基于协同计算的FDTD区域分解并行算法研究
2017-12-27唐晓斌龚晓燕
冯 圆,唐晓斌,龚晓燕
1.中国电子科学研究院,北京 100041
2.空军预警学院,湖北 武汉 430019
3.火箭军指挥学院,湖北 武汉 430013
美国、西班牙、土耳其、比利时等国外学者对并行电磁算法的研究取得了卓著成果。例如多层快速多极子方法(MLFMA)、时域有限差分法(FDTD)、有限元法(FEM)等多种算法都有对应的并行算法。目前,HFSS、CST、FEKO等常见电磁软件都开发了并行计算模块。各国已经将并行电磁计算技术广泛用于隐身/反隐身等电子装备的分析、设计、研制、评估等各个方面,推动了装备性能的快速升级。但随着科学技术的不断发展和电子武器装备应用领域的不断扩大,越来越多的更复杂的电磁问题被提出,例如THz频段的隐身/反隐身设计。可见,电子信息系统仍然存在着大量挑战性课题迫切需要解决,传统的并行计算技术逐渐不能满足日益发展的电磁计算需求。为此,研究性能更为强大的电磁协同计算是十分必要的。作为协同计算的最新发展,云计算应用于高性能科学计算领域具有广阔前景。
国内的协同计算技术距离国外有一定的差距。与国外研究情况类似,目前国内的大规模电磁计算主要采用消息传递接口模型(MPI),即传统的并行计算。而电磁协同计算特别是电磁云计算的研究工作尚属空白。
直到最近,云计算作为一种新型的协同计算模式,在我国的发展方兴未艾。中国科学技术大学率先对云计算MapReduce模型在科学计算中的应用进行了探讨,开发了面向高性能科学计算的MapReduce系统,该系统支持大规模计算的任务分配和自动并行,实现了矩阵LU分解,计算效率接近于传统MPI。遗憾的是,基于云计算的电磁计算理论与方法并没有建立。国内对并行电磁计算的研究主要集中于MoM、FDTD、FEM等几种典型方法,存在计算效率不够高、计算规模不够大等突出问题,无法充分满足隐身/反隐身等国防电子装备的迫切需求[1-3]。
本文基于协同平台的FDTD区域分解并行算法,添加了区域分解方法,引入划分子区域的虚拟边界,使用Despres传输条件进行划分,对三维问题进行分解,通过求解整个区域的有限差分方程,实现对整个区域的求解。最后,针对本文提出的算法进行算法验证和并行测试。
1 协同计算平台架构
1.1 协同系统设计
基于“主控中心—子集群”的两层泛型结构,为基于广域网的电磁计算任务的执行提供了一个高效的计算平台,整个平台通过浏览器(或标准API调用)为终端用户提供服务。用户在终端提交任务请求后,经过广域网传递到主控制节点,主控制节点通过业务管理模块获得任务信息后,调用主控中心调度器依据当前平台资源实时状况做出调度,并将任务下发到各个子中心控制节点,利用子中心调度器得到调度结果。
1.2 系统的架构
在两层调度体系中,由主控中心首先对任务各属性(计算复杂度、存储容量要求、通信量、地理位置等)进行分析,根据策略将任务进一步分发至子集群的控制节点。主控制中心主要完成任务接收、任务解析、资源映射、任务调度或分发、结果反馈、资源监控、用户认证、任务监控与迁移等工作,并不进行任务的具体计算,所有的计算工作都是在各个子计算中心完成,子计算中心是真正的电磁计算任务运行承载者。当子集群控制节点调度器收到任务请求后,会执行一个算法的迭代,然后产生结果集,返回给用户。

图1 计算任务协同平台整体架构Fig.1 Overall framework of computing tasks on the collaboration platform
1.3 硬件资源
本平台的物理设备主要由HP刀片服务器集群、曙光刀片服务器集群以及部分机架式服务器以及若干本地/异地PC机组成,平台的网络拓扑结构如图2所示。

图2 网络拓扑结构Fig.2 The topology structure on network
各物理设备的型号、具体硬件配置、用途等如表1所示:

表1 各物理设备的具体配置信息Table 1 Specific configuration information for each physical device
2 融合区域分解方法的算法原理
文献[4]已经使用时域有限差分方法分析了一般三维电磁场问题,考虑到针对大尺寸的三维问题求解时,存储量和计算量偏大等问题,本文添加了区域分解方法,用以解决这一问题。不失一般性考虑求解区域沿着y方向(别的方向一样)进行分解(见图3),各子区域间无重叠。总的区域分为Ω1,Ω2,Ω3,…,Ωm,交界面为Γ1,Γ2,Γ3,…,Γm-1。

图3 沿z方向区域分解示意图Fig.3 Schematic domain decomposition at Z direction
引入划分子区域的虚拟边界,使用Despres传输条件进行划分,对三维问题进行分解。区域Ω1,Ω2,Ω3,…,Ωm满足Maxwell方程,交界面Γ1,Γ2,Γ3,…,Γm-1满足Despres传输条件,同时,截断边界上满足CPML吸收边界条件,Yee网格下在无源区域,并设定相对电导率为1,即µr=1,后面的迭代都将使用这个结果进行计算。FDTD算法的处理过程同前所述,本节只讨论实施区域分解的内容。
相邻两个区域Ωm和Ωm+1间的虚拟边界Γm,m+1,该条件为:
城市公共艺术是城市的思想,是一种当代文化的形态,拥有良好城市公共艺术的城市,才是一座有感觉的城市。为此,我们应该凭着对艺术的忠诚,做好每一件与我们有缘的城市公共艺术作品,享受艺术创作带来的乐趣,寻找属于自己的艺术作品的符号,用城市公共艺术彰显城市的文化和特质,展示城市的形象与魅力。

考虑子区域Ωm和Ωm+1间的虚拟边界Γm,m+1,显然有,令并将其代入上式(1),得到Despres传输条件下的方程[5],即:

两个区域间的虚拟边界上的Despres传输条件则为:
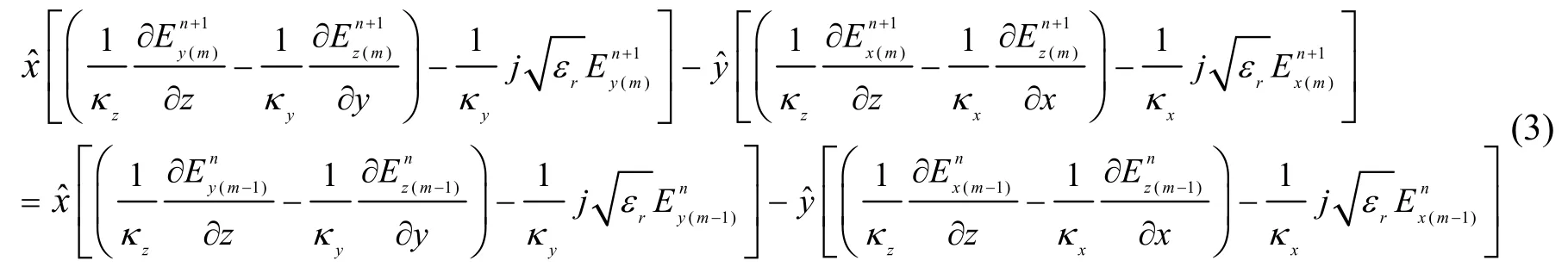
同理可以得到磁场的表达式。其磁场表达式为:


式(4)、(5)是子区域Ωm的上边界和下边界Despres传输条件的差分公式。通过这两组公式有效地连接了上一个相邻区域Ωm-1和下一个相邻区域Ωm+1。采用类似的方法处理所有子区域Ω1,Ω2,Ω3,…,Ωm,就可以求解出整个区域的有限差分方程,实现对整个区域的求解。
3 测试比对与分析
算例1:算法正确性检验
首先,检验上述算法的正确性。本文选取与文献[6]一致的三维金属导体方块,对其电磁散射特性进行分析。目标电尺寸为20 cm×20 cm×20 cm,介质表面涂覆厚度d=2.1 mm,涂覆层的材料电磁参数为Ɛr=4.8,σ=1.67×10-3s/m,σm=1.42×103Ω/m。采用平面波入射,计算频率设置为f=3 GHz,取δ=Δx=Δy=Δz,将整个求解目标分解为5个子区域,再沿着x,y,z方向将导体均匀离散成10份。吸收边界取在第10个网格外表明处。入射平面波方向见图4所示,计算结果见图5所示。

图4 立方体与入射平面波的关系Fig.4 Relation between the cube and the incident plane wave

图5 立方体abcd折线上的电流分布Fig.5 Current distribution on a cubeABCD fold line
算例2:算法的并行性能测试
再以16× 18个伞形阵列天线为例,采用本文的FDTD并行算法在协同计算平台上开展该天线的辐射特性计算。通过深入探讨在不同虚拟拓扑结构下FDTD算法的并行性能。单元和阵列模型示意图如图6所示。

图6 16×18阵列几何模型Fig.6 16×18 array geometry model
仿真参数为:三个方向的大小为0.736 m×1.1725 m×0.004 m。共有两层介质板,每层的厚度均为0.002 m,底层为PEC反射板,底层上方为泡沫支撑结构,介电常数为1,不计损耗;泡沫上方为偶极子辐射单元,夹层为介质材料,介电常数为2.2,不计损耗;组阵:横向16单元,纵向18单元。选择计算频率f=3 GHz,入射波为平面波,整个计算区域的网格大小取Δx=Δy=Δz=0.2 mm,总的迭代步数为10000步。选取的角度范围0°≤φ≤360°,角度采样间隔Δφ=0.5°,对于吸收边界使用5层CPML,激励使用Gauss基脉冲,计算的总网格数为1650×1960×630,总的网格数为203742000。计算结果如下:图7显示了288单元阵列天线的电场分布;图8为288单元阵列天线增益方向图3D显示;图9为288单元阵列天线在phi=0°和phi=90°两个面上的辐射方向图。

图7 16×18天线阵图中的电场分布Fig.7 The electric field distribution in 16×18 antenna array

图8 288单元阵列天线增益3D方向图Fig.8 Gain 3d pattern of 288 element array antenna

图9 288单元阵列天线辐射方向图Fig.9 Radiation pattern of 288 element array antenna
图9是采用了FDTD并行算法计算的多单元阵列天线增益方向图,并将该结果与商用软件CST的计算结果进行对比。从phi=0°面和phi=90°面的天线增益方向图可以看出,两者吻合较好,表明本文的算法可以准确地解决复杂结构的电磁场问题。
针对算法的并行效率测试的参数设置及对应的时间和并行效率值如表2所示。对比文献[7]的结果,可以看出,对于CPU核数从32到1024的测试中,算法并行效率从100%降到了73.67%,虽然不及江树刚等测试的结果,但是也在一定程度上说明了本文算法的程序具有较好的并行性能。本文的结果之所以并行效率没有达到参考文献的值,可能是在虚拟拓扑的选择、计算平台的硬件性能上的差异导致的。
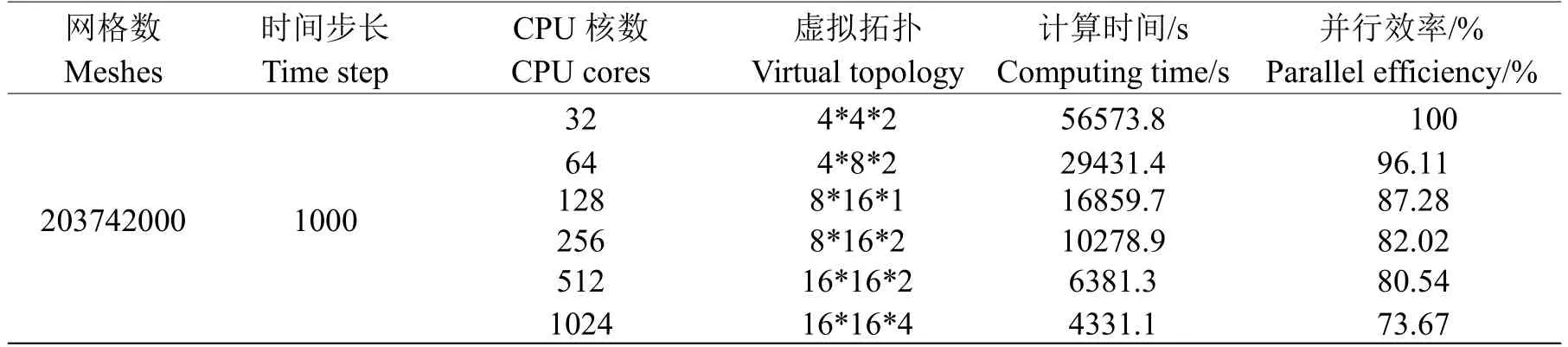
表2 不同核数下的并行性能对比Table 2 Comparison of parallel performance under different cores
表中虚拟拓扑是笛卡尔坐标的形式,即x×y×z,8×16×1表示的是在z方向上没有拓扑结构,虚拟拓扑的维数在现有数字上减1;16×16×2表示在三个方向上都有拓扑结构,所以拓扑的维度是3。
从表2可以看出,随着CPU核数的增加,虚拟的拓扑数目在增加,计算的时间大幅减少。拓扑的结构对并行计算的影响情况将是下面讨论的问题。本文分别对在相同CPU核数、不同维度虚拟拓扑和相同CPU核数、相同维度虚拟拓扑两种情况下的并行性能进行测试,讨论计算效率最优的问题。
考虑到计算量巨大和计算资源难以满足计算的需求,难以进一步研究算法的并行性能,为此,本文将对三维的虚拟拓扑情况进行计算和分析。由于CPU核数选用32时,虚拟拓扑结构可以出现的组合形式较少,仅有4×4×2、2×4×4和4×2×4三种,所以,本文选用64核进行测试。

表4 CPU 64核、三维不同虚拟拓扑下的并行性能对比Table 4 Comparison of parallel performances between CPU 64 cores and 3D topology
表4讨论了CPU 64核、三维不同虚拟拓扑下的并行性能,从计算数据可以看出,虚拟拓扑的不同,计算结果也有较大的差异,计算效率也会有较大的区别。通过上面的并行计算测试可以得出:在多核计算系统中,实现MPI通信下的FDTD并行计算需要充分考虑虚拟拓扑的结构与子域网格的划分方式,不同的分割方式会导致计算量的差异,影响计算的效率。
4 讨论与总结
本文基于协同平台开展一种新的FDTD并行算法研究。针对电大尺寸的三维开域问题求解时,存储量和计算量偏大等问题,添加了区域分解方法,引入分子区域的虚拟边界,使用Despres传输条件进行划分,对三维问题进行分解。同时对CPU并行效率进行了研究,根据相同CPU核数、不同维度虚拟拓扑和相同CPU核数、相同维度虚拟拓扑两种情况开展并行性能测试,实现算法的并行效率的优化。同时也得到:
(1)在进行MPI通信下的FDTD并行计算时,需要提前确定最优的虚拟拓扑结构。原则上是三维拓扑优于二维拓扑,二维拓扑优于一维拓扑,同时,在所有三维拓扑结构中仍然需要挑选最优拓扑方案;
(2)在维数相同的虚拟拓扑结构中,拓扑结构的选取应该遵循一定的规律,即:拓扑分割和计算网格在形式上要一致,比如,计算的总网格数为1650×1960×630,拓扑结构x×y×z在分割时,最好保持y>x>z,这样就有效地减少在子域交界面形成的网格数量,避免交界面上更多的数据通信,提高计算效率。
[1]Kim KH,Park QH.Overlapping computation and communication of three-dimensional FDTD on a GPU cluster[J].Computer Physics Communications,2012,183(11):2364-2369
[2]Xu L,Xu Y,Jiang RL,et al.Implementation and optimization of three-dimensional UPML-FDTD algorithm on GPU cluster[J].Computer Engineering&Science,2013,35:160-162
[3]Yang CT,Huang CL,Lin CF.Hybrid CUDA,Open MP,and MPI parallel programming on multi core GPU clusters[J].Computer Physics Communications,2011,182(1):266-269
[4]冯 圆,代小霞,唐晓斌,等.基于分布式平台的FDTD并行算法[J].北京航空航天大学学报,2016,42(9):1874-1883
[5]Despres B.Domain decomposition method and the helmholts Problem[C].Strasbourg France:Proc.Int.Symp Mathemat.Numerical Aspects Wave Propagate Phenomena,1992:44-52
[6]Taflove A, Umashankar K. Radar cross section of general three-dimensional scatters[[J].IEEETransEMC,1983,25(4):433-440
[7]江树刚,林中朝,张 玉,等.国产超级计算机实现10核FDTD并行计算[J].西安电子科技大学学报,2015,42(5):89-90
