伽达默尔的“成见”观、捷思法与人工智能
2017-11-30徐英瑾
■徐英瑾
人工智能专题【三篇】
【编者按】国务院不久前印发的《新一代人工智能发展规划》,从战略态势、总体要求、重点任务、资源配置、保障措施和组织实施共六个方面,为我国人工智能的发展指出明确的方向并做出科学的规划,在社会各界引起巨大反响和热烈讨论。为此,我刊组织三篇以人工智能为主题的文章,从不同角度阐发人工智能的发展已经或可能出现的问题。徐英瑾指出当代人工智能主流算法存在的缺陷,应该从伽达默尔对“成见”的理解中汲取思想资源,并主动吸纳心理学关于捷思法的研究成果,这对具体的科学问题提供的哲学参考;蔡恒进长期从事软件教学与研究,不仅指出人工智能发展的关键是找到“认知坎陷”,还对其必需的人文环境和教育模式给出了实质性建议;高奇琦、张结斌则从政治学视角对人工智能可能带来的失业问题提出前瞻性意见。三篇文章从微观到宏观,既有对现有科学问题的考察,又有对未来社会问题的关切,充分体现了人工智能的发展是一项复杂的系统工程,需要我们高度重视,并充分思考其对方方面面的深度影响。
伽达默尔的“成见”观、捷思法与人工智能
■徐英瑾
伽达默尔;成见;捷思法;人工智能
按照通常人的理解,人类设计人工智能系统的初衷之一,就是利用这些系统运作的 “客观性”,来消除人类决策过程中难以避免的种种偏见或者成见。譬如,根据大多数人的期望,人工智能系统应当能够帮助人类法官在审理案件的过程中更好地检查证据链的融贯性,或者量刑的合适性,以免人类的主观偏见使得判案出现偏差,等等。但是,从哲学角度看,这样的俗常见解预先已在所谓“主观成见”与所谓“客观见解”之间划下了楚河汉界,并在此基础上赋予了前者以负面价值。然而,这样的预设是否经得起哲学的仔细推敲,则依然值得深入探讨。
一、对伽达默尔“成见”的“正名”
德国哲学家伽达默尔(Hans-Georg Gadamer)在其名著《真理与方法》中便明确地挑战了上述预设:
在理性的绝对自我构造的观念下,被表现为“有限制的前见”的东西,其实属于历史实在本身。如果我们想要正确地对待人类的有限的历史的存在方式,那么我们就必须为“前见”概念根本恢复荣誉,并承认合理的前见的存在。[1](P355)
这里需要指出的是,伽达默尔在此所说的“前见”,就是平时我们所说的“成见”或者“偏见”。但为了肃清观察赋予“成见”一词的种种负面情绪,他宁可使用平时人们较少使用的“前见”一词,其德文为“Vorurteil”,其中“vor”这个前缀表示“前”,而“Urteil”这个词干表示“判断”。不过,由于“Vorurteil”的拉丁文形式为“prae-judicium”,而后者的在英文中的对应词正好是“prejudice”(即汉语中所说的“成见”直接对应的英文词),因此,在下文的正面叙述中,笔者将不再区分“前见”与“成见”这两个提法。
有的读者或许会说,仅仅用不那么带有贬义的“前见”来替换带有更多贬义的“成见”,就想彻底“洗白”我们对于“成见”的种种负面看法,这样的论证恐怕很难服人。然而,更为认真地阅读《真理与方法》的文本,却可以使我们确信,在伽达默尔的上述引文背后,其实至少有两个论证来支持他的观点。下面便是笔者根据自己的理解,对伽达默尔相关思想的重构。
论证一:1.任何诠释活动都必须依赖于一些自身不需要被反复检验的前提,否则相关的诠释活动都无法避免“元语言层面上解释资源不足”的困境;2.如果我们按照启蒙主义者的要求,对所有诠释活动的前提都按照理性的最高标准加以检验的话,那么我们就不得不陷入“元语言层面上解释资源不足”的困境;3.所以,为了避免陷入上述困境,我们就不能认为所有的前见都是有问题的;4.但我们也必须承认:某些诠释活动的结果的确是错误的,而其之所以错误,就是因为它所依赖的前提是错误的;5.所以,出于立论稳妥性的考虑,我们就必须承认:至少有一部分所谓“成见”是豁免于理性检验程序的审查的。
论证二:1.个体理性是有局限性的(譬如,在知识范围、推理能力与决策时间方面的种种局限);2.所以,“诉诸集体智慧”就是在个体理性遭遇“决策信息资源不足”问题时不可避免地采用的一种策略;3.集体智慧本身就往往是“历史权威”的代名词;4.因此,个体的社会人对于权威的接受本身,就是某种“认可集体智慧”的社会心理机制作用的结果,并且是为了应对个体决策资源不足而不得不采取的措施——而并不像偏狭的启蒙主义者认为的那样,意味着对于理性的全面抛弃;5.这种对于权威的接受活动本身就意味着“前见—成见”的最根本来源;6.所以,对于“前见—成见”的采取,乃是个体为了应对资源不足问题而不得不采取的措施。
在笔者看来,伽达默尔的上述观点(严格来说,是笔者所重构的伽氏观点)虽然没有直接涉及今日如火如荼的人工智能研究,却在客观上触及了任何人工智能系统的设计都难以回避的两个问题。
第一,系统运行的原始数据的来源问题。我们知道,任何计算系统的运作都需要人类社会“喂入”初始数据,而这些数据很难不体现特定工作领域人类的“权威”或者“成见”。换言之,如果任何个体人类的诠释活动都无法脱离“成见”而存在(这是前述“论证一”所指出的),那么,对于以任何一种技术路径为依托的人工智能系统而言,其运作也无法脱离人类成见的预先介入,故而,从某种意义上说,人工智能系统只是人类成见的“自动加工器”而已。由此看来,向机器“喂入”怎样的成见以使得其后续运作的产出能够符合人类用户的需求,也便成为所有的人工智能系统设计者都必须面对的一个重要课题。
第二,系统自身的运行资源有限性问题。具体而言,无论是运算能力如何强大的人工智能系统,它依赖的信息资源与计算资源都是有限的,因此,一个足够智慧的系统就应当能够根据某种既定的“捷思法”,以便从既有的历史资源——即伽达默尔所说的“权威”——中获得启发,以最终减少系统的计算负担(关于“捷思法”的讨论详后)。从这个角度看,前述“论证二”对于人类个体之理性有限性的提示,就具有了一种兼及人造机器的普遍性意义。
不过,尽管伽达默尔对于“成见”重要性的辩护具有向人工智能系统设计的领域延伸的潜在价值,对于大多数的人工智能工作者来说,伽达默尔的诠释学依然是一种相对陌生的思想资源。同时,由于伽达默尔本人的文本写作方式过于依赖纯粹人文领域内的学术经典,他对二战后认知心理学对于其立论的某种潜在的“补充说明”作用,也缺乏相应的自觉。而依据笔者浅见,伽达默尔立论中最为粗疏之处,便是忽略了:(甲)决策资源相对匮乏的社会个体在诉诸“集智”时,其实并不总是按照某种单一的路径来纾解信息匮乏的问题的——相反,可能会导致具有不同算法特征的不同“捷思法”在不同语境中被激活;(乙)某种更为广泛的“集智”也将包含单个的信息处理系统自身的微观运行历史,而伽达默尔的立论则过分强调来自社会共同体的集体权威与社会共同体的宏观运作历史。从这个角度看,要将伽达默尔的哲学洞见与人工智能研究的工程学实践相互打通,我们还需要一个中介理论层面的介入,这就是认知心理学对于所谓“捷思法”的研究。这也就构成了本文讨论的基本路线图:先通过深挖心理学界对于“捷思法”的研究的哲学意义来夯实伽达默尔的“成见”观的经验内容,再反过来“拷问”人工智能的现有研究路径。
二、心理学家眼中的“捷思法”以及其哲学意蕴
在专业的理论心理学研究中,“成见”并不是一个被广泛使用的术语。一个与之密切相关的术语是“捷思法”,英文为“heuristic”,有“发现”、“找到”的意思。需要指出的是,尽管这个词在中国现行的大多数心理学与人工智能文献中都被译为“启发式算法”,但依据笔者浅见,这个译法不如“捷思法”更能抓住英文原词的真正含义。非常粗略地说,“捷思法”就是某些特定的推理窍门,以便帮助信息处理系统能够在资源相对匮乏的情况下也可以给出问题的答案。虽然这些窍门一方面既不能保证其运作符合逻辑与概率论的要求,另一方面也并不保证输出的解是“最优解”,但在吉仁泽(Gerd Gigerenzer)等心理学家看来,“捷思法”的存在能够使相关的信息处理系统以最节俭的方式输出适应性的行为,因此其存在是符合自然选择的原理的(我们知道,自然选择并不关心生物体的信念是否是精确的,而只关心其信念是否能够满足其生存的需要)。①
而“捷思法”之所以与我们前面讨论的“前见—成见”相关,也恰恰是因为它与“前见—成见”一样,均由于强调“节俭性”而或多或少地违背了启蒙主义者对理性思维的种种规范性要求(因为对于这些规范的全面落实,往往会逼迫智能体以更不“节俭”的方式付出更大的计算资源)。此外,种种“捷思法”的存在本身,也为个体在决策匮乏的情况下汲取“集智”或“社会权威见解”提供了具体的心理操作路径。
为了更直观地说明“捷思法”的特点,笔者将详细讨论三种经常在心理学文献里提到的“捷思法”,并分别提示它们各自与规范理性要求之间的张力。
(一)锚定捷思法(anchoring heuristics)
锚定捷思法大体是指这样一种心理现象:人们往往依赖对事物的第一印象来作出决策,却对有关该事物的后续情报表示相对的麻木,或即使作出了某些偏离于被锚定印象的策略调整,调整的幅度也要小于正确决策所需要的幅度。站在启蒙主义者的立场上看,“锚定效应”显然是种种不合理偏见的一个重要源泉,因为该效应无法使决策者根据环境的变化迅速调整决策的方向,并由此陷入各种推理陷阱。比如,商家先将某种汽车的初始定价定得很高,以便为消费者设定某种“锚定效应”,尔后再削价让消费者更容易接受新价格——尽管新价格可能依然是超出了商品自身的价值。很显然,正是因为锚定效应的存在,才使得消费者更容易注意到离原价格较近的新标价,而不是离原价更远的商品实际价格。更有甚者,心理学家特沃斯基(Amos Tversky)与卡内门(Daniel Kahneman)还根据心理学测试的结果指出:“锚定效应”使得被试者在计算长数列的乘积时,更容易注意到数列中的前几个数字而忽略数列中的后几个数,并由此在估算乘积总数的测验中获得低分。[2]②
然而,只要我们调整一下自身的评价坐标系,启蒙主义者对锚定效应的这种批评意见就未必站得住脚了。我们不妨将问题反过来想:如果一个智能体不使用锚定捷思法,那么其信息处理进程又当是如何的呢?答案就只有一个了:在得到汽车的任何一次报价后,始终期待着下一次报价,并忽略每次报价之间的先后关系。但在笔者看来,在决策的时间资源不足的情况下,这样的决策方式并不能带来决策系统对于环境的“适应性”。我们不妨再来假设这样一种情况:汽车经销商的每次报价之间的时间间隔是1分钟,而且总的报价次数是10次。这样的话,一种不受锚定效应影响的信息处理系统,必须花费至少10分钟才能够完成关于“是否接受出价”的决策。但如果系统得到的决策时间只有5分钟的话,这样的系统显然没有办法完成相关的决策任务。与之相对比,基于锚定捷思法而运作的决策系统,却完全可能在如此巨大的时间压力下完成类似的任务,尽管其输出的解未必是最优解,但这总比没有任何输出要好。
启蒙主义者可能会辩驳说,对于锚定效应的依赖,分明已经让不少人在市场上受到了奸商的诓骗,或在计算数列时给出了错误得离谱的答案。难道一种得到启蒙精神滋养的成熟心灵,就应当甘于受到种种基于锚定效应的社会愚弄机制的操控吗?
对此,笔者的意见是,在市场上受到虚假报价的愚弄当然不是什么好事,但考虑到如下两个理由,笔者并不认为,对于这些愚弄的摆脱,需要我们付出抛弃以锚定效应为代表的种种认知成见的代价。理由(甲):利用锚定效应而去误导受众认知的社会机制,是在人类特定历史发展阶段而出现的新事物,而在此之前,在漫长的人类演化史中,锚定效应已经帮助人类解决了与生存有关的各种决策问题。因此,仅仅因为某种心理学效应可能产生的负面效果而否认其产生的整体利益,乃是不明智的。理由(乙):在实际生活中,对于汽车实际价格的了解,其实并不是来自于启蒙主义者看重的某种毫无成见渗入的客观计算,而是依然来自于特定专业领域内的“权威见解”。而对于这种权威见解的消化过程,很可能也带有某种更深层次的锚定效应。比如,某位汽车界业内人士的对于某款汽车的内部报价,也会在听者那里产生锚定效应,并由此使得其从经销商那里听到的报价造成的心理效应被大大冲淡了。由此看来,那些在市场上能够作出更多正确决策的成功人士之所以成功,很可能也并不是因为他们的决策过程并没有受到锚定效应的影响,而是因为,由于纯粹的偶然原因,第一次进入他们心智的情报的确具有较高的情报价值。
(二)关于“可获取性”的捷思法(availability heuristic)
大致而言,在这种捷思法的帮助下,如果心理主体被要求对两个事件的发生概率进行评估的话,那个相关示例更容易在记忆中被唤起的事件,往往更容易受到心理主体的偏好。譬如前面所提到的特沃斯基与卡内门,提出的另一个在认知心理学文献中广为引用的案例。如果懂英文的人被问及这样一个问题:“在英文单词中,以字母‘k’开头的单词多,还是以字母‘k’为第三个字母的单词多?”大多数被试者都会认定“以字母‘k’开头的单词多”,尽管实际答案是“以字母‘k’为第三个字母的单词多”。而大多数被试者之所以那么想,显然是因为“以字母‘k’为第一个字母的单词”更容易在记忆中被唤起。[3]而在新闻媒体的运作中,不少从业人员也利用这种捷思法设置思维陷阱,诱使公众认为那些更具“新闻价值”的事件要比其实际上更具普遍性。
对于该捷思法的产生机制,不同的学者有不同的看法。譬如,特沃斯基与卡内门就在前面引用的关于单词数量估计的实验报告中认为,“以字母‘k’开头的单词”的数量之所以被大多数被试者高估,就是因为在历史上,他们实际调用此类单词的频率的确比较高。而施瓦茨(Robert Schwarz)等人则给出了不同的诊断意见。在他们看来,对于相关事项的信息提取的难易度才是使得“以字母‘k’开头的单词”胜出的关键因素:因为它们显然要比“以字母‘k’为自身第三个字母的单词”更容易被提取到工作记忆之中。[4]
不过,无论对这种捷思法的哪一种解释是正确的,启蒙主义者肯定不会在健全的理性思维方式中为基于“可获取性”的心智算法预留空间。其理由也是非常明显的:在他们看来,这样的算法会引导我们对于事件发生的概率作出错误的估计,并由此配置错资源。比如,医疗部门就可能由于受到此种捷思法的影响,低估某些不那么容易想到的疾病风险,并由此作出对公众整体健康前景不利的决策。启蒙主义者或许还会补充说:哪些事项更容易在记忆中被唤起,乃是一个非常偶然的心理学现象,仅仅从这种偶然的线索出发就作出对于世界的实际状态的评估,实在是太不负责了。
对于启蒙主义者的这种见解,笔者的回应是:“偶然性”并不是心智构架中可以被完全排除的因素。具体而言,如果一个心智系统的长期记忆地址储藏的信息数量已经远远超出其工作记忆的最大容量,那么,这样的智能系统就必须具有某种特定的算法,以便只把长期记忆库中与当下任务有“相关性”的信息引入其工作记忆池。很显然,在特定的时间压力下,为了判断长期记忆库中的哪些信息与当下任务“相关”、哪些又“不相关”,系统就只能按照系统运作的内部特征来确立相关的筛选标准。譬如,根据相关事项在历史上被调用的频率,或根据调用这些事项的简易程度。但显而易见的是,系统内部的运作逻辑与外部世界的运作逻辑之间存在天然的差异,对于外部世界而言,这些经由系统内部运行历史而形成的内部参数的配置显然带有某种“偶然性”。但反过来看,若没有任何一种武断的、偶然的内部信息筛选标准,系统也就无法在浩瀚的信息海洋中找到方向,进而也就无法对外界作出任何回应。由此我们甚至可以设想:倘若我们为了杜绝各种偶然因素的“干扰”,而强制一个信息处理系统在不依赖“可获取性”的捷思法的前提下去进行推理活动,那么,这个信息系统的工作进程又将如何呢?很显然,在面对“在英文单词中,以字母‘k’开头的单词多,还是以字母‘k’为第三个字母的单词多”这样的问题时,启蒙主义者偏好的那类信息处理系统,只能傻乎乎地将两类字母从头到尾都数一遍,此类工作需要的时间资源与信息资源,显然都是惊人的。
当然,面对笔者的这种批评,启蒙主义者或许会这样继续为自己辩白说:“这样的信息处理过程固然耗时,但总比仓促地得出一个明显的错误结论来得好。”但这里必须要提出的一个更深的问题是:对于面临巨大生存压力的先民而言,知道“以字母‘k’为第三个字母的单词”的数量,的确多于“以字母‘k’为首的单词”,到底有什么价值呢?从概率论角度看,这样的问题显然都涉及对于两类对象的“基础比率”的比对问题(所谓基础比率,就是指一类对象在所有统计学对象中占据的百分比),因此它涉及的只是某种非常抽象的知识罢了。但生存斗争首先是关于个体及其行动的,而上述这类抽象知识除非通过某些“中项”的过渡机制而进入实践推理,否则就难以兑现为个体的实际行动,并由此增强其适应性。
为了理解这一点,我们不妨再来思考一个与“估字母数”的案例平行,但更具演化论气息的新案例:对于一个原始人的生存而言,他更需要获知的是“被蚊子叮咬而死的原始人是否多于被剑齿虎攻击的原始人”这一问题的答案,还是“到底是被剑齿虎攻击更容易死,还是被蚊子叮咬更容易死”这一问题的答案呢?很明显,前一问题采用了基本比率的格式后,后一问题则采用了后验概率的格式,一个理智正常的原始人显然应该对后一个问题的答案更感兴趣,因为对于前一个问题的知识,其实是无法指导原始人在面对真实的剑齿虎时该怎么做的(这又是因为:“剑齿虎所吃掉的人占据的基本比率”的高低,在数值上无涉于“在遇到剑齿虎攻击后原始人的生存率”的高低)。从这个角度看,基于“可获取性的”心智算法之所以会在面对“估单词数量”这样的任务时“出丑”,恐怕也是因为这样的任务已经脱离了自然选择面对的原始环境,而不具有与人类生存的直接关联性了。
(三)关于“辨识”的捷思法(recognition heuristic)
根据该心智算法,如果两个对象对主体而言,一个是比较熟悉,而另一个则难以辨识,那么,更容易被辨识者就会被估测为具有更高的价值。下面的心理学测验,则为这种捷思法的运作提供了具体的案例。假设有这样一张考卷,考卷上有一列由美国城市名字构成的对子,如“史普林菲尔德—旧金山”、“芝加哥—小石城”,等等。考生的任务,便是从每个对子里找出城市居民比较多的那个城市(在此期间任何考生不允许参考任何书籍以及网络上的相关信息),考官则根据考生的答对率进行判分。现在我们将考生的考卷分为两组:中国学生的答卷与美国学生的答卷。你猜哪一组的平均分会更高一点呢?
很多人都会认为美国的学生考分会高一点,因为在他们看来,美国学生总要比中国学生更熟悉美国城市的情况。然而,这个看法其实是有失偏颇的。作为一个大国,美国的行政区划以及相关的人口情况异常复杂,即使是一般的美国人,也仅仅是“听说过”不少城市的名字而已,并不太清楚所有城市的人口规模。而作为中国学生,事情就要相对简单一点。他们做题的时候遵循的是一条非常简单的“捷思法”:凡是中国人容易辨识出的美国城市,一般都是大城市,而大城市一般人口就多。总之,面对两个城市的名字“二选一”的时候,选那个看起来眼熟的地名就是了。而或许让人感到惊讶的是,这种看似“简单粗暴”的解题思路,成功率却相当了得。譬如,德国心理学家吉仁泽与其合作伙伴真做了这个实验,由于他是德国人,他当然是以德国大学生——而不是中国大学生——作为美国大学生的对照组,结果发现,德国学生的平均成绩明显要比美国学生好;而当别的研究者以“两个英国足球队中的哪一个会在联赛中获得更好的成绩”为问题,分别测试土耳其的学生和英国本土的学生后,他们同样惊讶地发现:答案正确率高的,再一次是相对不熟悉英国本土情况的土耳其人。[5](P43-44)简言之,将正面的属性(如人口多、体育强等)指派给你相对熟悉的地名,便是在上面的实验中德国学生与土耳其学生得以打败其美英本土竞争者的“制胜捷思法”。
关于辨识的捷思法的存在,无疑对启蒙主义者的理性观提出了更大的挑战,因为与前几种捷思法不同,人类对此类捷思法的运用,并没有导致明显的错误输出。更值得玩味的是,对于此类捷思法的使用体现出某种“多即少”(more is less)的效应,即“知道的多,反而猜对的少”。启蒙主义者的理性观显然是难以解释这种“多即少”效应,因为在启蒙主义者看来,“多获取各方面的情报”恰恰就是避免主观偏见的有效途径。而依据基于个体信息处理资源之有限性的考量,这种“多即少”效应却很容易得到解释:当一个人对某个对象O有比较丰富(但却远远谈不上完整的)知识的时候,“可辨识度”这一指标就会被淹没在大量的其他指标中,而失去了“第一向导”的作用。在这种情况下,被试者就不得不对大量指标与目标属性之间的关联进行逐一排查,由此即降低了信息处理的效率(这是由考虑的参数增多引起的),又降低了信息处理结果的品质(这是由于考虑的参数彼此之间的冲突引起的)。
由于篇幅的限制,在本节中正面涉及的“捷思法”便主要是以上这些。③现在,我们有必要从一个更抽象的角度来评估这三种“捷思法”的共性,这就是:三者都是对系统内部运行的历史都有一种间接表征,并由此在一定程度上体现了系统的运行过程中的“历史智慧”。具体而言,在锚定捷思法中,第一印象的时间优先性本身就意味着某种微观意义上的历史权威;而在关于“可获取性”的捷思法中,某种通过调用数据的既有习惯构成的历史路径,则成为指导心理主体调取当下数据的隐蔽历史权威;与之类似,在关于“辨识”的思捷法之中,心理主体对于被辨识对象的辨识历史,则构成了其猜测相关对象之内在价值的主要依据。换言之,上述捷思法在人类思维中的广泛运用,恰恰证明,人类是一种依据从历史累积而成的思维习惯,从而与“未来之不确定性”进行战斗的智慧存在者。
从一个更宏观的角度来看,心理学界对上述这些捷思法的研究成果,既印证了前节提及的伽达默尔的“成见”观,又对其作出了有力的补充,相互印证之处体现在,二者都对人类个体的理性有限性以及其对于历史权威的依赖性,作出了重要的提示;而捷思法研究对于伽氏之论的补充价值,则又体现于此类研究揭示的一个要点:在人类共同体的集体智慧与个体的实时决策活动之间,决策个体的自身的心理史必然会起到某种重要的中介作用。譬如,在锚定捷思法中,来自社会群体一端的某种权威信息,很可能就是以“锚定印象”的方式进入个体的心理运作历史,并对后继的相关决策活动产生影响。从这个角度看,在伽氏的论述框架中初步呈现出来的“社会—个体”二元关系,还需要通过认知心理学话语框架的重述机制,而进一步细化为某种自上而下的四层结构:社会权威(群体历史)、心理架构对于社会信息的提取装置、个体心理习惯(个体历史)、当下决策活动。很明显,在这种四层次结构中,本节提到的种种“捷思法”,便为个体与集体智慧意义上的历史权威之间的联系管道提供了大量的实现手段,同时也为种种“成见”的产生,提供了一种具有初步技术细节的说明。
通过上面的分析,读者很容易产生这样一种期望:通过“对于捷思法的算法化”这一重要的环节,我们就可以很容易地将伽氏的哲学洞见引入人工智能的工程设计。然而,真实的情况却并没有这么简单。正如下节要揭示的那样,目下人工智能发展的令人遗憾的现实便是,人工智能界的主流,并没有主动地吸纳心理学界关于捷思法的研究成果。
三、捷思法与人工智能
对于笔者在上节末尾给出的这番评论,熟悉人工智能发展情况的读者或许会感到惊讶:难道“捷思法”(heuristic)不也正是在人工智能领域广泛使用的一个术语吗?凭什么说心理学家对于捷思法的研究成果,尚且没有被人工智能学界所广泛吸纳呢?笔者的应答是:人工智能领域内的捷思法,虽然和心理学意义上的捷思法一样,均具有“减少信息处理系统计算负担”的功能,却并没有真正体现信息系统处理的个体运行历史,并在这种意义上体现出足够的“心理学”意味(遑论在此基础上成为引续共同体之集体智慧的“引水渠”)。下面,笔者便将通过对于相关技术案例的详细解释,来阐明这一论点。
在计算机科学文献里经常提到的一个运用捷思法的案例,乃是所谓“行销商旅行路径择优问题”(travelling salesman problem),简称为“TSP问题”。④这个问题是说,如果我们已知地图上有若干个城市,以及城市两两之间的距离,我们又如何能够为一个行销商找到最短的一条路径,使他能以某个特定城市为出发点兼回归点,并能够经过所有城市呢?从数学角度看,这样的问题带来的计算负担是非常大的,而为了减少此类负担,人工智能专家就会采用一种叫 “贪婪算法”(greedy algorithm)的捷思法。[6](P414-450)“贪婪算法”的基本技术思想是,首先不去寻找问题的全局最优解(因为这带来海量的计算负担),而仅仅满足于寻找局部最优解,并期望局部最优解的积累可以使系统慢慢接近全局最优解。将这个思路运用到TSP问题上去,由此产生的问题解决思路就是:从当下的城市坐标出发,访问与之最接近的一个城市坐标,即至少保证在局域环境中旅行者的行程是最短的。然后通过迭代,使得由此产生的旅行距离可以被延伸到更远的城市坐标去,最终完成全局路程规划。
虽然有研究指出贪婪算法并不能导致系统得到全局最优解[7],但笔者批评此类捷思法的着眼点并不在此。这里更需要提醒读者注意的,乃是此类捷思法与心理学捷思法之间的重要差异。很明显,执行贪婪算法的系统是没有长期记忆的,它只能关注到目下的坐标周围的那些城市坐标,并基于这种观察机械地丈量这些坐标之间的距离,由此再机械地移动到下一个观察点上去。因此,贪婪算法的运作并不包含着对系统既有运作历史的一种哪怕最弱意义上的表征(譬如,当系统像蠕虫一样爬到第八个城市时,它已经不记得它在第一个城市时选择的下一个城市了)。与之相对比,一个完整意义的人类心理主体,恐怕并不是按照这种愚蠢的捷思法来运作的。人类主体在面对此类问题时更可能采取的办法,是回忆他上次进行此类路程规划时给出的方案(此即“锚定捷思法”),或是去更偏好那些在视觉上更为直观的路径规划(此即关于“可获取性”的捷思法),或是去偏好那些首先经过那些更有名的城市的路径规划(此即关于“辨识”的捷思法)。不难看出,人类主体对于上述这些捷思法的运用,显然已经预设了人类的认知架构是能够调取长期记忆中的信息,并能够赋予每一个城市以相关的语义的。但这样的能力显然是“贪婪算法”所不具备的。
那么,为何预设了人类语义与记忆机制的人类捷思法,要比“贪婪算法”更优异呢?道理很简单:仅仅只能反映局域坐标点之间关系的“贪婪算法”,由于一开始就放弃了对于全局情况的把握,因此最终接近全局最优解的机会本来也就不会太大。与之相比较,“锚定捷思法”、关于“可获取性”的捷思法与关于“辨识”的捷思法都能够帮助心理主体提取路径规划的整体特征,由此“自上而下”地进行路径优化选择。不难想见,如果心理主体事先就获得的关于路径规划的历史信息的确比较有价值,那么,这种“自上而下”的规划路径显然就更有希望帮助主体找到全局最优解,或至少更接近之。
那么,为何现有的人工智能系统的设计者没有首先去将人类心理的捷思法“算法化”,而是要另起炉灶,去构建专为机器所用的捷思法呢?其道理其实也不难想见。很多从事人工智能研究的从业者都是数学专业(而不是心理学或语言学)出身,因而习惯于将各种人工智能问题视为数学问题的变种。从纯数学角度上看,在平面上摆放的各个城市的确就是一个个抽象的点,它们也的确并不承载任何文化或历史的意义。因此,在他们看来,人类捷思法预设的意义、记忆、文化与权威,既然在数学上无法处理,故而一种“干净”的人工智能之解法就应该将它们“约分”掉。但从心理学哲学的角度看,这样的处理却恰恰丢失了捷思法存在的最基本意义,即在个体富有意义的当下的决策行为与同样富有意义的历史信息库之间建立沟通管道。打个比方来说,抽离了意义的捷思法,就像切断了与自来水厂联系的水龙头一样,只能成为纯粹的摆设。
熟悉人工智能发展历史的读者或许还会辩白说,在人工智能元老司马贺(Herbert Simon)、肖(John Shaw)和纽艾尔(Allen Newell)对于“通用问题求解器”(General Problem Solver,简称GPS)的设想之中[8](P256-264),研究者们既设计了“长期记忆库”,又在记忆库中预存了大量的“捷思法”。同时,司马贺与纽艾尔设计GPS的初衷,便是希望系统自身能够在资源有限的前提下,通过更为经济的方式来获得自己的推理目标。由此看来,通过GPS规划,心理学家对于捷思法的种种设想,已经得到了算法化的处理。
但在笔者看来,这样的判断依然是粗疏的。为了说明这一点,我们不妨先来查看一下,在GPS架构通常具有的“手段—目标”进路(means-end-analysis approach)中,捷思法究竟扮演了怎样的角色。笔者对“手段—目标”进路的流程概述如下:
(1)先确定系统希望达到的理想状态B,然后再观察系统目前所面对的现状A。由此,系统就得到了对于当下目标的刻画:把A转变为B。
(2)找出A和B之间的差距D,若D目前无法克服,便确立子目标:缩小差距D。
(3)在方法库(method store)中,搜索可以满足子目标的捷思法Q,具体手段是:找到一个备选的捷思法,若它能通过初步的可行性测试,就将它应用于最初的状态A,由此给出结果A*。若它无法通过最初的可行性测试,则系统开始寻找下一个备选的捷思法,直到找到为止(“可行性检测”是指,面对表征这些备选操作手段的表达式,系统一一加以检测,以判断其中哪些可满足一个合格的操作手段所应满足的语义限制)。
(4)找出A*与B之间的差距D*,尔后确立新的子目标:找到差距D*。若找不到D*,任务结束。
(5)在任务没有结束的前提下,系统会搜索可以满足新的子目标的操作手段Q*,具体手段是:找到一个备选的捷思法,若它能通过初步的可行性测试,就将其应用于状态A*,由此给出结果A**。若它无法通过最初的可行性测试,则系统开始寻找下一个备选的操作手段,直到找到为止。
(6)比照A**和B,若二者无差距,任务结束。若存在差距D**,则重复上述操作,直到系统找到一个操作手段,直至产生一个与B重合的结果。
在这里特别需要关注的乃是步骤(3)。不难看出,在这个步骤中,GPS设计者提到的那些捷思法,是作为一种僵死的对象现成地摆放在方法库里,而系统对它们的提取过程本身则完全是随机的。与之相比较,以“辨识捷思法”为代表的人类捷思法,则首先是用以提取长期记忆中相关信息的捷思法,也就是某种用以克服上述这种“纯粹的随机性”的信息流动捷径。顺便说一句,在人类的心智架构中,这些捷径的形成固然受到某些偶然性因素的影响,但这种偶然性毕竟是具有历史维度的,因而并不能被消解为纯粹的随机性。从这个意义上说,在GPS中缺乏的,实际上就是某种用以调取既有捷思法的高阶捷思法,而能够与人类捷思法对应,并由此能够与人类的集体智慧相联系的,恰恰就是这种高阶捷思法。此外,在我们评价GPS时还需要考虑的一个因素是,上文给出的“手段—目标”进路的五个计算步骤,每完成一次运行,整个系统就会归零,这也就是说,在第一个轮回中,即使系统发现方法库中的捷思法H对于解决问题P是非常有价值的,它也不会在未来解决一个与P非常类似的新问题时去优先考虑H,因为GPS既缺乏对于问题之间的类似性关系的高阶表征能力,也不包括对于自身运行历史的“自传式记忆”的表征能力。
有的读者或许还会辩白说,人工智能界完全可以不顾心理学界对于捷思法的既有研究成果,而通过某种更为简单、粗暴的方式,以使得人类的集体智慧与人工智能系统相互接驳。譬如,我们可以通过“人工神经元网络”(artificial neural network,深度学习技术的基本母型)或“联接主义”(connectionism)的计算框架,把人类的权威见解顺利地复制到计算系统中去。
那么,人类成见究竟是如何在人工神经元网络的框架中得到体现的呢?要说明这一点,我们还需要对人工神经元网络的运行有一番基本的了解。非常粗略地说,神经元网络技术的实质,就是利用统计学的方法,在某个层面模拟人脑神经元网络的工作方式,设置多层彼此勾联成网络的计算单位(如输入层—隐藏单元层—输出层等)。由此,全网便可以通过某种类似于“自然神经元间的电脉冲传递,导致后续神经元触发”的方式,逐层对输入材料进行信息加工,最终输出某种带有更高层面的语义属性的计算结果。至于这样的计算结果是否符合人类用户的需要,则取决于人类编程员如何用训练样本,去调整既有网络各个计算单位之间的权重(参见图1)。⑤
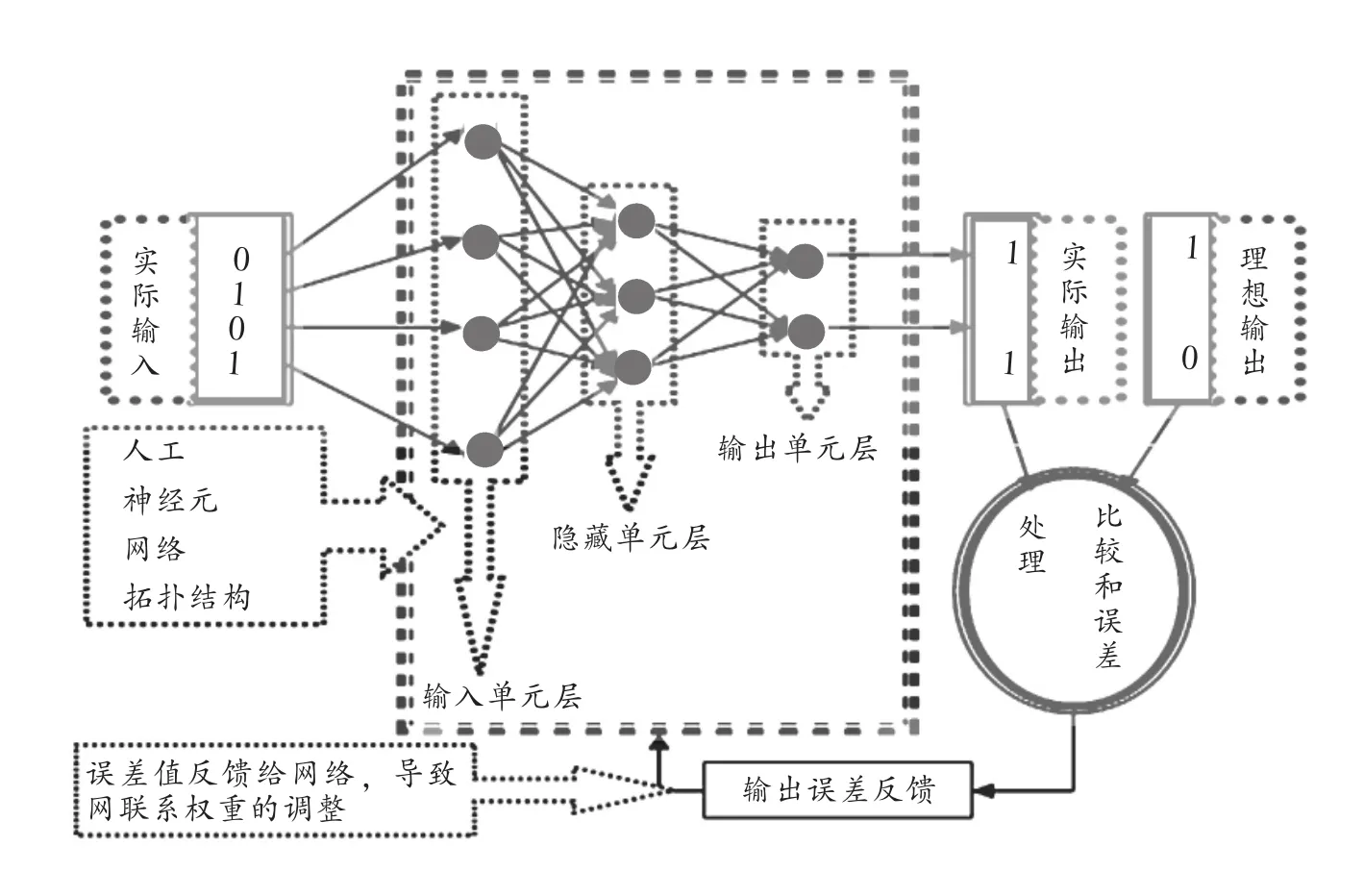
图1 高度简化的人工神经元网络结构模型
大致而言,在人工神经元网络的上述运作流程中,人类成见主要有三个机会介入系统的运作:(甲)通过精心设计系统的训练样本(尤其是通过对输入添加大量标签)来向系统“喂入”某些对于问题求解来说非常重要的先验知识;(乙)通过预先给出的理想解规定系统的学习目标;(丙)通过预先给出的反馈算法来规定系统的权重调整方式。但是,虽然通过这些手段,人类设计者姑且能够粗略地调整系统的性能,但人类设计者往往并不是特别清楚为何特定的系统参数变化能够导致系统运作性能的变化——这一点在人工神经元网络的内部架构已经空前复杂的今天,则显得尤其凸出,这也是人工神经元网络算法时常被称为“黑箱算法”的原因。从这个角度看,一个得到充分训练的人工神经元网络固然在某种意义上可以说是“复制了人类的成见”,但富有讽刺意味的是,人类设计者自身也说不清它们是如何完成这种复制的。更重要的是,对人工元神经网络的初始输入进行人工标注,往往会消耗人类程序大量的精力,同时,在隐藏计算层的数量激增的情况下,系统自身消耗的运算资源也是惊人的。换言之,与心理学意义的捷思法对于人类智能“节俭性”的彰显构成鲜明对比的是,目下的神经元网络—深度学习技术对于人类成见的复制机制,恰恰是建立在海量的数据输入、强大的硬件配置与海量的计算量之上的。⑥因此,这种意义上的人类成见复制机制,在工作原理与工作目的上均与人类自身的心智架构相去甚远,或者说,比起前面提到的GPS对于捷思法的粗糙刻画来说,这样的人工智能设计思路其实显得更不具有智慧性(如果我们将“智慧”或“智能”理解为在“系统相对匮乏的环境资源下对于环境的适应能力”的话)。
综合本节的讨论,我们可以得出:目前的主流人工智能研究——无论是符号主义进路的还是联接主义进路的——都没有真正消化心理学界对于捷思法的研究成果,遑论在这种情况下落实伽达默尔关于“成见”的种种洞见。那么,路在何方呢?
四、总结:走出对主流人工智能的迷信
通过上节的分析我们不难发现,就目下的人工智能研究来说,将心理学研究的捷思法加以算法化的最大障碍,便是对于语义表征的算法化。而这一问题之所以成为问题,则又是因为:一方面,研究捷思法的心理学家总是预设人类心智是具有语义表征能力,而另一方面,人工智能专家又总是倾向于通过剥离语义的方式而将日常生活中的种种具体问题“纯化”为形式问题(无论这种形式是数学的、逻辑学的还是统计学的)。两类学者之间工作理念的这种反差,自然就为人工智能界汲取心理学界的思想营养制造了观念上的障碍。不过,我们也应当看到,在主流的人工智能研究路径之外,将语义予以算法化的努力其实早就已经出现了。譬如,在美国天普大学(Temple University)的计算机科学家王培发明的“纳思系统”中,在长期记忆库中出现的任何一个词项的语义都可以通过某种可计算化的方式得到定义。⑦而且纳思系统本身的运作也在相当程度上基于其自身的系统运作历史,并因为这种依赖性而能够模拟诸如“锚定捷思法”这样的人类捷思法。不过,由于篇幅的限制,笔者在此无法充分解释相关的技术细节。但不幸的是,尽管笔者在不少场合都提到纳思系统的巨大潜力⑧,但它依然没有得到主流人工智能界的足够重视。而更令人担忧的是,在当下的各种媒体平台上,对于主流人工智能技术路径(特别是深度学习路径)的吹捧始终不绝于耳,同时,却很少有人谈及,主流人工智能进路搭建的计算框架,实际上只在一种很微弱的意义上关涉心理学家发现的人类智能架构。简言之,现有的人工智能系统其实还非常“不像人”。
面对这样的批评,主流人工智能的辩护士或许会说:我们根本不用关心人工智能的架构是否真像人,我们只关心它的输出是否能够满足人类用户的需要。但这里的问题便是,如果机器的“输入端”与“输出端”之间的“黑箱”即使在某种非常抽象的层面上都非常不类似于人类自身的心智架构,我们又可以在多大程度上担保其“输入—输出”关系能够与人类的“输入—输出”关系相互吻合呢?就拿前面讨论的神经元网络系统来说,为何这种系统的良好运作,往往要以输入数据的人工标注为先验前提,而人类的心智架构却可以容忍那些缺乏人为标注的“粗糙输入”呢?很显然,除非人工智能专家低下头来,认真向心理学家学习,否则“人工智能”作为“人力智能”之装饰品的本质就不会改变。
主流人工智能的辩护士或许还会说,人工智能专家已经向各行各业的人类专家虚心学习了——譬如“专家系统”对各种人类既有专业知识的学习——为何对心理学的学习就显得格外重要呢?在笔者看来,在回答这个问题之前,复习伽达默尔的诠释学资源便非常必要。从伽达默尔哲学的立场看,人类的集体智慧是通过某种隐蔽的说服机制而成为个体的“前见—成见”的,而个体与其历史传统的不同互动方式,也会为不同意义上的“成见—前见”结构的形成预备了机缘。而在目下主流的符号人工研究智能中,特定专业学科领域内的人类集体智慧,并不是通过对于个体操作系统的“说服”而进入长期记忆地址的,而是通过某种极为粗暴的“代码写入”方式而成为其先验知识。同时,对于同一个型号的人工智能系统而言,批量产生的系统之间也分享完全相同的先验知识,故而,在任何一个这样的个体系统与人类的既有智慧之间,就不存在着进行任何一种意义上的互动的可能性,遑论在这类多重互动可能性的基础上形成不同的“成见—前见”。这也就是说,个体与历史之间相互影响而又相互创造的微妙关系,在现有的主流人工智能系统之中是无法被复制出来的,除非主流的人工智能专家能够改弦易辙,转而去严肃对待个体心理结构用以获取“集智”的、作为信息快捷道的种种“捷思法”。
主流人工智能进路的辩护者或许还会说,我们为何要复制出所谓的“个体与历史之间相互影响而又相互创造的微妙关系”呢?为何不能始终让人类开创知识前进的历史,而始终让机器去复制人类前进的脚步呢?对此,笔者的回答是:从定义上看,这种只能拓印人类前进脚步的“人工智能”系统是没有资格去盗用“智能”的名义的,因为真正的“智能的”信息处理系统的“成见—前见”结构应当是具有自己的个性的(如果我们将“个性”视为“智能”或者“创造性”的题中应有之义的话),而人类历史自身,也恰恰是借由这些个性化的“成见—前见”结构之间的彼此冲撞,才得以开创出种种新的局面。但在主流的人工智能的成见复制机制中,我们却看不到任何得以创生出真正的新事物的机缘。而这又是因为,在主流的人工智能研究那里,前面提到的“历史权威—捷思法—个体心理史—当下决策”的四层架构关系的中间两层已被抽空,并由此使整个结构的动力学机制崩塌。可以毫不夸张地说,未来对于任何一种真正意义上的人工智能系统的严肃研究,都必须以修复这个坍塌的层次结构为前提。
注释:
①吉仁泽表达类似观点的文献很多,较新的文献为Gerd Gigerenzer:Simply Rational:Decision Making in the Real World.Oxford:Oxford University Press,2015.
②譬如,当被试者要求在5秒内计算8个数字的乘积的时候,这些数字进入被试者视野的次序,就会对其估测结果产生致命影响。当数列是以“1×2×3×4×5×6×7×8”的形式出现的时候,被试者会倾向于大大低估算式的值(因为首先出现的都是小数),而当数列是以“8×7×6×5×4×3×2×1”的形式出现的时候,被试者则依然会倾向于低估算式的值,尽管低估的程度稍有缓解(顺便说一句,这个式子的值为40,320,而被试者第一次估算的平均值是520,第二次估算的平均值是2,250)。
③关于捷思法问题更全面的心理学哲学讨论,参见拙著《认知成见》,复旦大学出版社2015年版。
④对于该问题的讨论文献很多,综合性的讨论文献参见David L.Applegateamp;Robert Bixby:The Traveling Salesman Problem:A Computational Study.Princeton:Princeton University Press,2007.
⑤对于神经元网络技术的更详细介绍,请参看拙著《心智、语言和机器——维特根斯坦哲学和人工智能科学的对话》,人民出版社2013年版,第43—53页。
⑥生物统计学家里克(Jeff Leek)最近撰文指出,除非具有海量的训练用数据,否则深度学习技术就会成为 “屠龙之术”,参见Jeff Leek:Don't use deep learning,your data isn't that big,https://simplystatistics.org/2017/05/31/deeplearning-vs-leekasso/。
⑦“纳思系统”的英文全称为“Non-Axiomatic Reasoning System”(非公理推理系统),“NARS”为其缩写,“纳思”为该缩写的汉语音译。关于纳思系统的文献很多,其中最重要的是Pei Wang.Rigid Flexibility:The Logic of Intelligence.Netherlands:Springer,2006。
⑧相关成果主要集中于拙著 《心智、语言和机器——维特根斯坦哲学和人工智能科学的对话》,人民出版社2013年版。
[1](德)汉斯·伽达默尔.真理与方法——哲学诠释学的基本特征(上卷)[M].洪汉鼎,译.上海:上海译文出版社,1999.
[2]Amos Tversky,Daniel Kahneman.Judgment under Uncertainty:Heuristics and Biases.Science,1974,(185).
[3]Amos Tversky,Daniel Kahneman.A v ailability:A heuristic for judging frequency and probability.Cognitive Psychology,1973,(2).
[4]Norbert Schwarz et al.Ease of retrieval as information:Another look at the availability heuristic.Journal of Personality and Social Psychology,1991,(2).
[5]Gerd Gigerenzer et al.Simple Heuristics that Make Us Smart.Oxford:Oxford University Press.
[6]Thomas Cormen et al.Introduction to Algorithms(the Third Edition).Cambridge,MA:The MIT Press,2009.
[7]G.Gutin,A.Yeo,A.Zverovich.Traveling Salesman should not be Greedy:Domination Analysis of Greedy-type Heuristics for the TSP.Discrete Applied Mathematics,2002,(117).
[8]A.Newell,J.C.Shaw,H.A.Simon.Report on a General Problem-Solving Program.Proceedings of the International Conference on Information Processing,1959.
【责任编辑:赵 伟】
根据伽达默尔的哲学诠释学思想,“成见”是人类个体借以获取集体智慧之结晶,以便弥补个体理性之不足的重要途径,因此,俗常人们赋予“成见”的种种负面印象,在相当程度上是有所偏颇的。而当代心理学对于“捷思法”的研究,则可以被视为对于伽达默尔的“成见”观的有益补充,因为所谓“捷思法”,在本质上就可以被视为心理主体调取历史信息资源的某些心理捷径。然而,尽管人造的信息处理系统像人类心理结构一样,肯定也会遭遇到“决策资源不足”问题的困扰,伽达默尔的“成见”论与心理学界对于“捷思法”的研究成果的精髓,却一直没有被主流人工智能界所吸取。毋宁说,目前主流人工智能所运用的“捷思法”在运作机制上是与人类“捷思法”相去甚远的,因为前者既不能像人类“捷思法”那样表征语义,也不能像人类“捷思法”那样体现心理系统自身的运行历史。从这个角度看,目前的主流人工智能系统缺乏“在决策资源匮乏的情况下灵活应对环境压力”的能力。
B017
A
1004-518X(2017)10-0005-13
国家社科基金项目“自然语言的智能化处理与语言分析哲学研究”(13BZ X023)、国家社科基金重大项目“基于信息技术哲学的当代认识论研究”(15ZDB020)
徐英瑾,复旦大学哲学学院教授、博士生导师。(上海 200433)
