基于关键点检测的文档文本定位算法研究
2017-12-20完颜勇王宗贤
完颜勇,王宗贤
(北方工业大学 城市道路交通智能控制技术北京市重点实验室,北京 100144)
基于关键点检测的文档文本定位算法研究
完颜勇,王宗贤
(北方工业大学 城市道路交通智能控制技术北京市重点实验室,北京 100144)
文本中的定位是文本提取的前提和基础,文中针对手机拍摄的文档文本定位易受背景和文档自身质量干扰的问题,根据文档文本的特性,提出了一种基于关键点检测的文档文本定位算法。算法使用二值化算法对文档文本进行增强处理,运用FASText关键点检测方法实现对文本的局部定位,运用文档文本的特性去除伪关键点,进行连通域检测和非最大值压制,获取文本候选区域;训练高、低精度两个文本分类器,对得到的文本候选区域进行双阈值分类,将候选文本集分为强文本集、弱文本集和非文本集;在弱文本集中,根据文本相似的特征,寻找与强文本集中相似的文本,去除虚假文本,提高定位精度。实验结果证明,该算法可以快速、精确地实现对文档文本的定位。
文本定位;关键点;双阈值分类;非最大值压制;分类器
随着智能手机的普及,使得人们获取数字图像变得更加地便利,图像中文本的提取蕴含着巨大商业和应用价值。然而,由于人们基于手机等便携式设备拍摄图像的随意性,所拍摄的文本图像会受到光照、背景、拍摄角度等诸多因素的影响,文本定位具有更多的难度和不确定性,定位精度无法达到较高的水平。
文本定位的算法主要可分为基于滑动窗口的算法和基于连通区域的算法。基于滑动窗口的算法[1-5]是将多尺度窗口在图像中所有可能出现文本的位置上进行滑动,提取滑动窗口梯度、纹理、变换域等特征,然后设计分类器进行分类;该类算法精确度与鲁棒性较好,但算时间复杂度通常比较高。基于连通区域的算法[6-10]是首先根据图像像素属性的相似性对像素进行聚合,形成大量的文本候选区域,然后运用几何约束条件或者分类器来获得文本区域;该类算法时间复杂度低,在背景简单的情况下能取得较好的文本检测效果。
文中结合文档文本的特性,应用FASText关键点检测算法[11],实现对文本的局部定位;根据文本的颜色特征将K均值聚类算法[12]应用到关键点检测的结果中,剔除一些误检测的关键点;通过连通域检测,将获取的候选文本进行非最大值压制,来消除文本的重复检测;训练高、低精度两个Adaboost分类器[13],对候选文本集进行双阈值分类,得到强、弱和非3个候选文本集,根据文本的相似特性,在弱候选文本集中找出与强候选文本相似的文本,作为检测结果。
1 文档文本候选区域的生成
1.1 关键点检测
1.1.1 FASText关键点
Fast关键点检测算法[14]检测出的特征具有平移和旋转不变形、快速等特点,广泛应用于目标检测中。Fast关键点检测算法应用于文本的关键点检测时,往往聚焦于文本笔画的转角(如:字母‘L’)和端点(如:字母‘l’),不能检测出笔画没有转角和端点的文本(如:字母‘0’)。
考虑到文本定位精度取决于文本笔画的检测,引入了两类关键点:笔画端点关键点(the Stroke Ending Keypoint,SEK)聚焦于笔画端点和笔画弯曲关键点(the Stroke Bend Keypoint,SBK)聚集于笔画弯曲处。两类关键点如图1所示,左图为SEK关键点,右图为SBK关键点。
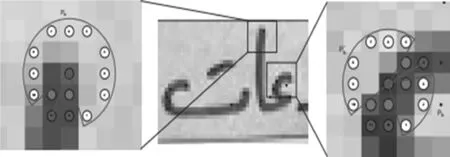
图1 FASText关键点
对图像中任一像素p,强度为Ip,以像素p为中心,两个像素宽为半径的圆上的12个像素x∈{1,2,…,12},根据其像素强度与Ip之间的关系,将像素x标记为下列3种标签之一
(1)
m的取值影响关键点检测的不精确和文本漏检率,m取值越大,文本的漏检率越小,但同时会造成较高的不精确度,反之漏检率较大,不精确度较低。
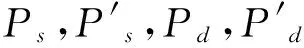
1.1.2 文档图像的二值化处理
由于文档图像自身的质量和手机拍摄状况的影响,文档图像可能会出现背景文本的渗透、阴影、污点、文本的对比度较弱等现象,为减少文档图像的质量对文档文本定位的影响,文中采二值化算法对文档图像进行增强处理,二值化的处理算法如下:
算法1
步骤1使用形态学闭运算对文档图像进行处理,得到背景估计图像;
步骤2背景估计图像减去原文档图像,消除背景对文档的影响;
步骤3使用双边滤波滤去噪声,对步骤2得到的图像进行Ostu二值化处理;
步骤4使用Sauvola算法对原文档图像进行二值化处理;
步骤5对步骤3和步骤4得到的图像进行与运算。
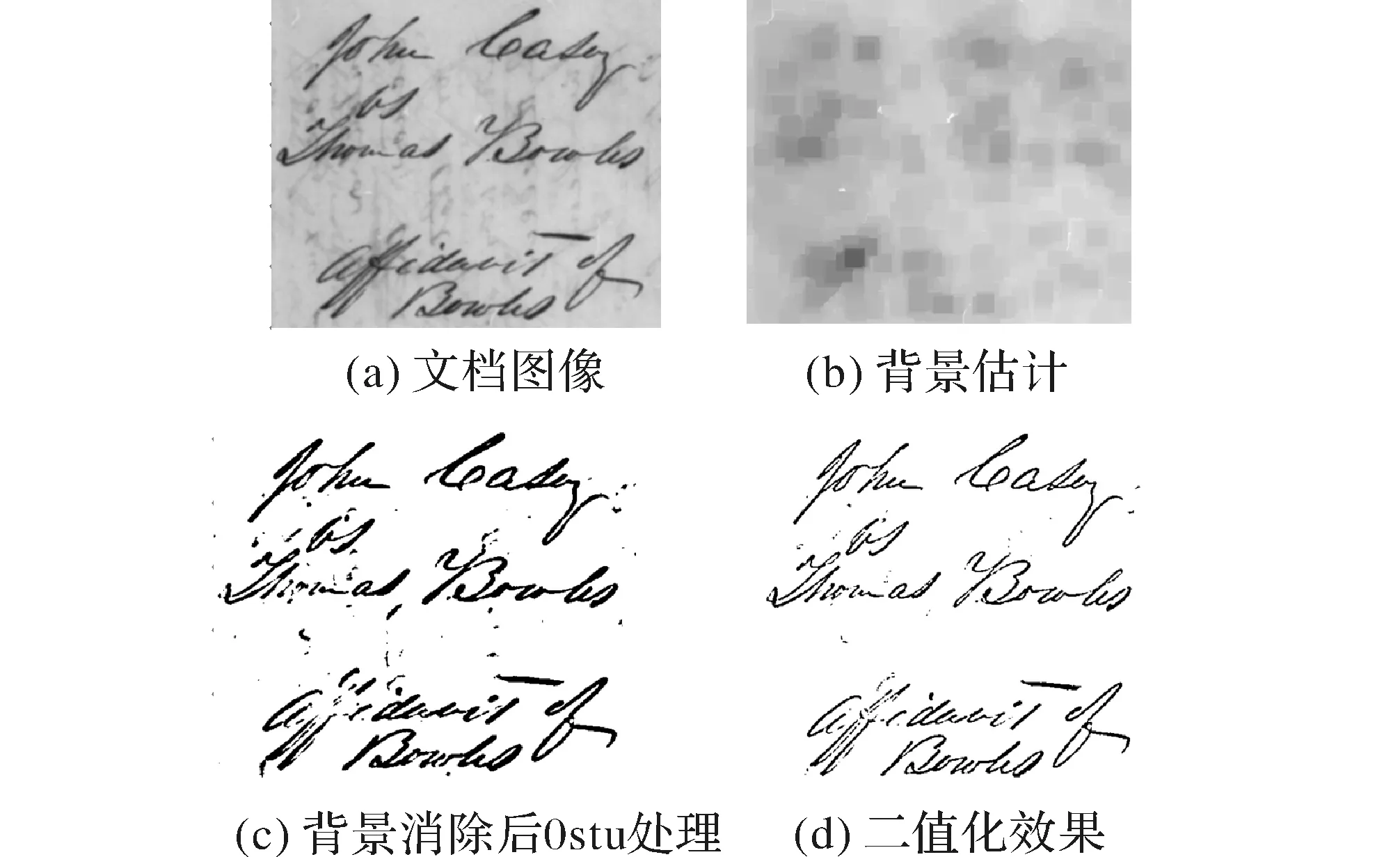
图2 文档图像的二值化处理
1.1.3 文档文本的关键点检测
Fast关键点检测器仅能检测出文本笔画宽度为两个或者3个像素的文本,为了检测出不同尺度图像中的文本,需对文档的二值化图像进行多级降采样处理,在每一级降采样子图中进行关键点检测,降采样的系数为1.6。
根据文档图像中文本笔画宽度的变化范围较小的特性,为减少文本的重复检测,计算每一级子图上关键点的数目,保留关键点数目最多的子图及它上两级和下两级子图中的关键点。
1.1.4 伪关键点的滤除
基于手机获取的文档图像往往处于不同的背景中,在背景中检测出的关键点对文本检测造成一定的干扰。由于文本中的关键点的分布比较集中且具有一定的规律,结合文本的特性,使用下列条件对关键点进行过滤:
(1)文档图像中文本行都是按行排列的,统计每行的关键点数目,若该行的关键点数目<5,则将该行的关键点滤去;
(2)为了防止成片的噪音对文本检测的干扰,在以关键点为中心,大小为25×25文档图像子块中,若关键点的数目<3,则将该关键点滤除。结合同一文档中文本色彩相近的特性,使用K均值聚类算法在原文档图像中对关键点进行聚类,进一步对关键点滤除,具体算法流程如下:
算法2
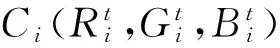
步骤2计算每个像素P(Rp,Gp,Bp)与第i个聚类中心的颜色距离Di,根据式(2)和式(3)对像素P所属的类别进行判定
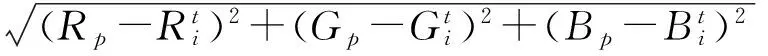
(2)
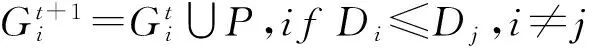
(3)
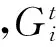
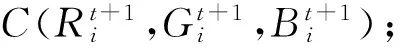
步骤4重复步骤2和步骤3,直到每个聚类中心颜色均值分量不再改变。
1.2 文本候选区的生成
1.2.1 文本候选区域的获取
使用上述关键点检测算法,获取关键点的位置信息,在文档的二值化图像中以关键点为种子点,采用漫水填充算法[15]来获取文本候选区域。通过观察,文档文本具有一定的几何特征。文本区域的长宽比不应超过10,文本区域长度或宽度应在10~300像素之间。
1.2.2 非最大值压制
应用Fast关键点算法检测文本的关键点时,同一个文本在不同级的降采样子图中可能均会被检测出关键点,出现文本被重复检测的现象。为保持文本检测的独特性,利用式(4)进行非最大值压制,来消除重复检测现象
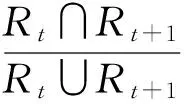
(4)
其中,Rt、Rt+1分别为由第i级、第i+1级降采样子图检测出的关键点形成的文本候选区域。当S(Rt,Rt+1)≥0.8时,保留Rt、Rt+1面积较大的区域,删除另一区域。
2 文档文本定位算法
基于上述算法获取的候选文本集,包含了大量的非文本区域,为了提高文本定位的精度,引入Adaboost分类器对候选文本集进行分类处理。
2.1 文本特征选取
文本特征选取,对分类器的性能有着至关重要的影响,4个特征被用于训练Adaboost 分类器:占空比、HOG特征、字符笔画面积比例、平均局部二值模型。占空比表示候选文本区域的面积与其外接矩形面积之比。
字符笔画面积比例是计算字符笔画的面积与整个候选文本像素面积的比例,能够有效的区分文本片断和背景区域。
给定的文本候选区域R,SEKR为区域R的SEK的集合,对任一P∈SEKR,由算法2求出p对应的连续笔画关键点的集合SSKp。
算法3
步骤1以p为起始点,沿着背离笔画端点的方向,将p移动至p对应的ps中最暗(或最亮)的点上;
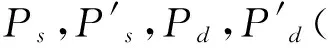
步骤3若p为连续笔画关键点,则重复操作步骤2,否则终止操作。
字符笔画面积As(R)由式(5)计算可得
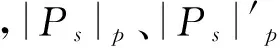
平均局部二值模型是局部二值模型的一个变化,对光照和旋转变化具有很强的鲁棒性。平均局部二值模型的计算方法:对候选文本中的任一元素p,计算以p为中心的3×3子块中,p的8连通区域的像素强度均值;如果p的8连通区域中像素强度比均值大,则置为1,否则置为0;然后从子块中的左顶点开始,顺时针将上述8连通区域每个像素点对应的值,放入一个8位的字节中进行编码。
2.2 分类器设计及双阈值分类
本文选用了基于手机在不同背景和光照条件下拍摄的500张文档图像作为图像数据库,其中300张作为训练图像,另外200张作为测试图像。在300张训练图像中截取了3 100个正样本和8 200个负样本作为分类器的训练样本,所有样本均一化为64×32像素的灰度图。
为了提高文本定位的召回率和精度,文中应用Adaboost算法训练一种多级联分类器,该分类器有两个级联分类器组成,第一个级联分类器为高精度Adaboost分类器,使用占空比、HOG特征、文本笔画面积比例和平均二值化模型特征进行训练,对样本集的分精度为99%。第二个级联分类器为低精度Adaboost分类器,使用占空比、HOG特征[16]、文本笔画面积比例等特征进行训练,对样本集的分精度为87%。
在双阈值分类中,高精度分类器对应的是高阈值,低精度分类器对应的是低阈值。候选文本集经过第一级分类器后,被分类为强文本集和非强文本集,由于高精度分类器的分类精度高,非强文本集中可能存在文本集。为了提高文本定位的精度,非强文本集经过第二级分类器进行分类,被分类为弱文本集和非文本集。
2.3 文本相似性追踪
由于强文本集对应高精度分类器,所以将强文本集作为检测结果集的一部分。而弱文本集是低精度分类器检测的结果,存在一定的误检区域,需对弱文本集进一步处理。
为了满足高召回率的要求,对强文本集中的任一强文本Rs,在弱文本集中追踪Rs的邻近文本Rw。若Rs与Rw具有相似的文本属性,则将Rw的状态置为强文本,遍历查询强文本集所有元素的相似文本。当两文本满足以下条件时,两文本为相似文本:(1)两文本的空间距离不超过两文本中长和宽最大值的2倍;(2)两文本对应的HSV模型各通道的差值最大不超过20;(3)两文本的笔画宽度之比不超过1.5;(4)两文本对应的长或宽之比不应超过2。

图3 文档图像的文本定位过程
为验证算法的有效性,文中使用了200张文档测试图像数据集进行测试。实验平台为:VS2013,Core i5-3230M CPU,主频2.60 GHz,8 GB内存。
实验1关键点检测实验 。
关键点检测算法采用的评估指标为:重复检测率(|D|/|GT|)、文本漏检率(|FN|/|GT|)、运行时间(T);其中|D|为检测出的关键点的数目,|GT|为文本的真实数目,|FN|为漏检的文本数目。表1对比了3种关键点检测算法,如表1所示,与Fast相比,本文算法在重复检测率、文本漏检率上得到了改善;与FastText相比,本文算法改善了重复检测率,且能保持其它方面的性能。

表1 不同关键点检测算法结果对比
实验2文本定位实验。
文本定位算法采用的性能评估指标为:召回率(R%)、正确率(P%)、综合性能(F%)、算法运行时间(T)。表2对比了4种文本定位算法,如表2所示,本文算法召回率为 75.2%,正确率为86.5%,综合性能为 80.5%,运行时间为7.9 s,优于其它算法。
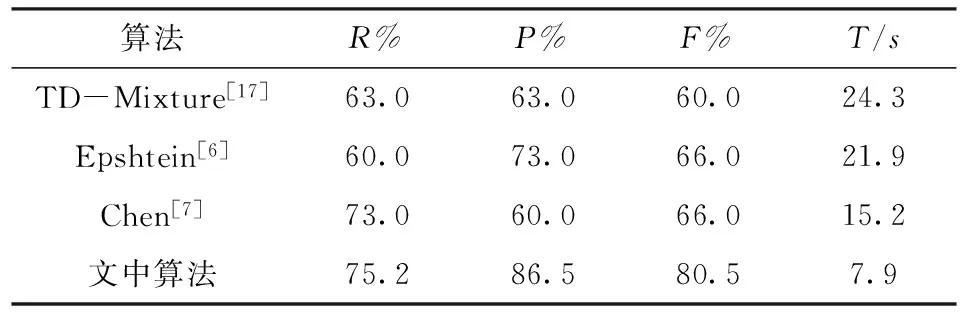
表2 不同文本定位算法结果对比
3 结束语
文中提出了一种基本关键点检测的文档文本定位算法。首先使用根据文档文本特性改进的关键点检测算法实现对文本初步定位,通过连通域检测获取候选文本,对候选文本集进行双阈值分类和相似文本追踪,提高定位的精度。实验表明,本文算法应用于复杂背景下的文档文本的定位时,获得了较高的精度和综合性能,快速、精确地实现对文档文本的定位。
[1] Wang K,Babenko B,Belongie S. End-to-end scene text in natural scenes[C].Barcelona:Proceeding of IEEE Conference on Computer Vision and Pattern Recognition,2011.
[2] Jaderberg M,Vedaldi A,Zisserman A. Deep features for text spotting[C]. Zurich: Computer Vision-ECCV 2014,2014.
[3] Lee J J,Lee P H,Lee S S,et al.Adaboost for text detection in natural scene[C].Beijing:ICDAR 2011,2011.
[4] Mishra A,Alahari K,Jawahar C.Top-downand bottom-up cues for scene text recognition[C].Providence:Proceeding of IEEE Conference on Computer Vision,2012.
[5] Yi C,Tian Y.Localizing text in scene images by boundary clustering,stroke segmentation,and string fragment classification[J].IEEE Transaction on Image Processing,2014, 72(10):4256-4268.
[6] Epshtein B,Ofek E,Wexler Y.Detecting t-ext in natural scenes with stroke width trans-form[C].San Francisco:Proceeding of Computer Vision and Pattern Recognition,2010.
[7] Chen H,Tsai S S,G.Schroth,at al,Robust text detection in natural images with edge-enhanced maximally stable extremal region[C].Brussels:International Conference on Image Processing,2011.
[8] Li Y,Jia W,Shen C,et al.Characterness:An Indicator of text in the wild[J].IEEE Transactions on Image Processing,2014,23(4): 1666-1677.
[9] Huang W,Qiao Y,Tang X. Robust scene text detection with convolution neural network induced MSER trees[C].Zurich:Proceeding of European Conference on Computer Vision,2014.
[10] Li Yao,Lu Huchuan.Scene text detection via strokes width[C].Rhode Island:Proceeding of 21nd IEEE Conference on Pattern Recognition,2012.
[11] Buta M,Neumann L,Matas J.FASText: efficient unconstrained scene text detector[C].Santiago:IEEE International Conference on Computer Vision,2015.
[12] 韩凌波. 基于密度的 K-means初始聚类中心选取算法[J].电子科技,2015,28(7): 32-34.
[13] 付忠良.关于AdaBoost有效性的分析[J].计算机研究与发展,2008,45(10):1747-1755.
[14] Rosten E,Porter R,Drummond T.Faster and better:A machine learning approach to corner detection[J].IEEE Transaction on Image Processing,2010,2(32):105-119.
[15] Treuenfels A.An efficient flood visit al-gorithm[J].C/C++ Users Journal,1994,12(8):39-62.
[16] Dalal N,Triggs B.Histograms of oriented gradients for human detection[C].Hong Kong:IEEE Computer Society on Computer Vision & Pattern Recognition,2005.
[17] Yao C,Bai X,Liu W,et al.Detecting texts of arbitrary orientations in natural images[C].Providence:Computer Vision an-d Pattern Recognition,2012.
Document Text Localization Algorithm Based on Keypoint Detection
WANYAN Yong,WANG Zongxian
(Beijing Key Lab of Urban Intelligent Traffic Control Technology,North China University of Technology,Beijing 100144,China)
Text localization is the hypothesis and foundation of text extraction. To solve the problem that document which is shooted by cell phone text localization is susceptible to the complex background and document quality,a document text localization algorithm based on keypoint detection is proposed, which adequately takes advantage of document text features .The algorithm firstly uses FASText keypoint detection method to achieve local text localization and to improve the localization accuracy,document text features is used to filter keypoints.Then through connected-component detection and non-maximum suppression ,obtain the text candidate regions.Finally, train two classifiers to classify the candidate regions,which is respectively high and low accuracy. These two classifiers divide the candidate text set into strong text sets, weak text sets and non-text sets.Utilize similar text characteristic to remove false text and improve localization accuracy.The experiments demonstrate that the algorithm can accurately and fastly locate the text region in document image.
text localization;keypoint;double threshold classification;non-maximum suppression;classifier
2017- 02- 07
科技创新服务能力建设-科技成果转化-提升计划项目-基于交通大数据的北京道路交通疏堵决策支持系统研发(PXM2016_014212_000036)
完颜勇(1988-),男,硕士研究生。研究方向:数字图像处理。王宗贤(1991-),男,硕士研究生。研究方向:数字图像处理。
10.16180/j.cnki.issn1007-7820.2017.12.017
TP391
A
1007-7820(2017)12-062-05
