一种基于Redis的分布式爬虫系统设计与实现
2017-11-16罗娇敏
罗娇敏,耿 茜
(南京航空航天大学 金城学院信息工程系,江苏 南京 211156)
一种基于Redis的分布式爬虫系统设计与实现
罗娇敏,耿 茜
(南京航空航天大学 金城学院信息工程系,江苏 南京 211156)
随着互联网技术的飞速发展,互联网信息和资源呈指数级爆炸式增长。如何快速有效的从海量的网页信息中获取有价值的信息,用于搜索引擎和科学研究,是一个关键且重要的基础工程。分布式网络爬虫较集中式网络爬虫具有明显的速度与规模优势,能够很好的适应数据的大规模增长,提供高效、快速、稳定的Web数据爬取。本文采用Redis设计实现了一个主从式分布式网络爬虫系统,用于快速、稳定、可拓展地爬取海量的Web资源。系统实现了分布式爬虫的核心框架,可以完成绝大多数 Web内容的爬取,并且节点易于拓展,爬取内容可以定制,主从结构使得系统稳定且便于维护。
Redis;分布式;主从式;爬虫系统
0 引言
互联网的快速崛起极大的改变了人们的生活,互联网上的资源和信息以一种爆炸式的方式增长。如此海量的数据,如此快的增长速度,为搜索引擎提出了不小的挑战。同时,海量的网页中拥有的大量有价值的数据,也需要通过爬虫来抓取,为信息检索和科学研究提供大量的数据支持[1]。网络爬虫作为一种被广泛应用的信息获取手段,早期使用的网络爬虫技术一般都是单机网络爬虫。爬虫程序首先设置待爬取队列,然后从待爬取队列中获取超链接URL,抓取该URL对应的页面,最后取出新的链接放入待爬取队列中,依次循环操作直到待爬取队列为空[2]。随着网页数量呈现爆炸性增长,单机的爬虫程序速度太慢,网络爬虫获取信息的速度也远远跟不上信息增长的速度,无法满足信息获取的要求。因此,必须采用分布式的方法,使用多个节点并行地对这些数据进行抓取和处理[3]。但已有的开源分布式爬虫系统实现复杂,应用起来较为困难。
目前,许多大型的互联网公司(如:百度,谷歌等)都研发出了自己的复杂的分布式的网络爬虫,但是这项技术作为公司核心的技术,没有对外界开放它的源码。有些在使用的开源的爬虫,基本上还是单机模式,很少采用分布式的方法。当然也存在一些分布式的爬虫,如:Nutch,Igloo等,但是这些系统实现和部署起来比较复杂[3]。因此,设计和实现一个简单稳定的、可定制性高的、中小规模的分布式爬虫具有很重要的意义,能够适应网页数据的指数式增长,帮助我们快速的获取海量的网页数据,为搜索引擎的检索,实验室大数据方面的研究提供数据源。
本文主要的研究内容是设计和实现一个基于Redis的分布式爬虫系统。采用主从的架构模式,用户向系统提交任务(需要爬取的种子 URL),主节点(Master)调度从节点(Slave)分布式并行地完成多个爬取任务,将爬取的网页数据存储于数据库和本地硬盘上。同时,对于每个页面的爬取提供接口函数以完成个性化的定制。
1 相关背景
1.1 爬虫的基本工作原理
对于互联网来说,就相当于一张大的图,爬虫的搜索就是图的广度优先遍历[4]。从一系列的种子节点出发,提取 HTML页面的子节点(超链接),放入待处理的列表里面。被处理过的链接需要放到一张表(visited)里。每次从待处理列表中取出一个链接,需要判断它是否已被访问过(即是否存在于 visited表中),如果是,则跳过不处理,否则,进行下一步的处理。爬虫的工作过程示意图如图 1所示:
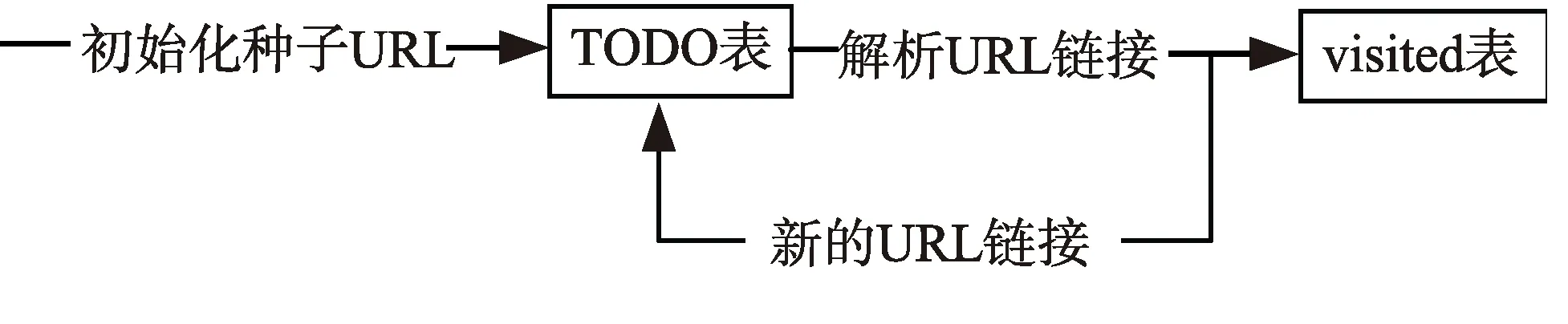
图1 爬虫的工作过程示意图Fig.1 Crawler working process diagram
初始化种子URL由用户或者系统设定,然后从种子URL出发,解析该页面的超链接,得到下一步将要处理的URL链接。接着,进行如下的工作:
(1)将解析的新URL链接放入TODO(待处理)队列。
(2) 处理完毕后,放入visited表,再次从TODO队列中取出一个URL链接。
(3) 针对这个链接,重复上述过程,直到TODO队列为空结束。
而分布式爬虫,其原理也是如此。只是抓取页面是在多个从节点上并行完成,各个节点之间相互通信,协同工作。
1.2 分布式爬虫的分类
各大公司采用的分布式爬虫,按照系统架构来分的话,主要分为三大类:主从模式,自治模式和混合模式[5]。
1.2.1 主从模式
主从模式是指由一台主机作为 Master控制节点,负责对所有运行网络爬虫的 Slave节点进行管理,爬虫只需要从控制节点那里接收任务,并把新生成任务提交给控制节点就可以了,在这个过程中不必与其他爬虫通信,这种方式实现简单利于管理。而控制节点则需要与所有爬虫进行通信,它需要一个地址列表来保存系统中所有爬虫的信息。当系统中的爬虫数量发生变化时,协调者需要更新地址列表里的数据,这一过程对于系统中的爬虫是透明的。这种模式结构清新简单,便于拓展从机节点,任务分配效率高。但是随着爬虫网页数量的增加,控制节点会成为整个系统的瓶颈而导致整个分布式网络爬虫系统性能下降[6]。主从模式的整体结构如图 2所示:
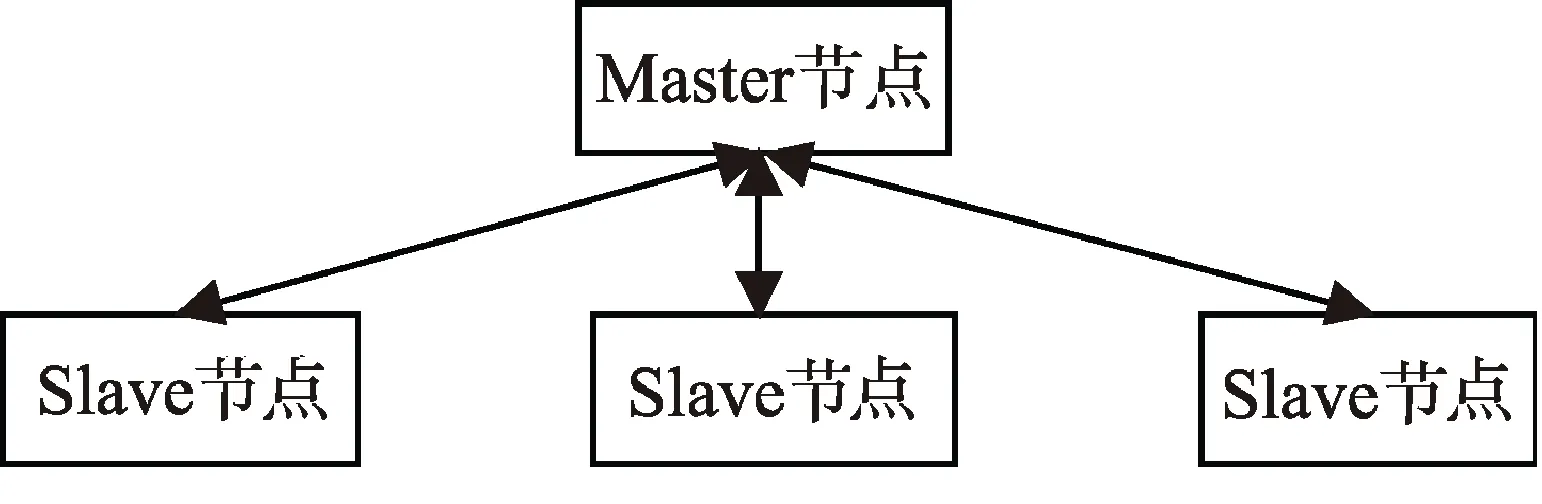
图2 主从模式结构图Fig.2 Master-slave diagram
1.2.2 自治模式
自治模式是指系统中没有控制者,所有的爬虫都必须相互通信。所有爬虫都可以相互发送信息,每个网络爬虫会维护一个地址列表,表中存储着整个系统中所有爬虫的位置,每次通信时可以直接把数据发送给需要此数据的爬虫[7]。当系统中的爬虫数量发生变化时,每个爬虫的地址列表都需要进行更新。这种模式系统的健壮性比较高,不会因为某个节点出现故障而导致系统无法工作。但是,它的结构比较复杂,节点之间的大量通信,影响了爬虫的工作效率。并且容易造成负载的不均衡。
1.2.3 混合模式
混合模式是结合上面两种模式的特点的一种折衷[8]。该模式所有的爬虫都可以相互通信同时都具有任务分配功能。爬虫中有个特殊的节点,该节点主要功能对已经经过爬虫任务分配后无法分配的任务进行集中分配。使用这个方式的每个网络爬虫只需维护自己采集范围的地址列表。特殊节点需除了保存自己采集范围的地址列表外还保存需要进行集中分配的地址列表[9]。
2 系统结构设计
本系统从流程图、数据库表结构、代码实现三部分来阐述系统实现,鉴于篇幅,这部分列出了实现本系统各模块的部分流程图、关键代码及实现后的截图。
2.1 系统架构
我们设计的分布式爬虫采用主从式架构,系统分为 Client,Master和 Slave三个主要部分。其中Client负责向Master提交爬取任务和获取任务的执行结果;Master负责任务调度和集群资源的管理,将任务分配到Slave节点执行,并同时与Slave通信,实时监测任务的执行和调度情况;Slave节点负责管理各自节点的资源,完成 Mater分配的爬虫任务,将爬取的数据存入MongoDB数据库。另外,Redis负责存储所有Slave节点的待爬取URL队列和已爬取URL队列,由Master和Slave共同维护和存取,同时记录每个爬取任务的执行状态。其主要的架构如图3所示。
在Master上,由Master维护,直接放在数据库Redis上,所有的Slave节点和Master节点均可以通过互联网访问Redis数据库。之所以采用Redis数据库来存取极其重要的 URL队列,主要是考虑到其存取速度快、可拓展、操作简单的特点[10-11]。这样的设计,就大大减少了Master节点维护URL队列所需要付出的资源,减少了与Slave节点的通信量。Master节点只需要将种子 URL存入 Redis待爬取队列,然后分配任务给 Slave节点,Slave节点接受到任务后,启动爬虫进程,从Redis获取URL开始爬取工作。同时,Slave节点可以完全按照自己的负载能力,按需从Redis取出URL,而不用 Master采取复杂的管控策略,既达到负载均衡的目的,又大大简化了系统的复杂性,使得系统更加稳定。
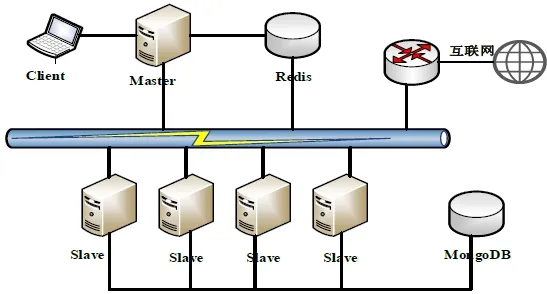
图3 系统结构图Fig.3 System structure diagram
2.2 系统的工作机制
系统任务的工作过程,大体可以简化成如步骤:用户提交爬取任务→Master管理任务队列→调度任务给 Slave→Slave执行爬虫工作→返回工作结果→任务完成。图4给出了系统详细的工作流程图。
Client主要是提供给用户的一个系统接口,方便用户使用该系统,它的主要功能如下:
(1)向Master提交爬取任务(种子URL)。
(2)查看任务的执行状态。
(3)查看Slave节点的系统状态。
Master节点是系统最为重要的一个组成部分,它主要负责为Client提供使用接口,与Slave通信,管理整个系统,分配和调度 Slave节点工作等,主要功能如下:
(1)与Client进行交互,为其提供功能接口。
(2)与Slave节点心跳通信。
(3)管理任务队列,初始化爬取URL队列。
(4)监测各个节点的工作情况和系统状态,管理Slave节点。
(5)根据 Slave节点的状况,动态地分配爬虫任务给Slave节点。
Slave作为任务执行的节点,其最主要的工作就是与Master通信,获取任务分片,然后启动爬虫爬取页面,并将爬取的页面写入数据库和本地磁盘,
主要功能如下:
(1)与Master心跳通信。
(2)管理本地资源,监测自身状态。
(3)接受Master分配的任务分片。
(4)启动爬虫,进行页面爬取,并将爬取的页面数据写入数据库和本地磁盘。
(5)向Master汇报自己的任务执行情况。
2.3 系统主要核心模块
基于篇幅的原因,本文主要介绍整个系统的核
心功能模块:爬虫模块。爬虫模块由 Slave启动调
用。其结构如图5所示。
其基本的流程图如图6所示。
其中,由于是分布式爬虫,所以URL去重是提
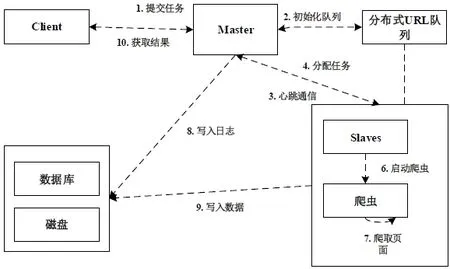
图4 系统工作流程图Fig.4 System workflow diagram
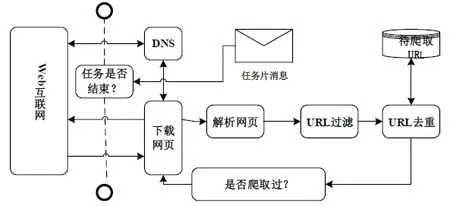
图5 爬虫模块结构图Fig.5 Crawler module structure diagram
升爬虫效率的一个关键手段,即所有的爬虫节点在接收到任务分片后,不会重复的爬取同一个页面。它的实现方式是将所有爬虫需要爬取的 URL队列和已爬取的URL队列放在共享的Redis数据库中,爬虫节点从该共享队列中按需取出URL进行爬取,已经爬过的页面不会重复爬取,这样就保证了URL
队列的一致性,提高爬虫效率。
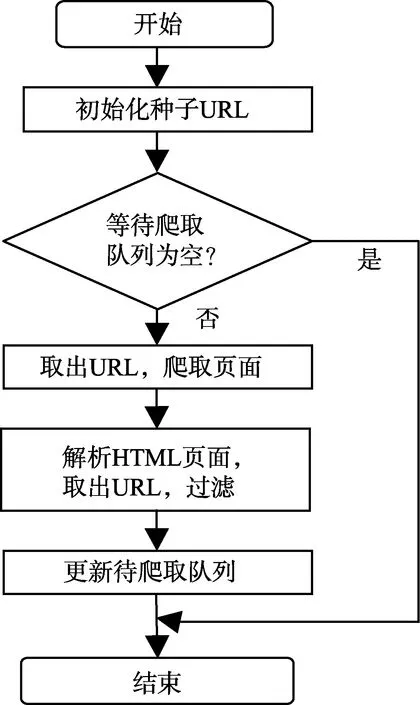
图6 爬虫工作流程图Fig.6 Crawler workflow chart
3 结语
网络爬虫一直作为互联网抓取信息的一个重要手段,在现今这个互联网高速发展的时代,互联网数据急剧膨胀的时代,我们更需要性能更加优良,效率更高,可以定制化的分布式网络爬虫,来获取更多、更有价值的数据,用于信息检索、科学研究、大数据分析等等。本文采用 Redis设计实现了一个主从式分布式网络爬虫系统,用于快速、稳定、可拓展地爬取海量的Web资源。系统实现了分布式爬虫的核心框架,可以完成绝大多数Web内容的爬取,并且节点易于拓展,爬取内容可以定制,主从结构使得系统稳定且便于维护。
当然,本系统也存在着不足之处:(1)主节点对系统资源、Slave节点的管理任务分配的策略并非最优;(2)还没有完成全自动化脚本,做到一键部署整个系统;(3)只能抓取静态的HTML页面,对于动态请求的,非HTML类型的网页数据不能抓取;(4)没有实现增量式的爬虫策略,对于较大规模的web,系统会出现一些小的错误,并且还是会存在资源浪费的情况。
以后的工作可以从以下几个方面着手:(1)改进任务调度和分配策略,加强对Slave节点的管理;(2)实现半自动化部署;(3)考虑动态的、其他类型的页面,增加爬虫的覆盖率;(4)结合增量爬虫的相关理论,减少爬取资源的浪费,提高爬取效率。
[1] 周京晖. 集成消息服务和定时通知的分布式内存数据库[J].软件, 2013, 34(1): 89-92.
[2] 刘晓婉, 胡燕祝, 艾新波. 开源中文分词器在web搜索引擎中的应用[J]. 软件, 2013, 34(3): 80-83.
[3] 郑力明, 李晓冬, 罗建禄. 服务器与集群系统节能技术研究[J]. 软件, 2013, 34(4): 59-61.
[4] 库劳里斯(英). 分布式系统概念与设计(原书第5版)[M].北京: 机械工业出版社, 2012.李婷. 分布式爬虫任务调度和AJAX页面抓取[D]. 成都电子科技大学硕士学位论文, 2015.
[5] 黄志敏, 曾学文. 一种基于Kademlia的全分布式爬虫集群方法[J]. 计算机科学, 2014.3.
[6] 袁威, 薛安荣, 周小梅. 基于Nutch的分布式爬虫的优化研究[J]. 无线通信技术, 2014. 08.
[7] 吴黎兵, 柯亚林, 何炎祥. 分布式网络爬虫的设计与实现[J]. 计算机应用与软件, 2011.11.
[8] 范珊珊, 李石君. 基于优先级队列的分布式多主题爬虫[J].计算机工程与设计, 2015.06.
[9] Yun Qi Gao, Chun Lin Peng. Design and Implementation of Distributed Crawler System for Opinion Mining[J]. Applied Mechanics and Materials., 2013(347).
[10] Shaojun Zhong. A Web Crawler System Design Based on Distributed Technology. Journal of Networks[J], 2011.12.
Design and Implementation of a Distributed Crawler System Based on Redis
LUO Jiao-min, GENG Qian
(Department of information engineering, Nanhang Jicheng College, Nanjing Jiangshu, 211156)
With the rapid development of Internet technology, the Internet information and resources are exponentially explosive growth. How to quickly and effectively obtain valuable information from a large amount of web pages for search engines and scientific research is a key and important infrastructure project. Distributed web crawler has obvious advantages in speed and scale, which can adapt to the massive growth of data, and provide efficient, fast and stable Web data crawling. In this paper, Redis is used to design and implement a master-slave distributed network crawler system, which can be used for fast, stable and scalable crawling Web resources. The system realizes the core framework of the distributed crawler, which can complete the crawling of the vast majority of Web content, and the nodes are easy to expand, the crawling content can be customized, and the master-slave structure makes the system stable and easy to maintain.
: Redis; Distribute; Master-slave; Crawler system
TP393.07
A
10.3969/j.issn.1003-6970.2017.10.015
本文著录格式:罗娇敏,耿茜. 一种基于Redis的分布式爬虫系统设计与实现[J]. 软件,2017,38(10):83-87
湖北省自然科学基金资助项目“面向数字取证的数据约简技术研究”(2015CFB764)
罗娇敏(1984-),女,讲师,主要研究方向:数据挖掘、分布式系统;耿茜(1963-),女,副教授,主要研究方向:信息技术。
