基于大数据的网运前台系统架构设计与优化
2017-12-27高智衡
高智衡
基于大数据的网运前台系统架构设计与优化
高智衡
(中国电信股份有限公司广州研究院,广东 广州 510630)
根据业务应用特性,提出了基于大数据的电信网络运营前台系统的技术架构设计。随着所承载的应用越来越多,从减少页面加载时间、提升查询性能、提高代码复用率等角度考虑,在单页面应用架构、查询模板化、查询缓存、业务功能组件化、查询服务高可用等方面对系统进行了优化,为类似系统的建设提供了参考。
大数据 网络运营 前台系统 技术架构
1 电信网络运营前台系统概述
电信网络运营系统以提高网络运行质量,提升用户的业务使用体验为核心目标,主要涉及两个方面的数据:一是网络/设备运行信息,包括反映设备/端口/链路的速率、带宽、抖动、延时等硬件运行情况的信息以及反映网络情况的业务统计信息,一般通过网管系统进行监控和采集;二是用户使用业务信息,包括用户的实时位置、正在使用的业务类型、业务内容、APP名称、终端型号版本、业务使用感知(时延、成功率、速率)等刻画用户行为、反映用户实时业务体验的动态信息,一般采用探针、镜像抓包等方式捕获[1]。
上述数据由现网实时产生、实时采集,数据量大,类型复杂,具备通常所说的大数据3V特性[2],因此系统采用了基于Hadoop的大数据技术进行数据处理和展示。整个系统可以划分为两部分,一部分负责对数据进行采集、ETL预处理、分析/汇总/挖掘等一系列处理,提供数据共享平台,主要面向系统运营维护管理人员,称为后台系统;另一部分负责结合实际业务需求,以图表、地图等方式呈现数据,基于业务经验和分析挖掘结果提供指导生产的结论,并在必要时回写数据,主要面向最终用户使用,称为前台系统。本文探讨后者的技术架构设计及优化。
2 电信网络运营前台系统技术架构设计
该系统的业务关键特性在于:应用以数据查询展示为主,辅以少量的回写业务;属于企业内部应用,仅供内部员工使用;用户层面广泛,应用场景复杂,涉及高层领导关注的宏观汇总数据、基层操作人员关注的细粒度数据以及中层分析人员灵活多变的即席数据查询。
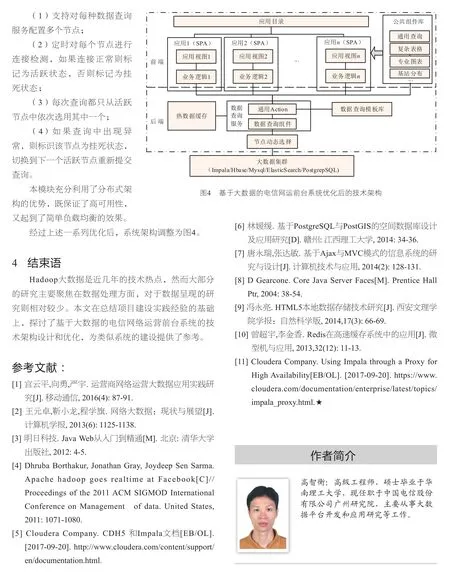
基于上述业务特性,系统技术架构设计如图1所示:

图1 基于大数据的电信网运前台系统技术架构
系统采用了基于Web的BS架构,具备跨平台、客户端零维护等优势[3]。然而BS架构在系统响应方面有所不足,而系统用户要求绝大部分交互在3 s内完成,因此根据不同的应用场景需采用不同的数据存储策略和查询引擎。面向清单级别的查询使用高度可扩展、数据按Rowkey排序、可快速检索指定范围内Rowkey数据的Hbase[4],汇总数据查询和数据回写使用Mysql,灵活多样的即席查询采用高效率的大量数据并行处理(Massively Parallel Porvessing,MPP)查询引擎Impala[5],涉及空间分析则采用支持地理空间数据管理的PostgrepSQL[6]等。查询引擎的多样化使前台系统需要面对多种查询引擎,增加了技术复杂度,所以在后端模块中设计了通用数据查询组件,统一封装各种查询引擎,提供标准SQL或类SQL的查询命令支持,有效地把技术复杂度局限在小范围内。
图1中的每一个应用,对应着一个业务主题,包括以下三个模块:在后端运行的Action服务,负责接收前端请求并调用查询组件访问数据;在前端运行的应用视图模块,负责页面内容的样式和布局;在前端运行的应用逻辑控制模块,负责收集用户的输入,向后端提交数据查询请求,并根据返回结果刷新界面。三个模块使每个应用自身构成了一个标准的MVC子架构[7]。
所有应用由单页面应用(SPA)模块整合,采用静态资源预加载,动态资源按需异步加载的策略,有效地降低了页面内容加载和刷新时给用户带来的停滞等待感。
3 前台系统的优化
上面所介绍的前台系统,结合了Mysql、Postgrep SQL等传统关系型数据库系统和Hadoop大数据处理平台的技术优势,基本可满足各种复杂应用场景下的需求。但是,随着应用的不断深化和扩展,也导致了一些问题的出现,下面总结了相关的优化。
3.1 整体单页面架构转变为按应用的单页面架构,解决了控件版本冲突问题,提升了页面运行性能
SPA架构中,客户端与服务端的所有数据交互仅在同一页面内进行,用户体验类似于桌面应用,其优点在于无需重新加载整个页面,内容刷新快,用户体验好[8]。
然而,当应用数量从初期十多个膨胀到一百多个后,情况就不一样了。首先,不同应用间的控件版本如果存在冲突,只能选用其中之一。比如某应用使用的是echarts2.0,而另一个应用由于一些新的需求希望使用echarts3.0,由于3.0非后向兼容,所以此时要么统一升级到3.0,要么统一继续使用2.0。其次,统一加载的静态资源文件过多,用户登录后页面加载时间过长。再次,当用户打开很多应用时,由于DOM过于庞大导致页面元素检索偏慢。为此,把SPA架构下沉到每个应用内部,即单个应用内还是SPA,每个应用占用一个浏览器标签,而原来的SPA模块则调整为应用目录展示模块,在每个应用窗口的左侧展示应用目录,利用HTML5的本地存储功能(LocalStorage)[9]记录当前用户已打开的所有应用,在任意一个窗口的目录上点击打开某个应用时,以此为基础判断是新建标签页还是激活已打开的标签页。经此改造,每个应用可以自由选择其所需要的控件。
3.2 数据查询模板化,实现前后端开发分离
每个应用的前端视图、逻辑控制模块都与应用需求紧密相关,差异较大,但后端Action模块的主要功能是接收前端请求并根据请求中的参数构建查询命令,调用查询组件获得相关数据并把数据返回。因此,所有应用的Action服务被整合为一个通用的Action服务,与数据查询组件合并,形成数据查询服务。合并的关键点在于把每个应用的查询命令模板化,统一放入一个可配置的查询模板库中。
图2是某模板示例,前端只需把唯一标识模板的id值及模板中的变量名(模板中带有#字符的花括号标识的部分)、变量值放入请求即可。数据查询组件根据id调取出模板,然后把变量名替换为变量值完成模板实例化,最后调用数据查询组件,把查询结果以统一格式返回给前端。模板内容配置在XML模板库文件中,而模板库在Web服务启动时即加载到内存,以加快模板检索速度。
Javascript查询组件以Ajax异步请求[7]的方式把相关参数提交到数据查询服务,并在数据结果返回后调用指定的回调函数进行后续处理。前端开发者只需调用该组件,传入模板id和变量参数以及回调函数等,在回调函数中实现界面数据的刷新即可完成所需的业务功能。而后端开发人员则专注于根据数据需求创建查询模板,并持续地优化查询服务,从而实现了前后端开发分离,避免了原来多个Action状态下的大量代码重复出现的问题。而且,当需要核查数据时,执行模板实例,即可快速定位出问题是在于后台系统的数据处理,还是前台系统的数据展示。可见,查询模板化,前后端分离,不仅提高了开发人员的开发效率,也方便了测试人员的数据核查工作。
3.3 创建查询缓存,提升热数据的查询响应效率
数据查询服务在个别情况下,尤其是涉及数据量较大时或用户并发度较高时,响应还是不够理想。经分析,前台查询基本存在着按月、周、天或者小时的时间周期特点,不同的用户使用相同的功能,实际上查询引擎执行了完全一样的操作。虽然部分查询引擎具备缓存功能,但后台系统运行繁忙,缓存效果并不显著,因此,添加了基于Redis的查询缓存模块。Redis是适用多种场景,可支持多种数据类型的内存数据库,基于Key-Value类型的设计可实现快速高效的缓存管理[10]。

图2 查询模板代码片段
图3 是同步型查询的缓存流程图。以查询命令的MD5值作为查询的唯一标识(Key)。如果该Key存在于缓存库,则说明查询结果已被缓存,直接从缓存库读取该Key值对应的值(Value),返回给调用方即可。如果Key不存在,则说明未缓存,此时先调用查询引擎,在返回查询结果的同时,把该Key和查询结果(即Value)一起写入缓存库备用。为了使缓存写入工作对该次查询的影响降到最低,查询结果被深度克隆后,即返回查询结果给调用方,而另开线程处理缓存库的写入。异步型查询因为涉及进度的轮询,需多次调用,缓存流程稍显复杂,但基本思路与同步型一致,篇幅所限这里不再赘述。
加入缓存模块后,当缓存命中时,不论原查询消耗多少时间,基本上0.2 s内可返回结果,查询效率的提升十分显著,而关键点在于如何提高缓存命中率。通过对系统日常运行查询情况进行统计,可以得到一些较常用的查询,然后根据数据生成周期,在系统闲时对查询进行预触发,可有效提升命中率。当然,缓存模块的引入增加了系统的管理成本,需要仔细分析业务模式,以决定是否启用缓存,并结合数据生成周期配置每个模板的数据缓存有效期,避免过度缓存而导致最新数据变更未能及时取得。
3.4 抽取常用的前端功能模块进行组件化,提升系统开发和维护效率
系统应用不断增加,而相当部分的功能在不同的应用中是类似的甚至相同的,这种情况下,直接复制代码虽然可以快速解决问题,但是当后期需求有所变更时,则不得不翻查每一处的代码进行修订,这显然不是一个长久有效的办法。因此,对所有应用专题进行了分析,梳理出一些常用业务功能,构建了前端公共组件库。这里所说的前端组件,是指具备相对独立的业务功能,提供固定的API接口,可直接引入和调用的Javascript模块,以下是组件库中几个组件的实例。
(1)查询组件——负责以Ajax异步请求的方式把相关参数发送给数据查询服务,并在数据结果返回后调用指定的回调函数进行后续处理,前面的查询模板化部分已有深入介绍。
(2)复杂表格组件——负责生成那些具有复合表头、行列锁定、按列排序、后端分页加载、事件绑定等多种功能的复杂表格。
(3)专业图表组件——负责生成那些常用的专业图表,例如分布图,具备自动定位到用户所指定的分布百分比对应的分界线上。
(4)基站分布组件——在地图上动态地画出当前视图范围内的满足过滤条件的所有基站,并根据其频率、厂家等信息个性化地进行显示。
组件库既规范了业务功能在各个应用的界面和交互,也大幅提升了代码复用率,对提高开发质量,提升开发效率有很大帮助。组件库随着应用的持续开发而不断扩展。
3.5 查询节点动态切换,保证查询服务的高可用性
Hadoop集群中的数据处理服务都是采用分布式多节点架构,如果其中某个节点挂死,可以切换到其他节点,以保证服务的稳定。例如Impala可以结合haproxy提供负载均衡[11],然而,大数据集群也可能由于某种原因尚未提供高可用的支持,所以在后端查询服务与大数据集群之间增加了一个动态切换查询节点的模块,其主要业务逻辑如下:

图3 同步型查询缓存流程
Design and Optimization of Network Operation Foreground System Architecture Based on Big Data
GAO Zhiheng
(Guangzhou Research Institute of China Telecom Co., Ltd., Guangzhou 510630, China)
According to service features, a technical architecture design of the telecommunication network operation foreground system based on big data was proposed in this paper. Considering the more and more applications, the system was optimized in the single page application architecture, query template, query cache, service function componentization and query service high availability, with respect to the page loading time reduction, query performance enhancement and code reusability improvement. It provides a reference to the construction of similar systems.
big data network operation foreground system technical architecture
10.3969/j.issn.1006-1010.2017.22.016
TP319
A
1006-1010(2017)22-0084-05
高智衡. 基于大数据的网运前台系统架构设计与优化[J]. 移动通信, 2017,41(22): 84-88.
2017-09-26
刘妙 liumiao@mbcom.cn
