用研究[D].重庆:重庆大学,2004
[2]Shvachko K, Kuang H, Radia S, et al.The Hadoop Distributed File System[C]. MASS Storage Systems and Technologies.IEEE,2010:1-10
[3]汤韬.基于Hadoop的云计算平台安全机制研究[J].电子技术与软件工程,2015(2):224-224
[4]朱珠.基于Hadoop的海量数据处理模型研究和应用[D].北京:北京邮电大学,2008
[5]Vavilapalli V K, Murthy A C, Douglas C, et al. Apache Hadoop YARN: yet another resource negotiator[C].Symposium on Cloud Computing,2013:1-16
[6]李俊,李勇.联邦式异构数据库应用系统的集成框架和实现技术研究[J].计算机应用研究,2001, 18(4):19-22
[7]科学数据共享工程项目组.地球系统科学数据共享网[DB/OL]. http://www.sciencedata.cn 2010-12-10 / 2016-12-10
[8]Dean J, Ghemawat S. MapReduce: Simplified Data Processing on Large Clusters.[C].Conference on Symposium on Opearting Systems Design & Implementation, USENIX Association, 2004
[9]李建江,崔健,王聃,等. MapReduce并行编程模型研究综述[J].电子学报,2011,39(11):2 635-2 642
[10]向小军,高阳,商琳,等.基于Hadoop平台的海量文本分类的并行化[J].计算机科学,2011, 38(10):184-188
P208
B
1672-4623(2017)12-0070-03
10.3969/j.issn.1672-4623.2017.12.022
2016-11-29。
国家自然科学基金资助项目(41471323);中国烟草公司贵州省公司科学研究与技术开发项目(201407)。
(*为通讯作者)
李帅,硕士研究生,主要从事时空数据挖掘方面的研究。
