任意网页的主题信息抽取研究
2017-11-27张儒清俞晓明程学旗
张儒清,郭 岩,刘 悦,俞晓明,程学旗
(1. 中国科学院计算技术研究所 中国科学院网络数据科学与技术重点实验室, 北京 100190;2. 中国科学院大学,北京 100190)
任意网页的主题信息抽取研究
张儒清1,2,郭 岩1,刘 悦1,俞晓明1,程学旗1
(1. 中国科学院计算技术研究所 中国科学院网络数据科学与技术重点实验室, 北京 100190;2. 中国科学院大学,北京 100190)
目前大部分的网页信息抽取方法都局限于某一类网页的提取,并没有进一步深入到适用于任意网页的抽取。针对这一问题,该文提出了一种基于融合机制的任意网页主题信息抽取框架,特点是通过“模板库匹配—基于模板抽取—网页分类—全自动抽取”四个步骤实现对模板无关的全自动抽取算法和基于模板的抽取算法的融合。实验显示,这种融合机制能促进抽取准确率的有效提高,从而最终建立起一个适用于任意网页的、具有实用价值的信息抽取框架。
任意网页;主题信息;网页分类;实用价值
1 引言
随着互联网技术的不断发展,网页的主题信息逐渐成为信息检索(information retrieval)、数据挖掘(data mining)和机器翻译(machine translation)等互联网应用的基础数据,从网页中抽取出高质量的主题信息对于这些应用来说非常关键。例如,对于信息检索,主题信息抽取结果的质量会直接影响检索的准确率。网页主题信息是指与网页主题相关的内容,包括正文、作者、来源、标题、发布时间等。其他与主题无关的内容叫作噪声内容块,如广告链接、导航条、版权信息、装饰信息等。网页信息抽取的目标就是,去除网页中的干扰信息,保留和页面主题相关的有效信息。从某种角度上讲,主题信息的抽取质量直接决定了网络应用服务的效果。因此,网页信息抽取一直是近年来研究的热点。
现有的网页信息抽取方法都普遍针对某一类的常规页面,还没有一个方法能够通用于所有类型的网页。在工程实践中,处理的是类型多样、包含大量噪声、结构复杂且多变的海量网页数据。例如,元搜索引擎,其将用户的检索提问同时提交给多个独立的搜索引擎,并对检索结果去重、排序。在这种应用场景下,每天处理的都是上百万级别的大规模数据,传统的局限于某一类网页的抽取方法根本无法满足实际需求。面对互联网上网页规模的膨胀和信息来源的增加,如何准确、快速地定位并抽取出网页的主题信息,是一项具有重要意义却充满挑战的工作。
目前在这个领域已经有很多关于网页信息抽取的研究成果,主流方法主要分为基于模板的抽取方法和模板无关的全自动抽取方法。基于模板的信息抽取方法强依赖于HTML内部结构特征,因为同一类数据源的HTML结构特征都是类似的。网页模板是指属于相同网站的网页共同包含的一些稳定的装饰结构和功能结构。大多数传统的基于模板的方法都利用模板的这个特点,依据某一类网页中稳定的部分生成该类网页的公共模板,用来抽取结构相近的网页中的信息。其优点是当模板质量高且网页结构足够相似时,抽取准确率较高,且抽取速度较快。如果待提取信息的网页规模较大且来自很多类数据源,就会导致模板制作工作量的增大及维护代价的提高。当某一类页面的结构发生变化时,原有的模板就有失效的风险,无法适应网页结构的变化。模板无关的全自动信息抽取方法通常利用一些经验规则处理特定领域或特定格式的网页,极大地提高了信息抽取的自动化程度。常见的方式有基于文本密度、链接文本密度及视觉信息等方式。这种无关模板的方法特别适用于存在大量异构数据源的网络应用中,使得大规模、多数据源的信息抽取成为可能。但该类方法通常基于过强的假设,当处理不符合相应算法假设的页面时,会导致抽取精度不佳、效率较低的情况。针对目前面对的挑战,即大规模真实数据的处理,已有的方法根本无法满足实际需求。
针对已有方法的缺陷,以及面对的挑战,本文在相关研究的基础上,将模板无关的全自动抽取方法和基于模板的抽取方法巧妙地融合起来,提出了一个适用于任意网页的主题信息抽取框架。当今互联网中页面种类繁多(网站首页、版块页面、列表页、专题页、内容页等),解决所有网页的主题信息抽取问题具有很强的挑战性,我们希望能着重解决对后续应用有价值的常规网页的主题信息抽取问题。本文主要关注内容页,即内容所在的最终页面。内容页通常分为单记录页面和多记录页面两类。图1上半部分为单记录页面,通常指新闻、博客等包含一条正文记录的网页;图1下半部分为多记录网页,通常指包含跟帖的论坛帖子、 新 闻评论等包含多条正文的

图1 两类内容页面

图1 两类内容页面(续)
网页。对于这些页面,我们采用相应的算法进行抽取。对于非内容页面(版块页、网站首页等),通常是由大量锚文本组成的内容页面索引页,由于包含的主题信息较少,我们视为其他类,使用较为简单的抽取方法。
本文的主要贡献主要有以下四点。
首先,提出了一个针对任意网页的多元主题信息的抽取框架。该框架可处理任意网页,不限网页类型,很好地融合了模板无关的全自动信息抽取方法和基于模板的信息抽取方法,使得两类算法能够相辅相成。实验结果表明,该框架在结果准确率方面有很大的提升。
其次,针对没有通用于所有类型网页的抽取方法的问题,我们提出了先分类后处理的策略。具体做法是: 按照网页的综合特征对网页进行分类,通过不同的全自动方法来提取网页中的主题信息。实验表明,这种策略能明显提高信息抽取准确率,扩大抽取范围。
然后,该框架具有很好的扩展性,其中一些关键环节可根据实际需求进行替换。
最后,实际应用中处理的是海量在线网页,结构复杂多变,噪声信息众多。该架构为了解决实际问题而生,具有很强的实用性和应用前景。
2 相关工作
我们的目标是抽取出任意网页中包含的有价值文本信息,为之后的数据分析提供优质的基础数据。目前,基于模板的信息抽取方法和模板无关的全自动信息抽取方法以其特有的优势占据了主流位置。
基于模板的信息抽取方法设定同类网页有着相似的结构特征。文献[1]对该方法进行了全面的概述。经典方法有文献[2]提出的包装器归纳方法Softmealy,文献[3]提出的无监督方法RoadRunner,文献[4]提出的有监督方法STALKER,文献[5]提出的半监督学习方法OLERA。基于模板的网页信息抽取方法在模板的生成和维护上都是费时费力的,人工难以满足实际需求。
模板无关的全自动信息抽取方法仅根据网页自身相关特征进行抽取,不依赖于模板,极大提高了信息抽取的自动化程度。文献[6]采用基于网页正文文本密度最大的假设,但对于正文所在区间内出现比正文更长的噪声的网页,该方法会导致正文抽取错误。文献[7]通过计算链接文本比确定正文所在区域,但版权信息噪声一般不包含超链接,因此无法准确判断正文位置。文献[8]利用网页的视觉化特征将页面划分成视觉块,提取网页正中间且比较突出的信息作为主题内容,但开销大,无法满足实际需求。
目前研究的网页信息集中在某一类单记录页面,且较少看到对除正文以外其他主题信息的研究。本文通过“模板库匹配—基于模板抽取—网页分类—全自动抽取”四个步骤实现对模板无关的全自动抽取方法和基于模板的抽取方法的融合。
3 对任意网页的信息抽取框架
本文框架的思路是先将无法使用基于模板的抽取方法抽取的网页与抽取成功的网页区分开来,对抽取失败的网页进行分类,再针对不同类别分别进行抽取。其中,对于其他类网页,即非内容页面,我们采用较为简单的抽取算法。在实际应用中,网页种类繁多,结构复杂,单一的抽取方法根本无法满足需求,因此该框架对解决实际问题有很大的应用价值,并基本能覆盖所有的常规页面。
本框架先用速度较快、抽取信息较准确、但抽取范围较窄的基于模板的抽取方法对网页进行信息抽取。若模板匹配失败,则对网页进行分类,使用全自动抽取方法抽取信息,整体流程如图2所示。

图2 任意网页的主题信息抽取架构图
具体抽取步骤如下:
① 读入待抽取信息的网页HTML文件。
② 通过网页URL匹配过滤可以解析的网页,从数据库中取出对应模板,采用基于模板的抽取方法将可解析的网页进行网页结构化处理,并抽取主题信息。
③ 验证基于模板的抽取信息是否正确,成功,转向第⑥步,失败,转向第④步。
④ 对网页进行分类,即单记录网页、多记录网页和其他。其中单记录网页具体指新闻、博客,多记录网页具体指论坛。
⑤ 若为单记录网页,则采用单记录网页全自动抽取算法抽取;若为多记录网页,首先判断识别其是否为开源软件生成。若识别成功,则采用基于模板的抽取方法;若失败,则采用多记录网页全自动抽取算法;若为“其他”,则采用其他类网页的全自动抽取算法。
⑥ 获取抽取结果,保存信息。
4 关键技术
我们将详细论述本文提出的框架包含的关键技术。
4.1 基于Trie树的URL匹配
基于模板的信息抽取方法是网页信息抽取中的传统方法。我们采用人工方式,分版块制作模板,并使用文献[3]的方法对匹配成功的网页进行抽取。
我们逐个使用数据库中的模板对网页进行匹配,会消耗大量的时间,并且若模板匹配失败会导致抽取结果的失败。因此,如果能直接使用网页所在版块的模板,势必会对系统的运行效率和准确率有很客观地改善。
同一版块的网页URL具有较高的相似性,不同版块的网页URL具有较高的差异性,因此可以根据网页的URL识别网页的所属版块。本文使用数据库中的所有版块URL建立Trie树来进行网页URL的过滤分析。Trie树,即字典树,是一种树形结构,是一种哈希树的变种。它的优点是最大限度地减少无谓的字符串比较,查询效率比哈希表高。本文正是利用Trie树的优点对网页所属版块进行筛选。
Trie树的前缀匹配是找出一个字符串集合中以相同子字符串开头的字符串。我们先对数据库中的所有版块URL去除开头的“http://”,然后以“/”拆分URL生成多个子字符串,最后用所有的子字符串构造Trie树。当输入一个网页URL时,若能搜索到任一叶子节点且建树时该路径只访问一次,则认为查询成功,否则查询失败。
4.2 网页分类
在众多网络舆情载体中,新闻、博客和论坛是三种最强大的网络舆论载体。本文将网页分为新闻、博客、论坛及其他四大类。现有的网页信息抽取方法种类繁多,各有所长,但还没有一个算法能够通用于所有类型的网页。因此,分而治之地对网页进行信息抽取,能提高抽取准确率和效率。
根据不同类型网页的文本特征、结构特征及超链接特征等,我们构建了面向内容页面类型识别的特征集,进行特征选择后,应用SVM[9]对数据集进行训练。但若仅采用上述学习的方法,训练集的质量会直接影响最后模型的预测表现,除了很难得到大量训练集外,还很难得到优秀的训练集。然而实际需求更加倾向于准确率,所以通过较严格的规则挑选出高质量的网页,不仅能更加准确地对网页进行分类,同时时间开销较小。针对两种方法的优缺点,本文提出了以规则分类算法为主、机器学习分类方法为辅的基于网页综合特征的分类算法,其框架如图3所示。

图3 网页类型判断算法框架
基于网页综合特征的分类算法分为三大步骤:
① 基于SVM分类器的网页分类算法: 根据训练数据中网页HTML源码或DOM树属性,得到预先定义的特征,包含文本特征、结构特征、超链接特征及标签特征,对这些特征进行训练,生成分类器。其中,文本特征为每个预先设定的文本特征词的频率;结构特征为DOM树中h1、h2、h3节点出现的频率,以及head子数中的title和meta节点中出现预先设定的特征词出现的频率;超链接特征为所有链接里出现预先设定的特征词的频率;标签特征为每个tag节点数量占总tag节点数量的比率。新进入一个目标网页时,重复特征提取,使用分类器对网页分类。
② 基于严格规则的网页分类方法。首先通过严格的关键词识别网页类型,比如由Discuz!生成的论坛页面中,帖子页面中都含有lt;divgt;或者lt;tdgt;标签,包含属性id=“postmessage_”。如果页面中含有这个字符串,则可以被判定为是论坛的帖子页面。然后对网页是否是内容页面进行判断,网页中的噪声多是成块的链接,移除网页中成块的链接,然后计算剩余部分的正文长度等,超过一定阈值,则判定为正文页面,而非垃圾页面。然后对于正文页面,确定是否能够通过网页URL判断类型,即积累一个库,判断网页URL所属板块域名是否在这个库里。对于不在库中的页面,确定是否能够通过meta标签信息来确定网页类型,大多数的网页都会在lt;metagt;标签的keywords、description 等属性中写明网站基本信息。
③ 两种网页分类方法的结合。由于我们面向的是实际业务需求,对准确率和效率有严格的限制,因此我们采用以规则分类算法为主、机器学习分类方法为辅的基于网页综合特征的分类算法。我们先使用基于严格规则的网页分类方法,若划分为新闻、博客或论坛中的一类,则分类成功;若划分为“其他”,我们使用基于SVM分类器的网页分类算法进行网页分类,若分类为新闻、博客或论坛中的一类,则分类成功,否则输出类别为其他。
4.3 全自动抽取方法
本框架先用抽取较为准确但抽取域较窄的基于模板的方法对网页进行信息抽取,若数据库中无匹配的网页模板或者抽取结果验证失败,再使用不同类别下的全自动抽取方法抽取网页信息。
4.3.1 单记录网页抽取方法
针对单记录网页,即新闻、博客,我们的抽取目标是网页中的正文和主要的元信息(标题、发布时间、作者、来源、正文中的图片和链接)。我们基于文献[6]中的模型,采用标签密度直接定位正文,并采用标记方法操作DOM树抽取网页的来源、作者、时间、标题、正文图片及超链接。观察单记录网页,我们会发现有短正文和长正文网页两类。对于长正文网页,采用传统的抽取方式(基于文本密度和)进行处理;对于短正文网页,我们使用最大文本密度的节点代替最大文本密度的节点,即以该节点为根的子树上面的文本即为正文。这样能提高整体的抽取效果,在一定程度解决传统方法不适用短正文的问题。单记录网页的抽取算法描述如下:

ALGORITHM单记录网页抽取算法
INPUT:
某个单记录网页HTML源文件
OUTPUT:
网页的正文和主题信息
BEGIN:
1 读入文件,清理换行符和首尾的空格,编码转换为UTF8,建立DOM树,标记form标签为非正文节点,并为每个节点设置密度权值
2 遍历DOM树,提取lt;titlegt;标签里的文本作为候选标题,并将遍历得到的含有换行标签,比如lt;td class="title"gt;里的文本与候选标题进行对比计算相似度,最相似的认为是页面标题。清除标题之前的全部内容
3 截取标题后的一个换行标签,比如lt;tdgt;lt;/tdgt;,作为副标题。查找副标题中是否有字符串在网站来源词典中,若有,则作为来源,否则,用来源关键词和正则定位来源,若依然失败,则在全文查找符合来源匹配串的字符串
4 依然在副标题中查找带有”作者”这类特征或者包含姓氏字的字符串,若找不到,则在全文查找”作者”这类特征
5 在副标题中使用时间正则找出时间,清理副标题
6 根据配置文件中的关键字标记网页中的噪声,表示标签已被排除正文考虑范围
7 计算文本数和标签数,计算各个节点及孩子节点的标签密度
8 在一定范围内寻找标签密度和最大的作为正文统领节点,并将统领节点的祖先节点中最小的密度值作为阈值
9 标记正文节点,通过阈值取出一些疑似广告链接
10 获取正文节点的文本,组成正文
11 从正文开始节点遍历DOM树,抽取lt;imggt;标签中的src属性作为正文中的图片,lt;agt;标签中的href属性作为正文中的超链接
END
4.3.2 多记录网页抽取方法
针对多记录网页,即论坛类的内容页,我们主要关注帖子中每层楼的发帖人、发帖时间及发帖内容。在对论坛使用全自动抽取方法之前,我们先判断论坛内容页是否由开源论坛软件生成。互联网上开源软件生成的网页占所有论坛网页的比例高达70%,并且开源软件生成的论坛网页在结构上相对稳定。由此可见,在使用全自动信息抽取方法之前,对论坛内容页进行一定的预判断和处理能提高论坛抽取准确率。
开源网页论坛的识别和抽取我们采用文献[10]的方法,其基于数据记录特征的聚类算法,将大规模开源软件生成的论坛网页进行有效地自动划分,形成可标注类别,对每个聚类中的中心页面配置模板。最后,针对新网页,使用与其结构最相似的模板进行基于模板的信息抽取。
多记录网页的全自动抽取,大多借助网页之间结构的相似性,即网页内部不同块之间的重复度来找到各条记录所在的节点。而在实际数据中,有相当一部分论坛类内容页面只包含一楼内容,这使得基于结构相似性的算法所依赖的假设失效,因此我们需要将单楼层的页面区分出来。本文使用文献[11]的方法进行抽取。单楼和多楼论坛页面分类算法流程如图4所示,单楼层论坛页面和多楼层论坛页面的全自动抽取方法分别如图5、图6所示。
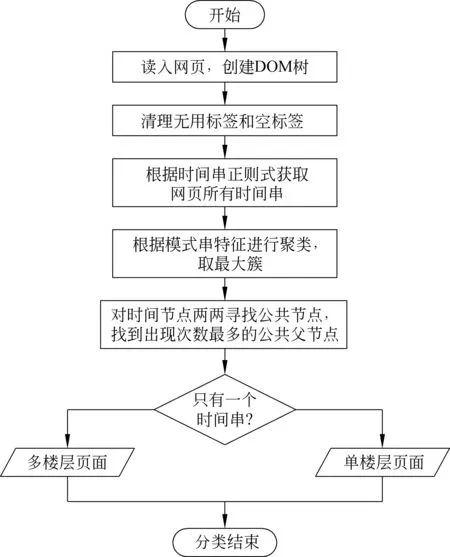
图4 单楼、多楼论坛页面分类方法
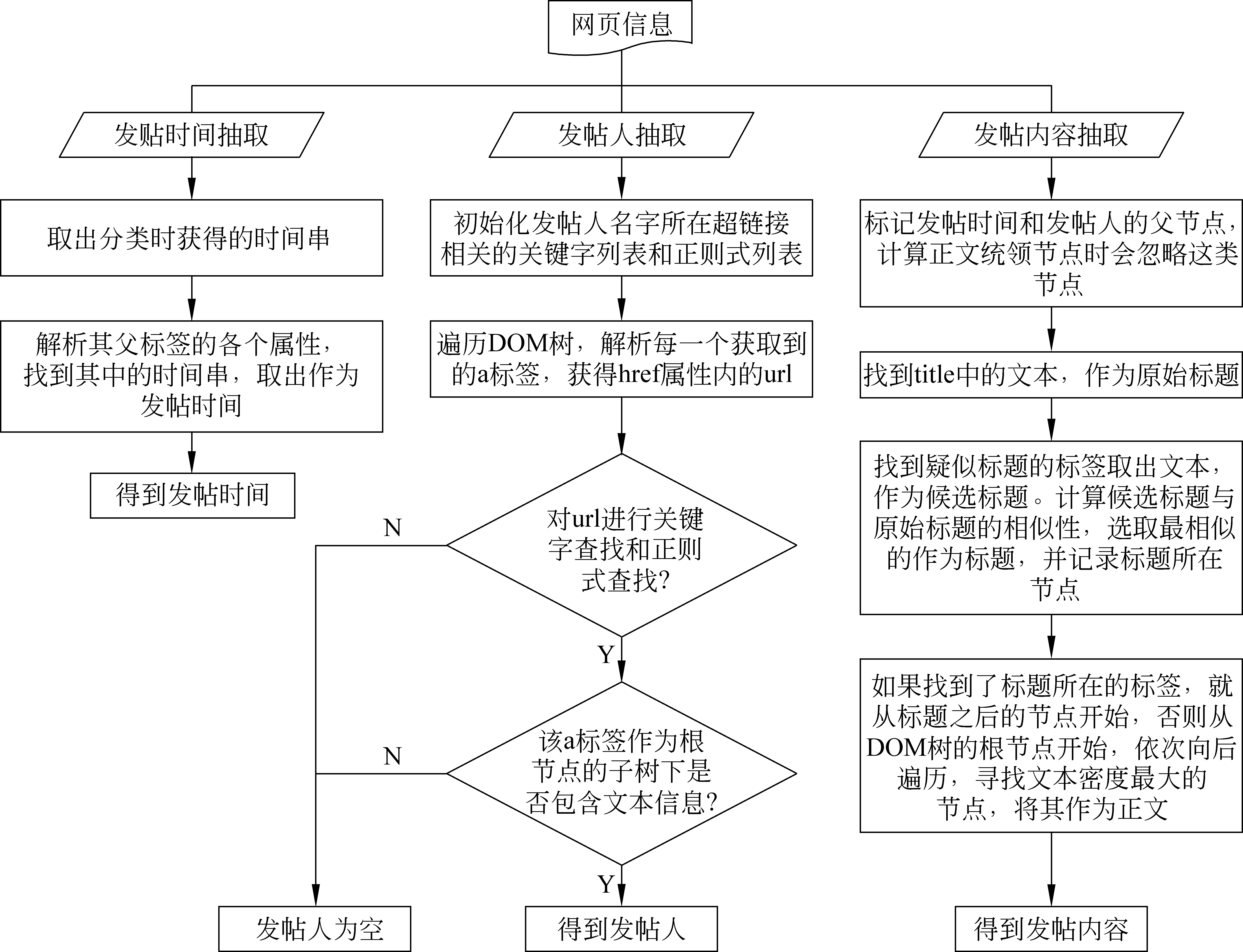
图5 单楼层论坛页面全自动抽取方法
4.3.3 其他类网页抽取方法
对本文定义的其他类网页,由于该类网页中含有大量的噪音,所以我们采用较简单的方法进行主题信息的抽取。对于标题,我们直接提取lt;titlegt;标签内的文本作为标题;对于时间,我们直接从根节点遍历DOM树,使用时间正则串匹配时间信息,选取第一个匹配成功的时间串作为发布时间;对于正文内容,计算各个节点以及孩子节点的标签密度,寻找标签密度和最大的作为正文统领节点,并将统领节点下的所有子节点包含的文本拼接成正文内容;对于正文中的图片和超链接,和单记录网页抽取方法一样。
5 实验
5.1 实验数据
实验数据来自元搜索引擎返回的20 000个网页。元搜索引擎是指将多个单一搜索引擎集成在一起,将用户的检索提问同时提交给多个独立的搜索引擎,获取检索结果。元搜索网页具有主题相关性高、质量优良及来源广泛等特点。本文所使用的搜索引擎包括百度、谷歌、奇虎360、必应和搜狗,以及新浪、腾讯、搜狐、网易、凤凰这些站内搜索引擎。我们根据多个单一搜索引擎实时的热点关键词拼接url,向元搜索引擎中发送请求,获得结果页面。这20 000个网页来源广泛,基本覆盖了各大主流网站,且网页结构方面也几乎覆盖了各种情况,因此保证了实验数据的多样性和异构性。
5.2 实验变量
现有的网页信息抽取方法普遍针对某一类或预定义范围的常规页面,并不通用于所有类型的网页。而本文的研究对象为任意网页,根据对已有研究的分析,并未找到可以和本文方法作直接对比的已有算法。但是为了更直观且客观地体现该框架的有效性和通用性,我们使用该框架的多个变形进行实验:
① 仅使用单记录网页的全自动抽取方法: 所有的20 000个网页全部视为单记录网页。
② 仅使用多记录网页的全自动抽取方法: 所有的20 000个网页全部视为多记录网页。
③ 仅使用其他类网页的全自动抽取方法: 所有的20 000个网页全部视为其他类网页。
④ 使用网页分类器对网页分类(新闻、博客、论坛和其他),对新闻和博客使用单记录网页的全自动抽取方法,对论坛采用多记录网页的全自动抽取方法,对其他类网页采用其他类网页的全自动抽取方法。
⑤ 基于上一个实验设置,对论坛进行开源软件生成识别,若识别为开源生成的论坛,则采用基于模板的信息抽取方法,并对抽取结果进行验证,得到论坛抽取结果;若验证失败,则采用多记录网页的全自动抽取方法。
⑥ 基于上一个实验设置,在对网页进行分类前,先进行网页URL的匹配,若匹配成功,则从数据库中取出其所属版块的模板,运行基于模板的信息抽取方法,并进行结果验证。若匹配未成功或结果验证失败,则进入上一个实验设置流程。
5.3 评价方法
我们从网页来源和网页类型对网页进行了人工筛选。同一搜索引擎返回的结果中,同一版块内的网页结构相似。新闻、博客及论坛三种类型的网页各不相同,但同一类型网页信息又有相似之处。因此,在保证网页来源和网页类型的多样性和泛化性,以及人工代价较小的前提下,我们选取5 000个网页数据进行人工标注,获得5 000个网页的正文、发布时间、作者三个主题信息作为参考结果,计算各个主题信息抽取准确率。实际中,我们通过交叉验证,先使用基于模板的方法进行主题信息抽取,然后使用人工标注的方法进行结果验证和完善,从而保证答案集的质量。对第i个网页,假设Di为人工标注的参考结果,Li为实验抽取结果。对于正文,每个网页的抽取准确率如式(1)所示。
其中,LcsLength(Di,Li)为字符串Di和字符串Li的最大公共子串长度,Length(Li)为字符串Li的长度。对于5 000个网页,最终的准确率为式(2)。
其中,N是网页总个数,Pi为每个网页的准确率。
对于发布时间和作者,我们采用一致的评价方法。对5 000个网页,抽取准确率为式(3)。
其中,N是网页总个数。
5.4 实验结果及分析
实验结果如图7所示。下面对实验结果进行相关分析。
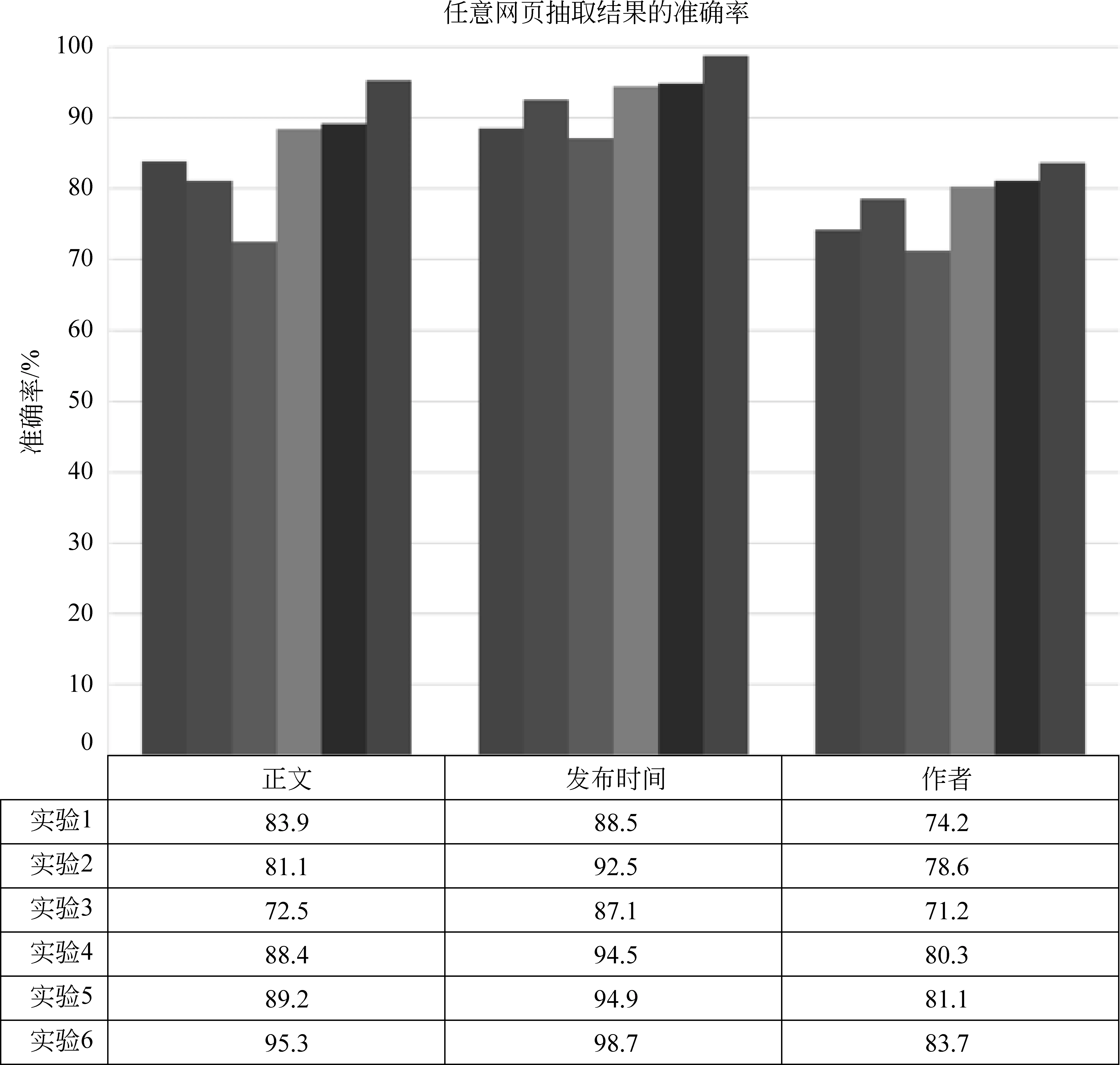
图7 六种实验方案的结果
5.4.1 实验1、实验2、实验3与实验4
实验1、实验2和实验3,我们认为所有网页都是一个类型,这种方法实现简单,且时间开销和内存占用较低。而实验4对网页进行了分类,针对不同类别网页采用不同全自动抽取方法,这样可以防止单一算法的倾向性,因此较前三个实验,准确率明显提高。这样可以看出,先进行网页分类,后使用模板无关的全自动抽取方法的抽取结果要好于直接使用某单一全自动抽取方法。
5.4.2 实验4与实验5
实验5认为部分论坛网页是由开源软件生成的,因此在对论坛运行多记录网页抽取方法前,先识别论坛网页是否由开源软件生成,若是则使用基于模板的抽取方法,否则和实验4一样使用多记录网页的全自动抽取方法。由实验结果可以看出,对论坛网页进行开源软件生成的预判断,准确率有提高。
5.4.3 实验5与实验6
实验6基于人工标注的各大网站版块的模板,在进行分类前,对网页进行URL匹配,反向查找该网页所在版块,若匹配成功,则从数据库中提取模板运行基于模板的抽取方法,否则进入实验5的实验步骤。由实验结果看出,加入数据库中是否存在已有模板的预判断,可明显提高准确率。这也侧面证实了基于模板的信息抽取方法的准确性较高。
5.4.4 整体实验结果对比
通过上述实验结果的分析发现,从仅采用局部方法到使用全部框架流程,任意网页的信息抽取率有了本质的提高。因此,客观地检验了整个框架的有效性和健壮性。
6 结论与展望
本文提出了一个基于融合机制的任意网页主题信息抽取框架,该框架通过“模板库匹配—基于模板抽取—网页分类—全自动抽取”四个步骤将模板无关的全自动抽取方法和基于模板的抽取方法巧妙地融合起来。实验结果表明,本框架能够在抽取准确率方面有本质的提高。同时本文还提出了以规则分类算法为主、以机器学习分类方法为辅的网页分类算法,将该算法引入到全自动抽取方法之前,能更准确地定位网页结构和类型,从而使多个全自动抽取方法之间相辅相成,提高抽取准确率。
进一步的研究希望针对该框架中的模板库匹配进行相关改进。由于现有模板库中的版块url会有重叠出现的情况,采用Trie树匹配时可能会匹配多个,现有的做法是取匹配到的第一个版块url作为匹配结果。之后可以对匹配到的多个版块url进行合理性验证,选取出最优的匹配版块url,以期待得到更好的抽取效果。
目前本文提出的架构确实为了解决实际问题。我们在提出面向任意网页抽取架构的同时,也考虑了实际应用中的性能和效率问题,所以包含的算法基本都是对传统方法的改进。我们希望能在未来工作中将最新的前沿技术应用其中,比如,在网页分类算法中,我们可以分别使用CNN[11]和RNN[12]对网页中的图像和文本进行特征抽取,并将两个特征向量拼接起来,使用softmax分类器进行分类。
[1] Chang, C.H., et al., A survey of web information extraction systems. Knowledge and Data Engineering [J], IEEE Transactions on, 2006. 18(10): 1411-1428.
[2] Chun-Nan Hsu, Ming-Tzung Dung. Generating finite-state transducers for semi-structured data extraction from the web [J]. Information Systems 23(8): 521-538, 1998.
[3] Valter Crescenzi, Giansalvatore Mecca and Paolo Merialdo. RoadRunner: Towards Automatic Data Extraction from Large Web Sites [C]//Proceedings of the 27th International Conference on Very Large Data Bases, p. 109 - 118 Morgan Kaufmann Publishers Inc. San Francisco, CA, USA 2001.
[4] Ion Muslea,et al. A hierarchical approach to wrapper induction[C]//Proceedings of AGENTS’99,New York,NY,USA,ACM,1999:190-197.
[5] Chai-Hui Chang, Shih-Chein Kuo. Olear: semisupervised web-data extraction with visual support [J]. Intelligent Systems,IEEE,2004,19(6):56-64.
[6] Tim Weninger, William H and Jiawei Han. CETR-Content Extraction via Tag Ratios [C]//Proceedings of the 19th international conference on World wide web, p.971-980, New York, NY, USA 2010.
[7] Jyotika Prasad, Andreas Paepcke. CoreEx: Content Extraction from Online News Articles [C]//Proceedings of the 17th ACM conference on Information and knowledge management, p. 1391-1392 ACM New York, NY, USA 2008.
[8] Deng Cai, Shipeng Yu, Jirong Wen and Weiying Ma. Extracting content structure for web pages based on visual representation[C]//Proceedings of the 5th Asia-Pacific web conference on Web technologies and applications, Springer-Verlag Berlin, Heidelberg 2003:406-417.
[9] Burges CJC. A tutorial on support vector machines for pattern recognition [C]//Proceedings of the Data Mining and Knowledge Discovery ,1998 2(2).
[10] 刘春梅,郭岩,俞晓明,等.针对开源论坛网页的信息抽取研究 [J].计算机科学与探索, 2016.
[11] Yoon Kim. 2014. Convolutional neural net- works for sentence classification [C]//Proceedings of the arXiv preprint arXiv:1408.5882.
[12] Ilya Sutskever, James Martens, and Geoffrey E Hinton. 2011. Generating text with recurrent neural networks[C]//Proceedings of the 28th International Conference on Machine Learning (ICML-11).
[13] 郗家贞.一种基于时间串的论坛页面信息自动抽取方法及系统[J]. 中国,201410429698.9[P].2014-08-29.

张儒清(1994—),博士,主要研究领域为信息抽取。
E-mail:zhangruqing@software.ict.ac.cn

E-mail:guoy@ict.ac.cn

E-mail:liuyue@ict.ac.cn
AGeneralThemeInformationExtractionforWebpages
ZHANG Ruqing1,2,GUO Yan1, LIU Yue1,YU Xiaoming1,CHENG Xueqi1
(1. CAS Key Laboratory of Newtwork Data Science and Technology, Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China;2. Graduate University of Chinese Academy of Sciences, Beijing 100190, China)
Most of existing information extraction methods are focused on a specific type of webpages, rather than applicable to all webpages. In this paper, we propose a general framework based on fusion mechanism to enable the extraction of the theme information of all webpages. This framework combines the automatic information extraction strategy and the template detection strategy through four steps: template matching, template based extraction, web page classification and automatic extraction. The experiments show that the proposed strategy can lead to an additional performance improvement in the precision of extraction.
any page; theme information; web page classification; practical value
1003-0077(2017)05-0127-11
TP391
A
2016-03-16定稿日期2017-04-26
国家重点基础研究发展计划(“973”计划)(2014CB340401,2013CB329606);科技部重点研发计划(2016QY02D0405);国家自然科学基金(61232010,61472401,61425016,61203298);中国科学院青年创新促进会优秀会员项目(20144310,2016102)
