ABC聚类算法与KHM算法相结合的ABCKHM聚类算法
2017-12-19都兴朔
姜 华,胡 欣,王 峥,都兴朔
(1.东北师范大学信息科学与技术学院,吉林 长春 130117; 2.东北师范大学智能信息处理吉林省高校重点实验室,吉林 长春 130117)
ABC聚类算法与KHM算法相结合的ABCKHM聚类算法
姜 华1,2,胡 欣1,2,王 峥1,2,都兴朔1,2
(1.东北师范大学信息科学与技术学院,吉林 长春 130117; 2.东北师范大学智能信息处理吉林省高校重点实验室,吉林 长春 130117)
针对调和K均值聚类(KHM)算法存在陷入局部最优解的问题,提出一种人工蜂群(ABC)算法与KHM算法相结合的混合聚类算法ABCKHM.实验表明,该算法解决了KHM算法有时陷入局部最优解的问题,并且该算法较之KHM算法及同类其他算法有更好的性能.
聚类;KHM;人工蜂群优化;ABC
聚类分析是一大类数据挖掘方法的总称,是数据挖掘的一个重要领域.聚类过程就是把事物聚集到几类中,使得不同类中的对象尽可能的不同,同一类中的对象尽可能相似[1].调和K均值聚类(KHM)算法1999年被提出[2].KHM算法相比于K-means算法减少了对初始中心点的依赖[3-4].2005年Karaboga提出的人工蜂群(ABC)算法的优化算法,最初是为解决多变量函数优化问题,模拟了蜜蜂群体的采蜜行为.[5]ABC算法具有全局寻优、收敛速度快等很多优点,该算法经过合理设置优化目标函数可以应用于聚类问题.本文提出一种混合聚类算法ABCKHM,结合了ABC聚类算法与KHM算法的思想,借助ABC聚类算法全局寻优能力,解决KHM可能陷入局部最优的问题.
1 KHM算法
KHM算法比K-means算法虽减轻了对中心点初始选择的依赖,但是KHM算法仍有可能陷入局部最优解.KHM算法相关概念和记法如下[6]:
xi(i=1,2,…,n):数据对象.
cj(j=1,2,…,k):第j簇的中心点.
KHM(X,C):KHM算法的目标函数.
m(cj/xi):隶属函数,表示数据对象xi属于第j个簇的程度.
w(xi):权值函数.
KHM算法的主要步骤如下:
Step1:初始化算法参数,随机选择初始中心点.
Step2:计算目标函数KHM(X,C),公式为
(1)
其中p是输入参数,通常取p≥2.
Step 3:计算隶属度m(cj/xi),公式为
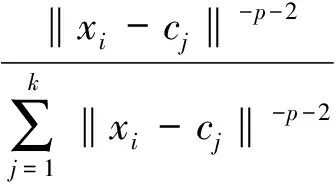
(2)
其中m(cj/xi)∈[0,1].
Step 4:计算数据对象xi的权值w(xi),公式为

(3)
Step 5:根据xi的隶属度m(cj/xi)和权值w(xi)重新计算类的中心点
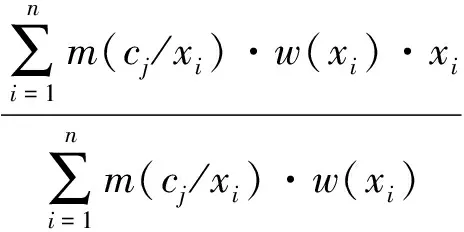
(4)
Step 6:重复Step 2—5,直至目标函数KHM(X,C)的值不再改变或达到最大循环次数MaxGen.
Step 7:分配数据对象xi到隶属度m(cj/xi)最大的第j个簇中.
2 ABC优化算法
ABC优化算法模拟自然界中的蜜蜂采蜜行为,用食物源的位置表示优化问题的解[7].蜂群有引领蜂、跟随蜂和侦察蜂3种:引领蜂收集食物源的蜜量等信息;跟随蜂在蜂巢等待并察看引领蜂的动作信号(舞蹈),从中获取信息决定是否跟随;侦察蜂则随机地寻找食物源.设有SN个食物源,ABC算法规定引领蜂数量=跟随蜂数量=食物源数量.优化解集合包含SN个D维向量,第i个解为xi=(xi1,xi2,…,xiD),i=1,…,SN,食物源的花蜜量对应适应度值,也即解的质量.
ABC算法在初始化过程中随机产生SN个初始解,进而计算它们的适应度值.然后,循环使用引领蜂、跟随蜂和侦察蜂更新食物源位置,最终完成最优解的搜索过程.引领蜂判断附近食物源的花蜜量(适应度值),如果新食物源高于现有的花蜜量,则引领蜂记住新食物源,放弃现有的食物源,否则,仍保持不变,即进行一个贪心选择过程.引领蜂搜索过后,通过跳舞动作传递食物源信息给跟随蜂,跟随蜂进行评估,计算每个食物源与花蜜量相关的概率值,并优先选取值较大的食物源,依据贪心选择过程进一步尝试更新.每个食物源的概率值计算公式为
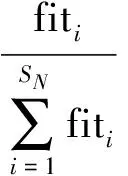
(5)
其中fiti表示食物源的适应度值.
ABC算法修正现有食物源xi的位置,计算公式为
vij=xij+Rij(xij-xkj).
(6)
其中:k随机选取,k∈{1,2,…,SN}且k≠i,j∈{1,2,…,D};Rij是[-1,1]间的随机数,控制着在食物源xi附近什么位置产生新食物,本质是邻域搜索.
ABC算法中,如果在limit次循环后一个食物源还没有被更新,那么放弃这一食物源,侦察蜂随机寻找新食物源取代之.这个过程计算公式为

(7)
ABC算法有食物源总数SN、limit值、最大循环数MaxCycle 3个控制参数.ABC优化算法如下:
(1) 初始化MaxCycle及limit,置cycle=1.
(2) 随机生成各个最初的食物源xi,并计算适应度值fiti(i=1,…,SN).
(3) 循环,反复执行下列步骤,直到cycle达到预定迭代次数MaxCycle:
(a) 派出SN个引领蜂,根据公式(6)更新第i(i=1,…,SN)个食物源,并计算其适应度值newfiti,与原有食物源的适应度值fiti比较,若newfiti>fiti则记下这个食物源,反之丢弃;
(b) 使用公式(5)计算各个食物源的概率Pi;
(c) 派出SN个跟随蜂,根据Pi判断是否需要再次更新食物源,更新方式同步骤(a);
(d) 记下更新后得到的更好食物源;
(e) 派出侦察蜂,重新初始化经过limit次尝试一直没有得到更新的食物源;
(f) cycle=cycle+1.
(4) 输出求得的最优函数值及对应的食物源,算法结束.
3 ABC聚类算法
我们对ABC优化算法进行改进,得到一种新的ABC聚类算法[8].
ABC优化算法的目标在于寻找k个(取决于具体问题)食物源,以使给定的目标函数值达到最小.当把ABC优化算法应用于聚类问题时,每一个食物源对应一个中心点.如果度量使用欧氏距离,ABC聚类过程就将数据对象分配到与之有最短欧式距离的食物源所在的簇中,并最小化上述聚类目标函数f.
ABC优化算法中每一个食物源的适应度fiti定义为
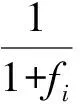
(8)
其中fi是目标函数的当前值,fi越小,fiti越大.把ABC优化算法用于聚类问题时,则目标函数f值越小,食物源的适应度值越大,聚类效果越好.
4 ANCKHM聚类算法
以ABC聚类算法对数据集进行初始聚类,将得到的k个中心点作为KHM算法的初始聚类中心,再运行KHM算法获得最终聚类结果.由于ABC聚类算法的全局寻优特点,新算法能有效地减少KHM算法陷入局部最优的问题.新的ABCKHM聚类算法如下:
(ABC聚类算法优化中心点阶段)
(1) 初始化MaxCycle及limit,置cycle=1.
(2) 随机生成初始食物源xi,并计算其适应度值fiti(i=1,…,SN).
(3) 循环,反复执行下列步骤,直到cycle达到预定迭代次数MaxCycle:
(a) 派出SN个引领蜂,根据公式(6)更新第i(i=1,…,SN)个食物源,并计算其适应度值newfiti,与原有食物源的适应度值fiti比较,若newfiti>fiti则记下这个食物源,反之丢弃;
(b) 使用公式(5)计算各个食物源的概率Pi;
(c) 派出SN个跟随蜂,根据Pi决定是否需要再次更新食物源,更新方式同步骤(a);
(d) 记下SN个更好的食物源,把数据点划分到离它最近的食物源所在的簇中;
(e) 派出侦察蜂,重新初始化经过limit次尝试仍未更新的食物源;
(f) cycle=cycle+1.
(4) 输出SN个簇最好的食物源.
(KHM聚类算法阶段)
(5) 将ABC聚类算法的食物源作为KHM算法初始中心点.
(6) 根据公式(1)—(3)计算目标函数KHM(x,c)、隶属度m(cj/xi)、权值w(xi).
(7) 根据公式(4)重新计算类的中心点cj,cycleKHM=cycleKHM+1.
(8) 循环执行步骤(6)和(7),直至目标函数KHM(X,C)的值不再改变或达到最大循环次数MaxGen.
(9) 分配数据对象xi到隶属度m(cj/xi)最大的簇中.
5 实验部分
本文实验在Pentium (R) CPU 2.5 GHZ+512 MB RAM平台上进行,采用C++编码.为了测试ABCKHM混合聚类算法的性能,使用3个标准数据集Iris、Glass和Wine.ABCKHM聚类算法使用的初始参数见表1.
5.1 数据集
实验使用的3个数据集Iris、Glass和Wine的信息见表2.

表1 ABCKHM算法设置的参数初值
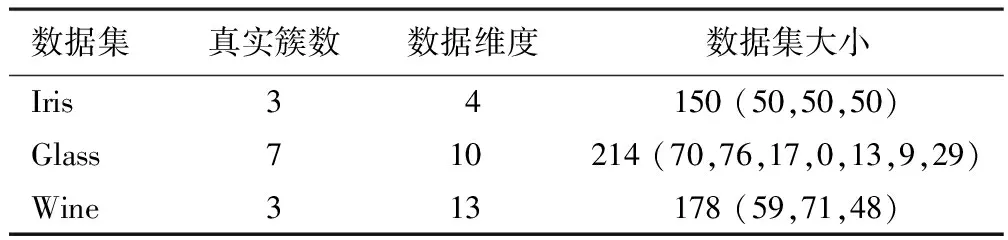
表2 数据集特征
数据集详细描述:
Iris(n=150,d=4,k=3)是机器学习领域一个经典的数据集.这个数据集包括Iris Setosa、Iris Versicolour和Iris Virginica三类数据对象.每类都有50个4维的数据对象,4维属性分别是sepal length、sepal width、petal length和petal width.
Glass(n=214,d=10,k=7)是另一个常用的机器学习数据集,包含214个数据对象、维数10个、7类数据对象.
Wine(n=178,d=13,k=3)是一个著名的用于机器学习的数据集,描述3种不同的意大利酒,包括178个数据对象、维数13、3大类数据对象.
5.2 性能评估方法
本文用F-Measure函数来评估算法聚类效果[9].F-Measure度量包括精确率(p(i,j))和召回率(r(i,j))两个组成部分,分别定义为
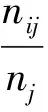
其中:ni是聚类算法求得的第i类中的数据点数;nj是数据集第j类中真实的数据点数;nij是前述2个集合交集的数据点数;p(i,j)代表算法的准确性;r(i,j)代表算法的查全率.F-Measure定义为
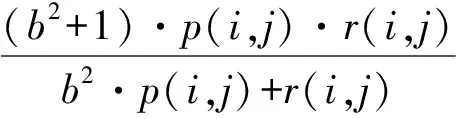
其中取b=1,使得p(i,j)和r(i,j)的权值相等.如果数据集的大小为n,整体的F-Measure定义为

F-Measure的值越大,算法的聚类效果越好.
5.3 实验结果及分析

图1 ABCKHM聚类算法在3个数据集上10次运行的准确率
本文进行了2组实验:(1)研究了ABCKHM聚类算法的稳定性;(2)ABCKHM聚类算法与同类其他算法(KHM算法、FKH算法、KHM-SAPSO算法、KHM-CPSO算法)进行了对比.
首先,为验证ABCKHM聚类算法的稳定性,分别在3个数据集(Glass、Iris、Wine)上运行10次,聚类的准确率如图1所示,结果非常稳定.ABCKHM聚类算法的准确率表明其有效避免了KHM算法有时会陷入局部最优解的问题.
为进一步验证ABCKHM聚类算法的效果,把ABCKHM聚类算法与已有的KHM算法、FKH算法、KHM-SAPSO算法、KHM-CPSO算法进行对比,分别在3个数据集上运行10次,再分别取准确率(Accuracy)的平均值及F-Measure的平均值.当p=3.5时的实验结果见表3.
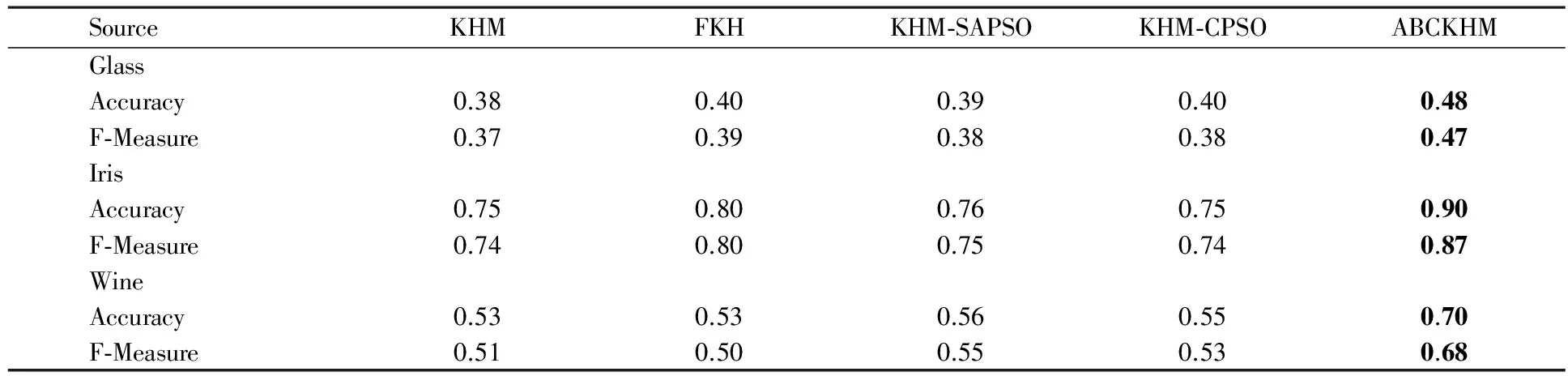
表3 KHM、FKH、KHM-SAPSO、KHM-CPSO 和ABCKHM聚类算法的结果(p=3.5)
结果显示:ABCKHM聚类算法的准确率及F-Measure值均优于同类其他算法.
6 结束语
本文把ABC算法改写为聚类算法,将其求得的聚类中心作为KHM算法的初始中心点并运行KHM算法求得最后聚类结果.本质是借助ABC聚类算法的全局寻优特性来克服KHM的固有缺点.实验结果表明,本文提出的ABCKHM聚类算法的性能优于传统KHM算法及其他同类算法.但是对于Iris和Wine这样维数较高的数据集而言,聚类效果还有很大提升空间,将是后续研究的重点.
[1] XU RUI,DONALD WUNSCH,Survey of clustering algorithms[J].IEEE Transactions on Neural Networks,2005,16(3):645-678.
[2] JIANG HUA,YI SHENGHE,LI JING,et al.Ant clustering algorithm with K-harmonic means clustering [J].Expert Systems with Applications,2010,37(12):8679-8684.
[3] GRIGORIOS TZORTZIS,ARISTIDIS LIKAS.The minmax K-means clustering algorithm[J].Pattern Recognition,2014,47(7):2505-2516.
[4] KRISBNA K,NARASIMHA MURTY M.Genetic K-means algorithm [J].IEEE Transactions on Systems,Man,Cybernetics,Part B,1999,29(3):433-439.
[5] YURTKURAN ALKIN,EMEL ERDAL.An adaptive artificial bee colony algorithm for global optimization [J].Applied Mathematics and Computation,2015,271(15):1004-1023.
[6] GÜNGÖR Z,ÜNLER A.K-harmonic means data clustering with tabu-search method [J].Applied Mathematical Modelling,2008,32(6):1115-1125.
[7] SONG X Y,YAN Q F,ZHAO M.An adaptive artificial bee colony algorithm based on objective function value information [J].Applied Soft Computing,2017,55(7):384-401.
[8] KARABOGA D,OZTURK C.A novel clustering approach: artificial bee colony (ABC) algorithm [J].Applied Soft Computing,2011,11(1):652-657.
[9] MARATEA A,PETROSINO A,MANZO M.Adjusted F-measure and kernel scaling for imbalanced data learning [J].Information Sciences,2014,257(1):331-341.
AhybridclusteringalgorithmABCKHMcombiningABCandKHM
JIANG Hua1,2,HU Xin1,2,WANG Zheng1,2,DU Xing-shuo1,2
(1.School of Information Science and Technology,Northeast Normal University,Changchun 130117,China;2.Key Laboratory of Intelligent Information Processing of Jilin Province,Northeast Normal University,Changchun 130117,China)
It is still possible that K-harmonic means clustering algorithm reach local minimal value.Artificial bee colony optimization algorithm has good performance in global optimization,so the clustering algorithm derived from artificial bee colony optimization algorithm ought to overcome the problem of trapping in local optimization.This article proposes a hybrid clustering algorithm (ABCKHM) combining artificial bee colony algorithm and K-harmonic means algorithm.Our algorithm has better global searching capability,faster speed,and stability.
clustering; K-harmonic means clustering; artificial bee colony optimization; artificial bee colony clustering
1000-1832(2017)04-0066-05
10.16163/j.cnki.22-1123/n.2017.04.013
2017-09-29
国家自然科学基金资助项目(71473035).
姜华(1964—),男,硕士,副教授,主要从事数据挖掘研究.
TP 31学科代码520·10
A
(责任编辑:石绍庆)
