基于改进语义分层的无人飞行器场景理解∗
2017-11-28任民
任 民
(江苏南京半山园 南京 210016)
基于改进语义分层的无人飞行器场景理解∗
任 民
(江苏南京半山园 南京 210016)
随着无人飞行器的大范围普及,针对其场景理解的技术和应用也变得越来越重要。论文采用BOO原理建立语义标注模型,利用地图软件中显示的瓦片金字塔技术,结合事件识别领域提供的训练数据集和测试数据集,提出了一种新的语义分层方法。实验仿真证明该方法能够使无人机在不同高度拍摄的场景中识别出相应的景物。
场景理解;视觉字典;语义标注;语义分层;瓦片金字塔
1 引言
图像理解、事件理解、场景理解是图像分析的三部曲,图像标注是基础,事件理解是目的,场景理解是关键。理解的主要媒介就是视频,相当于人的眼睛或镜头捕捉到的画面,而事件识别是人类大脑的图像分析或机器模拟人类的图像分析技术[1]。
视觉场景理解的定义为在环境数据感知的基础上,结合视觉分析与图像处理识别等技术手段,从计算统计、行为认知以及语义等不同角度挖掘视觉数据中的特征与模式,从而实现场景有效分析、认知与表达。
自然场景具有非结构化特性和随机性。由于光照、地形及运动等多种因素会使得自然景物在视觉系统中的成像有显著差异,加上结构化建筑物和室外道路这些特定人造场景,增加了对非规则自然景物识别与理解的难度。
现今的研究大多集中于自适应地对场景进行快速理解,并利用多传感器信息融合技术提高自然场景理解的鲁棒性。近年来,结合数据挖掘、机器学习、生物认知和统计建模等技术,包括以图像处理为主的多层次场景图像表达,基于不同学习策略的场景信息有效学习,确保视觉系统鲁棒性的系统知识结构与视觉控制策略,以及与生物认知学相结合,为场景辨识和识别提供了许多解决方案[2~3]。其中最具代表性的是由美国国防高级研究计划局主办的野外无人车挑战赛,参赛无人车在室外复杂场景下的深层环境感知和稳定运行推动了自然场景理解在实际平台上的技术转化。
本文结合无人机飞行时期场景识别的应用背景,利用地图软件中显示的瓦片金字塔技术与现有的图像识别技术相结合,提出一种语义分层的场景识别方法,不同的层级,其标注的事件也会不同。通过仿真实验,可以看出这个方法可以提高无人机在不同情况下场景识别的实时性和准确性,具有应用前景。
2 Texton特征提取
Texton特征提取的流程如下:

图1 Texton特征提取流程
首先将RGB像素图转变成Lab矢量图。为了使图像更符合人脑接收视觉信息的标准,使用Gauss滤波器、高斯拉普拉斯滤波器和高斯一阶微分滤波器对Lab颜色空间进行滤波,使用不同的滤波器,可以检测出图像不同方面的信息。而这些图像中的基本信息能够对最后的图像子块结构进行很好的模拟和重构。滤波函数如下所示:
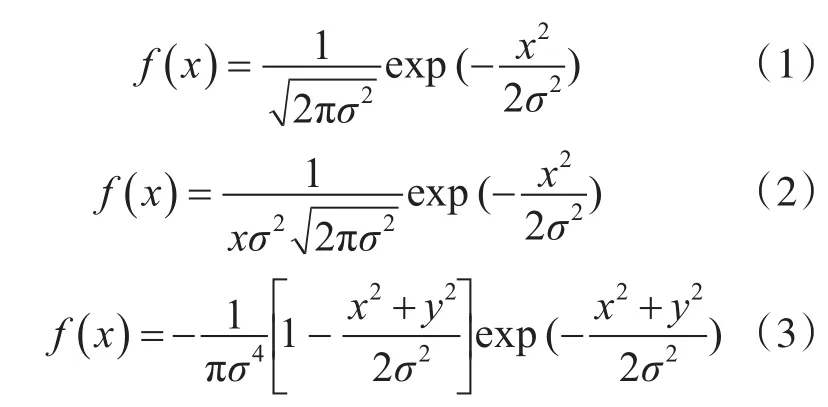
然后使用k-means聚类算法将通用的像素点结构进行筛选,经过n次迭代,得到图像中有效的基本结构的点。这些点构成的集合就是Texton字典[4]。获得了图像的Texton字典后,即可进行BOO模型构建了。
3 BOO模型
如果将场景图像理解按照低、中、高三种表达层次进行划分,可对应分为图像特征识别、图像语义标注和图像分类注释三个层次。其中作为中间层的图像语义标注是利用图像低层的颜色、纹理、Texton等特征来形成图像不同区域的语义信息。该信息是连接低层和高层的桥梁,可克服高低两层之间表达跨度较大所产生的弊端[5]。
本文采用Bag of Objects(BOO)模型。在图像理解中,一张图像会被描述成很多物体对象的集合,只考虑对象出现次数,而不考虑出现位置,这样的一张图像如同装满了物体对象的袋子。BOO模型的最大特征就是借助了主题对象语义这个中间键,缩短了高层图像事件与底层图像特征之间存在的语义鸿沟,如图2所示。将BOO引入图像语义标注检索技术,一般都是将每幅图像看作一个文档,图像中对象对应的词就是文档语义。结合前文使用的Texton字典特征,可以提高BOO模型对语义检索的准确性。
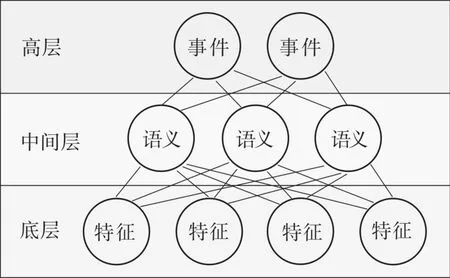
图2 对象语义中间键
通过BOO模型进行图像语义标注有两个过程——训练模型过程为测试标注图像过程。
1)训练模型过程
训练模型过程的核心步骤分为以下三点[6]:
(1)找到图像中的主题词汇;
(2)通过主题词汇这个桥梁找到待标注图像中的主题词汇概率分布;
(3)通过语义词汇在主题中的概率分布计算出测试图像语义词汇的概率分布。
这个过程与人类认知图像的过程非常相似[7]。训练模型过程其实就是模仿人类的学习过程,目的在于让计算机学会图像中都有什么样的主题特征,并且让计算机记住每种主题包含的词汇分布。
2)测试标注图像过程
基于BOO模型的图像标注系统的整体结构是将图像集分为训练集图像(被手工标注的图像)和测试图像(待系统标注图像)[8]。将训练图像通过处理得到训练图像的视觉词汇特征,这样训练图像集就成了两种词汇的集合,即语义词汇和视觉词汇。接着对图像集进行LDA建模,分为以下四个步骤:
(1)得到P(w|z)和P(z|d)两个关于主题词汇的概率分布[9~10];
(2)针对视觉词汇建模,结合上次得到的P(z|d)可以得到P(v|z),即视觉词汇在主题词汇中的分布规律;
(3)测试图像只有视觉词汇特征,结合训练得到的P(v|z)可以计算出P(z|d),即测试图像中隐藏的主题词汇[11];
(4)最后可以由P(z|d)和P(w|z)计算出测试图像的P(w|d),即标注结果,语义词汇的概率分布。
4 语义分层标注
通过飞行中的无人机中的摄像头拍摄到的场景往往具有很大的不确定性,除了天气因素造成相同的场景不同的呈现之外,无人机在不同的高度拍摄到的相同场景也会有不同呈现。由于各种不确定因素的存在,对于场景中的景物辨识具有一定的模糊性,并经常导致分类的错误。
为解决这类问题,需要对构建场景的知识库,对语义进行分类、约束和分层[12]。分类可以借助有已的语义库,约束主要涉及到物体间的关联信息,如图3所示。

图3 语义的分类和约束
语义分层主要是将语义由“概括”向“具体”的层次划分,参考地图显示中的瓦片金字塔技术,在无人机离场景距离远时,仅识别公园、小区、树林、湖泊等大目标,在无人机离场景距离近时,可以识别树木、房屋等小目标。识别大目标到小目标之间的切换通过无人机上配备的距离测量仪测量的距离远近动态转换。
分层语义模型如下。
上层语义:无人机在高空时,主要语义为城市、农田、河流、湖泊等
中层语义:无人机在中空时,主要语义为小区、公园、树林、道路等。
下层语义:无人机在低空时,主要语义为树木、房屋、桥梁、地标等。
如图4所示。
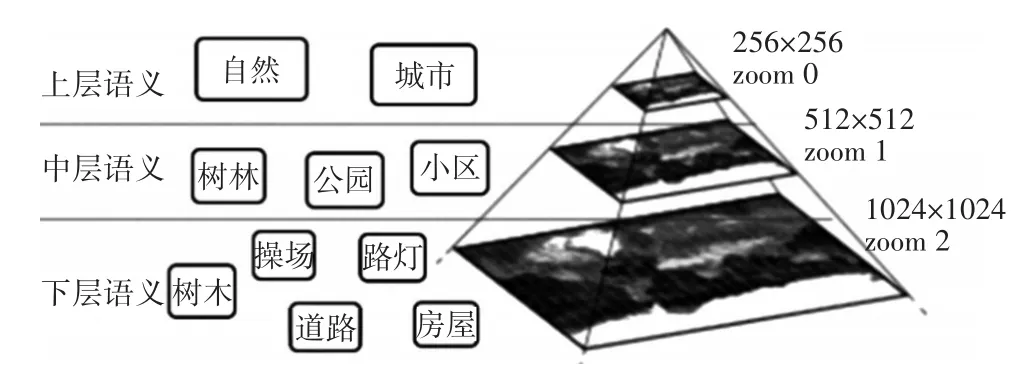
图4 分层语义模型
5 结果验证
本文采用模拟仿真的方法,对本文提出的算法进行仿真验证。
为了提高开发效率,实验数据通常并不需要自己构建,而是采用成熟的数据集,本文采用分类领域影响非常大的Standford background数据集,包括572张训练样本和143张测试样本,共有包括建筑物、水、天空等在内的8个类别,能基本涵盖无人机飞行时所处的场景信息。然后,将这些图片分为远景、中景、近景三层。通过在Matlab仿真软件上采用本文所述的Texton特征提取、分层语义算法,用搜索算法遍历整个数据集,最终输出最符合特征的语义。具体过程如下:
1)输出一张场景图片;
2)在单选框中选择使用哪一层的语义;
3)用鼠标划定需要理解识别的区域;
4)通过后台计算,在识别结果中显示对应的语义。
本文所采用分层语义算法所完成的近景、中景、远景语义标注效果分别见图5、图6、图7所示。

图5 近景语义标注
由图4、图5、图6可以看出,在图片与语义级数匹配的情况下,系统可以准确地识别出指定的图像,并将输出相应的语义。
6 结语
本文只是对场景语义进行了粗略的分层,在实验仿真时也只是放入静态图片进行测试并证明方法有效,但是对实时性、鲁棒性都没有进行优化和仿真,也尚未实现图片缩放时识别层次的自动切换,离实用化尚有一段距离。下一步,作者希望能沿袭这个分层语义的思路,使用视频进行实时性检测,并进行语义跨层时的切换平滑度研究,使整个程序在操作时更加流畅和人性化。

图6 中景语义标注

图7 远景语义标注
[1]Heitz G,Gould S,Saxena A,Koller D.Cascaded classiflcation models:combining models for holistic scene understanding[C]∕In:Proceedings of the Conference on Neural Information Processing Systems.Vancouver,Canada:NIPS,2008.1-8.
[2]蔡自兴,邹小兵.移动机器人环境认知理论与技术的研究[J].机器人,2004,26(1):87-91.
[3]Bay H,Ess A,Tuytelaars T,van Gool L.SURF:speeded up robust features[J].Computer Vision and Image Understanding,2008,110(3):346-359.
[4]Brostow G J,Fauqueur J,Cipolla R.Semantic object classes in video:a high-deflnition ground truth database[J].Pattern Recognition Letters,2009,30(2):88-97.
[5]李梦萦宋海玉王泽宇.场景理解在实时监视中的应用研究[J].中国高新技术企业,2016.2:45-46.
[6]Bosch A,Munoz X,Freixenet J.Segmentation and description of natural outdoor scenes[J].Image and Vision Computing,2007,25(5):727-740.
[7]Hadsell R,Sermanet P,Ben J,Erkan A,Sco-er M,Kavukcuoglu K.Learning long-range vision for autonomous off-road driving[J].Journal of Field Robotics,2009,26(2):120-144.
[8]庄严陈东王伟韩建达王越超.移动机器人基于视觉室外自然场景理解的研究与进展[J].自动化学报,2010.36(1):1-11.
[9]Socher R,Lin CC,Ng AY,eds.Parsing natural scenes and natural language with recurisve neural networks[C]∕∕The International Conference on Machine Learning,Bellevue,2011.
[10]Liu B,Fan HQ.Semantic labeling of indoor scenes from RGB-D images with discriminative learning[C]∕The international Conference on Machine Vision,London,2013.
[11]孙丽坤刘波.基于分层区域合并的自然场景理解[J]. 计算机系统应用,2014.23(11):116-121.
[12]庄严陈东等.移动机器人基于视觉室外自然场景理解的研究与进展[J].自动化学报,2010.36(1):1-11.
UAV Flight Scene Understanding Based on Improved Semantic Layering
REN Min
(Banshanyuan,Nanjing 210016)
With the widespread popularity of UAV,UAV scene understanding technology is more and more important.In this paper,BOO principle is used to establish semantic annotation model,and the tile-pyramid technology of map software is used and the training dataset and test dataset provided in event recognition field are combined,and a new semantic layering method is proposed.The experimental simulation proves that the proposed method can identify the corresponding objects in the scene of the UAV photographed at different heights.
scene understanding,texton map,semantic annotation,semantic layering,tile-pyramid
V279
10.3969∕j.issn.1672-9730.2017.10.019
Class Number V279
2017年4月7日,
2017年5月26日
任民,男,硕士,副教授,研究方向:海军兵种战术。
