社交网络下非结构化数据协同过滤推荐算法改进
2017-11-16王腾飞
王腾飞,孙 华
(1. 中车青岛四方机车车辆股份有限公司,山东 青岛 266100)
社交网络下非结构化数据协同过滤推荐算法改进
王腾飞,孙 华
(1. 中车青岛四方机车车辆股份有限公司,山东 青岛 266100)
现代社交网络中存在着数量巨大且无序的非结构化数据,针对非结构化数据采取协同过滤十分必要。传统的基于用户的协同过滤推荐算法由于其本身原理,其相似性计算的时间复杂度极高,本文通过引入粗集,高速分割用户和用户项目,直接计算分割后各组质心与初始用户的相似性来解决该问题。但数据易稀疏以及冷启动的问题仍未解决,对此在引入粗集的基础上加入信任概念,根据用户信任度以及信任的传递性缓解以上问题。在增强精确度的基础上还提高推荐速度。该模型还可以方便的扩展。
推荐算法;协同过滤;粗集;相似性;非结构化数据
0 引言
在许多社交网络系统中,存储,发布和共享项目的便利性使得用户在获取有趣信息时会产生信息超载。越来越多有影响力的社交网络为用户提供了标记URL链接,电影,照片等项目的标签。标签提供的信息显示用户的兴趣,更多被描绘了的项目准确地为数据分析和知识发现提供更多的机会和资源[1-3]。个性化推荐系统是用于改善用户体验和帮助用户获取适合自己兴趣的信息的系统,是社交网络中最常见的模块之一。其中最为流行的是基于协同过滤的推荐系统,但由于其是通过项目和注释操作计算所有用户对的相似性,从而对时间复杂度提出了非常高的要求,强烈地抑制了推荐速度。本文为了克服这个缺点,利用粗集的方法,高速分割类似的用户和相关项目,以增强基于用户的协同过滤性能[4],为社会标签系统开发快速协作用户模型。最重要的是没有损失精确度。
另外随着互联网技术以及智能化手机的不断发展,社交网络用户量增长迅速,据预测,2017年中国社交网络用户将达到6.62亿,其中的主要增长来源于 50-60岁的老年群众。而社交网络是推荐系统的重要信息来源。一些诸如阿里巴巴,京东等电子商务网站也基于社交网络进行了重构,努力向社会化电商。事实证明,相比于陌生人和没有社会影响力的人,用户更相信身边的人和有一定社会影响力的人士的推荐,信任作为人际关系中的重要标准,在很大程度上影响着用户的决策,因此将信任关系作为重要维度,与协同过滤相融合,对于协同过滤本身的冷启动和稀疏性问题都能起到较大的缓解[5-6]。
1 协同过滤
1.1 协同过滤概述
主要分为在线和离线两种。在线协同是指通过在线数据分析得出用户可能产生偏好的项目,而离线协同是将在线协同的项目集进行过滤,例如过滤到预测评分低于阈值的项目或者过滤掉预测评分在阈值之上但用户已经购买的项目[7]。本论文使用基于用户的协同过滤,公式(1)进行相似性计算 公式(2)进行分数预测。
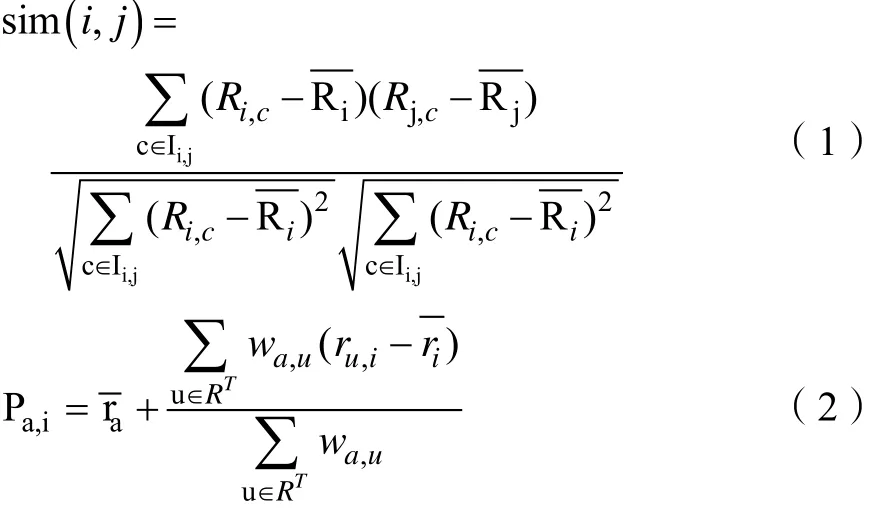
1.2 协同过滤优缺点
协同过滤算法之所以能够在众多个性化算法中脱颖而出,主要有以下两个方面:
(1)可以过滤一些机器解析相对困难的项目,例如艺术品、电影和音乐等,以及一些抽象的概念,例如思想、品味和评论等。
(2)可以推荐出让用户出乎意料的项目。
然而传统基于用户的协同效率算法仍有以下缺陷[8]:
(1)可扩展性。由于在实际网站中用户和项目达到百万级甚至千万级,这就会使用户-评分矩阵的维度非常的高,并且由于用户和项目数量仍会持续增长,其时间复杂度会增加的更加剧烈,严重影响推荐系统的效率。
(2)稀疏性。实际网站中一般都拥有众多用户和项目,且其数量是不断增加,然而用户只对其中非常小的一部分项目产生项目评分(大概只占到所有项目1%),这就导致用户的评分矩阵非常的稀疏,从而导致搜索到的最近邻和最近邻的评分信息都会减少。
(3)冷启动。冷启动问题的根源在于“新”,一个新生成的项目是没有人去评论的,所以该项目不会推荐给任何用户,推荐系统对该项目是失效的。同样的,一个新用户没有对任何项目产生评论,那么通过相似性计算无法产生任何最近邻集,则推荐系统也是无效的。
在本文中,我们通过引入粗集的方式缓解第一个缺陷,利用引入信任度缓解后两个缺陷。
2 基于粗集的快速协同过滤模型
一个社交网络的标签系统包含用户的行为(例如标签项),项目(使用的URL/视频/图书/商品)和注释操作(例如,在应用程序中标记/收集),可以表示为用户项标记的三种形式。

其中U,R,T表示有限用户组,项目和标签,Eurt描述了具有特定标签的项目。
只看用户方面,我们可以分类出用户-项目和用户-标签

因此,用户可以通过资源使用和注释动作的信息来表征。换句话说就是可以被表示为两个向量:用户项目向量和用户标签向量。其中用户项目向量可以表示为:

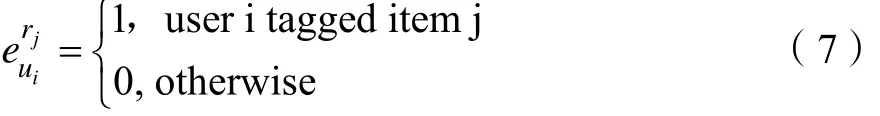
我们可以使用相同的建模方式对项目和标签结点进行建模。相似的用户标签向量表示为:


2.1 相似性指标
我们考虑共同使用项目和标签来测量相似度。事实上,高维并稀疏的数据对欧式距离是有影响的,当数据高维并稀疏时,其欧式距离更为较为集中,而两对数据元素的欧式距离也很相似[9]。因此我们对公式(9)进行改进从而进行相似性评估。β的值设置为 0.5是由于这两个类型的余弦相似性遵循类似的分布。
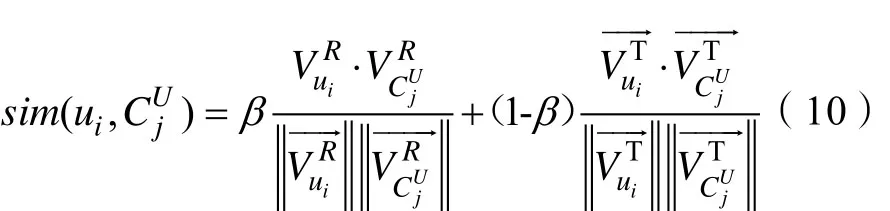
2.2 用户和项目的粗集
算法关键是用户和项目的快速分区。我们使用k均值分割算法,它的相似性度量是基于公式(10)。基于粗集,我们首先将用户划分为互不重叠组。在整个用户-项目结构中,这些项目还通过用户项目关系被划分成相关联的重叠组。结合每个用户组和相关联的项目组,我们将用户-项目划分成用户方面的不同子类[10-12]。虽然粗集算法的步骤与K均值方法中的步骤相似,但其目的不是获得社会标签系统的完全收敛的用户/项目组。因此,不必使算法迭代收敛。K均值算法第一步是将节点交付给任意组。而第二步,计算每个组的质心,并根据节点和质心的相似度将每个节点重新分配给新的组,直到多次迭代到一个收敛的结果。本算法中,迭代数为 2。因为只要计算用户的相似之处和每个用户组的质心就能反应用户的相似之处。两个质心方程分别如下:
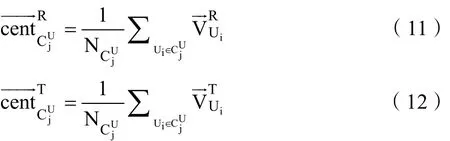
其中UjCN 是用户组中的用户数,将公式(11)和(12)代入公式(10)中,得新的相似性计算公式:
3 基于信任的协同过滤
3.1 信任的定义及属性
社会学家Lhumann指出“信任是降低社会复杂度的一种方法”[13-14],用户之间通过信任形成社交圈,再通过该社交圈进行社交行为,从而不断地更新和强化信任,因此信任在社交网络之中至关重要。在推荐算法的范畴里,我们使用 Golbeck对信任的定义:假设用户B的行为为用户A的行为带来了有利的参考和更好的结果,有利的参考表示相关性,更好的结果表示价值性,一旦价值性和参考性同时存在,那么我们可以认为A是信任B的。信任网络图由用户和具有权重的有向边构成,其中权重表示信任度。信任作为一种复杂的网络关系,具有一些固有属性[15]。
(1)主观性:信任是一种主观判断,由信任方自身的情况决定,是在一定客观因素的基础上做出的自主判断。正因如此,信任双方的信任关系并不是等价的。
(2)非对称性:信任关系是有方向性的,是一种单向关系。
(3)上下文相关性:信任只表示某个领域的信任,对于其他领域可能是无效的。
(4)传递性:在拥有共同上下文相关性的基础上,信任可以传递并且是逐级递减的。
(5)动态性:信任建立之后是时刻变化的,这种变化随时可能发生而导致信任在任何情况下发生更新。
3.2 信任度和相似度计算
我们使用Golbeck等人研究的有关信任度ta,u的计算方式:

通过对信任网络进行广度优先遍历,我们可以搜索到初始用户到目标用户的所有路径,从而筛选出与目标用户之间存在的最大信任度的用户集合,采用加权平均方法,迭代地更新目标用户的初始用户信任。相似度公式采用公式(13)。
3.3 基于信任的协同过滤框架
对于新的预测评分公式,将公式(14)带入传统的协同过滤算法项目预测公式(2)中,形成新的用户a对项目i的预测公式:
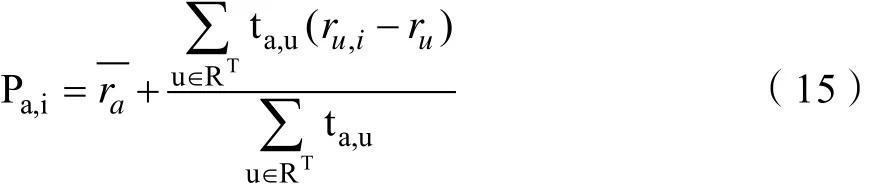
r代表用户对自己所有项目的平均分。用户集合为拥有共同上下文的其他用户。
对于传统协同过滤算法的固有问题,通过引入信任,虽然无法完全解决,但我们可以很好地缓解。只要有一个信任用户,根据信任的传递性就可以找到诸多其他用户,丰富评分矩阵,从而使推荐系统重新生效,缓解了冷启动问题。又例如稀疏性问题,同样的,依赖于信任的传递,我们可以找到比传统协同过滤更多的用户。
3.4 算法流程
(1)去除信任网络中的回路。基于信任的协同过滤模型的最大特点是可以根据信任的传递获得更好的信任度,但信任的传递同样会导致信任网络中出现较多的回路。基于现实中人们更加相信自己的主管判断而不是他人判断这一事实,我们将所有的回路去掉,只考虑从用户A到用户C的直接信用度。同时合并多路径。这样,一个杂乱无序的信用网络就可以被我们整合的井然有序。
(2)简化完信用网络之后,利用信任算法,我们递归的搜索初始用户的信任用户(类似于图论算法中的广度优先遍历),直到查完所有目标。之后根据公式计算每个信用路径的结果。
(3)根据每条信用链的计算结果求出初始用户对目标用户的信用平均值,大于系统规定的阈值就将其加入最近邻用户集之中。
(4)根据评分公式进行预测,将结果推荐给初始用户。
4 总结与展望
传统基于用户的协同过滤模型存在着诸如相似性效率低,冷启动以及稀疏性等问题,利用粗集的方法进行快速分割,只需计算用户组的质心与初始用户的相似性,加快了推荐速度。同时将信任维度引入协同过滤算法,依赖于信任传递性的特点,用信用度替代原本预测公式中的推荐权重,可以找到更多的用户和项目。
对于未来的工作,本人将考虑主要研究基于模型的协同过滤算法,这是目前学者着重研究的,其可以概括为解决一个问题:即有n个产品和n个消费者数据,其中只有部分用户和部分项目之间有评分,其余评分都是空的,通过已知评分来填补空白评分。关于该问题,大都使用机器学习算法建模解决,例如关联算法、聚类算法、分类算法、回归算法、矩阵分解算法和神经网络等。其中用深度学习做协同过滤应当是今后的一个主流,现在比较流行的是两层神经网络的限制玻尔兹曼机,在今后,基于CNN和RNN的协同过滤应当会有更好的效果。本人计划在改进限制玻尔兹曼机的基础上,重点研究通过深度学习来填补推荐模型的空白,分析用户特征和项目特征。
[1] 张振华, 刘瑞芳. 微博社交网络中面向机构的用户挖掘[J].软件, 2013, 34(1): 121-124.
[2] 谭学清, 黄翠翠, 罗琳. 社会化网络中信任推荐研究综述[J]. 现代图书情报技术. 2014(11).
[3] 李善涛, 肖波. 基于社交网络的信息推荐系统[J]. 软件,2013, 34(12): 41-45.
[4] 颜龙杰. 基于近邻评分预测的协同过滤推荐算法[J]. 软件,2013, 34(8): 63-66.
[5] 徐妍妍, 王宏志, 高宏, 等. 基于高维稀疏数据的k- 分桶高效skyline 查询算法[J]. 新型工业化, 2012, 2(8): 41-55.
[6] 张富国. 基于社交网络的个性化推荐技术[J]. 小型微型计算机系统. 2014(7).
[7] 郭磊, 马军, 陈竹敏. 一种信任关系强度敏感的社会化推荐算法[J]. 计算机研究与发展. 2013(9).
[8] 曹一鸣. 协同过滤推荐瓶颈问题综述[J]. 软件. 2012(12).
[9] 孙冬婷, 何涛, 张福海. 推荐系统中的冷启动问题研究综述[J]. 计算机与现代化. 2012(5).
[10] Recommender systems survey[J]. J. Bobadilla, F. Ortega, A.Hernando, A. Gutiérrez. Knowledge-Based Systems. 2013.
[11] Jesús Bobadilla, Fernando Ortega, Antonio Hernando, Jesús Bernal. A collaborative filtering approach to mitigate the new user cold start problem[J]. Knowledge-Based Systems. 2011
[12] Yehuda Koren. Factor in the neighbors[J]. ACM Transactions on Knowledge Discovery from Data (TKDD). 2010 (1).
[13] X. Zhu, H. Tian, S. Cai, J. Stat. Mech. Theory Exp[J]. 2014(2014) P07004.
[14] G. Adomavicius, A. Tuzhilin, IEEE Trans. Knowl. Data Eng[J]. 17 (2005) 734-749.
[15] L. Lü, M. Medo, C.H. Yeung, Y.-C. Zhang, Z.-K. Zha g, T.Zhou, Phys. Rep[J]. 519 (2012): 1–49.
Improvement of Unstructured Data Collaborative Filtering Recommendation Algorithm in Social Network
WANG Teng-fei1, SUN Hua2
(CRRC QINGDAO SIFANG CO., LTD.Qingdao Shandong, 266100)
There is a large amount of unstructured data in the modern social network, and it is necessary to adopt collaborative filtering for unstructured data. The traditional user-based collaborative filtering recommendation algorithm has a very high time complexity in its similarity calculation due to its own principle. By introducing the coarse cluster, high-speed segmentation user and user project, this paper calculates the similarity between the groups and the initial users To solve the problem. But the data is easy to sparse and cold start problem remains unresolved,which in the introduction of coarse clusters based on the concept of trust, according to the user trust and trust to ease the above problems. On the basis of enhanced accuracy to improve the recommended speed. The model can also be easily extended.
: Recommended algorithm; Collaborative filtering; Coarse cluster; Similarity; Unstructured data
TP301.6
A
10.3969/j.issn.1003-6970.2017.10.033
本文著录格式:王腾飞,孙华. 社交网络下非结构化数据协同过滤推荐算法改进[J]. 软件,2017,38(10):169-172
王腾飞(1987-),男,工程师,信息技术应用;孙华(1972-),男,高级工程师,信息技术应用。
