基于移动用户浏览行为的推荐模型
2017-12-22郑文韬秦志光
丁 哲,秦 臻,郑文韬,秦志光
基于移动用户浏览行为的推荐模型
丁 哲,秦 臻,郑文韬,秦志光
(电子科技大学信息与软件工程学院 成都 610054; 电子科技大学网络与数据安全四川省重点实验室 成都 610054)
推荐算法已经被广泛地应用于很多领域。但是如果利用传统的推荐算法预测移动用户浏览互联网的行为,并在此基础上对移动用户进行个性化的内容推荐,传统推荐算法的推荐效果往往比较差。该文通过分析移动用户浏览互联网的记录,得出传统推荐算法效果差的原因。在此基础上,提出了一个基于移动用户浏览行为的推荐模型,即RMBDMU。该模型可以对移动用户浏览互联网的行为进行预测,在预测的基础上对移动用户进行内容推荐。为了验证推荐模型的有效性,在真实的移动用户浏览互联网的行为数据上进行了实验。实验结果显示基于移动用户浏览行为的推荐模型比传统的推荐算法更为有效。
移动用户; 浏览行为的预测; 概率频繁项集挖掘; 推荐模型
随着手机应用的普及,移动技术已经成为人们生活中不可或缺的一部分。人们利用手机通讯、浏览网上的信息等,使电商和移动运营商掌握了大量移动用户上网行为的数据。如何利用这些数据预测移动用户的上网行为,并在预测的基础上对用户进行内容推荐成为了学术界的研究热点。目前大部分电商网站,如淘宝、亚马逊等,都利用所掌握的用户数据为用户提供产品推荐
与传统的用户购买记录和用户评分记录不同,移动用户浏览互联网信息的行为记录存在很大不确定性。这就导致了传统的基于用户购买或评分数据的推荐算法不适用于基于移动用户浏览行为的推荐。移动用户常常为了完成一个自己相对陌生的临时任务,需要利用手机在互联网上浏览大量相关的信息。当这项工作完成以后,该用户很少浏览相关信息。例如,一个移动用户去伦敦度假,他会利用手机在互联网上浏览大量关于伦敦旅游景点的信息。当他度假回来,可能就很少关注伦敦旅游景点的信息。移动用户在互联网上的大部分浏览行为都是为了完成这种临时性的任务而产生的,所以移动用户浏览大部分互联网信息的原因并不是自己的兴趣,而是这种临时的需求,这就导致了移动用户浏览行为记录存在很大的不确定性。所以很难利用传统的推荐算法发现用户真正感兴趣的互联网信息。为了能够从移动用户浏览行为的记录中发现移动用户的兴趣,本文提出一种新的基于移动用户浏览行为的推荐模型(recommendation model based on mobile user behaviors, RMBDMU)。该模型不仅分析了移动用户浏览互联网信息的次数,还分析了移动用户关注互联网信息的天数,从而分析出移动用户的兴趣。本文有以下3个贡献。
1) 通过分析移动用户浏览互联网信息的记录,发现造成传统推荐算法无法有效地应用于基于移动用户浏览信息推荐的原因。
2) 提出一种新的基于移动用户浏览行为的推荐模型(RMBDMU)。
3) 在真实的移动用户浏览行为的数据上对提出的推荐模型进行实验,实验结果表明该推荐模型比传统的推荐算法更为有效。
1 相关工作
最常用的协同过滤推荐算法是建立在邻居模型的基础上。最早的基于邻居模型的协同过滤推荐算法是基于用户邻居的协调过滤推荐算法[1]。如果将基于用户邻居的协同过滤推荐算法应用于电商系统,该算法需要大量的计算量,这就导致了推荐效果较差。为了解决这一问题,基于项目邻居的协同过滤算法得到广泛的应用[2-3]。
基于隐语义模型推荐算法,如奇异分解,也是一种常用的协同过滤模型。隐语义模型中,隐因子建立用户兴趣和商品之间的联系[4-5]。文献[6]在SVD中引入了自信度,并提出基于隐反馈的推荐算法。文献[7]利用价格之间的联系处理推荐算法中的冷启动问题。
频繁项集挖掘是数据挖掘中的一个重要的分支。1993年,文献[8]提出了Apriori算法。为了提高项集挖掘的效率,文献[9]提出了基于FP树挖掘算法,基于FP树挖掘算法相对Apriori算法,减少了挖掘频繁项集的运行时间和所需的空间。虽然Aprior和基于FP树挖掘算法得到了广泛的应用,但Apriori算法和基于FP树的挖掘算法很难直接应用于基于不确定数据集的频繁项集挖掘。在2007年,文献[10]提出了期望支持度的方法来计算项集在不确定数据集中的支持度。文献[11]提出了频繁概率来计算项集在不确定数据集中的支持度。本文利用频繁概率作为频繁度的度量。文献[12]提出了一种新的挖掘概率频繁项集的方法,该方法可以挖掘出由项集组成的集合,包含项集的个数最少,但包含的所有频繁项集的概率很高。而文献[12]中计算频繁概率的方法则是建立在泊松二项分布的相关理论[13-15]基础上。
2 数据分析
本文根据互联网信息的内容对互联网信息进行分类。由于移动用户浏览互联网信息的原因很多,并且在一时间段,移动用户关注的时间不一定随着浏览的次数增加而增加。所以传统推荐算法很难在浏览数据中发现移动用户的兴趣。
2.1 数据描述
本文应用的数据是31660个用户3个月的智能手机应用程序日志,这些数据来源于网络运营商。当智能手机的应用程序访问互联网的资源时,就会生成其访问资源的记录。所使用的数据包括179 954181个访问记录,每个记录是由表示其用户ID和被访问互联网资源的数字编码组成。通过使用正则表达式对不同关键字的匹配,得到了与被访问的互联网资源相匹配的主题。本文按照主题对信息进行分类,如体育类、金融类等。通过分析31660个移动用户在2013年10月的浏览数据,发现移动用户的浏览特征。
2.2 关注时间分析

图1 关注时间对比分析
通过分析31660个移动用户在2013年10月浏览网络信息的日志,获得移动用户浏览行为的特点。在2013年10月中,不同的关注天数的主题占2013年10月关注所有主题的人均百分比如图1所示。在图1中,横坐标表示移动用户对主题的关注天数,纵坐标表示关注相应天数的主题数占2013年10月总关注主题数的人均百分比。从图1可以看出,在10月份,移动用户浏览的不同主题的信息,大部分主题只关注1~3天,即关注1~3天的主题数占10份关注总主题数的42%。随着关注时间的扩大,关注主题数急剧下降。当关注时间大于20天后,关注的主题数目趋近于平稳,约占10月份关注总主题数的5%。
2.3 浏览次数分析
分析不同关注天数的主题的人均浏览次数,如图2所示。通过分析图2,可以发现在2013年10月,移动用户对主题的浏览次数并不一定随着关注时间的增加而增加。
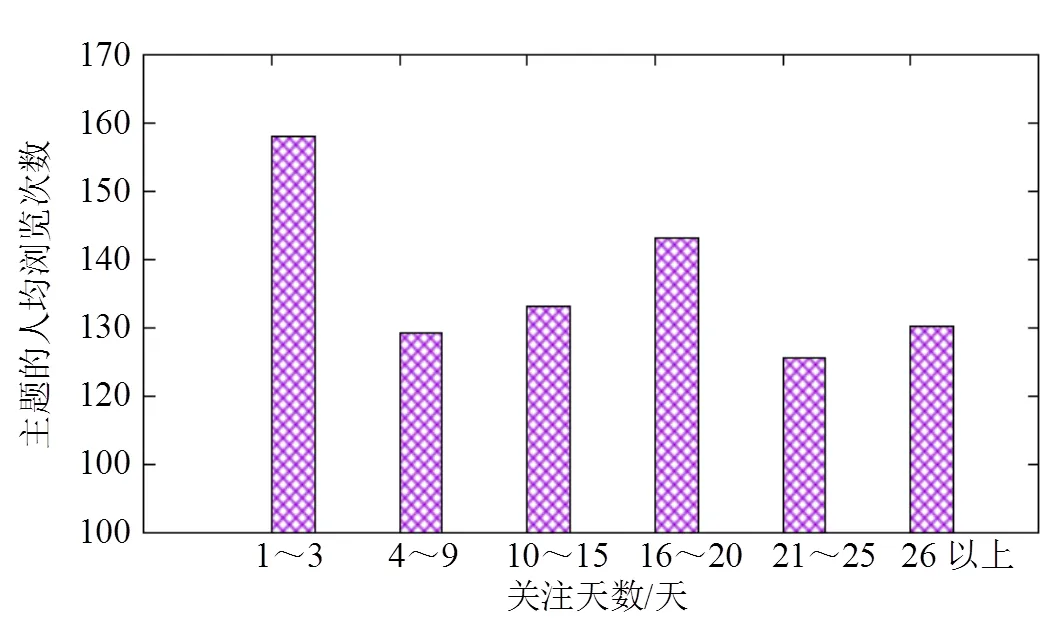
图2 浏览次数对比
通过上述分析,可以得出:1)移动用户关注大量的互联网信息,但是只有很少的一部分是与该用户的兴趣相关的;2) 在一段时间之内,移动用户浏览次数多的互联网信息不一定与该用户的兴趣相关联。
3 推荐模型
本文提出一个新的基于移动用户浏览行为的推荐模型(RMBDMU)。该模型建立在概率频繁项集挖掘的基础上,发现移动用户对于不同主题的互联网信息的兴趣度,然后根据兴趣度的大小,将主题以递减的方式排序,最后将前个主题推荐给移动用户。
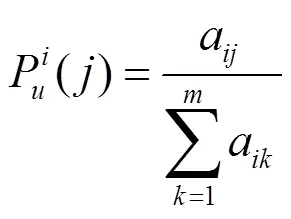
为了使模型有更好的推荐效果,本文从两方面对第个主题信息的兴趣度的预测结果进行优化。
1) 利用用户邻居对用户的兴趣度进行优化
如果不同的移动用户具有相似的行为,那么他们的兴趣也可能相似,所以利用皮尔森相似度来对移动用户行为的相似性进行度量,从而发现每个移动用户的邻居用户,利用邻居用户对用户的兴趣度进行优化。
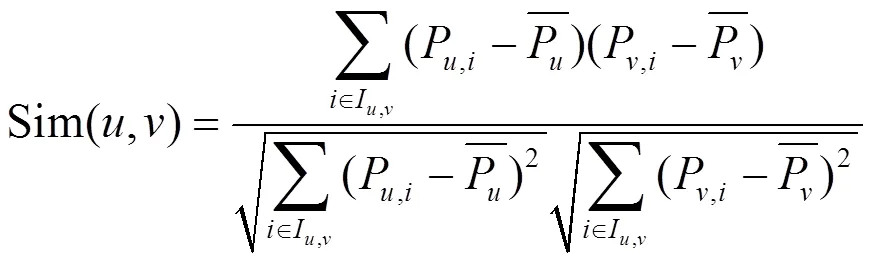
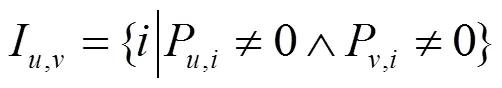
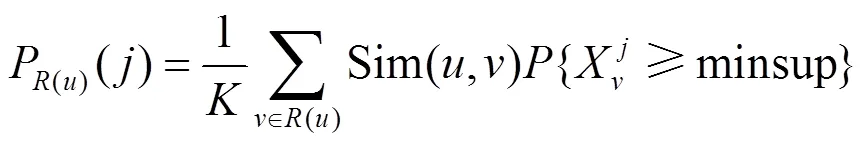
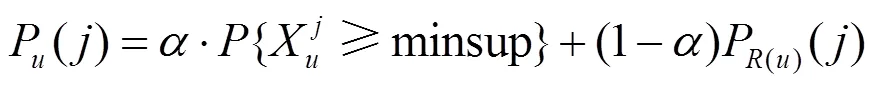
2) 利用主题邻居对用户的兴趣度进行优化
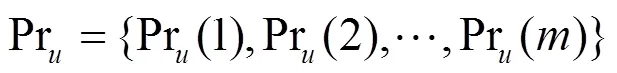
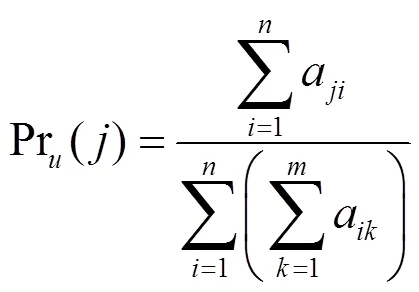
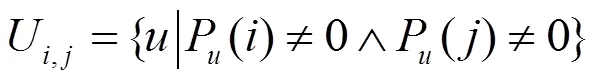
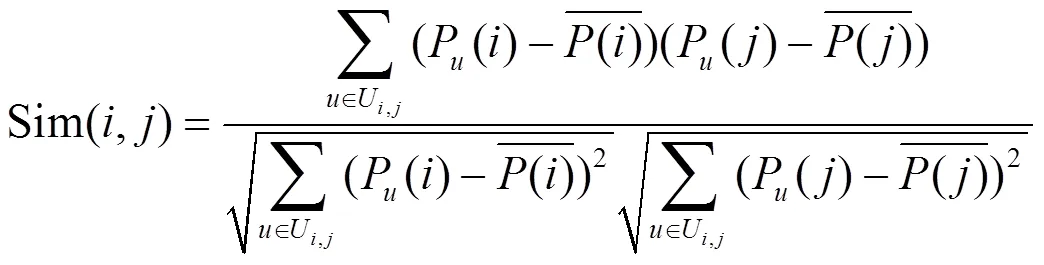
利用皮尔森相似度,可以找到第个主题的前个邻居,从而利用式(8)得到对于第个主题,基于邻居主题的关注度。最终利用式(9)优化用户对第个主题关注度。其中是控制权重的参数。
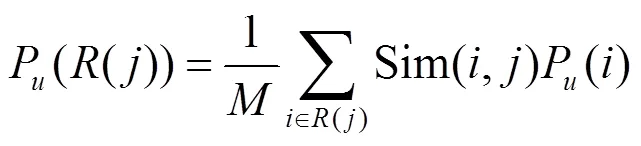
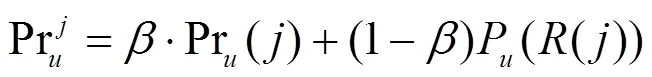
最后关于用户对第个主题的兴趣度,即Interesing()的预测结果是(是控制权重的参数):

4 实验评估
4.1 评估度量
本文利用移动用户的人均1值和在测试集中,移动用户人均浏览推荐主题的平均浏览次数,对测试结果进行评估。1值是融合了正确率和召回率的指标,即是准确率和召回率的调和平均值[14]。人均1值如式(12)所示,其中表示用户的人数,Precision表示对第个用户推荐的准确率,即对第个移动用户推荐,并且被该用户浏览的主题占为第个用户推荐的全部浏览主题的百分比,Recall表示对第个用户推荐的召回率,即对第个移动用户推荐,并被该用户浏览的主题占总该移动用户浏览总主题数的百分比。
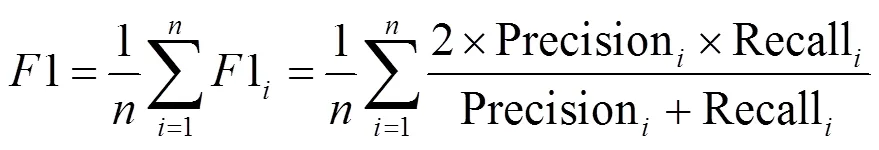
4.2 参数调节
利用2013年10月15日-2013年10月31日的浏览数据作为训练集,2013年10月1日-2013年10月14日的浏览数据训练模型中的参数。
1) 对于参数和参数的调节:为了评估随着用户邻居数的变化对模型的推荐效果的影响,设置和为0.1,minsup为1,和为5,的范围从1~20。实验结果显示当大于等于5时,人均1值达到稳定,所以设置等于5。在评估主题邻居数对推荐效果的影响时,设置和为0.1,minsup为1,为10,为5,从1~20,实验结果显示当≥5时,人均1值达到稳定,设置为5。
2) 对于参数和进行调节,设minsup为1,、和为5,当测试对推荐效果的影响时,和为0.1,的取值范围从0.1~1。实验结果显示当≥0.7时,人均1值达到稳定,即52.8%,所以设置为0.7,当测试对推荐效果的影响时,设置为0.7,的取值范围是从0.1~1。实验结果显示当≥0.8时,人均1值达到稳定,即55.8%,所以设置为0.8。
3) 最大推荐主题数: 为了评估最大推荐数,设minsup为1,为0.7,和为5,为0.8,为0.1。的取值范围是从1~20,随着的增加,推荐效果有很大的改进。当≥10,推荐效果达到稳定状态。此时人均1值为53.41%。所以设的最大值为10。
4) 参数:为了评估的变化对推荐效果的影响,设为10,为0.7,和为5,为0.8,minsup为1。在实验中的取值范围从0.1~1。实验结果显示人均1值随的增大而增大,当等于0.9时,人均1值达到最大,所以实验值设置为0.9。
5) 最小关注天数minsup:为了发现最小关注天数变化对推荐结果的影响,设等于10,为0.7,和为5,为0.8,等于0.9。minsup从1~15。实验结果显示,人均1值随minsup的增大而增大,当minsup≥13时,人均1值达到稳定值。所以设置minsup为13。
4.3 实验结果分析
本文有4个对比实验,分别是:1) 基于项目邻居的协同过滤推荐算法(collaborative filtering recommendation model based on item neighbors, CFRMIN)。该算法利用皮尔森相似度寻找用户浏览过的主题的邻居,然后利用用户浏览过的主题的邻居集合去预测用户对自己浏览过的主题的感兴趣程度[6]。2) 基于隐语义模型的推荐算法(rcommendationmodel based on latent factor model, RMLFM)[4]。3) 基于浏览次数的推荐算法(rcommendation model based on browsing times, RMBT),即将所有用户浏览过的主题按用户浏览次数,以递减的顺序排序,将前个推荐给用户。4) 基于用户关注天数的推荐算法(recommendation model based on concerning a number of days, RMCD),即将用户浏览过的主题按用户关注的天数,以递减的顺序排序,将前个推荐给用户。
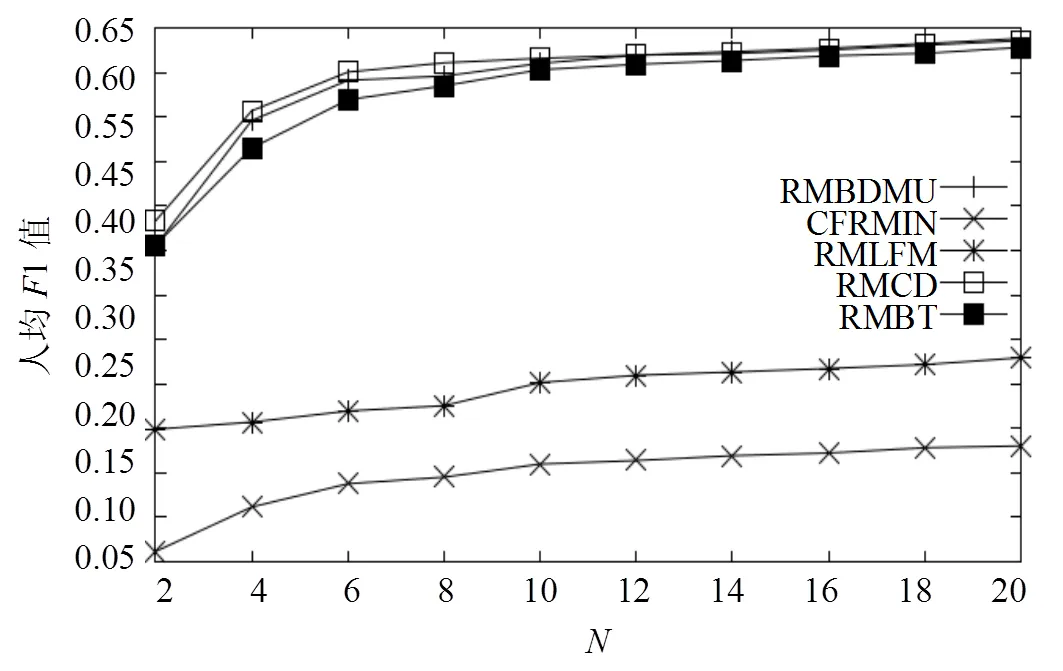
图3 第1组实验的移动用户人均F1值
本文通过两组实验测试模型的有效性。1) 利用31660个移动用户2013年10月日-2013年10月31日的浏览数据作为训练集。并以2013年11月的浏览数据作为测试集,测试结果如图3和图4所示。2) 训练集和参数不变,以2013年12月的浏览数据作为测试集,测试结果如图5和图6所示。本文提出的推荐模型(RMBDMU)的实验效果总体优于CFRMIN和RMLFM的实验效果。正如第2.3节提到的,首先移动用户关注的大量信息中,只有很少的一部分是和他的兴趣相关的,其次,在一段时期,移动用户浏览越多的信息,可能不是与其兴趣相关的。所以寻找主题之间的关系,是非常困难的。CFRMIN和RMLFM都是基于主题之间的相互关系的,所以效果很差。图3和图5中,可以看出当等于2时,RMBDMU的人均1值分别是0.443和0.412。随着的增大,RMBDMU的人均1值逐渐的增大。当大于等于8时,RMBDMU的人均1值到达稳定,分别是0.594和0.591。虽然RMBDMU的人均1值随着值得增大而增大,但是RMBDMU的人均1值与RMCD和RMBT的人均1值非常接近。这说明RMBDMU推荐的主题和RMCD和RMBT推荐给用户的主题,用户都有关注。但是图4和图6显示,用户人均对RMBDMU推荐主题的平均浏览次数远远大于用户人均对RMCD和RMBT推荐给用户主题的平均浏览次数。这说明RMBDMU推荐给用户的主题,用户的关注度更高。

图4 第1组实验用户人均浏览推荐主题平均浏览次数
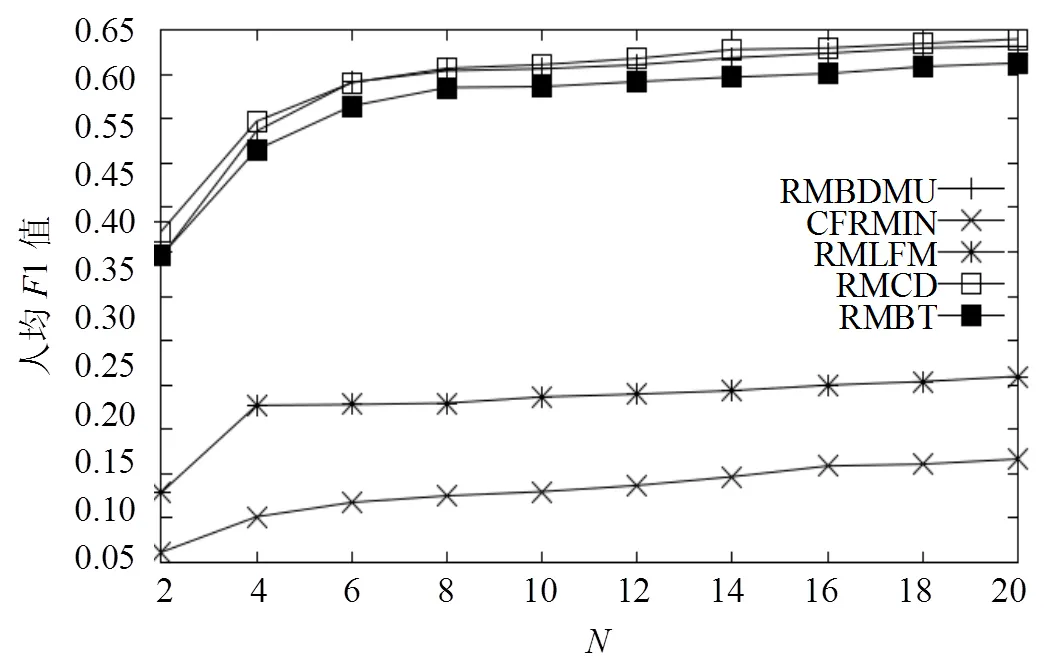
图5 第2组实验的移动用户人均F1值
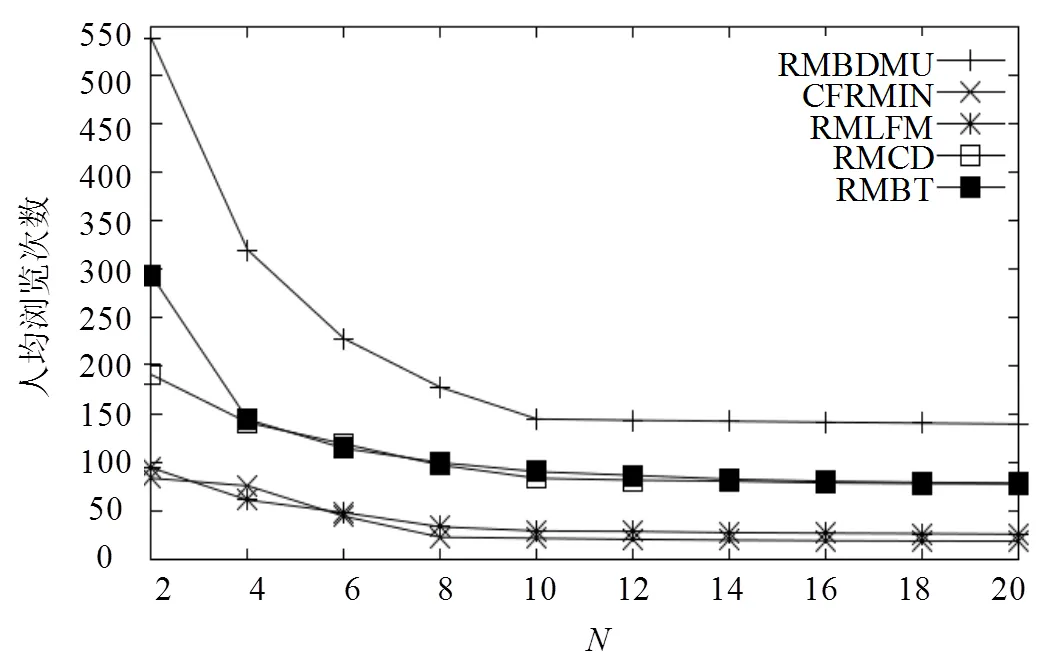
图6 第2组实验用户人均浏览推荐主题平均浏览次数
5 结束语
本文首先分析传统推荐算法无法在移动用户上网浏览数据上进行有效内容推荐的原因。然后提出了一种基于移动用户浏览行为的推荐模型。通过在真实的移动用户浏览数据上进行测试,实验验证了模型的有效性。
[1] HERLOCKER J L, KONSTAN J A, BORCHERS A, et al. An algorithmic framework for performing collaborative filtering[C]//Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. Berkeley: ACM, 1999: 230-237.
[2] SCHAFER J B, DAN F, HERLOCKER J, et al. Collaborative filtering recommender systems[C]//The Adaptive Web, Methods and Strategies of Web Personalization. Berlin, Heidelberg: Spring, 2015: 46-45.
[3] SARWAR B, KARYPIS G, KONSTAN J, et al. Item-based collaborative filtering recommendation algorithms[C]// Proceedings of the 10th International Conference on World Wide Web. Hong Kong, China: ACM, 2001: 285-295.
[4] FUNK S. FunkSVD [EB/OL]. (2006-12-11). http:// sifter.org/∼simon/journal/20061211.html.
[5] KOREN Y, BELL R. Advances in collaborative filtering[M]. Recommender Systems Handbook. New York: Springer, 2011.
[6] HU Y, KOREN Y, VOLINSKY C.Collaborative filtering for implicit feedback datasets[C]//Eighth IEEE International Conference on Data Mining. Pisa: IEEE, 2009: 263-272.
[7] CHEN J, JIN Q, ZHAO S, et al. Does product recommendation meet its waterloo in unexplored categories: no, price comes to help[C]//Proceedings of the 37th International ACM SIGIR Conference on Research & Development in Information Retrieval. Gold Coast: ACM, 2014:667-676.
[8] AGRAWAL R SRIKANT R. Fast algorithm for mining association rules[J]. Journal of Computer Science & Technology, 1994, 15(6): 619-624.
[9] HAN J, KAMBER M, PEI J. Data mining: Concepts and techniques[M]. Netherlands:Elsevier, 2011.
[10] CHUI C K, KAO B, HUNG E. Mining frequent item sets from uncertain data[J]. 2007, 4426: 47-58.
[11] LEUNG K S. Uncertain frequent pattern mining[M]. Frequent Pattern Mining. New York: Springer International Publishing, 2014.
[12] LIU C, CHEN L, ZHANG C. Summarizing probabilistic frequent patterns: a fast approach[C]//ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Chicago: [s.n.], 2013: 527-535.
[13]BERNECKER T, CHENG R, CHEUNG D W, et al. Model-based probabilistic frequent itemset mining[J]. Knowledge and Information Systems, 2013, 37(1): 181-217.
[14] WANG L, CHEUNG D W L, CHENG R, et al. Efficient mining of frequent item sets on large uncertain databases[J], IEEE Transactions on Knowledge and Data Engineering, 2012, 24(12): 2170-2183.
[15] CAM L L. An approximation theorem for the Poisson binomial distribution.[J]. Pacific Journal of Mathematics, 1960, 10(4): 1181-1197.
编 辑 蒋 晓
A Recommendation Model Based on Browsing Behaviors of Mobile Users
DING Zhe, QIN Zhen, ZHENG Wen-tao, and QIN Zhi-guang
( School of Information and Software Engineering, University of Electronic Science and Technology of China Chengdu 610054; Network and Data Security Key Laboratory of Sichuan Province, University of Electronic Science and Technology of China Chengdu 610054)
Recommendation algorithms have been commonly adopted in many fields. However, traditional recommendation algorithms fail to achieve the expected recommendation results if they are applied to predict browsing behaviors of the mobile users and further to recommend personalized content to the mobile users. By analyzing the Internet browsing data of the mobile users, this paper proposes a recommendation model based on browsing data of mobile users, denoted as RMBDMU, to predict the future browsing activities of the mobile users and take them as the bases to recommend contents to the mobile users. An experiment on the Internet browsing behavior data of the real mobile users is conducted to verify the effectiveness of the model. The experiment result shows that the recommendation model based on browsing data of mobile users is more effective than the traditional recommendation algorithms.
mobile users; prediction of browsing behaviors; probabilistic frequent itemset mining; recommendation model
TP393
A
10.3969/j.issn.1001-0548.2017.06.020
2016-07-21;
2016-12-15
国家自然科学基金( 61133016, 61300191, 61202445, 61370026);四川省科技支撑计划(2014GZ0106, 2016JZ0020)
丁哲(1982-),男,博士生,主要从事机器学习、推荐算法和信息安全方面的研究.
