基于字典学习的模糊车牌中文字符识别
2017-11-20干宗良麦媛玲
吕 颢,刘 峰,干宗良,麦媛玲
(1.南京邮电大学 图像处理与图像通信江苏省重点实验室,江苏 南京 210003;2.视频图像智能分析与应用公安部重点实验室,广东 广州 510000)
基于字典学习的模糊车牌中文字符识别
吕 颢1,刘 峰1,干宗良1,麦媛玲2
(1.南京邮电大学 图像处理与图像通信江苏省重点实验室,江苏 南京 210003;2.视频图像智能分析与应用公安部重点实验室,广东 广州 510000)
车牌识别技术已经是一项非常成熟的技术。而车牌当中的中文字符由于笔画比较复杂且位置较偏导致拍摄条件受限,得到的车牌中文字符图像质量不佳,往往较难辨认,从而给车牌识别工作尤其是车牌中文字符识别带来了极大困难。文中采用基于费希尔判别准则的字典学习方法来提取中文字符的特征,为了从不同的角度对中文字符提取特征,用不同的训练样本训练三个字典学习模型,将车牌中文字符样本分别通过训练好的三个字典学习模型,从而形成三种残差信息,用Softmax对三种残差信息进行整合,最终得到识别结果。通过实际测试表明,由于文中采用了更加具有区分能力的基于费希尔判别准则的字典模型,且采用三种不同的字典学习模型同时对同一个中文字符进行特征提取,与传统的中文识别方法相比,该方法对模糊车牌中文字符具有较好的识别效果。
中文字符识别;字典学习;主成分分析;Softmax回归
0 引 言
随着智慧城市的快速建设和机动车辆数量的增加,车牌识别技术变得愈来愈重要。由于受获取图像实际环境和条件的限制,车牌图像可能会十分模糊。此外,中文字符结构具有多样性和复杂性等特性,使得识别这种模糊场景中的车牌中文字符变得十分困难。
中文车牌识别技术在国内外研究广泛,有许多方法可以处理此类问题。如最简单的模板匹配[1-2],它不需要提取特征,输入图像直接与一系列的模板字符进行匹配,最终选择出与原图像最接近的模板并将其作为最终的字符识别结果。ANN(人工神经网络)也常被用来识别中文字符[2-4]。当然目前CNN(卷积神经网络)在中文字符的识别[6-7]上运用得更加广泛,它是通过许多样本来训练一个能够识别中文字符的卷积神经网络,通过卷积层和采样层来提取图像特征。SVM(支持向量机)也常用在识别系统中[8-11]。近年来,字典学习也逐渐被使用[12-14]。还有用经典的字典学习方式SRC(稀疏表示识别方法)完成车牌识别任务。但是由于原始车牌中的噪声干扰,导致字典不能有效地表示目标车牌。总的来说,上述方法都能识别出清晰的中文字符,但对于模糊车牌的识别仍然非常困难。
因此,文中提出一种基于费希尔判别准则的字典学习方法来表示车牌中的中文字符。通过费希尔判别准则得到的字典能够比一般的字典学习方法生成的字典更好地表示模糊中文字符。采用三个字典学习模型同时对一个模糊车牌样本进行处理,进而分别得到三个不同的残差,将其通过Softmax回归进行整合得到最终识别结果。
1 车牌中文识别算法
算法流程如图1所示。
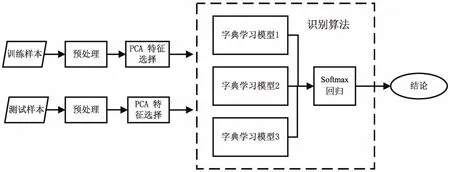
图1 算法流程
先从现实的车牌图像中截取车牌中文字符。经过一系列的预处理操作,用PCA(Principal Components Analysis)对车牌中文字符的特征进行提取,不仅可以降低数据的维度,加快算法的速度,同时也可以滤除噪声。根据不同的训练样本分别生成三个字典学习模型。用基于费希尔判别准则的字典学习模型来建立字典更加利于模糊车牌中文字符的重建。最后,将经过字典学习所得到的残差作为输入,采用Softmax回归的方式进行整合并得到最终的识别结果。识别模型数量的增加使得识别结果更加稳定。如果一旦一个识别器识别错了,最终结果会被其他两个识别器纠正过来。实验结果表明,该方法更加有利于中文车牌字符的识别。
1.1预处理
一般从监控视频中获取的是包含车辆以及更多背景图片的图像,识别系统无法直接处理。因此,这些图像必须经过一系列预处理,包括车牌截取、仿射变换、字符分割、灰度化、去均值和归一化等步骤。经过预处理,中文字符图像变得更加利于后续操作。
1.2特征提取
PCA是一种数据处理技术,可以方便有效地找出对象的主成分和图像结构,消除冗余信息量的同时降低数据维度。该方法非常简单且没有参数限制,已经广泛应用于字符识别中[15-16]。经过PCA操作,可以提取出模糊车牌中文字符的特征,加快整个算法的速度,在一定程度上降低图像噪声。
1.3识别算法
目前字典学习在许多图像处理和计算机视觉领域当中应用广泛[14-15]。与一般字典学习方法不同的是,文中算法生成的字典不仅具有区分性,而且对应的稀疏系数同样具有稀疏性。
该方法先构造一组与类别标签相关的结构字典D=[D1,D2,…,DC],其中Di为与第i个省份中文车牌信息相关的字典部分;C值为31,因为总共需要识别31个省份的车牌。训练车牌样本表示为X=[X1,X2,…,XC],X通过结构字典线性表示:X≈DA。其中A表示编码稀疏矩阵,A=[A1,A2,…,AC],Ai代表属于第i省份的所有训练样本Xi通过字典D表示所对应的编码系数。除了需要字典D对训练样本X具有强大的重建区分能力,也希望A具有区别样本的能力。因此引入费希尔判别准则,使得稀疏编码系数A的类间散度变大同时类内散度变小。最终,损失函数如下:
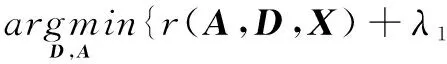
λ2f(A)}
(1)
其中,r(A,D,X)为区别项;‖A‖1为稀疏项;f(A)为区别常数项;λ1和λ2为系数参数。
接下来详细讨论费希尔判决标准中的r(A,D,X)和f(x)。
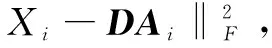
区别系数项f(A)是为了使编码系数A同样具有区分能力。基于费希尔判决准则,最小化类内间隔SW(A)同时最大化类间间隔SB(A)。其中SW(A)和SB(A)分别定义为:
(2)
(3)
其中,mi和m分别是Ai和A的平均向量。
因此f(A)被定义为:
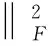
(4)
残差生成:对于测试样本y,首先通过字典D编码,从而能获得它的稀疏系数编码:
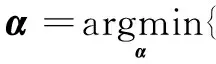
(5)
其中,α为子字典Di的系数。
定义残差为:
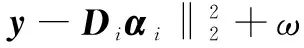
(6)
其中,第一项代表第i个省的重建错误;第二项为系数向量α与所学习到的第i个省车牌的像素值均值的距离;ω为平衡这两项的权重
识别整合:Softmax回归是一个用于多分类识别的可监督学习模型。将得到的残差还有所对应的省份标签作为训练样本,将训练样本放入Softmax回归模型进行训练。因此,一旦能够获得这三类不同字典学习模型所获得的残差信息,就可以通过Softmax回归模型去确定这辆车来自于哪个省份。
2 实验结果与分析
在相同的软件和硬件环境中测试并对比提出的识别算法与其他中文识别算法。如表1所示,SVM[8]占用了最少的时间,而ANN[2]和CNN[6]则花费了较多的时间,神经网络需要花费大量时间在反向梯度传导时计算偏导数,而一般神经网络都有2到3层甚至更多。文中算法并没有多层处理。因此,相对于多层网络算法,时间损耗将少得多。即使重建模糊车牌需要花费一定的时间,但是由于基于费希尔判决的字典学习所产生的字典数量比其他字典学习要少,因此相对于其他字典学习方法花费了更少的时间。

表1 不同算法的实验对比
从表1同样可以看出,文中算法比其他算法有更高的识别率。原因在于所用的字典具有较强的区分能力,能够较好地重建出要识别的模糊车牌。此外,同时使用三个不同的字典学习模型去识别同一个模糊车牌中文字符,一旦一个识别器给出了错误信息,其他两个识别器有很大的可能去纠正这个错误。鉴于以上两条优势,文中算法获得了比较可观的识别率。

表2 不同省份车牌的实验结果统计
如表2所示,文中方法不光对于模糊中文车牌有更高的识别率,还有着很高的识别稳定性,对结构相近的省份字符同样能够区分出来,比如“甘”和“吉”、“云”和“甘”等等。在所有31个省份车牌中,有4个省的车牌达到100%的识别率,20个省的车牌达到大于97%的识别率。这与算法独特的结构设计以及字典学习方式是分不开的。由于通过字典所形成的残差和稀疏编码系数同时都具有区分性,故文中算法的字典能很好地重建出模糊车牌中文字符,使得中文车牌字符不易于与其他中文结构相近的省份车牌字符所混淆。
3 结束语
文中提出了一种模糊车牌识别的新方法。该方法采用基于费希尔判决准则的字典学习模型和Softmax回归来分别表示和识别模糊车牌中文字符。相比一般的字典学习算法,基于费希尔判决准则的字典学习对于模糊车牌中文字符有着更强的重建能力。此外,整合三个字典模型进行识别的方法比只凭一个识别器识别的方法具有更高的识别率和更好的稳定性。因此,可以广泛应用于车牌系统识别中。
[1] Lan C,Li F,Jin Y,et al.Research on the license plate recognition based on image processing[C]//Fifth international conference on instrumentation and measurement,computer,communication and control.Qinhuangdao:IEEE,2015:731-734.
[2] 邹明明,卢 迪.基于改进模板匹配的车牌字符识别算法实现[J].国外电子测量技术,2010,29(1):59-61.
[3] 呙润华,苏婷婷,马晓伟.BP神经网络联合模板匹配的车牌识别系统[J].清华大学学报:自然科学版,2013(9):1221-1226.
[4] 吴 聪,殷 浩,黄中勇,等.基于人工神经网络的车牌识别[J].计算机技术与发展,2016,26(12):160-163.
[5] Vishwanath N,Somasundaram S,Nishad A,et al.Indian license plate character recognition using Kohonen neural network[C]//International conference on computational intelligence & computing research.[s.l.]:IEEE,2012:1-4.
[6] Liu P,Li G,Tu D.Low-quality license plate character recognition based on CNN[C]//2015 8th international symposium on computational intelligence and design.Hangzhou:IEEE,2015:53-58.
[7] Zhong Z,Jin L,Feng Z.Multi-font printed Chinese character recognition using multi-pooling convolutional neural network[C]//13th international conference on document analysis and recognition.Tunis:IEEE,2015:96-100.
[8] Bautista R M J S,Navata V J L,Ng A H,et al.Recognition of handwritten alphanumeric characters using projection histogram and support vector machine[C]//International conference on humanoid,nanotechnology,information technology,communication and control,environment and management.[s.l.]:[s.n.],2015:1-6.
[9] Angeline L,Wei Y K,Wei L K,et al.Research of license plate character features extraction and recognition[C]//2nd international conference on computer science and network technology.[s.l.]:[s.n.],2012:2154-2157.
[10] Ghahnavieh A E,Amirkhani-Shahraki A,Raie A A.Enhancing the license plates character recognition methods by means of SVM[C]//22nd Iranian conference on electrical engineering.[s.l.]:[s.n.],2014:220-225.
[11] 周 鹏.基于支持向量机的车牌字符识别方法[J].数字技术与应用,2016(9):91.
[12] 陈思宝,赵 令,罗 斌.基于核Fisher判别字典学习的稀疏表示分类[J].光电子·激光,2014,25(10):2000-2008.
[13] 练秋生,石保顺,陈书贞.字典学习模型、算法及其应用研究进展[J].自动化学报,2015,41(2):240-260.
[14] 朱 杰,杨万扣,唐振民.基于字典学习的核稀疏表示人脸识别方法[J].模式识别与人工智能,2012,25(5):859-864.
[15] 刘冰冰.基于PCA车牌汉字识别算法的研究与实现[D].长春:长春理工大学,2011.
[16] 闫雪梅,王晓华,夏兴高.基于PCA和BP神经网络算法的车牌字符识别[J].激光与红外,2007,37(5):481-484.
ChineseCharacterRecognitioninFuzzyVehiclePlateBasedonDictionaryLearning
LYU Hao1,LIU Feng1,GAN Zong-liang1,MAI Yuan-ling2
(1.Key Laboratory on Image Processing & Image Communications of Jiangsu Province,Nanjing University of Posts and Telecommunications,Nanjing 210003,China;2.Key Laboratory on Video Image Intelligent Analysis and Application of Ministry of Public Security,Guangzhou 510000,China)
Vehicle license plate recognition has already been a mature technology.However,due to the complicated strokes in Chinese character and bad shoot environment by the remote location,the image quality of Chinese character is too bad to recognize,which is difficult for the vehicle license plate recognition,especially for Chinese character recognition.The dictionary learning method based on Fisher discriminative criterion is proposed to extract the Chinese character features.In order to extracting features of Chinese character from different aspects,three dictionary learning models are trained by different training samples and through them,three different residual information are obtained which are integrated by Softmax for final recognition results.The practical tests show that compared with the traditional Chinese recognition methods,it can own better recognition effect in Chinese character of fuzzy vehicle plate since the use of dictionary model based on Fisher discriminative criterion with more strong distinguishing and adopting three dictionary learning models to extract features for same Chinese character at the same time.
Chinese character recognition;dictionary learning;principal component analysis;Softmax regression
2016-11-23
2017-03-09 < class="emphasis_bold">网络出版时间
时间:2017-07-19
国家自然科学基金项目资助项目(61471201);江苏省高校重大基础研究项目(13KJA510004);江苏省六大人才高峰资助计划(RLD201402);南京邮电大学“1311”人才资助计划;广州市软件和信息服务产业专项资金所属重点专项(2060404)
吕 颢(1992-),男,硕士生,研究方向为图像处理与多媒体通信;刘 峰,博士,教授,博士生导师,通讯作者,研究方向为图像处理与多媒体通信、高速DSP与嵌入式系统。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170719.1113.084.html
TP301
A
1673-629X(2017)11-0075-04
10.3969/j.issn.1673-629X.2017.11.016
