众包之基于位置的查询∗
2017-12-18穆超
穆 超
(河海大学计算机与信息学院 南京 211100)
众包之基于位置的查询∗
穆 超
(河海大学计算机与信息学院 南京 211100)
在这个智能手机迅猛发展的网络时代里,大家的生活都已离不开移动网络,便捷的查询以及网络支付是它成功的关键。人们更喜欢找到附近的好吃的、好玩的、住所,这使得旅行更加方便。这就有了基于位置的查询。然而传统的搜索引擎在主观问题的搜索方面并不是很好,这就促使我们探寻众包微博上基于位置上的查询的有效性,更具体地说,就是研究基于位置服务的有效性,去寻找一个合适的人回答基于位置的查询。通过几个基于查询的例子,论文主要研究提出方法的可行性,并突出社交软件搜索引擎的重要性。
智能手机;便捷查询;位置查询;搜索引擎
1 引言
随着智能手机的发展,几乎每部智能手机都自带定位,这所带来的机遇,使得移动众包应用在现实世界中日益普及。很多人可以利用闲暇时间完成一些简单任务,比如用手机做一份翻译,抄写或者填写调查问卷来获得相应的好处[1],还可以充实自己的生活。从前的搜索只能搜索到基于事实的问题,而现在随着基于位置查询的迅猛发展,人们可以查到更多主观的问题,比如附近有没有适合情侣吃饭的餐厅,这些都会有人去回答你,我们现在做的就是要将回答的时间缩短,以尽可能满足你游玩的需要,这就需要我们创建一个平台,使大家可以迅速问答。我们创建一个将位置作为参数的平台,将任务分配给工人,通过研究发现移动用户的几条规律:1)移动的工人更喜欢主动从平台上接任务而不是等着平台去推送任务给他。2)人们更喜欢拍照片等简单的任务。3)用户主要选择靠近自己家的位置的任务
过去几年出现了很多项目,他们的成功都是基于一个庞大人群的贡献。百度百科就是一个典型的例子,它利用了互联网上庞大人群的广泛知识。高德地图是另一个成功的例子,它也是根据生活在不同地理区域的人们贡献、分享和处理他们的位置轨迹做的一个全面的在线地图。这仅仅是其中的两个成功例子,在这两个例子中都是有着很多的人,每个人都作出自己的一份小小贡献,成就了一个全新的,适应于互联网的应用类型。
2 基于位置查询
2.1 基于位置查询的应用情景
1)情景一:李刚在回家的路上看到一款照相机的广告,这个店离他家很远,由于一天工作很累不想亲自过去,与其相信买家秀的照片,更加相信其他顾客亲自去店里看到的,他们的评价是更有意义的,更具参考价值,因此他从平台上上传一个这样的任务,即到店里拍一张他喜欢相机的照片。
2)情景二:王宇要去一个大学演讲,结果扭伤了膝盖,而很多学生都会出席这个演讲,他为此将这次演讲内容录音了,发到众包平台想要其他人去替她完成这次演讲,将这次演讲的时间,位置和它想要讲的发到了平台上,过了几分钟,收到李明的积极回馈,李明在完成的任务中具有很高的评价。后来王宇收到视频和音频文件以及李明的笔记副本。
3)情景三:王莎居住在徐州,她最近非常高兴,因为在南京找到了一份工作,她将要去南京居住,有热心的房屋中介为她提供了一些优惠的房屋选择,但这些房间在网上找不到任何房子周边的照片,于是王莎在平台上询问房子周边更多的信息,包括图片。一个附近的人将房屋周边的街道,商店和咖啡店拍了下来[4]。
2.2 基于位置查询的国内外研究
2.2.1 基于位置查询的发展
由于智能手机技术的迅速发展,基于位置的查询变得越来越流行。最近的研究中为可扩展的基于位置的网络服务引入了一个新的数据库管理系统。这个目的就是为基于位置查询提供一个快速和可扩展的数据库管理系统。
搜索从事于基于位置查询的数据库研究者和公司,包括空间索引的问题、最邻近搜索还有基于位置查询的几何方法,这些工作本身就是算法。并假设这些查询制定了明确的目标名称,所以这个重点就是用最小的花费发送这些查询的答案。
2.2.2 众包与协作
以前我们的研究都是集中在协同应用,例如描述一下当前的天气状况,这是一个只要在那种环境的人都能回答的问题。相比来说,我们现在主要研究的是回答基于位置的查询,通过问题的主题分类以及人们签到的位置信息来找到最合适的人去回答问题。
最近的研究是关于众包图片搜索,计算机很难去很好地识别一张图片尤其是在无限制的环境下。本文将改进这一点,将人类的智能和机器结合起来,用土耳其机器人中的人用过电脑处理查询的图片后得到的信息去验证答案。
在下面我们统计一下我们基于位置的查询中的位置类型,在当前的研究中,我们还只是在以下几个位置类型中进行研究,我们计划在研究成熟后,扩展到整个社会中去,为人们的便捷生活做出贡献。
3 系统结构

表1 位置类型
基于位置查询的问答系统主要组件是:问题收集器、验证器、问题请求者、答案收集器、中转站。系统的整体结构如图1。
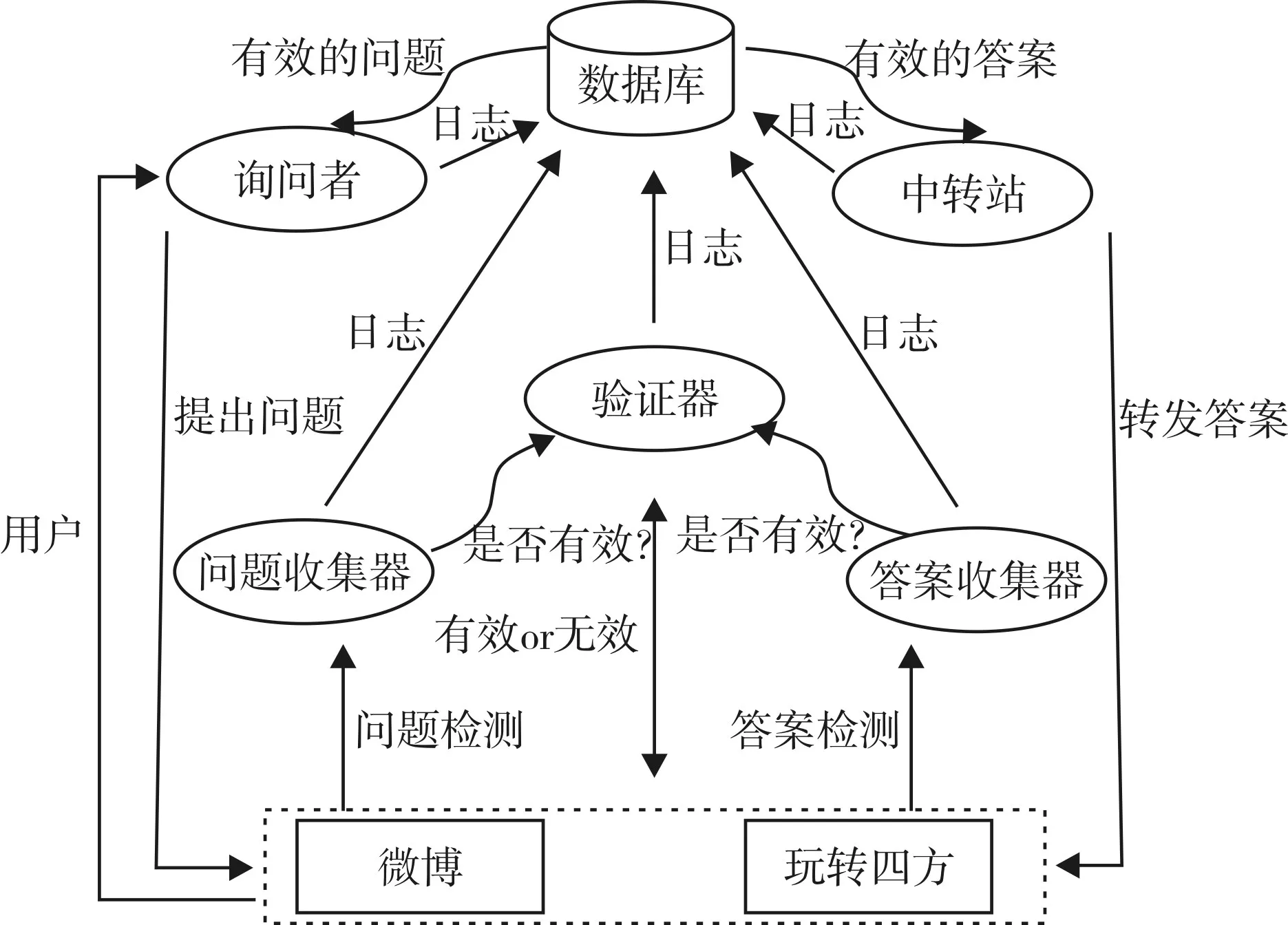
图1 系统结构图
3.1 问题收集器
我们利用微博自带的搜索功能去收集问题,我们要找出问问题的博文,首先要找到一个问题标记,毫无疑问,带有问号“?”标记的博文很有可能成为我们的目标。因为我们主要研究基于位置的查询,所以我们主要收集表1中类型的博文。我们想到找几类关键词可以筛选到好的问题,例如某人、某些建议、哪里等等关键词。接下来,我们根据下面的模板来收集博文(关键词顺序不重要),问题关键词-正文-位置信息-?。下面是我们用上面模板收集到的例子:某人-吃晚餐去哪里好-南京水游城-?。
最后,我们通过被拉入黑名单的词语过滤掉不合适和含有讥讽意味的博文,并且过滤掉那些含有连接http://和标记@的博文,因为我们发现一般人在提出问题时不会插入链接,@在微博中代表着与朋友的聊天[9]。

表2 问题等级
3.2 验证器
尽管问题收集器可以过滤掉一些明显的博文,但中国文字博大精深,完全过滤掉不合适的博文是不可能的,所以我们还要借助于验证器来去掉那些文字游戏以及含有讥讽的博文,因此我们在问题得到答案之前,让问题核对者去验证问题。
没有通过验证的问题放在一个队列里,并将这些问题转发给其他在线可利用的核对者。验证一个问题是一个简单的任务。例如,一个人询问在南京哪里可以找到便宜,好一点的宾馆。作为一个有效的问题,问题中并没有关于南京和宾馆的详细信息。开始我们只是使用我们实验室和大学的问题核对者,但随着发展,渐渐供不应求,无法满足大众的要求,我们需要扩充核对者的范围,从更广泛的人群中找到我们需要的人才。我们还引入绩效系统,来激励人们的积极性,完成相应的核对就会获得对应的绩效点,那么他可以用绩效点在平台上发布查询,并且这样的问题优先级更高。
问题核对者的工作就是标注问题的种类以及质量如何。对于分类的问题,表1是核对者标记问题的位置类型,表2的问题的等级的标注,如果一个问题被标记等级1,它就是不合适的问题,不能够被回答,其他两个等级都是可以被回答的,等级三比等级二的问表达更清晰明了。
对于一个问题的验证,我们的系统会发送三个连续的消息给问题核对者,第一个是表二中,博文的种类,第二个是表2中,问题的等级,第三个就是问题核对者需要去验证的问题了。下面举个验证问题的例子
@用户名 A:艺术娱乐,C:大学教育,F:食物N:夜生活P:户外停车场,S:购物,T:旅行
@用户名 1:不恰当2:能被回答3:好问题
@用户名(问题)
在发送上面的博文后,我们的系统就等待着问题核对者的回应。为了简便起见,我们设定一个严格的回答格式。问题核对者回答时,首先要用问题种类的首字母并且标注问题的等级,比如“N2”代表着问题的种类是夜生活,等级是2,能够被回答的问题。如果问题核对者不能在给定时间内完成验证,我们会发送问题给其他可用的核对者。如果核对者没有完成前一个问题的核对,我们是不会给他发下一个任务的。这样的话,如果有的核对者不想做了,这种机制为他们提供了一种简单的方式。
在完成上述验证步骤后,这个问题就可以用来“问”了。
3.3 询问者
这个询问者发出的验证过的问题,想要找到最合适的人去回答这个问题。这里我们使用两种方法找出最合适的人。第一种方法是我们筛选他们的简历,挑选出居住在问题包含的城市的人群。第二种方法是,我们挑选出微博账号和玩转四方账号绑定在一起的用户,因为玩转四方是一款基于位置查询的软件,并且它的用户每天都频繁的发表签到地点[11]。
接下来询问者会通过微博来向人们问问题,假设一个人没有回答我们的问题,那么系统就不会进一步对这个人进行提问,这给人们提供了一个简单地退出方式对我们的研究。
@用户名请帮助我们的研究项目,通过回答以下问题,问题链接(网址链接)
@用户名(问题)
由于微博也是有频率限制的,每天过快的频率会出现系统繁忙,稍后再试的调试,所以我们要在这种限制下找到适当的方法。从我们的试验来看,超过百分之五十的人都是在问题提出二十分钟之内回答,所以我们主要集中在问题提出后收集答案。
3.4 答案收集器
答案收集器通过民意投票对一些收到答案的问题进行筛选,它和问题收集器相似,也是将答案中含有黑名单的词语相比对,含有的话就去掉这个答案。最后这个组件使用数据库的日志数据来找到问题的最佳答案,并存储验证步骤的答案。尽管验证答案的时候,我们会过滤掉一些不合适的答案,但还是会有一些不符合要求的答案,我们进一步对答案的处理,和对问题的处理相似,我们将答案发送给核对者去验证,如果通过验证,我们将答案整理发送给任务的发布者。

表3 答案等级
3.5 中转站
在这个步骤,我们将符合要求的答案和好的答案转发给相应的询问者。
@询问者我们的众包系统找到了你对应问题的答案,答案来源于用户@回答者;
@询问者(问题);
@询问者(答案)。
4 实验
在这部分,我们描述我们的实验结果,我们使用C语言作为程序语言,利用玩转四方中的数据,将我们的日志数据分成八个表,分别由问题,答案,用户和核对者组成。我们的数据集包括365个有效的问题。我们将问题分成两大类:事实问题和主观问题,在我们的数据集中,主观问题占70%,事实问题占30%,下表展示了每种类型的问题样式。
我们最希望的结果就是,比起百度的回答率50%多我们的系统回答问题率要超过它,到达70~80%。然而百度回答80%为事实问题,仅有20%主观问题。这表明我们的系统主要针对主观问题,同样不失事实问题回答。

表4 事实问题与主观问题
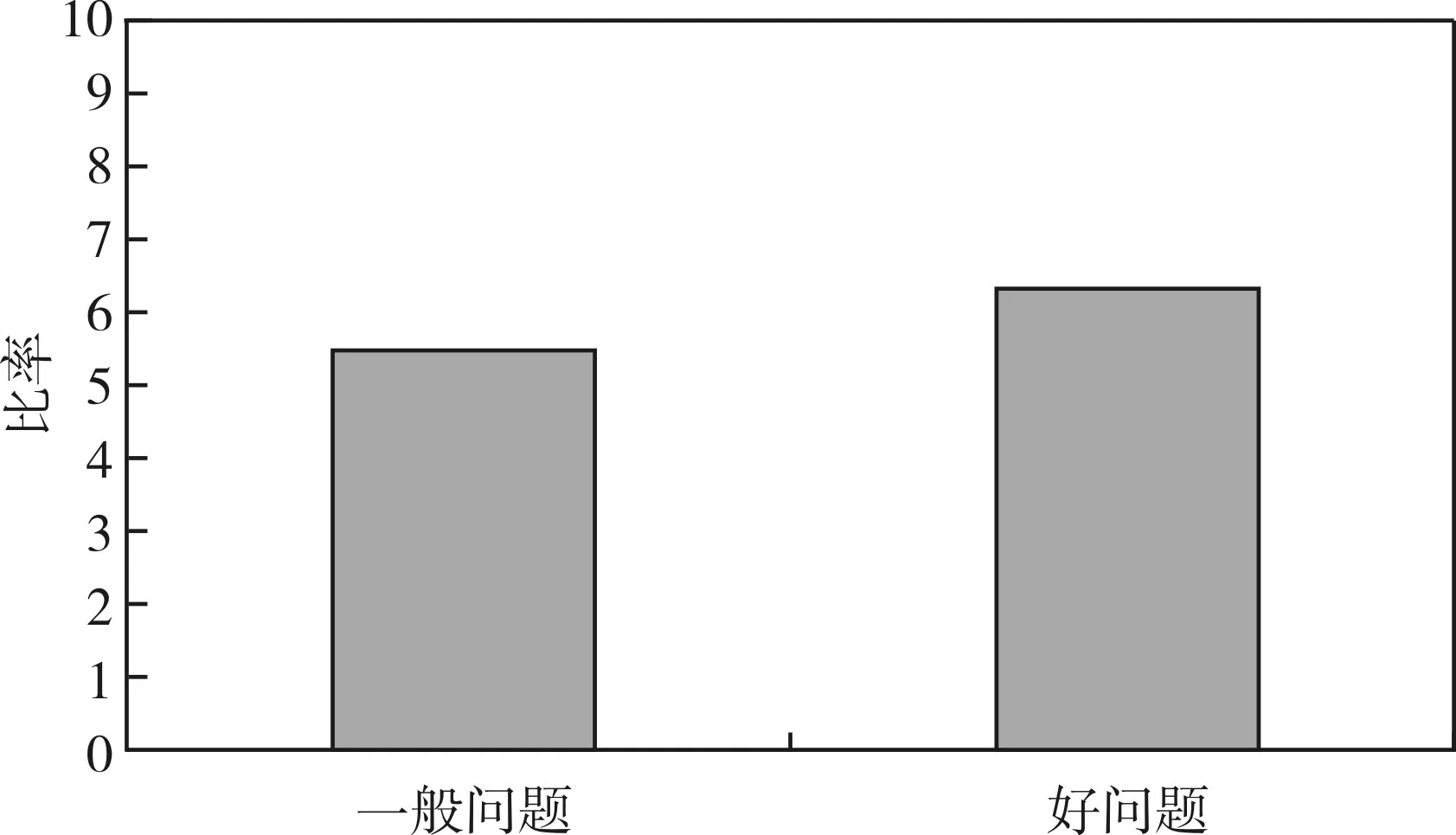
图2 基于问题等级的回答率
基于问题等级的回答率:上图为基于问题等级的回答率,研究发现:人们相对于一般问题更喜欢去回答好的问题。由于好的问题,描述清楚,定义明确,可以更好地理解询问者的用意,更利于人们完成任务。尽管人们在一般问题和好问题的回答率上差距不是很大,但我们依然可以将问题设计的更好,来提高问题的回答率。
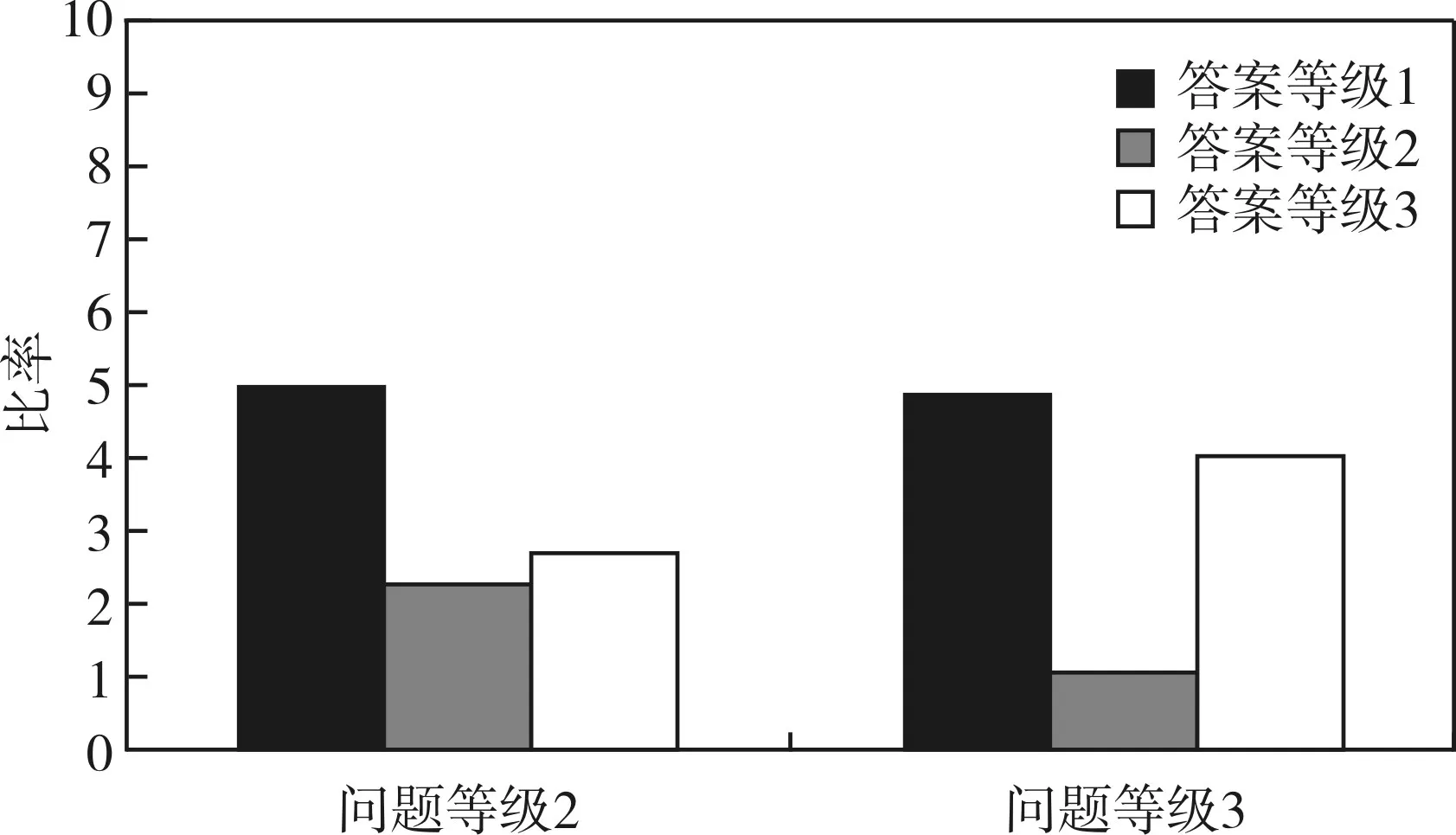
图3 问题等级与答案等级之间的映射关系
问题等级与答案等级之间的映射关系:随着问题等级的变化,得到的答案的等级也随之变化。如图所示,等级越高的问题(好问题)相应得到的答案的等级也就越高。好问题得到的答案,40%都是好答案,还有10%是可以被转发的答案,转发的答案可以交给核对者,经过核对后也可以发给询问者。另一方面,等级二的问题得到的好答案为27%,可以被转发的答案接近为23%。
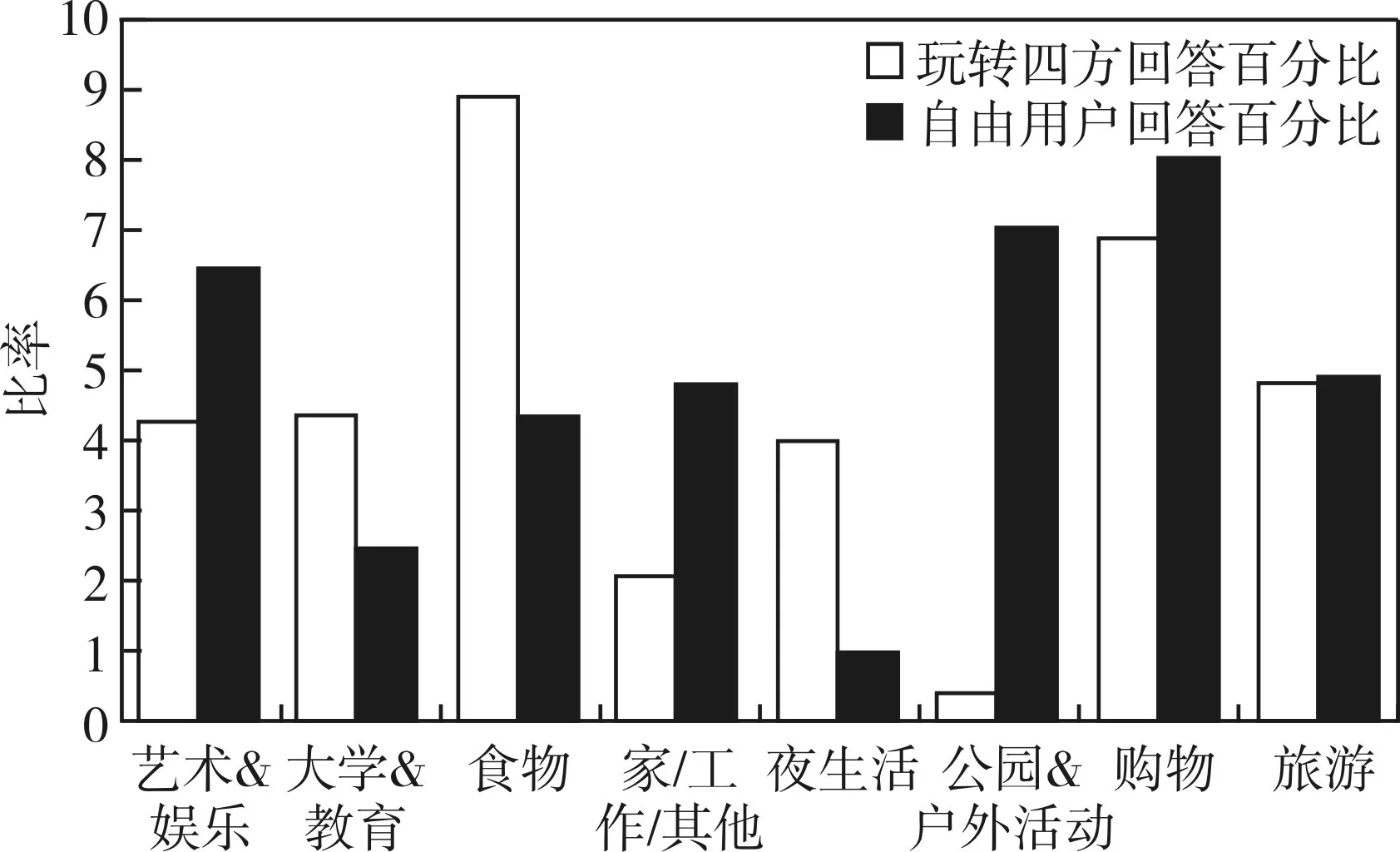
图4 玩转四方用户的回答率与自由用户的回答率
玩转四方用户的回答率与自由用户的回答率:通过比较玩转四方用户和自由用户对各种问题类型的回答率比较,我们发现,玩转四方的用户更多的是去回答大学教育、食物、夜生活等问题。而自由用户更多的是去回答艺术娱乐、家庭工作、公园和户外运动等问题。并且,在购物、旅游等非常广泛的领域,想要为一个专门的问题找到一个精通的回答者,是很难的。
5 结语
在本文中,我们对老的搜索引擎进行了剖析,发现了它的不足。从而针对它的缺点进行了改进,提出了新的系统,完善了基于位置查询的功能。从进行的实验中,知道该系统能够回答至少70%的问题。此外,对于娱乐、美食、夜生活等方面的问题,玩转四方的用户比自由用户回答的更符合询问者的要求。最后,社交软件方面为我们提供了散播问题的平台,这有利于我们快速找到问题的答案。
[1]Howe,Jeff.The Rise of Crowdsourcing[J].06 Jenkins H Convergence Culture Where Old&New Media Collide,2006,14(14):1-5.
[2]Howe J.Crowdsourcing:Why the Power of the Crowd Is Driving the Future of Business[J].American Journal of Health-System Pharmacy,2009,67(18):1565-1566.
[3]Kittur A,Chi E H,Suh B.Crowdsourcing user studies with Mechanical Turk[C]//CHI 08:Sigchi Conference on Human Factors in Computing Systems.ACM,2008:453-456.
[4]Kamar E,Horvitz E.Collaboration and Shared Plans in the Open World:Studies of Ridesharing[C]//IJCAI 2009,Proceedings of the,International Joint Conference on Artificial Intelligence,Pasadena,California,Usa,July.2009:187-194.
[5] Chen J,Subramanian L,Brewer E.Sms-based web search for low-end mobile devices[C]//International Conference on Mobile Computing and Networking,MOBICOM 2010,Chicago,Illinois,Usa,September.2010:125-136.
[6]Chow C Y,Bao J,Mokbel M F.Towards location-based social networking services[C]//International Workshop on Location Based Social Networks,Lbsn 2010,November 2,2010,San Jose,Ca,Usa,Proceedings.2010:31-38.
[7]Davidov D,Tsur O,Rappoport A.Semi-supervised recognition of sarcastic sentences in twitter and amazon[J].Conll,2010:107-116.
[8] DemirbasM, BayirM A, AkcoraC G, etal.Crowd-sourced sensing and collaboration using twitter[C]//World of Wireless Mobile and Multimedia Networks.IEEE,2010:1-9.
[9]Lange T,Kowalkiewicz M,Springer T,et al.Overcoming challenges in delivering services to social networks in location centric scenarios.[C]//International Workshop on Location Based Social Networks,Lbsn 2009,November 3,2009,Seattle,Washington,Usa,Proceedings.2009:92-95.
[10]Roussopoulos N,Kelley S,Vincent F.Nearest Neighbor Queries[J].Acm Sigmod Record,1995,24(2):71-79.
[11]Ledlie J,Odero B,Minkov E,et al.Crowd translator:on building localized speech recognizers through micropayments[J].Acm Sigops Operating Systems Review,2010,43(4):84-89.
[12]Von Ahn L,Liu R,Blum M.Peekaboom:a game for locating objects in images[C]//Sigchi Conference on Human Factors in Computing Systems.ACM,2006:55-64.
Location Based Query of Crowdsourcing
MU Chao
(School of Computer and Information,HoHai University,Nanjing 211100)
In the rapid development of intelligent mobile phone network era,everyone can not live without the mobile network,convenient query and online payment is the key to its success.More and more people love to find nearby delicious,fun,hotel,which makes travel more convenient.This create the location-based queries.The traditional search engine in the subjective aspect of the problem is not very good,this has prompted us to explore the effectiveness of Crowdsourcing the location-based queries of microblog.More specifically,Tant is to study the effectiveness of location-based service,which can find a suitable answer the location-based queries.Through several query examples based on this paper,The main research method is feasible,and highlight the importance of social software search engine.
smart phone,convenient query,location query,search engines
TP311
10.3969/j.issn.1672-9722.2017.11.031
Class Number TP311
2017年5月15日,
2017年6月18日
穆超,男,硕士研究生,研究方向:众包。
