基于数据挖掘与机器学习的蛋白质疏水性分析的研究
2017-12-27周斯涵刘月兰
周斯涵,刘月兰
(哈尔滨师范大学)
0 引言
验证蛋白质的亲疏水性对蛋白质的稳定性、构象和蛋白质功能具有重要意义.多年来,科学工作者为测定蛋白质的亲疏水性做了多方面的研究,目前,研究者多用ExPASy的Protparam[1]用来预测蛋白质,但是仍未出现一种比较精确的预测方法.
机器学习[2](Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科.该文基于机器学习中的四种分类算法,设计出四种分类器,并将四种分类器整合,得到最优解.可将多个含有亲疏水性特征值的蛋白质作为一个数据集输入到分类器中.分类器利用该数据集进行自我训练与学习,最终准确预测出蛋白质的疏水性.
1 算法与过程
1.1 数据获取
通过Python编程语言编写数据挖掘方法,利用Enterz与包含正则表达式的re模块,实现自动从美国NCBI数据库获取指定ID号的多个蛋白质一级结构序列数据,并以蛋白质名、序列数据存入可指定位置的本地文档,部分源代码如下所示:
def get_protein_sequence(protein_id):
handle=Entrez.efetch(db="protein",id=str(protein_id),rettype="genbank", email="")
record=handle.read()
protein_name=re.findall(r'
(.+?)
protein_sequence=re.findall(r'
(.+?)
',str(record))
for n in range(100000,200000):
line=get_protein_sequence(n)
line=str(line)
line=line.replace(',',' ')
print line
f.write(line+' ')
f.flush()
f.close()
return protein_name,protein_sequence
def get_term(database_name,Term):
handle=Entrez.esearch(db=str(database_name),term=str(Term),email="")
record=Entrez.read(handle)
return record['Count']
def browse_record(m,n,record):
return record["IdList"][m:n]
1.2 类型转换与特征值分配
蛋白质的亲疏水性的鉴定是一个二分类问题,故将亲水性蛋白质(hydrophilic protein)的特征值定为-1,疏水性蛋白质(lyophobic protein)设为1.
由于分类算法中的输入数据集必须为数值型数据,故将蛋白质序列数据中各个氨基酸根据表1中的疏水性参数[9]进行转化.
如glutamate--ammonia ligase (EC 6.3.1.2) - kidney bean中的氨基酸序列可转化为如下数组:[-3.5, -1.6,-1.3,4.2 4.2,-0.7, -0.8, 3.8,3.8, 1.8, -3.5, -0.7,-0.8,3.8,3.8,-0.9,-3.5,-1.6,-0.7,3.8,-3.5,1.8,-3.5,1.8,3.8,1.8,1.8,-3.5,-3.9,3.8,1.8,3.8,-3.9, 4.2].

表1 氨基酸疏水性参数
将从美国NCBI数据库中随机获取的500个来自不同物种的非等长蛋白质序列匹配相应的参数值与特征值,作为训练数据集输入到分类器中,分类器通过算法进行学习后,达到对未知亲疏水性的蛋白质进行自动分类.
1.3 分类器算法
1.3.1 支持向量机(Support Vector Machine)算法
支持向量机[3](Support Vector Machine,SVM)算法是由所属于AT&TBell实验室的V.Vapnik等人所提出的一种新的机器学习算法.支持向量机目前已经用在了基因分类、目标识别、函数回归、函数逼近、时间序列预测及数据压缩、数据挖掘等各个领域中.
SVM的主体思想[4]是针对二分类问题,找到一个能分成两部分训练样本点的超平面,达到保证最小的分类错误率.在线性可分的情况下,有一个或多个超平面能让训练样本全部分开,支持向量机算法的目的就是为了找到其中最优的超平面.
SVM的基本模型:设输入样本集合{a[n]} ∈Rn由两部分点组成, 如果a[n]属于第一部分,则y[n] = 1 , 如果x[n]属于第二部分,则y[n] = -1 , 有训练样本的集合{a[n] ,b[n]} ,n= 1 ,2,3 , …,n,求最优分类面ka-p=0,满足:b[n](wa[i] -p) >= 1;并使得2*h= 2/‖k‖最大,即min‖k‖*‖k‖/2.
根据对偶理论,可以通过解该问题的对偶问得到最优解,对偶问题为:
max∑α[n] - 1/2 ∑α[n]*α[m]*b[n]*b[m]*a[n]*a[m]
0≤α[n]≤C*∑α[n]*b[m]=0.
其中a[n] ·a[m]表示这两个向量的内积,当对于线性不可分的情况,用核内积K(a[n],a[m])(通过核函数映射到高维空间中对应向量的内积)代替a[n] ·a[m].根据对偶问题的解α,求得k,p,得到最优分类面.
SVM 模型求解 :当向量维数较大且训练样本向量比较多时,上述的对偶问题是一个大型矩阵的问题,用一般的矩阵求逆的方法不管是在时间复杂度上还是在空间复杂度上都是非常不可取的.序贯最小优化(sequential minimal optimization,简称SMO)算法是目前解决大量数据下支持向量机训练问题的一种比较有效的方法.
SMO[6]算法的大致步骤为:
(1)将m向量分为两个集合,工作集a,固定集b,即:m= {a,b}.
(2)每次对a求解单个较小的二次规划时,使b中的值不变.
(3)每次迭代选择不同的a和b,每次解出一个小规模的优化问题,都是在原来的基础上向最后的解集前进.
(4)在每次迭代后,检查结果.当满足优化条件时,便得到了优化问题的解,该算法结束.
将该算法封装成一个易于调用的函数,其部分源代码如下所示:
def SVM(test_protein):
model=SVC()
model.fit(dataset.data,dataset.label)
svm_result=model.predict([dataset.To_staticlist(dataset.Delplace(test_protein))])
sum_result.append(svm_result[0])
1.3.2 决策树(Decision Tree)算法
决策树[5]也是经常使用的数据挖掘算法,决策树分类器就像判断模块和终止块组成的流程图,构造决策树的过程就是寻找有决定性作用的特征,根据其决定性大小的程度来构建一个倒立的树,将最大决定性作用的特征作为根节点,之后递归寻找各个分支下子集里其次要决定性作用的特征,直到子集中所有的数据都属于同一类别.故建立决策树的过程实际上就是依据数据的特征将数据集进行分类的递归过程.
决策树的基本构造步骤如下;
(1)Create node M
(2)if训练集为NULL,在返回node M标记为False
(3)if训练集中所有数据都属于同一个类,则用此类别标记node M
(4)如果候选的属性为空,则返回M作为叶节点,标记为训练集中最普通的类;
(5)for each 候选属性 Att_List
(6)if 候选属性是连续的
(7)then对该属性进行离散化
(8)选择候选属性Att_List中具有最高信息增益率的属性A
(9)标记node M为属性A
(10)for each 属性A的统一值a
(11)由节点M长出一个条件为A=d的分支
(12)设置S是训练集中A=d的训练样本的集合
(13)if S==NULL
(14)加上一个树叶,标记为训练集中最普通的类
(15)else加上一个返回的点
将上述算法封装成一个易被调用的函数,其部分源代码如下所示:
def Decision_Tree(test_protein):
model = DecisionTreeClassifier()
model.fit(dataset.data,dataset.label)
tree_result=model.predict([dataset.To_staticlist(dataset.Delplace(test_protein))])
sum_result.append(tree_result[0])
1.3.3 逻辑回归(Logistic Regression)算法
逻辑回归[7]是机器学习中一种常见的分类方法,主要用于二分类问题,利用Logistic函数,自变量取值范围为(-INF, INF),自变量的取值范围为(0,1),函数形式为:
因为Logistic函数的定义域是(-INF, +INF),而值域为(0, 1),所有最基本的LR分类器适合于对二分类(类0,类1)目标进行分类.Logistic 函数是“S”形图案的函数,如图1所示.
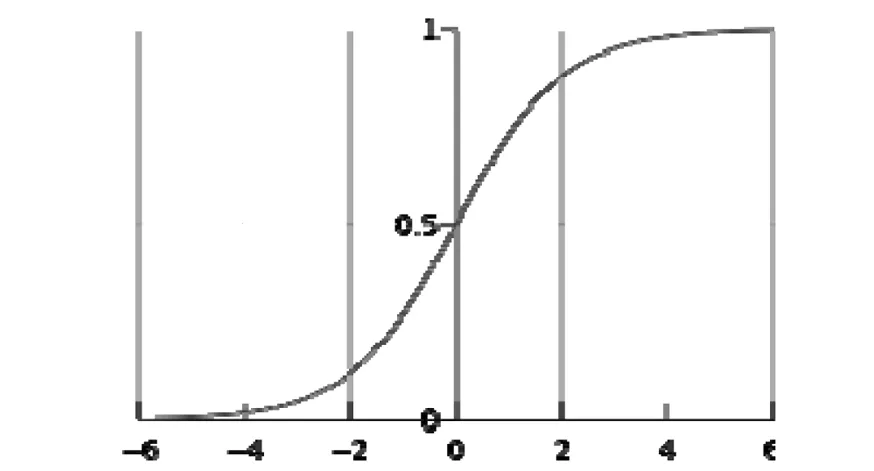
图1 Logistic 函数
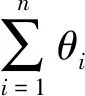
(1)
函数hθ(X)的值表示结果为1的概率(特征属于y=1的概率)所以对于输入x分类结果类别1和类别0的概率如式(2)所示:
P(y=1|x;θ)=hθ(x)
P(y=0|x;θ)=1-hθ(x)
(2)
当要判别一个新来的特征属于哪个类时,按式(3)求出一个z值:
(3)
(x1,x2,…,xn是某样本数据的各个特征,维度为n)
进一步求出hθ(X),当其大于0.5时,就是y=1的类,相反则属于y=0的类.(假设统计样本是均匀分布的,设阈值为0.5).
Logistic算法也可以用于多分类问题,但是二分类的更较常用.因此实际中最常用的就是二分类的Logistic算法.LR分类器适用数据类型:数值型和标称型数据.其优点是计算代价不高,易于理解和实现;其缺点是容易欠拟合,分类精度可能不高.
将上述算法封装成一个函数,其部分源代码如下所示:
def Logistic_Regression(test_protein):
model=LogisticRegression()
model.fit(dataset.data,dataset.label)
logic_result=model.predict([dataset.To_staticlist(dataset.Delplace(test_protein))])
sum_result.append(logic_result[0])
1.3.4 K近邻(K-Nearest Neighbor)算法
KNN[8](K Nearest Neighbors,K近邻)是一种基于实例的监督学习算法,利用计算训练集和新数据集特征值之间的距离,然后选取k(k>=1)个距离最近的邻居进行回归或者分类判断.当k=1,新数据就会被简单分配给其相邻的类.KNN算法的过程为:
(1)选取一个计算距离的方式, 利用所有的数据特征来计算新数据集与已知类别数据集中数据点的距离.
(2)依照距离,递增排序,选择和当前距离最进的k个点.
(3)对于离散的分类问题,对返回k个点出现频率最多的类别进行预测分类;对于回归则返回k个点的加权值用作预测值.
将上述算法封装成一个函数,其部分源代码如下所示:
def KNN(test_protein):
model=KNeighborsClassifier(n_neighbors=10)
model.fit(dataset.data,dataset.label)
knn_result=model.predict([dataset.To_staticlist(dataset.Delplace(test_protein))])
sum_result.append(knn_result[0])
2 结果与分析
2.1 算法结果
根据上述算法,开发出名为protein verify的软件,可从本地打开包含氨基酸序列的文本文档作为输入数据写入软件,其输入格式具有很强的健壮性,可对输入数据进行增删更改,输入数据无格式要求,可包含空格数字,对输入序列大小写无要求.该软件界面如图2所示.
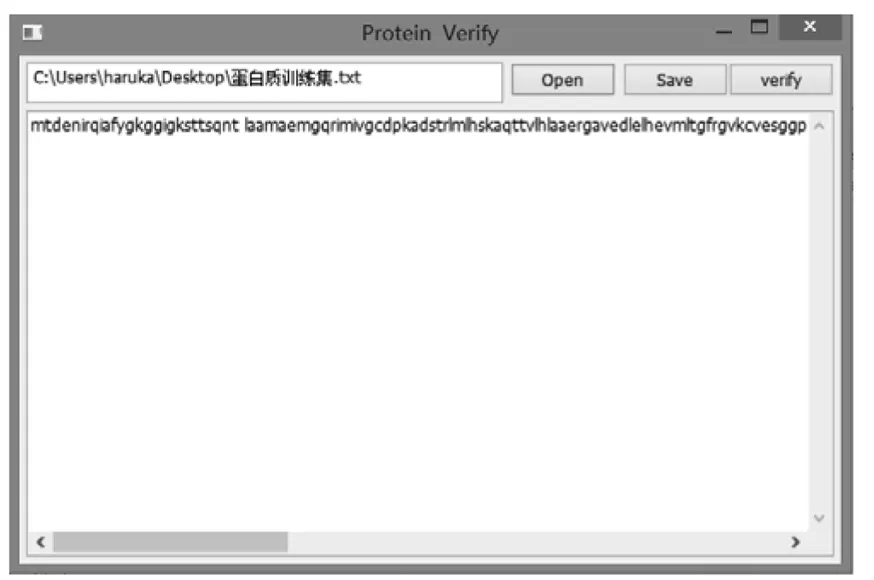
图2 protein verify软件界面
软件功能如下:
(1)open按钮;可从本机打开存有蛋白质一级序列的文档,打开后序列呈现在文本框内.
(2)Save按钮:对打开后的序列进行增删更改后可保存到本地.
(3)verify按钮;即可对该蛋白质做出亲疏水性鉴定.其查询结果与预测准确率如图3所示.
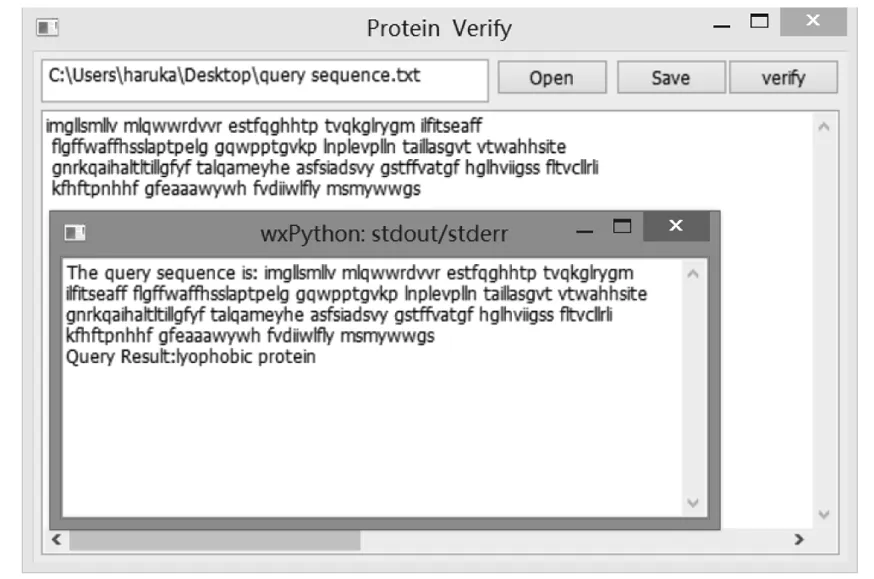
图3 查询结果显示
2.2 准确率分析
通过以上四种分类器算法的集成,随机选择多个蛋白质进行软件测试,利用图4所示的计算方法得出表2的预测准确率:
True Positive(TP):被模型预测为正的正样本
True Negative(TN):被模型预测为负的负样本
False Positive(FP):被模型预测为正的负样本
False Negative(FN):被模型预测为负的正样本
True Positive Rate(TPR)
TPR = TP/(TP + FN)正样本预测结果数/正样本实际数
True Negative Rate(TNR) TNR = TN/(TN + FP)负样本预测结果数/负样本实际数
False Positive Rate(FPR) FPR = FP/(FP + TN)被预测为正的负样本结果数/负样本实际数)
False Negative Rate( FNR)FNR = FN/(TP + FN)被预测为负的正样本结果数/正样本实际数
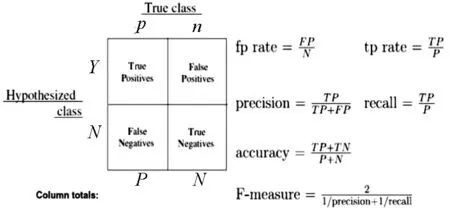
图4 概率计算方法
Precision:正确预测的概率
F1-Score:precision和recall的调和平均数
Recall(真阳性率):正确识别的概率
Support:训练集样本容量
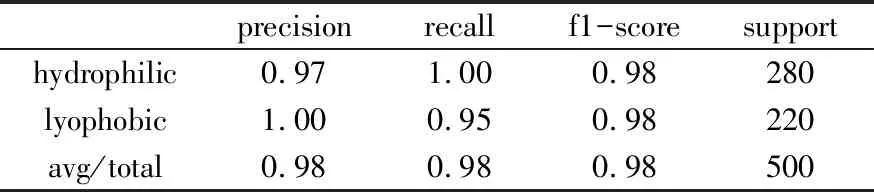
表2 Classification report
2.3 结论
经过实验,该算法可将多个含有亲疏水性特征值的蛋白质作为一个数据集输入到分类器中.分类器利用该数据集进行自我训练与学习,最终准确预测出蛋白质的疏水性.
该算法可作为蛋白质疏水性分析预测的有力工具,在生物信息领域中得到广泛的应用.
