基于用户隐性反馈行为的下一个购物篮推荐
2017-11-27李裕礞练绪宝林鸿飞
李裕礞,练绪宝,徐 博,王 健,林鸿飞
(大连理工大学 计算机科学与技术学院,辽宁 大连 116023)
基于用户隐性反馈行为的下一个购物篮推荐
李裕礞,练绪宝,徐 博,王 健,林鸿飞
(大连理工大学 计算机科学与技术学院,辽宁 大连 116023)
下一个购物篮推荐是当前电子商务领域中极其重要的一项任务,传统的下一个购物篮推荐方法主要分为时序推荐模型和总体推荐模型。这些方法对点击、收藏、加入购物车等用户的隐性反馈行为利用得不够,并且没有考虑用户行为偏好的时间敏感性。该文提出了一种基于用户隐性反馈行为的下一个购物篮推荐方法,将用户行为按照一定的时间窗口进行划分,对于每个窗口从多个维度抽取用户对商品的时序偏好特征,运用深度学习领域的卷积神经网络模型进行分类器训练。在真实数据集中的实验结果表明,与传统的线性模型和树模型等分类器相比,该文提出的卷积神经网络框架具有较强的特征萃取能力和泛化能力,提高了推荐系统的用户满意度。
下一个购物篮推荐;隐性反馈;时序行为;卷积神经网络
1 引言
电子商务伴随着互联网的普及得到了飞速的发展,将实体店的商品搬到虚拟的网络平台,一方面方便了用户,优化了购物体验;另一方面也方便了卖家推销自己的商品,降低了成本。然而,纷繁多样的商品却也增加了用户挑选商品的难度。电子商务平台中可以产生大量的用户隐性反馈行为数据,其中包含了丰富的用户偏好信息,从这些行为数据中预测出用户下一个购买的商品即下一个购物篮[1-4]具有极其重要的意义。
当前,大部分的推荐方法主要关注用户-商品的二元矩阵,并对它们的二元关系直接建模。其往往只能利用用户对商品有限的显性反馈数据,而隐性反馈行为及行为的时效性往往会被忽略。有研究表明用户的历史交易行为对用户的购买行为表现了较强的相关性。为了解决下一个购物篮推荐问题,主要有两种建模思路。第一种是基于马尔可夫链的时序推荐模型,即充分利用时序行为数据来根据用户的上一次购买行为预测下一次购买行为。这种模型的优势是能够通过时序行为产生好的推荐。第二种是总体推荐模型,即不考虑用户行为的时间敏感性(即时序特点),而是根据用户的整个消费历史记录来产生推荐结果。这种推荐方法可以捕获用户的总体偏好,这里面最具代表性的就是协同过滤推荐,协同过滤推荐主要分为基于记忆的协同过滤和基于模型的协同过滤(如矩阵分解等)。更好的方案是既考虑用户的时序行为,也能包含用户的总体偏好,相应地,Steffen Rendle等人提出了分解个性化马尔可夫链模型[5](factorizing personalized Markov chains, FPMC),它既能对用户的时序行为建模,也能捕获用户的总体偏好,实验结果表明和单独的时序模型和综合推荐模型相比它具有更好的推荐效果。
近年来,深度学习模型已经在计算机视觉、语言识别和自然语言处理等领域取得了突破性的进展。它通过模拟人类神经系统的网络结构,能够自动地从原始输入特征中学习出高级抽象特征,实验证明,和浅层模型相比,深层模型能更好地表达数据的特征[6]。卷积神经网络[7-8]是一种特殊的深度网络结构的深度学习模型,它的权值共享网络结构使之更类似于生物神经网络,降低了网络模型的复杂度,减少了权值的数量。其基本结构包括两层,其一为卷积层(convolutional layer),每个神经元的输入通过卷积核(也称为特征图,feature map)与前一层的局部接受域相连,并提取该局部特征;其二为池化层(pooling layer),网络中的每个神经元通过一个卷积核连接,从而提取出总体特征。卷积神经网络对于处理图像等二维特征具有较大的优势。
基于以上分析,本文提出了一种基于卷积神经网络的下一个购物篮推荐模型。以用户-商品对作为一个训练样本,将此问题看作二元分类问题,对用户在下一时刻是否购买该商品进行分类判断。为了捕获用户对商品的时序偏好特征,我们将用户对商品的行为按照一定长度的时间窗口进行划分,利用用户的隐性反馈行为从多个角度对窗口内用户对商品的偏好特征进行刻画。使用卷积神经网络在卷积层中按照时间窗口提取其局部特征,在池化层中提取其总体特征,以此训练卷积神经网络模型,从而充分利用用户对商品的时序偏好和总体偏好。最后,在预测阶段我们将测试集的样本特征输入模型,产生Top-K样本作为最终购买预测结果。
本文的主要贡献包括以下几点:
① 采用了时间窗口的机制充分刻画用户对商品的时序行为偏好特征,并且对每个窗口从多个角度对用户的隐性反馈行为特征进行建模。
② 提出了一种基于分类的推荐模型,和传统的时序推荐方法、协同过滤推荐方法不同,本文将用户在下一时刻对某一商品是否发生购买行为看作一个二元分类问题,增强了此问题的适用性。
③ 提出了一种基于卷积神经网络的下一个购物篮推荐算法,按照时间轴将用户行为特征转化成二维平面输入卷积神经网络中,充分利用卷积神经网络可通过卷积层提取局部特征及池化层提取总体特征的特性,充分发掘特征之间的内在联系,从而获得更好的特征表达,对模型进行训练。实验结果表明,这种机制有效地提高了推荐性能。
2 相关工作
电子商务平台中会产生大量的用户隐性反馈行为数据,这些行为数据中往往包含了时间序列,从这些隐性反馈行为数据中挖掘出有价值的模式来为用户提供个性化推荐,既可以帮助零售商更好地理解用户的消费需求,也可以降低用户挑选商品的难度。这种根据用户的历史行为预测用户在下一个时间序列发生购买的商品,又称为下一个购物篮推荐(next basket recommendation),其已经成为推荐系统领域一项极具挑战且具有重要意义的任务。
下一个购物篮推荐是基于隐性反馈数据推荐系统的一个典型应用,用户不表达显性的偏好,而只有正向的浏览记录。下一个购物篮推荐方法主要分为三种,分别是时序推荐模型(sequential recommender)、总体推荐模型(general recommender)和混合推荐模型(hybrid recommender)。时序推荐模型主要基于马尔可夫链,利用序列行为数据通过上一次行为预测下一次购买[9]。Zimdars等人[10]提出一种基于马尔可夫链的序列推荐模型,主要研究利用概率决策树模型抽取序列模式从而学习到下一个状态。2002年Mobasher等人[11]研究推荐中的不同序列模式,并且发现连续的序列模式相比总体序列模式更加适合序列推荐任务。2012年Chen等人[12]将歌手建模为马尔可夫链,提出了一种逻辑斯蒂马尔可夫嵌入(logistic Markov embedding)模型来学习歌曲的向量表达从而预测出其所属歌手。与序列推荐模型相比,总体推荐模型并不考虑用户的序列行为,而是基于用户的整个购买历史做出推荐,其核心思想是将用户购买行为转化成对商品的评分矩阵,再利用传统的协同过滤推荐算法生成推荐结果。时序推荐模型考虑了用户偏好的时间敏感性的特点,能够捕获到其时序偏好,总体推荐模型能够捕获到用户的总体偏好却忽略了时序偏好,一种更好的方案是将两者结合起来,混合推荐模型即是这样的一种方法。2010年Rendle等人[5]提出了一种分解个性化马尔可夫链模型(factorizing personalized Markov chain, FPMC),他们构建了一个交易立方体,立方体中的每个元素是用户在上一次交易中已经买了某商品时再买另一商品的概率值,通过分解这样一个立方体解释用户、上一次交易的商品、下一次购物篮商品三者之间的关系。由于分解过程中考虑了用户整个购买历史,FPMC模型可以综合考虑用户的时序偏好和总体偏好。2015年Wang等人提出了一种层次表达模型[13](hierarchical representation model, HRM),使用了一种深度网络结构训练用户和商品的特征向量表达,在预测时综合考虑了用户的交易记录中的所有商品和用户的偏好向量,能够捕获总体偏好和序列行为。这些方法虽然能够综合考虑用户的时序行为和总体偏好,但是他们对于多种不同类型隐性反馈行为的用户偏好建模、用户偏好的时间敏感性建模及发掘用户不同时序偏好的内在联系方面所做的工作不够,仍然有一定的局限性。
3 问题描述
对于在线商品购买预测的推荐场景,其中包含一系列用户U={U1,U2,…,Un}和一系列商品I={I1,I2,…,In},商品具有类别等属性。在电子商务平台中用户会有一系列隐性反馈行为,每一条行为记录可表示为{Ui,Ij,Ck,action_type,time},其中Ck表示商品类别k,action_type表示行为的类型,主要包括点击(click)、收藏(collect)、加入购物车(cart)、购买(buy)等,time表示发生该行为的时间。如图1所示,在线商品购买预测问题可表示为给定T时间之前的用户行为记录集合D,预测用户在T时间发生购买行为的商品集合。
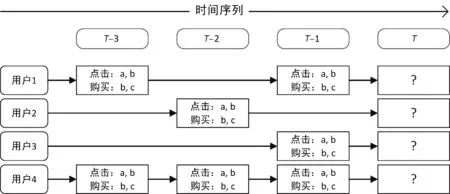
图1 基于隐性反馈行为的下一个购物篮推荐示意图
4 时序行为偏好特征构建
本文以阿里巴巴移动推荐算法竞赛公开的数据集为例,具体数据集描述详见6.1节,数据集中给定用户一个月的行为记录。为了更好地捕获用户的时序特征,本文将数据划分为时间窗口,并从多个维度对用户偏好特征进行刻画。
4.1 样本及特征体系构建
与传统的推荐方法不同,本文将在线商品购买的预测问题看作一个分类问题,将用户-商品对作为一个训练样本,本文的特征构建和模型训练均基于这样的样本数据。
如图2所示,选定三天为一个窗口,从12月14日至12月16日期间的用户行为数据中抽取样本并进行特征统计,以12月17日用户对该商品是否发生购买行为对样本进行标注,构建出训练集。在12月15日至12月17日期间用户的行为数据中抽取特征作为测试集,从而对12月18日进行在线商品购买进行预测。特别地,对于预测日期前三天没有发生购买行为的用户-商品对,我们选择直接忽略处理。
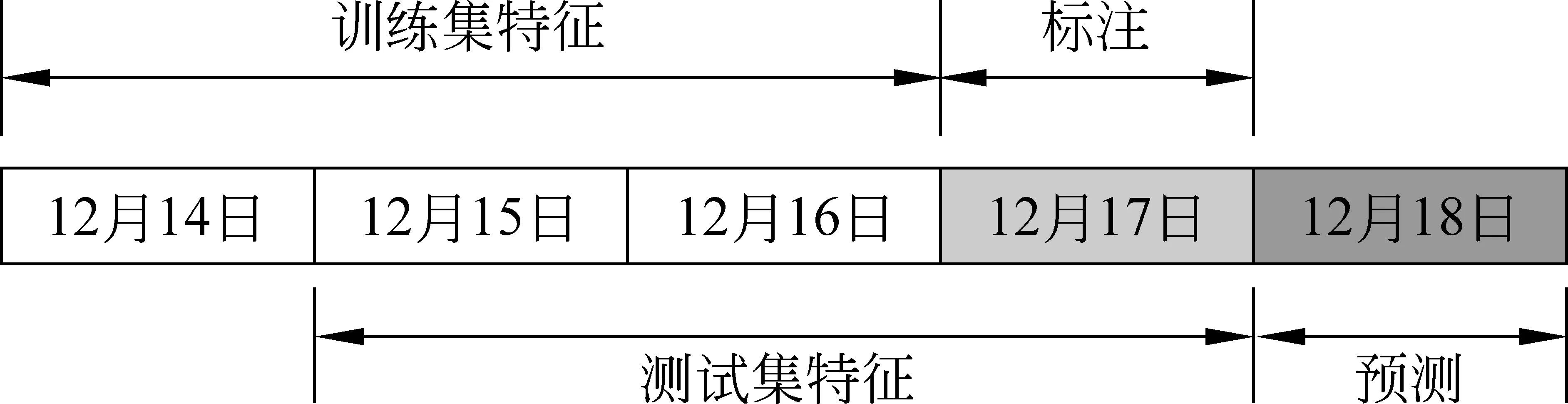
图2 数据集划分示意图
为了体现用户商品购买预测的时序特性和时间敏感特性,在三天的样本构建窗口内选择更加细粒度的特征统计时间窗口,以每八个小时作为一个特征统计窗口将数据划分为九个窗口。根据数据集中用户行为记录的特点,我们将特征分为五个群组,按照特征统计方法又将特征分为四种类型,如表1所示。

表1 特征体系示意表
4.2 计数特征
对于每个特征统计窗口,本文使用了行为计数特征及去重型计数特征。行为计数是以累计的方式统计在当前窗口及其之前发生各类行为的数量。如对于点击行为,分别表示用户对商品的点击数量、用户的总点击数量、商品的总点击数量等,其他行为以此类推。去重型计数特征与行为计数类似,但只统计不重复的各类行为数据的数量。
4.3 比值特征
用户对商品的行为占用户、商品或商品类别总行为的比例往往也是影响用户对该商品偏好程度的一个方面。例如用户对某商品的点击数与该用户的总点击数的比值等。在时间窗口t用户i对商品j的点击量占用户i总点击量的比值计算方法如式(1)所示。
其中分子部分表示用户i对商品j在窗口t的点击量,UI表示用户-商品特征群组中的行为统计;分母部分表示在窗口t用户i的总点击量,U表示用户特征群组中的行为统计。
4.4 转化率特征
由于消费者心理及行为习惯的差异,有的用户购买目的性较强,可能少量的浏览便能决定是否购买该商品;而有的用户会显得比较犹豫。从商品的角度来分析,有的商品往往需要较少的点击就能转化为一次购买,如消费类的电影票;而其他商品往往需要更多的浏览行为,如服装类。基于这些分析,本文提出转化率特征作为描述用户、商品及商品类别的一个方面。在时间窗口t用户i的购买转化率可表示为如式(2)所示。
其中分子部分表示用户i在时间窗口t的购买总量,分母部分表示为用户i在时间窗口t的点击总量。
4.5 均值特征
为了更好地刻画用户的活跃度、商品及商品类别的流行度,本文基于计数型特征衍生出一系列的均值型特征。以点击行为为例,在用户特征群组里包括用户对商品、用户对商品类别的平均点击次数;在商品特征群组中包括商品被点击的平均次数;在商品类别特征群组中包括该商品类别被所有用户的平均点击次数。用户i对商品的平均点击次数计算方法如式(3)所示。
其中分子部分表示在时间窗口t用户i的点击数,分母部分表示在时间窗口t用户i点击不同商品的数量。
5 基于卷积神经网络的下一个购物篮推荐
为了综合考虑用户对特定商品偏好的时序敏感性及用户的总体偏好,同时发掘用户在不同时间序列中商品偏好行为特征的内在联系,从而获得更好的特征表达,本文利用用户隐性反馈行为构建特征并采用卷积神经网络模型对用户的下一次购买行为进行预测。
5.1 模型框架

图3 卷积神经网络模型示意图
基于以上分析及构建好的用户时序行为偏好特征,我们采用了如图3所示结构的卷积神经网络模型。模型分为四层,分别为输入层、多窗口卷积层、池化层及输出层。其中输入层为构建好的输入特征,按照时间序列将输入特征转化为一个二维平面,每个时间窗口表达为一个特征向量;多窗口卷积层通过不同长度的时间窗口对输入特征平面进行卷积计算,得到不同的特征图(feature map);池化层对卷积层得到的不同特征图进行降维,得到一个池化后的特征向量;输出层与池化层是全连接的网络结构。
5.2 卷积层及池化层
假设一共有T个特征统计时间窗口,每个时间窗口有K个用户对商品的偏好行为特征,那么对于每个输入样本x可以表示为一个T×K的矩阵,即x∈RT×K。 卷积层中的特征图由输入层和卷积核通过卷积计算得到。假设卷积核的窗口长度为h,xi:i+j表示时间窗口i到时间窗口i+j进行拼接得到的特征向量,卷积核w可表示为一个h×K的向量,即w∈Rh×K,特征图可得到T-h+1个特征,即特征图f=[f1,f2,…,fT-h+1],其中第i个特征fi按照式(4)计算得到。
其中b是偏置项,是一个实数;σ(x)是非线性激活函数,本文采用ReLu作为激活函数,如式(5)所示。
本文采用最大值池化(Max-pooling)的方式对卷积层输出的特征图进行处理。池化层旨在对特征图进行缩放,同时降低网络的复杂度,通过最大值池化操作可以得到该卷积核的最主要特征。本文也采用了几种不同窗口长度的卷积核。假设在卷积层第k个卷积核得到的特征图为fk=[fk,1,fk,2,…,fk,T-h+1],池化操作可表示为式(6)所示。
5.3 模型训练

其中bk表示全连接层的第k个偏置项。通过最大化模型的似然概率值可得到模型的交叉熵损失函数,如式(8)所示。
其中T为训练数据集,yi为第i个样本的真实类别,xi为第i个样本的特征,θ为模型的参数。通过极小化该损失函数学习模型参数,训练方法本文采用了2012年Zeiler提出的改进的梯度下降方法Adadelta[14]。另外,为防止模型出现过拟合现象,我们对卷积层采取了Dropout[15]处理,即按照一定的概率随机将卷积层的神经元节点转为0,使其权重不工作。
6 实验结果与分析
本章详细介绍本文的实验过程采用的数据集、实验结果、实验对比分析,以及实验参数对实验结果的影响等。
6.1 数据集描述
本文的实验采用的是阿里巴巴集团在2015年举办的移动推荐算法竞赛公开的数据集,此数据集包含了一个月(2014年11月18日—2014年12月18日)的用户行为数据及商品信息。其中用户的行为数据包括10 000个用户对2 876 947个商品的各种行为,行为类型包括点击、收藏、加入购物车和购买,每一条行为记录标识了精确到小时的行为时间。商品信息包括商品类别信息,且标识出该商品是否为线上到线下类型的商品(online to offline, O2O),表2是数据集的一些基本统计信息。
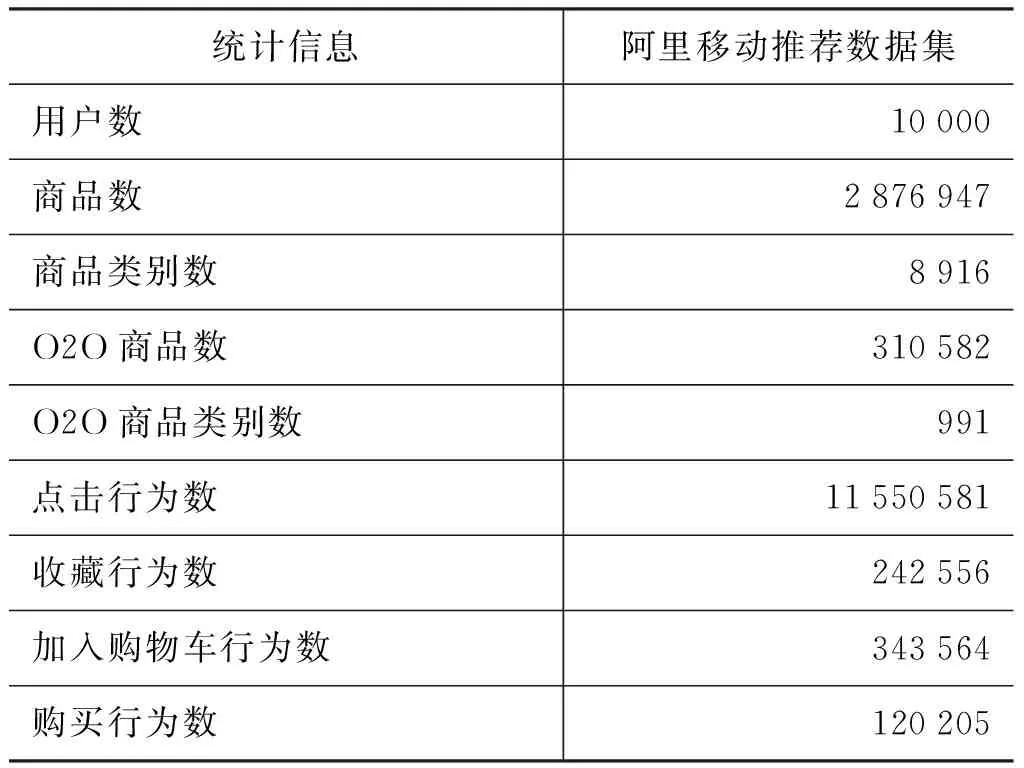
表2 数据集的基本统计信息
6.2 评价指标
本文提出方法的目的在于根据用户的历史行为记录预测用户在下一时刻购买的商品列表,因此我们将数据集中最后一天即2014年12月18日的数据作为测试集对模型进行评价,以该日期之前的行为数据作为训练集对模型进行训练,样本的构建方法如4.1节所示。我们采用F1-score作为模型的评价指标,F1-score可以看成是准确率(precision)和召回率(recall)的调和平均数,只有在两者都较高时才能有较高的得分,目前F1值已广泛用于推荐系统的评价中。
6.3 数据预处理与实验设置
由于本文中采用的数据集正负样本分布极其不平衡,比例约为1∶680,负样本中含有较多的噪声,为了让模型更适合不平衡数据下的学习[16],我们对负样本做了随机欠采样(under sampling)处理,有放回地选择5%负样本与正样本合并作为该标注日的训练数据集。为了丰富数据集,我们选择了多个标注日的数据合并作为最终训练集。按照第四节中所介绍的方法统计特征,将每个样本可以划分为共九个时间窗口。模型训练过程采用AdaDelta Update Rule进行随机梯度下降调整模型的参数。模型可调的超参数(hyper parameters)如表3所示,表中的值为在验证集误差最小时模型的超参数。

表3 卷积神经网络参数设置
6.4 实验结果与对比
为了验证卷积神经网络在捕获用户对商品时序偏好和挖掘用户时序行为特征之间内在联系的优势,我们在保证训练特征等条件相同的情况下对比了几种常用的分类模型。它们分别是线性逻辑回归分类模型[17](logistic regression, LR)、支持向量机模型[18](support vector machine, SVM)、随机森林模型[19](random forests, RF)和梯度提升回归树模型[20](gradient boosting decision tree, GBDT),另外还对比了将最近8小时加入购物车商品(latest cart)作为推荐结果。我们对预测结果进行了过滤,只选择O2O商品作为最终的预测结果,实验中使用了sklearn工具包。实验过程中各个模型的超参数设置分别为:
① LR,选择L2正则,正则化系数为0.1。
② SVM,选择径向基(radial basis function, RBF)核函数,核函数gamma为0.005。
③ RF,树的数量为200,选择熵作为特征切分标准,随机特征比例为0.5。
④ GBDT,树的数量为100,学习率为0.1,树的最大深度为3。
使用上述参数得到的实验结果如表4所示。从中可以看出,使用本文设计的特征的各机器学习模型效果均较大幅度地优于基于购物车规则的Latest Cart,说明本文对用户的时序行为偏好建模是合理的,对于提高推荐系统准确率有积极作用。在单一模型中,CNN模型效果最佳。使用简单投票的模型融合方法,将LR及GBDT前N个结果的交集,合并到CNN的输出中,可进一步提高模型结果。由此也说明本文方法与传统的LR及GBDT拥有不同的视角,由于线性模型假设各个特征是独立的,无法挖掘出特征之间的内在联系, 本文 提出的方法能更好地挖掘用户时序偏好特征之间的内在联系,并且能够充分地利用用户的隐性反馈行为。
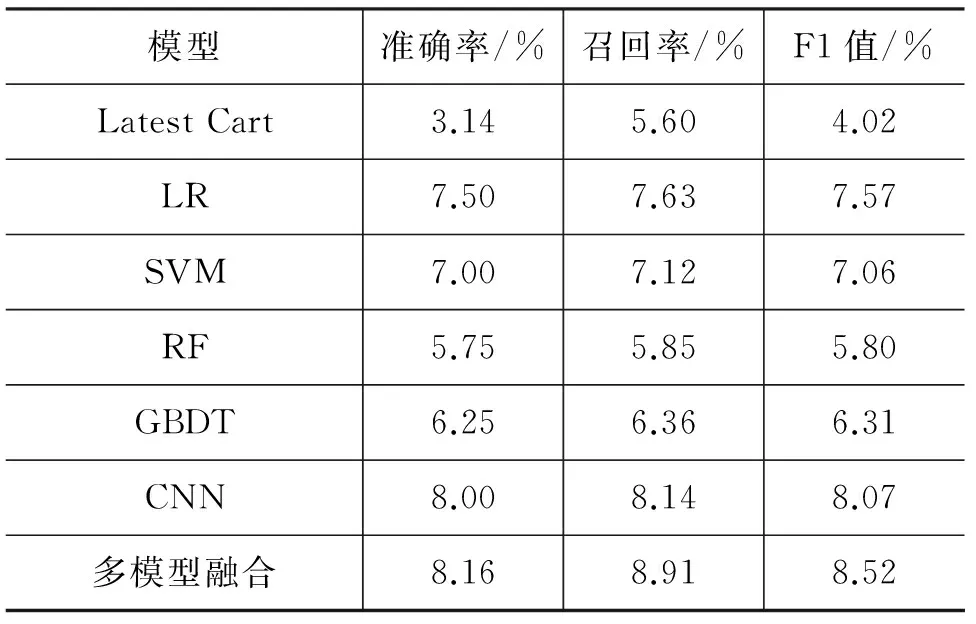
表4 各个模型的实验结果对比
本文中的任务要求预测出未来一天内用户购买的确切商品,不同于以往的推荐问题,该任务要求较为苛刻,用户是否购买一件商品受很多因素影响,预测难度较大,传统的推荐方法如协同过滤更偏向于预测用户感兴趣的商品,对购买行为的预测效果较差。此外,使用传统带时序信息的推荐方法如factorizing personalized Markov chains(FPMC)等,均只能预测出在未来一段时间内用户可能感兴趣的商品,而对于固定一天时间内的预测效果较差。本文任务来源于阿里移动推荐算法竞赛,在经过大量实验及对竞赛中各个队伍所选用的方法进行对比后发现,使用原始推荐方法协同过滤、FPMC等在该任务上所得到的准确率均无法超过2%,与本文中对比的分类方法相比均存在较大差距。由此也说明,对于未来固定时间内的购买行为预测问题,使用分类的方法能取得更好的效果。因此,本文着重比较了多个分类模型在该任务上的效果差异。
本文也对比了阿里推荐竞赛中的冠军队伍公布的其模型在12月18日数据集上评测的结果*https://tianchi.shuju.aliyun.com/mini/reply.htm,表5中展示了本文中的各个模型与冠军队伍对应模型的F1值的对比结果。从中可看出, 本文中的CNN模型及经过简单的模型融合后,模型结果的F1值优于对方对应模型的结果。由此也可在一定程度上说明本文构建的CNN网络结构及引入的用户隐性反馈行为的合理性。

表5 本文方法与竞赛队伍最优F1值对比
本文分析了双十二购物节对于模型预测结果的影响。如图4所示,在双十二当天,各模型预测结果的F1值均有大幅提升,其中CNN模型当天的F1值达到15.44%,经过模型融合后结果进一步提升到16.21%。而在11日及13日模型预测结果则有明显的下降。分析原因在于,在双十二购物节前后几天里,人们的购物行为与平常相比出现了较大差异,人们将通常分散在几天购买的东西,集中在购物节当天购买。使得在用户有限的潜在购买商品集合中,在当天产生更多购买行为,从而使得模型对购买行为的预测效果有所提升。从图4中也可看出,在CNN模型的基础上进行简单投票方式的模型融合,便可在大多数时间中得到更优的效果,说明本文中的CNN模型与其他对比模型在数据处理上较为不同,能够更好地萃取出不易被其他模型感知到的用户隐性反馈行为。
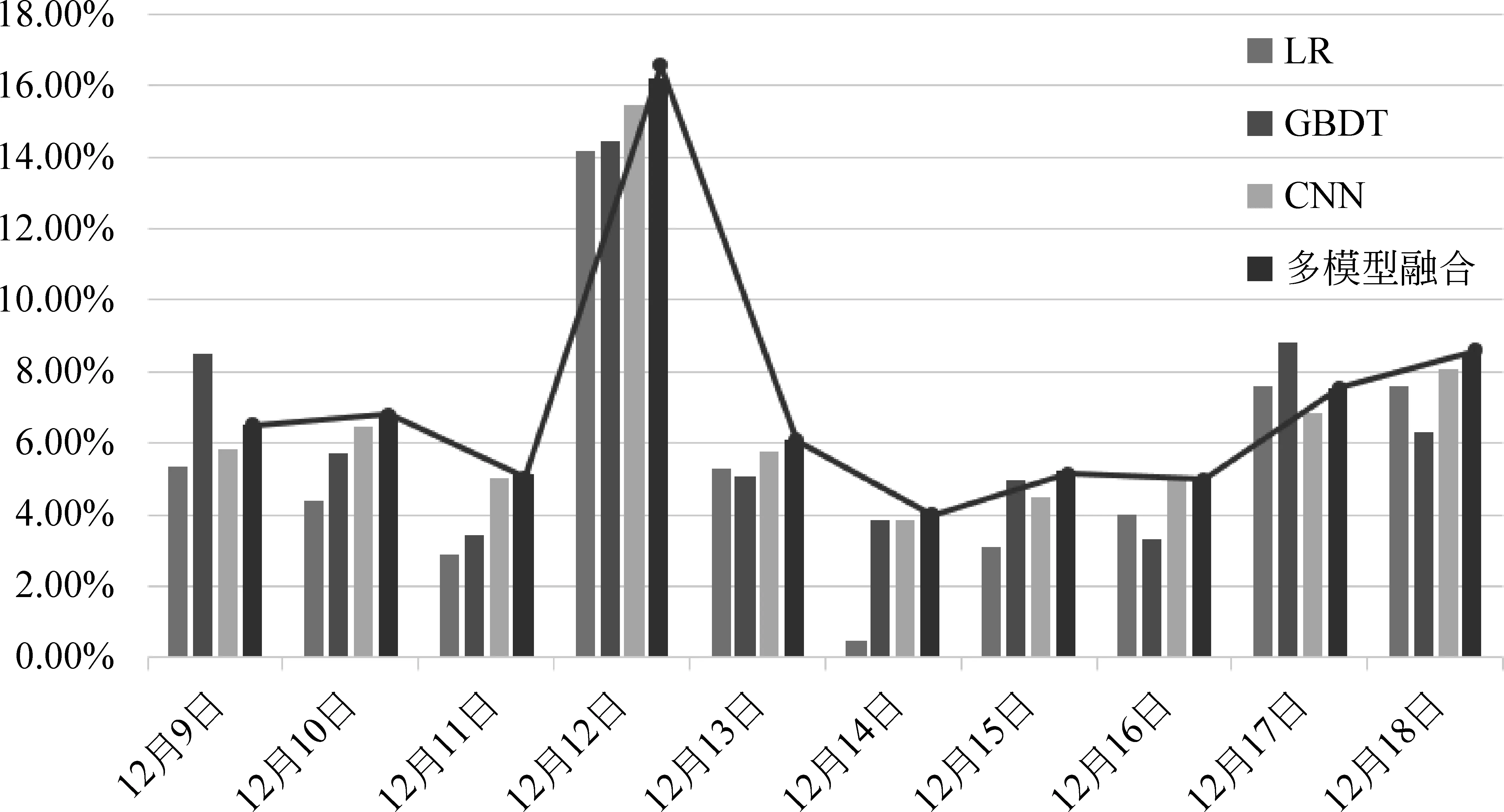
图4 各模型预测结果的F1值与日期的关系
7 总结与展望
针对用户的隐性反馈行为,本文提出了一种基于卷积神经网络的下一个购物篮推荐算法。本文选取电子商务领域中的下一个购物篮推荐作为研究目标, 介绍了所研究问题,并详细介绍了本文所采用的方法。首先将用户行为按照一定的时间窗口进行划分,对于每个窗口,从多个维度抽取用户对商品的时序偏好特征。运用深度学习领域的卷积神经网络模型,由模型中的卷积层组合不同长度的特征图来训练分类器。最后介绍了本文的实验过程,在真实数据集上取得了较好的预测效果,实验结果也表明本文方法与其他线性或树形模型具有不同的特征抽取视角,有更强的特征萃取能力及泛化能力,同时经简单投票的模型融合后能产生更好的效果,有助于提高推荐系统的准确性及用户满意度。
另外我们也发现,在当前的下一个购物篮推荐中也存在一些可以改进的方面,比如在商品显性反馈行为建模中引入更多的外部信息,如用户对商品评论信息,融入文本挖掘特征及评论的情感信息等。在建模方面可以对用户进行用户画像,从而更细致地考虑不同类型用户的偏好特点。另一方面,对商品也进行更加细致的刻画,如考虑其位置信息等。
[1] Ricci F, Rokach L, Shapira B. Introduction to recommender systems handbook[M]. Springer US, 2011: 147-184.
[2] Gatzioura A, Sanchezmarre M. A case-based recommendation approach for market basket data[J]. Intelligent Systems IEEE, 2015, 30(1):20-27.
[3] Lee J S, Jun C H, Lee J, et al. Classification-based collaborative filtering using market basket data[J]. Expert Systems with Applications, 2005, 29(3):700-704.
[4] Wang P, Guo J, Lan Y. Modeling retail transaction data for personalized shopping recommendation[C]//Proceedings of ACM International Conference on Conference on Information and Knowledge Management. ACM, 2014:1979-1982.
[5] Rendle S, Freudenthaler C, Schmidt-Thieme L. Factorizing personalized Markov chains for next-basket recommendation[C]//Proccedings of International Conference on World Wide Web, WWW 2010, Raleigh, North Carolina, USA, 2010:811-820.
[6] Bengio Y. Learning deep architectures for AI[J]. Foundations amp; Trends©in Machine Learning, 2009, 2(1):1-127.
[7] Kalchbrenner N, Grefenstette E, Blunsom P. A convolutional neural network for modelling sentences[J]. arXiv preprint Arxiv, 1404.2188,2014.
[8] 练绪宝. 基于排序学习和卷积神经网络的推荐算法研究[D].大连理工大学硕士学位论文, 2016.
[9] Chand C, Thakkar A, Ganatra A. Sequential pattern mining: survey and current research challenges[J]. International Journal of Soft Computing amp; Engineering, 2012, 2(1):185-193.[10] Zimdars A, Chickering D M, Meek C. Using temporal data for making recommendations[C]//Proceedings of the 17th conference on Uncertainty in artificial intelligence. Morgan Kaufmann Publishers Inc., 2001: 580-588.
[11] Mobasher B, Dai H, Luo T, et al. Using sequential and non-sequential patterns in predictive web usage mining tasks[C]//Proceedings of the 2002 IEEE International Conference on Data Mining. IEEE, 2002:669-672.
[12] Chen S, Moore J L, Turnbull D, et al. Playlist prediction via metric embedding[C]//Proceedings of the 18th ACM Knowledge Discovery and Data Mining. 2012:714-722.
[13] Wang P, Guo J, Lan Y, et al. Learning hierarchical representation model for nextbasket recommendation[C]//Proccedings of International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 2015:403-412.
[14] Zeiler M D. ADADELTA: An adaptive learning rate method[J]. Computer Science, 2012.
[15] Hinton G E, Srivastava N, Krizhevsky A, et al. Improving neural networks by preventing co-adaptation of feature detectors[J]. Computer Science, 2012, 3(4): 212-223.
[16] He H, Garcia E. Learning from imbalanced data[J]. IEEE Transactions on Knowledge amp; Data Engineering, 2008, 21(9):1263-1284.
[17] Dierckx G. Logistic regression model[J]. Encyclopedia of Actuarial Science, 2009, 39(2):261-291.
[18] Hearst M A, Dumais S T, Osman E, et al. Support vector machines[J]. IEEE Intelligent Systems, 1998, 13(4):18-28.
[19] Breiman L. Random forests[J]. Machine Learning, 2001, 45(1): 5-32.
[20] Friedman J H. Greedy function approximation: a gradient boosting machine[J]. Annals of Statistics, 2000, 29(5):1189-1232.

李裕礞(1992—),硕士研究生,主要研究领域为推荐系统,用户画像挖掘,深度学习与文本情感分析等。
E-mail: lym199286@mail.dlut.edu.cn

练绪宝(1993—),硕士,主要研究领域为推荐系统,机器学习等。
E-mail: lianxubao93176@163.com

徐博(1988—),博士研究生,主要研究领域为搜索引擎,机器学习,排序学习等。
E-mail: xubo2011@mail.dlut.edu.cn
NextBasketRecommendationBasedonImplicitUserFeedback
LI Yumeng, LIAN Xubao, XU Bo, WANG Jian, LIN Hongfei
(School of Computer Science and Technology, Dalian University of Technology, Dalian, Liaoning 116023, China)
“Next Basket” recommendation is a crucial task in E-commerce field. Traditional algorithms can be divided into sequential recommender and general recommender, both of which neglect the impact of implicit feedback behavior and time sensitivity of user’s preferences. This paper proposes a “next basket” recommendation framework based on implicit user feedback. We divide the user behaviors into several time windows according to the timestamp of these behaviors, and model the user preference in different dimensions for each window. Then we utilize the convolutional neural network to train a classifier. Compared to traditional linear models and tree models on a real dataset, the proposed model improves the user satisfaction with the recommender system.
next basket recommendation; implicit feedback; sequential behavior; convolution neural network
1003-0077(2017)05-0215-08
TP391
A
2016-08-26定稿日期2017-03-29
国家自然科学基金(61572102,61632011, 61562080);国家重点研发计划(2016YFB1001103)
