基于MPB-Tree索引的空间数据多关键词模糊查询算法研究
2017-12-26张素智赵亚楠
张素智, 赵亚楠, 杨 芮
(郑州轻工业学院 计算机与通信工程学院, 郑州 450002)
基于MPB-Tree索引的空间数据多关键词模糊查询算法研究
张素智*, 赵亚楠, 杨 芮
(郑州轻工业学院 计算机与通信工程学院, 郑州 450002)
随着具有定位功能的智能设备的大量使用,产生出海量的空间数据,每条数据中包含的信息越来越多,而以往的查询算法多数仅对单个关键词进行查询,已难以满足用户更为个性化的需求.为此,本文提出一种多空间关键词模糊查询算法,在该算法中,将以往的两维空间距离计算转化为莫顿码匹配提升查询效率,且与模糊查询算法融合支持查询的容错.实验结果表明,该算法的效率及准确性较以往查询算法有较大提高.
空间数据; 多关键词查询; 莫顿码; 模糊查询
近年来,移动信息产业发展迅速,随着移动终端设备的普及,产生出海量的数据,而这些数据都具备地理位置信息和文本内容双重属性,例如在QQ空间或微博中发布信息,都可以标注出用户所处的地理位置,因此基于位置的服务(Location Based Service , LBS)得到人们的广泛关注.
目前的LBS系统把关键词查询[1](Spatial Keyword Query)作为处理空间数据的主要方式之一,简单的说,假定空间数据集中有多个兴趣点(Points of Interest,POI),每一个POI点都包含两种属性的信息:文本信息和位置信息,用户通过输入关键词将其作为查询约束条件,从而检索得到符合要求的POI点.这种处理方式也被各搜索引擎公司采用,但随着空间数据量不断增长、用户需求更加个性、智能移动设备功能的更加齐全导致以往的查询算法渐渐无法满足用户不断提高的需求.
在实际使用中,用户为了获得更为丰富的信息,输入多个关键词作为查询条件是经常出现的,但一个POI点包含的信息有限,有很大几率不能完全覆盖用户所输入的全部文本内容,例如,用户输入休闲、购物、饭店就可能需要多个POI点协作才能满足用户需求.而且现在用户经常用便携的移动设备进行查询,例如手机,其可操作面积较小,有较大几率输入不规范的查询词,例如将“星巴克”误写为“星吧克”,因此还需要查询算法具备一定的容错性.如何从海量的空间数据中快速高效地找出对应的信息已成为目前的研究热点之一.
1 相关研究工作
1.1 研究现状及分析
空间关键词查询目前还处于初步阶段,经过大量学者的研究仍取得一定成果:Yao[2]等人建立MHR-Tree索引结构,并提出一种近似匹配查询算法,将编辑距离引入实现查询的容错,在MHR-Tree内各子节点中增设签名对查询结果进行裁剪,但其质量无法保证,使得查询效果并不理想;Yu[3]等人通过建立MRD-tree索引,允许数据入口放到中间节点处,减少I/O重复次数解放出大量计算资源;Wang[4]等人提出RB-Tree作为索引结构,加入位图使查询的稳定性和准确性得到提高;Zhang[5]等人将模糊匹配融入到k近邻查询中,使得查询结果更为符合需求;Yi[6]等人对Patricia树索引进行改进,大幅度提高了查询速度.
但以上都是以单关键词为主进行研究,对多关键词查询关注较少.而且近似匹配查询是用编辑距离[7]来衡量查询词与POI点的相关程度,通过阈值对POI点进行剪切,然而在实际使用中发现查询词的文本长度是变化的,长文本需要的阈值可能较大,短文本的则较小,阈值过大或过小都可能导致查询结果质量不高,设置出合适阈值的难度很大;其次,随着空间文本数据量的激增,传统的欧式空间距离方法已难以满足人们日益提高的需求,而且以往的空间数据关键词查询研究多数仅考虑空间信息的相关性,对文本相关考虑不够深入.
1.2 本文工作
对于以上提出的问题,本文设计出一种空间数据多关键词模糊查询算法SMFQ (Spatial Multi-Keyword Fuzzy Query),该算法综合考虑文本相关性及空间相关性,融合近似匹配查询方法,支持模糊查询;不设置固定的编译距离阈值,将其与排序算法相融合找出与查询词最相似的k个关键词,支持容错且使算法更为灵活.为满足用户日益提高的查询要求,SMFQ算法需支持:
1) 该算法支持多关键词的模糊查询,查询结果覆盖用户输入的所有文本内容,包含一些文本较长且较复杂的词,比如Four Seasons Resort.
2) 得到的查询结果应该是距离用户最近的,且不过于分散.
3) 该算法对查询结果排序,将最相关的信息优先显示给用户.
为此,本文引入编辑距离、关键词权重、莫顿码[8]、空间和文本相关性[9]等概念,综上本文的主要贡献如下:
1) 基于RB-Tree与Patricia索引建立出支持多关键词近似查询的索引结构MPB-Tree.
2) 提出并设计了空间数据上多关键词模糊查询算法.
3) 使用真实数据进行仿真测试,用实验结果证明SMFQ算法具有较高的可行性及查询效率.
2 相关工作
2.1 基本概念
在给定的某个空间文本数据集中,设O表示一组POI点,即O={p1,p2,p3, …,pn},p={o,t}则有O={(o1,t1.1,t1.2,…,t1.w)……(on,tn.1,…,tn.w)}其中每个POI点对象p都包含有空间位置信息o和文本信息集合t,如图1所示.
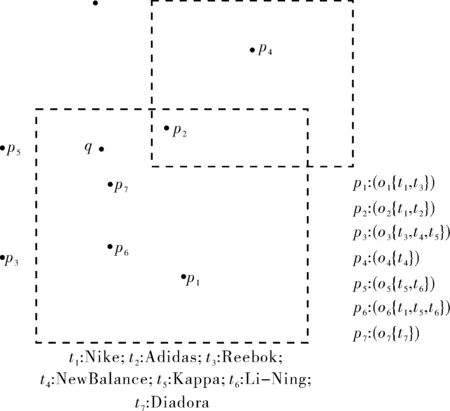
图1 空间数据内在分布关系Fig.1 Spatial distribution of spatial data
假定多空间关键词查询Q={ql,qT},ql表示空间位置,qT表示文本词集合,那么可以存在,ti是用户输入的查询词,ki表示编辑距离上限,ql和ol均用二维空间数值{lon,lat}表示,其中lon和lat分别代表经度和纬度.
2.2 相关算法准备
2.2.1 文本相关性 本文中SMFQ算法支持查询容错,即允许查询关键词qt与POI对象词ot不完全相同,具体的说,本文计算衡量文本相关性主要依据两个因素:关键词权重和编辑距离.
首先,定义空间数据上的多关键词查询集(Spatial Multi-Keyword Set, SMKS),表示为:
{t1,t2,t3,…,tm},1≤|m|≤|qt|.
(1)
在实际生活中,不同的POI点拥有相同的词汇描述的现象是肯定存在的,如图1所示,有三个不同的POI点:p3、p5、p6,它们具有一个相同的文本描述词“NewBalance”.另外,SMFQ是近邻查询,可能仅考量空间位置就可以满足查询要求,但是查询结果的文本相关性无法保证,因而筛选出与查询词最相关的POI点,就需要通过使用权重值进行衡量,查询关键词qt对相应对象O的权重越大说明其文本越相关,需被优先检索.
本文计算权重的方法是在TF-IDF模型[10]基础上优化后得到的:

(2)
其中,tf(t,oT)表示关键词t在oT中出现的次数,次数与权重成正比,idf(t,P)表示在查询范围内的POI点中包含有关键词t的个数的倒数.wmax表示全局最大的权重值,这样可使权重处于0到1区间,便于计算.
查询关键词与相应对象词的编辑距离表示为ed(qt,ot),即qt转换成ot所需的最小操作数,例如将“NowBalances”转变为“NewBalance”,把o换成e然后删除s需两步,即编辑距离为2.编辑距离越小说明两者越相似,文本相关性也越高.
由此可以为关键词文本相关性做出形式化定义,在该式中对编辑距离和权重值两方面进行综合考量,如下所示:
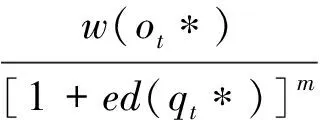
(3)
其中,t*表示与查询关键词编辑距离最小的文本词,ed(qt*)表示该词的编辑距离,w(ot*)表示相应权重值,m用来调整权重与编辑距离两者之间的偏重比,试验中初始化为2,以保证其文本相关性值是在0到1区间.
2.2.2 空间相关性 SMFQ是近邻查询算法,要求其查询范围内检索到的POI点应与ql位置相近.以往的研究多数使用欧几里德距离[11]来表示查询点ql与对象点ol之间的位置关系,但是随着POI点数量的激增其计算花费的时间将成倍增加.
为解决这一问题,本文将二维的经纬度信息转化为一维的莫顿码,具体的说,就是把空间位置从经度和纬度两个方向均转化成二进制的编码,如沿着纬线自西向东方向进行二分,处于上方区域的编码为1,下方为0;类似地,沿着经线自南向北进行二分,左侧区域编码为1,右侧为0.假设经度转化后的的二进制编码为0101,纬度的二进制码为1101,把经度二进制码存到偶数位,纬度的放在奇数位,如图2所示,则产生一组新的编码10110011,即为莫顿码.
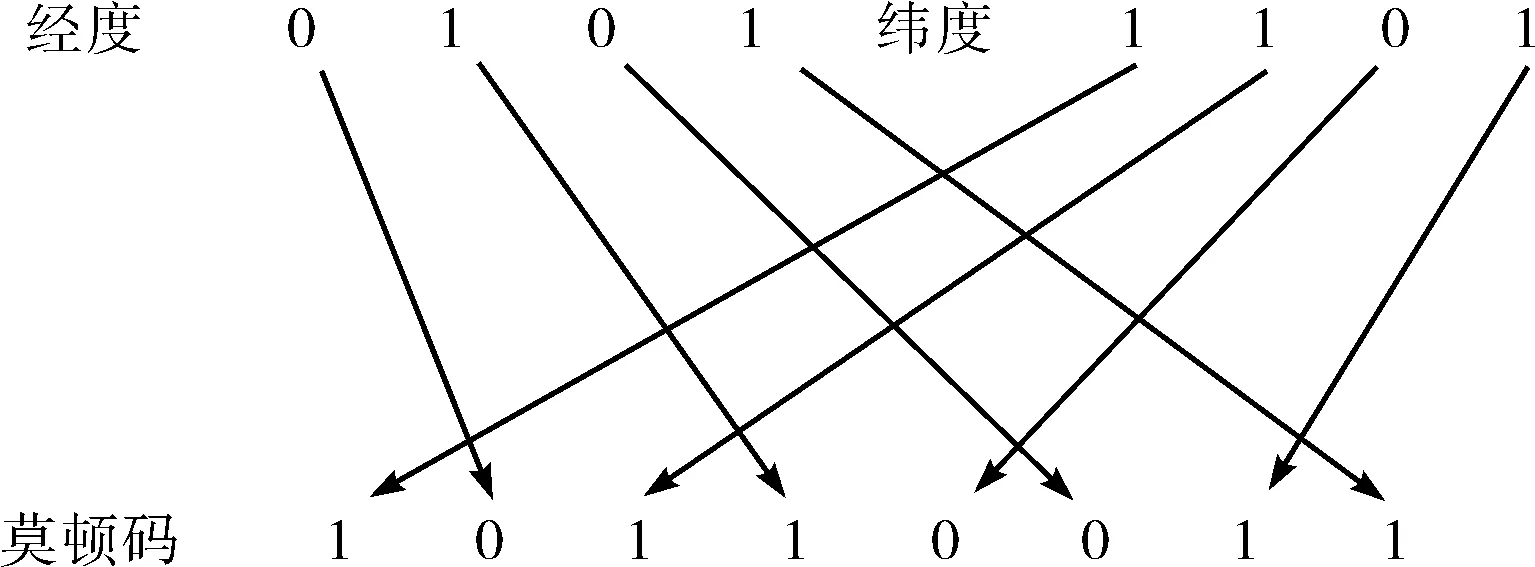
图2 莫顿码格式Fig.2 Morton code format
根据不同的位置精度需求,可以设置出相应长度的二进制莫顿码,距离越近其共同前缀码的长度就越长,因而可以通过字符串匹配替换传统的欧式距离计算节省大量的计算资源.其空间相关性公式可以形式化表示为:
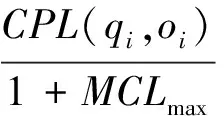
(4)
其中,CPL(q,o)表示查询点位置ql和相应对象ol共同前缀的长度,MCLmax是当前所采用的莫顿码长度.
综上,将文本相关性表达式(3)和空间相关性表达式(4)融合得到综合相关表达式:
(cost)q,o=λ·QT(qt,ot)+(1-λ)·QL(qi,oi).
(5)
λ∈(0,1)用来调节文本和空间两者相关性的偏重比,取值较大则更注重文本相关,反之则更注重空间相关.
3 基于MPB-Tree索引的多关键词查询算法
3.1 MPB-Tree索引
本文把表示地理位置的经纬度信息转化为Morton码,通过比较共同前缀码的长度近似得到距离的远近,从而避免欧式距离所需的巨大计算量.Patricia树是一种前缀树形结构索引,使其与Morton码相结合,在该索引结构中,父节点中存储的是其子节点的共同前缀编码,按规则“左0右1”放入对应子节点,以此不断划分.因为精度的限制,每一个Morton编码表示的并不是空间地理的某个具体的点,而是一片矩形区域,同时其共有前缀码表示一个更大的区域.为使查询结果的文本相关性更好,需对节点进行改进,在上述Patricia树的基础上引入长度位图LB和相关权重位图GB,将qt和ot关键词相似计算简化为位运算;同时节点内还增加存储该点的查询范围MBR;在每个节点添加倒排文件DI,方便计算关键词的权重.结合图3的位置关系MPB-tree结构如图4所示.

表1 相关倒排文本
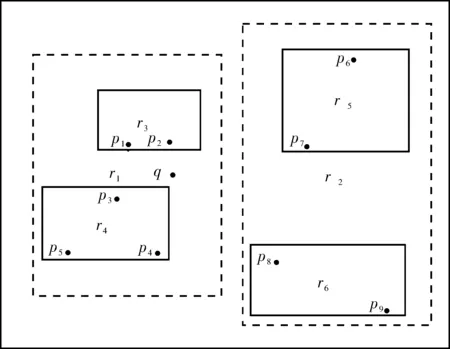
图3 空间对应位置关系Fig.3 Spatial position relation
实验发现,在节点中存的信息稍多一些,其索引体积就呈倍数扩大,因此使用指针代替具体信息,每个非叶子节点存放内容为{pos, mask, ptr_l, ptr_r},pos表示该节点对应编码在整个编码中的位置,mask是一组二进制编码(8位),存储用来比较的编码的最高的不同位,ptr_l和ptr_r是两个指针分别指其左右两个子节点.其叶子节点中的信息为{maininfo, ptr},其中ptr 是指针,指向对应的Morton码串;maininfo中存放POI点信息,该信息内容包含{MBR,LB,GB,DI}.
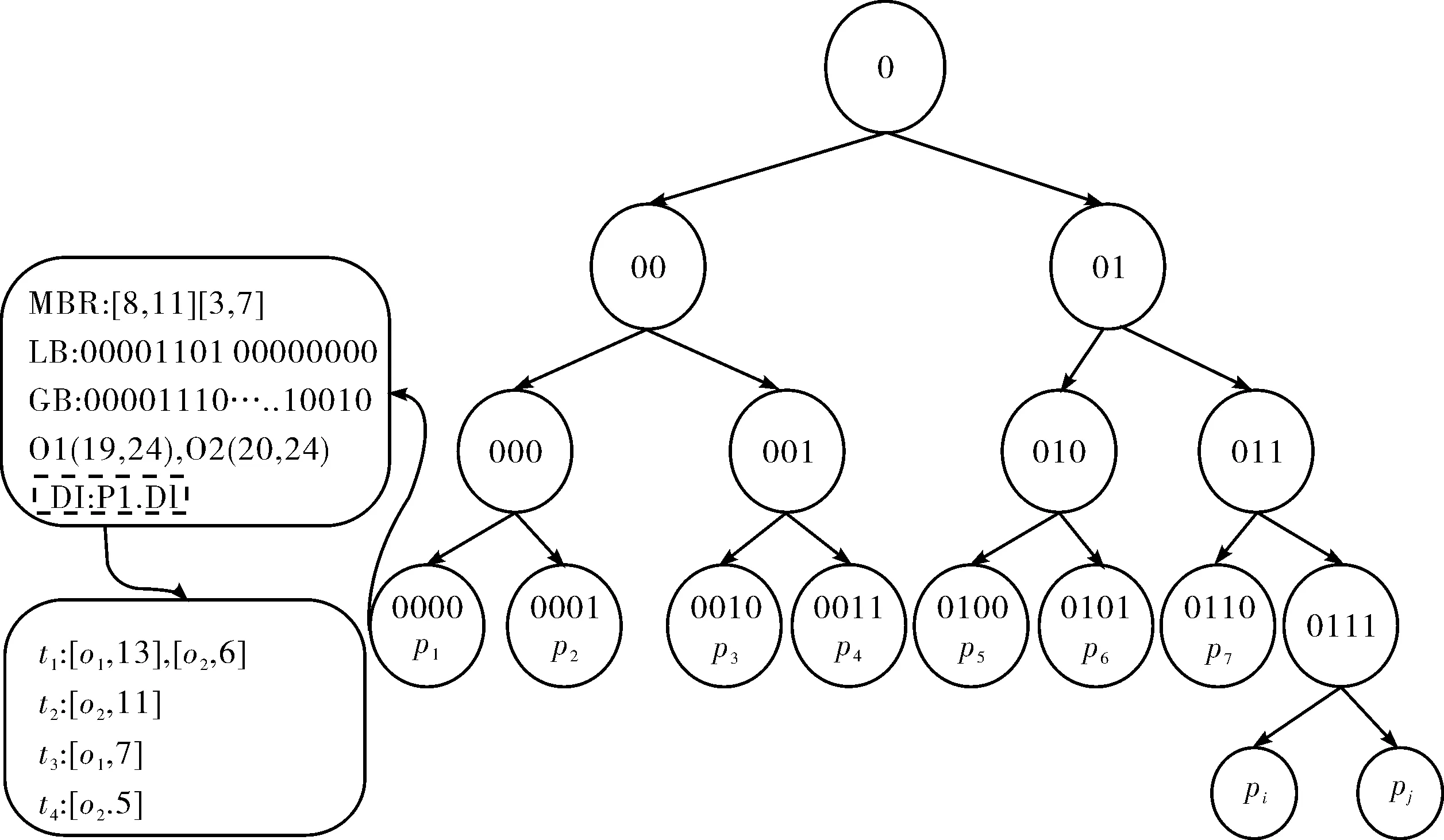
图4 MPB-tree索引结构Fig.4 MPB-tree index structure
该索引的建立借鉴二叉树创建过程,基本思路如下:自根节点而下,判断是否为空树,如果为空,创建一个新节点;如果不为空,先查询出适合插入的位置loc,然后计算config(pos,mask),判断新插入节点的莫顿码与loc中的有无差别,如果有,计算出新的pos和mask并重新设置;如果没有,初始化一个新节点,新节点中包含pos、mask及两个指针,并用相应指针指向下一个该创建的节点,以此类推构成MPB索引.
3.2 基于MPB-tree的模糊查询算法
为使得到的查询结果是空间位置上相近的,本文以查询范围递增的方式对周边区域进行检索,与Top-k算法[12]结合检索出一个初步结果集;之后在此基础上进行文本相关性计算,最终找出N个最符合要求的结果.
由Morton码的特点易知:两个POI点距离越近其共有前缀码越长,由此可以利用其前缀码进行近邻查询.但是在实际情况中可能存在查询点ql与对象点ol不完全对应的情况,为防止遗漏,在查询时不仅使用ql对应的编码进行检索,还对编码进行处理,使得其周围的8个区域也能被检索,算法每循环一次,都可以在上次的查询范围外再增加一层以目前节点莫顿码长度表示的范围,这样可以充分利用之前的查询结果,进而提高查询速率.算法过程如下:
算法1: 获取初始查询集,以及对应的空间相关性值
输入:查询点ql(lon, lat);MPB结构指针MPBptr;查询目标数Num;编码匹配范围Range
输出:含有Num个目标的初始结果Res.queue;
1 Initialization sequence Res.queue;
2 Initialization res.vec,Res.temp;
3 Cente r=MortonEncode(lon, lat,Range);
4 SearchRange=GetOther(Center);
5 do {
6 Search.number=MPBptr.search
(SearchRange, Res.temp,Range);
7 if(Search.number < Num){
8 res.vec=append(Res.temp);
9 Num=Num-Search.number;
10 }
11 else {
12 res.vec=CompSpaSimilarity
(res.vec, Num, Search.number);
13 Res.queue=sort(res.vec, K);
14 break;
15 }
16 Update(SearchRange);
17 } While(i)
18 return Res.queue;
在算法1中,第1行和第2行初始化一个结果队列及两个数组,用来保存查询结果.第3行到第17行先把经纬度数值转化成莫顿码,获取查询中心区域,并获取与中心查询区域相邻的查询范围.使用查询函数循环检索,得出一定数量的查询结果,并将目标信息存入Res.temp.其中第12、13行对查询到的点进行空间相似度比较,从而找出最接近的top-k个结果,然后存入到结果队列Res.queue中.循环执行,直至完成任务跳出循环.
为了找出与用户查询词内容相关的POI点,需要对算法1中得到的检索结果进行二次查询.基本思路是:从编辑距离为0的项开始查询,对SMKS内的所有关键词依次进行比较,统计出Res.queue内对应POI点的文本相关值,并存入相应队列内,循环查询直至遇到以下两种情形才结束:(1)在综合评分集合内已存在N个(N 算法2 :获取空间和文本均相关的查询结果集 输入:查询关键词集 SMKS{t1, t2,…,tn}, Res.queue,查询结果数N; 输出 :查询结果集Result 1 Initialization Search(); 2 Initialization sequence Result; 3 flag=true; ed=0; 4 while(flag){ 5 POIs=Search(ed,Res.queue, SMKS); 6 pre.queue=Process(POIs, pre.queue); 7 ed++; 8 if(ed > limit && pre.queue.size > N) 9 break; } 10 function Process(POIs, pre.queue){ 11 for each(POI in POIs ){ 12 for each(keyword in POI’s Inverted-file) { 13 score+=compere(keyword, POI); 14 pre.queue.append(score,POI) 15 if (pre.queue.size > N) 16 flag=false; 17 return pre.queue; 18 } } 19 } 20 Result=Compare(pre.queue, N); 21 return Result; 在算法2中,第4行到第9行从编辑距离为0的查询词开始进行处理,在第6行调用Process()方法对从算法(1)中得到的POI点逐个比较,第11行到第16行计算出相应查询词在其倒排文本中的文本相关程度,得出评分值,并将结果存入对应的位置,然后编辑距离加1进行循环计算,直至完成任务后跳出循环.第20,21行对所有符合条件的POI点进行综合相关性计算,返回最相关的结果集. 实验环境为:WIN8操作系统,CPU为Inter(R) Core(TM) i5 , 运行内存为4G.数据集通过微博API抓取,每条微博都包含发布的内容和发布时所处的位置,选取大约2万条空间数据,为能更顺利地测试,对每条信息内容进行过滤,删除其中的不规范网络词汇及特殊符号等.查询集由256个不同的关键词构成,查询地点和查询词都是随机任意选择,取多次试验数据的平均值作为最终结果. 图5 不同对象个数的存储空间Fig.5 The storage space of the number of different objects 如图5所示,莫顿码越长所表示的位置精度越高,但若是莫顿码过长会使得MPB-Tree索引中节点数增多,造成所需存储空间激增,同时这也使检索所花费的时间更长,影响查询效率.然而莫顿码太短又会使划分的查询区域过大,造成查询位置失真.根据实际需要,本文在实验时将莫顿码设置为32位. 图6表示查询关键词个数不同时SMFQ算法、精确查询算法、近似算法之间运行时间的变化.可以看出,随着查询词个数增加SMFQ算法明显具有较大优势,因为该算法用字符串匹配的方法替代以往的欧式距离计算方法,检索速度快,从而获得较高的查询效率. 图6 不同个数查询词的运行时间Fig.6 The running time of different number of query words 图7 不同查询结果数的满意度状况Fig.7 Satisfaction degree of different query results 图7表示用户对不同查询结果个数的满意度,本文让多名用户随机挑选3个查询关键词进行查询,然后对得到的结果进行满意度评分.首先把查询结果数设为10,使用3种查询算法进行查询并让用户对查询结果进行评分,可以看出,SMFQ算法获取的查询结果明显评分较高;随后将查询结果数设置为20,SMFQ算法还具有优势但是差距有所降低,随着查询结果数再次增大3者表现基本持平,这是因为SMFQ算法查询过程中已经对检索到的结果进行排序和剪枝,将最相关的结果优先提供给用户,所以在查询结果数较低时表现优异.但是当查询结果数超过一定范围后,一些相关性不高的信息也会被检索到,从而影响评分,但是在相同条件下SMFQ算法满意度评分仍较其他算法高,说明该算法在查询准确度上较传统算法有所提升,且将最相关结果优先提供给用户的方式也更符合用户的查询习惯. 本文在RB-Tree索引的基础上构建出支持多关键词模糊查询的MPB-Tree索引,并基于该索引设计出一种空间数据上的多关键词模糊查询算法,通过引入莫顿码、编辑距离,权重值等多种因子,给出相关查询及剪枝方法,从而实现空间和文本两方面的相关查询.由于采用新型的字符匹配方法替代传统的欧式距离计算来处理位置数据,从而提高了查询速度;同时在查询时充分利用MPB-tree索引中的各种位图信息,对初步结果集进行剪枝、排序,从而确保最终呈现给用户的结果集是综合相关度最高的集合.最后实验数据证明,该算法的查询效率及用户满意度上较其他算法有较大提升. [1] 刘喜平, 万常选, 刘德喜,等. 空间关键词搜索研究综述[J]. 软件学报, 2016,27(2):329-347. [2] YAO B, LI F F, Hadjieleftheriou M.Approximate string search in spatial databases[C]//Proc of the ICDE. Washington: IEEE, 2010: 545-556. [3] 余 艳, 林伟华, 谈晓军. 一种基于R-tree的空间索引方法[J]. 计算机工程, 2010,36(12):30-32. [4] 王金宝, 高 宏, 李建中, 等. RB树:一种支持空间近似关键字查询的外存索引[J]. 计算机研究与发展, 2012,49(10):2142-2152. [5] ZHANG D X , CHEN Y M, MONDAL A, et al . Keyword search in spatial databases: towards searching by document[C]//Proceeding of the 2009 IEEE international conference Data Engineering. Washington,DC:IEEE,Computer Society, 2009: 688-699. [6] 易显天, 徐 展, 郭承军, 等. 基于Patricia树的空间索引结构[J]. 计算机工程.2015,41(12):68-74. [7] 徐 明. 基于节点分裂优化的R-树索引结构[J]. 计算机应用研究, 2016,33(12):3530-3534. [8] 张文胜, 解 骞, 钟 瑾, 等. 基于八叉树邻域分析的光线跟踪加速算法[J]. 图学学报, 2015,36(3): 339-344. [9] 刘 义, 景 宁, 陈 荦, 等. Map Reduce框架下基于R-树的k-近邻连接算法[J]. 软件学报,2013(8): 1836-1851. [10] LONG C, WONG R C,WANG K, et al. Collective spatial keyword queries: a distance owner-driven approach[C]//Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data. New York: ACM,2013: 689-700. [11] 李 丹, 朱玲玲, 胡迎松. 基于最小生成树的多视图特征点快速匹配算法[J]. 华中科技大学学报(自然科学版),2017,45(1):41-45. [12] 胡 俊, 范佳明. 空间数据上的Top-k模糊查询研究[J].计算机学报, 2012,35(11):2237-2246. Researchonmulti-spatialkeywordFuzzyqueryalgorithmbasedonMPB-Tree ZHANG Suzhi, ZHAO Yanan,YANG Rui (School of Computer and Communication Engineering, Zhengzhou University of Light Industry, Computer Applications and Software, Zhengzhou 450002, China) With the extensive use of smart devices with location function, a large amount of spatial data is produced, and more and more textual information are included in each datum. However the previous algorithm is only a single text word query and difficult to meet the demands of users. To address the above problem, in this paper, a multi-keyword Fuzzy query algorithm is proposed. In this algorithm, the traditional two-dimensional spatial distance calculation is transformed into Morton code matching to speed up the query efficiency, and the fault-tolerant query is supported by combining the Fuzzy algorithm. Experimental results show that the algorithm has better efficiency and accuracy than the previous query algorithm. spatial data; multi-keyword query; Morton codes; Fuzzy query 2017-04-02. 国家自然科学基金项目(616772470);北京市重点实验室开放课题(BKBD-20171408). *E-mail: 2680732805@qq.com. 10.19603/j.cnki.1000-1190.2017.06.007 1000-1190(2017)06-0765-07 TP392 A4 实验及性能分析
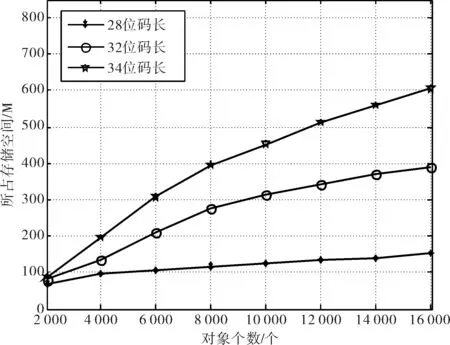
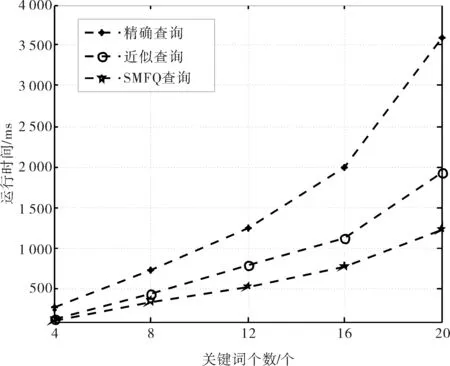

5 结语
