对分布式数据库查询算法的改进与应用研究
2017-11-30杨燕艳
杨燕艳
(苏州托普信息职业技术学院,江苏 苏州 215311)
对分布式数据库查询算法的改进与应用研究
杨燕艳
(苏州托普信息职业技术学院,江苏 苏州 215311)
针对分布式数据库数据查询难的情况,文章对分布式数据库查询算法原理及优化问题展开了分析,然后提出了基于贪婪算法的改进查询算法,并对算法进行了应用测试。从应用效果来看,采用改进算法能够降低数据库查询代价,并保证查询合格率,因此能够满足系统的运行需求。
分布式数据库;查询算法;贪婪算法
随着信息技术的发展,大数据时代已经全面到来,对数据管理提出了更高的要求。采用分布式数据库,能利用其强大的数据管理功能满足数据存储和管理的需求。但就目前来看,分布式数据库也将受到分布性和冗余性的影响,以至于难以快速实现数据查询操作。而对分布式数据库查询算法进行改进,能进一步提高数据库查询效率,并降低数据库的传输代价,进而使分布式数据库得到更好的应用。
1 分布式数据库查询算法原理及优化问题
在分布式数据库查询方面,得到广泛应用的传统算法为半连接算法。从算法原理上来看,就是利用半连接操作减少操作连接关系数量,以加强网络数据传输量控制,进而实现查询优化[1]。半连接算法由连接和投影构成,需要完成关系代数运算,先假设节点A和B上分别拥有两个随意待连接关系R和S,然后根据属性条件R.A=S.B进行半连接操作,可以得到如下公式:
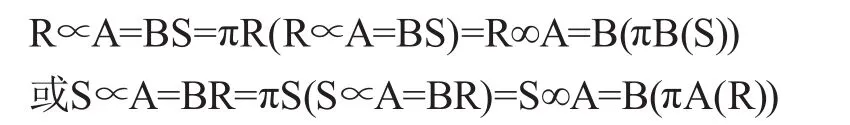
式中,∞指的是连接操作,∝指的是为半连接操作,投影操作用π表示。对算法的连接过程进行研究时,可以简化传输代价公式,得到T=c0+c1x(c0)。其中,c0指的是两站点经过初始化得到的一次传输代价,c1代表是传输率,x指的是数据传输量。按照简化公式实现半连接,即R∞A=RS,首先还要先对节点B上的关系S在属性B上的投影值进行计算,得到πB(S)。在此基础上,需将计算结果由节点B传至A,得到传输代价c0+c1×size(B)×val(B[S])。在该表达式中,size(B)即为属性B的长度,val(B[S])为该属性在S中的数量。A节点完成投影值接收后,会进行半连接的计算,得到R’=R∝S,执行R∞πB(S)操作。将得到的结果从A传递至B,将得到传输代价c0+c1×size(R)×card(R’)。在该表达式中,size(R)即为R的长度,card(R’)为其元组数。B在完成结果接收后,会执行R’∞A=BS操作,得到如表1所示的结果集。
从算法结果来看,最终所有结果在一个结点上得到了集中,以至于无法对算法具体应用情况进行考虑。受这一因素的影响,请求节点可能与结果集存放节点并不相同。如果存在大量结果集,发送查询请求就会因一些节点需完成大量数据传输而出现拥堵问题,而另一些节点则会被闲置,进而导致负载不均衡。而分布式数据库具有数据量大和数据属性多的特点,采用传统半连接算法将无法完成传输代价的有效缩减,从而导致系统在数据传输的过程中产生较多数据冗余和较大的通信代价。针对这一情况,还要对分布式数据库查询算法进行改进优化,以便达到更好的算法应用效果。
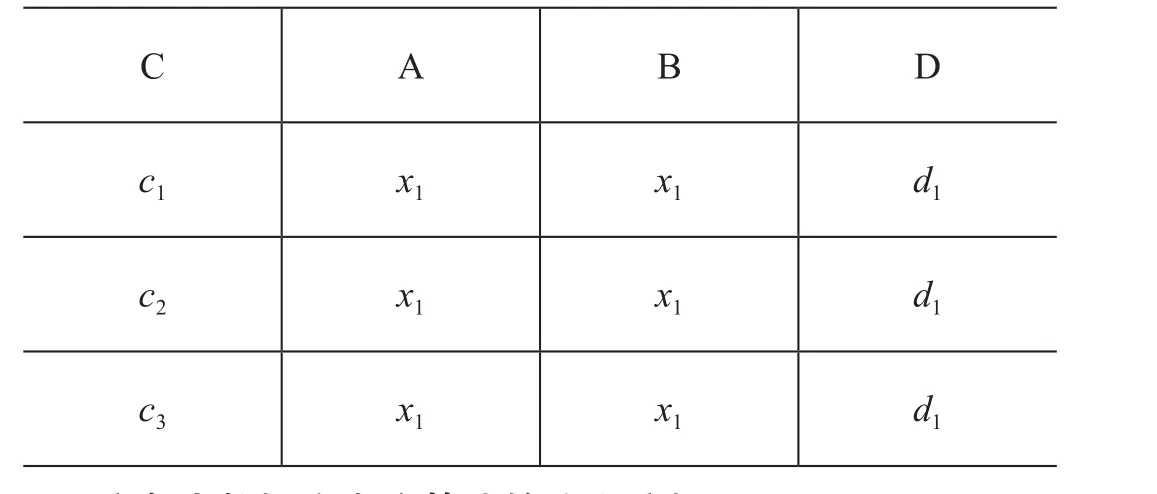
表1 R’∞A=BS结果集
2 分布式数据库查询算法的改进分析
2.1 数据库通信建模
在分布式数据库查询的过程中,查询操作执行所消耗的代价由数据处理代价、通信代价和存储器访问代价构成。由于分布式数据库的网络节点较多,所以相较于其他代价,分布式数据库的通信代价更高,因此主要还要完成通信建模分析[2]。为简化问题的分析,可以对剩余两种代价进行忽略。假设在分布式数据库中,存在有A,B,C,D 4个网络节点,各自拥有10,5,20,15的数据量,彼此间拓扑关系和通信距离如图1所示。在数据传输的过程中,延迟和费用都会对通信产生影响。而在对通信整个传输开销进行衡量时,利用费用得到开销最小,传输数据量也最小,因此费用将起到至关重要的作用。结合这些特点,可以得到CCOM(x)=c0+c1×x的模型,其中c0为数据传输一次需要的固定费用,即启动代价,c1指的是单位传输数据费,可称之为单位传输代价,x依然为数据传输量。
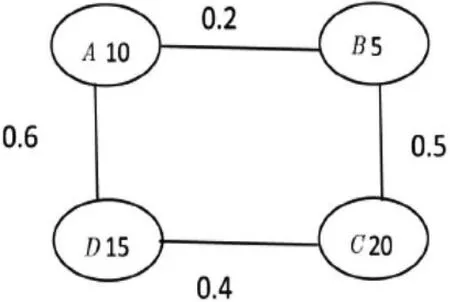
图1 建模查询
2.2 算法的改进思路
针对分布式数据库的查询问题,可以引入贪婪算法实现对传统半连接算法的改进。所谓的贪婪算法,又被称之为贪心算法,就是在问题求解的过程中,先进行当前最好选择,从而得到局部最优解。而通过选择一系列局部最优解,就可以通过贪婪选择得到问题的整体最优解。所以采用贪婪算法,需要以迭代方式进行选择,每次选择都要将问题简化为规模小的子问题,然后通过求解子问题的最优解确定问题最优子结构[3]。采用该算法实现分布式数据库查询连接算法改进,可以根据要求完成相应度量法则的选取,从而实现对分级事件处理方法的优化,按照顺利实现多输入。如果输入无法与部分最优解融合得到可行解,则可以将该输入舍去,所以能够完成最优的依次分级处理。在连接查询数据库的过程中,采用该算法可以利用中间查询反馈结果值进行消耗通信代价的虚拟表示,然后在不同数据节点连接查询时完成消耗代价最小的中间结果查找,并通过合并结果降低系统查询代价。采用贪婪算法实现原有数据查询算法改进,其实是先利用静态优化方法完成结果执行,以免系统通信开销过大[4]。在此基础上,则可以通过计算数据统计结果与实际偏差完成动态规划方案的调用,即利用启发式规则完成各种查询方案的筛选,然后根据消耗代价完成最优方案的选择。
2.3 改进算法的提出
按照上述思路,可以得到改进的查询算法。首先,在连接相邻数据服务器节点时,可先进行连接消耗代价最小的连接运算查找,即逐次完成相邻节点连接查询代价计算。按照C节点∞相邻节点=关系节点数据量×相邻关系节点数据量×通信距离的计算公式,则能得到CA∞B=10×5×0.2=10,CB∞C=5×20×0.5=50,CC∞D=20×5×0.4=120,CD∞A=15×10×0.6=90。通过计算,可以发现A和B两个节点连接消耗的通信代价最小。对这两个节点进行合并,则能得到如图2所示的结果。
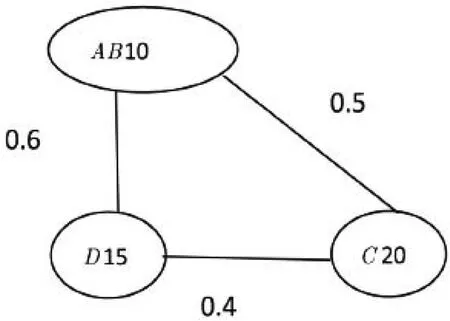
图2 A和B的合并结果
完成A B合并之后,可以按照上述步骤进行再次计算,以得到最小的查询代价。具体来讲,就是得到CAB∞C=10×20×0.5=100,CD∞AB=15×10×0.6=90,CC∞D=20×5×0.4=120。由计算结果可知,需要对AB和D进行合并。最后,对ABD和C进行合并,则能得到CABD∞C=90×20×0.5=900。最后,在对整个分布式系统进行查询时,需要消耗的通信代价应该为CA∞B+CD∞AB+CABD∞C=1 000。由此,可以得到(((A∞B)∞D)∞C)的查询顺序,从而实现对查询的优化处理。采用不同查询顺序所消耗的查询代价如表2所示。通过对比可以发现,采取不同的查询顺序,最后一步都将消耗1 000的通信代价,但是中间消耗的查询代价并不相同。而采用得到的最优查询顺序,消耗的代价总共为1 100,比其他查询顺序都小。
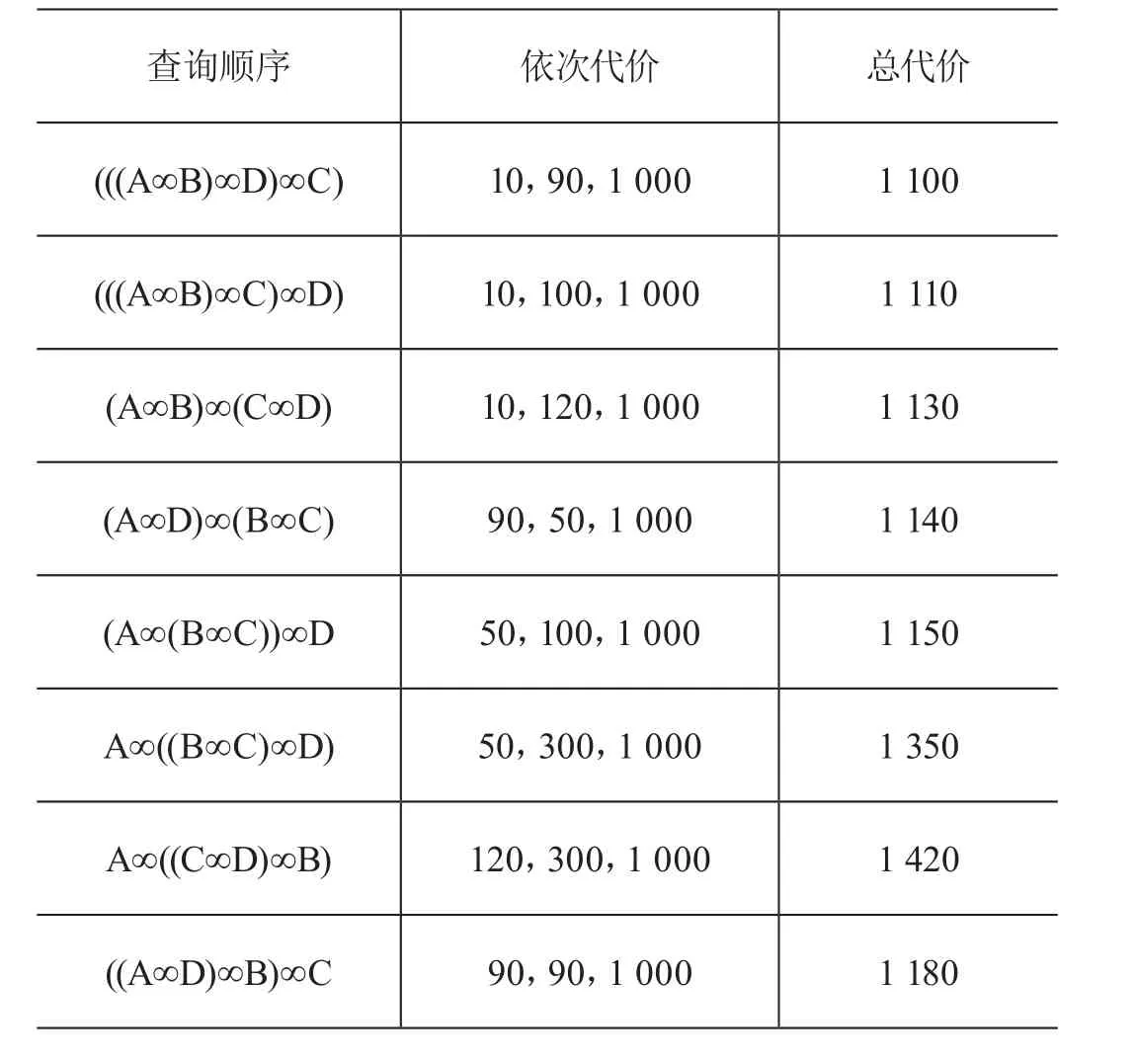
表2 不同查询顺序的查询代价
3 分布式数据库改进查询算法的应用分析
3.1 数据库系统分析
为验证提出的改进算法的应用效果,还要以新农合分布式数据库的查询为例。该数据库为数据库管理系统(Data Base Management System,DBMS),利用不通网络服务器进行数据分散,所以各服务器相当于系统数据子集,即包含门诊数据、药品数据等数据分别存储在各省县的医疗卫生服务部门服务器中[5]。在对该数据库进行查询时,需完成多部门节点数据的协同处理,所以节点负荷较大,需要利用优化查询算法减少系统额外通信开销,进而使数据库系统保持流畅运行。而各服务器都采用了统一操作系统,即Windows 2003 Server,系统中央处理机(Central Processing Unit,CPU)的内存为4 GB,主频2.4 GHz。在数据库管理上,均采用SQLServer2005。
3.2 改进算法的应用
在算法测试的过程中,将农民参保信息数据库服务器设定为A节点,其中共包含100 000条元组,由农保编号、出生年月等参保信息构成。其次,需要将医院信息系统(Hospital Information System,HIS)数据库服务器设定为B节点,其中包含50 000条元组,由农保编号、出生年月等门诊住院信息构成。再者,需要将卫生部门数据库服务器设定为C节点,其中包含200 000条元组,由农保编号、出生年月等新农合数据统计信息构成。最后,需要将负责新农合报销的保险公司数据库服务器设定为D节点,其中包含150 000条元组,由农保编号、出生年月等报销记录数据构成。此外,在应用改进算法进行数据库查询优化时,还要弄清楚各节点间的通信距离。具体来讲,就是要根据各服务器间通信传输距离完成各节点通信距离设定,即A与B节点距离设置为20,B与C节点距离设置为50,C与D节点距离设置为40,A与D节点距离设置为60。明确各节点关系后,则可以按照提出的改进连接算法进行数据查询连接。
3.3 算法的应用效果
采用不同连接顺序的实验结果如表3所示。由结果可知,采用之前得到的最优连接方法,能够有效节省信息查询时间,能够使系统在最短时间内响应用户的数据查询操作。而消耗的时间代价较少,也意味着系统能够更多地完成数据处理任务,尽量做到即时结算报销,因此能够满足新农合数据库系统对数据查询的实时性要求。

表3 不同查询顺序的实验结果
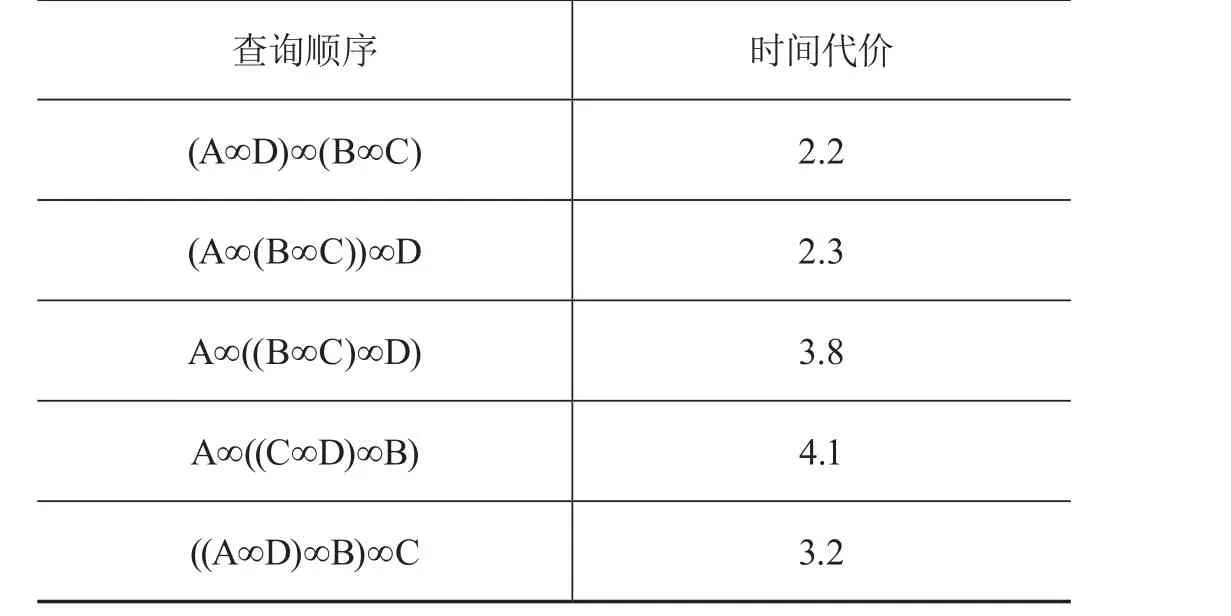
续表3
值得注意的是,在验证改进算法应用效果时,还要认识到无论采用哪种算法都会不可避免地出现结果不为最优的情况。所以,还要对比原有算法与改进算法得到较优解的合格率,以确保数据查询结果的正确性。为此,还要进行6组数据的查询,每组数据查询次数为100次,然后进行合格率的统计。而只要查询代价与最优代价差值不超过设定范围,可以认为查询结果合格。原算法与改进算法的查询合格率比较结果如表4所示。由结果可知,相较于原来的算法,使用改进算法能够获得更高的数据查询合格率。而随着数据关系数量的逐渐增多,无论是原有算法还是改进算法的查询合格率呈现出下降趋势。但相较于原有算法,改进算法的查询合格率一直维持在80%以上。由此可以认为,改进算法比原来算法有更高的稳定性。
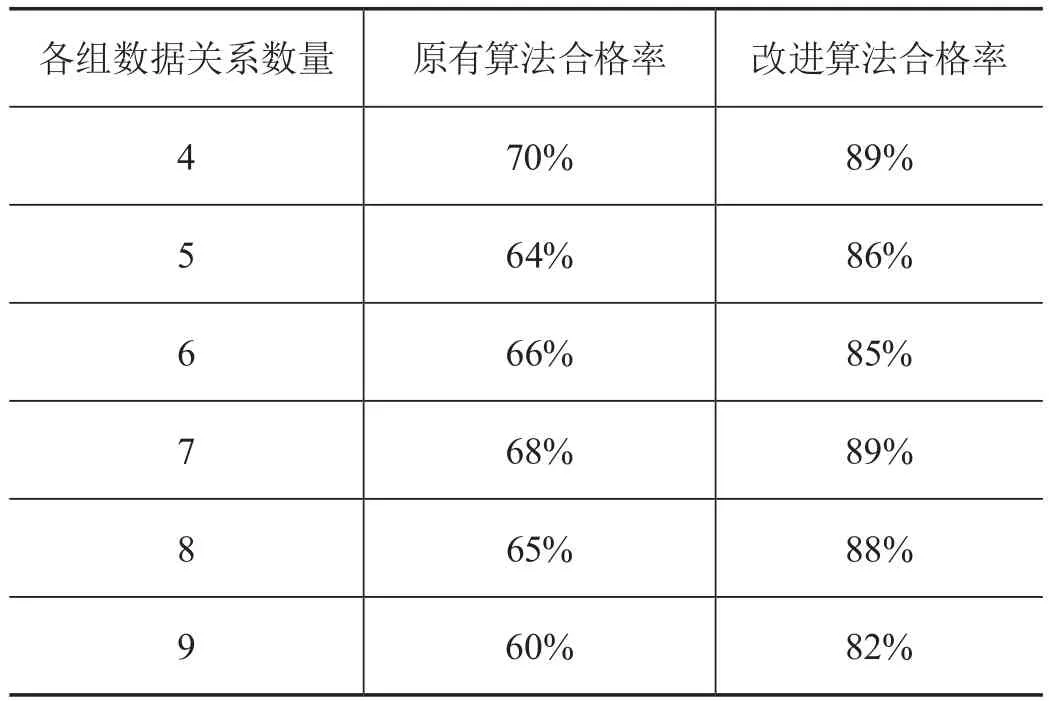
表4 原有算法与改进算法的查询合格率比较
4 结语
通过研究可以发现,在分布式数据库查询方面,由于数据库查询需要完成大量数据传输,所以采用传统半连接算法难以完成通信代价的缩减,将导致系统无法及时响应用户操作。而利用贪婪算法对原有算法进行改进,则能通过查找数据查询的最优顺序简化查询过程,从而在降低系统通信代价的同时,获得更高的查询合格率。因此,该种算法能够在分布式数据库查询中得到较好的应用,以满足数据库系统的数据检索要求,使系统工作效率得到进一步提高。
[1]吴洋,温佩芝,邓星,等.一种改进的分布式数据库查询优化遗传算法[J].桂林电子科技大学学报,2015(3):217-221.
[2]刘晓丹.基于Oracle分布式数据库的查询算法改进研究[J].自动化与仪器仪表,2015(11):164-165.
[3]于洪涛,钱磊.一种改进的分布式查询优化算法[J].计算机工程与应用,2013(8):151-155.
[4]李川.应用半连接的分布式数据库查询优化算法[J].重庆理工大学学报,2013(11):74-77.
[5]杨浩,林喜军,曲海鹏.分布式网络下改进的Top-k查询算法[J].计算机工程,2017(2):79-84.
Research on the improvement and application of query algorithm in distributed database
Yang Yanyan
(Suzhou Top Institute of Information Technology, Suzhou 215311, China)
In view of the difficult situation of data query in distributed database, this paper analyzes the principle and optimization of distributed database query algorithm, and then proposes an improved query algorithm based on greedy algorithm, and applied the test to the algorithm. From the application effect, the improved algorithm can query the cost of low database and ensure the query pass rate, so it can meet the system operation requirements.
distributed database; query algorithm; greedy algorithm
杨燕艳(1981— ),女,江苏南通人,讲师,学士;研究方向:数据库研究。
