基于特征词匹配的政策文本分类算法研究与实现
2017-11-09王丽鹏张鹏云和志强
王丽鹏,张鹏云,和志强
(河北经贸大学 信息技术学院,河北 石家庄 050061)
基于特征词匹配的政策文本分类算法研究与实现
王丽鹏,张鹏云,和志强
(河北经贸大学 信息技术学院,河北 石家庄 050061)
在基于特征词遍历匹配的文本分类算法中,字符串匹配算法的选取及相似度阈值控制对文本分类结果起着决定性的作用。针对三种常用的字符串匹配算法做了分析及对比实验,选取了最适合政策文本分类的一种字符串匹配算法。并通过研究政策文本具有的特征提出了一种基于特征词加权的相似度阈值计算方法,经实验证明相似度阈值符合分类要求。
字符串匹配算法;阈值计算;文本分类
0 引言
丰富的网络信息资源为研究Web文本分类技术提供了有利条件。然而,不规则的Web页面结构,半结构化的文本信息,繁多的信息种类对于Web文本分类提出了巨大挑战[1]。Web文本数据挖掘主要是对Web文本中包含的关键词汇进行矢量化并对特征词进行总和、分类、聚类及相关性研究,同时可以对Web页面内容等数据进行相关趋势预测等[2]。文本分类与文本聚类是文本数据挖掘的核心技术。然而在众多文本分类算法中,尚没有一种适合于政策文本分类的算法。本文通过对比三种字符串匹配算法的分类效果及计算消耗时间选取了一种适合政策文本分类的字符串匹配算法,并通过分析政策文本具有的特征提出一种相似度阈值计算的方法。
1 网页文本分类关键技术
1.1 网页文本内容提取技术
与普通纯文字文档相比,Web页面文本的结构具有多样性,Web页面是半结构化数据。Web页面的基本结构是DOM(Document Object Model,文档对象模型)结构[3]。由于HTML语法灵活多变,大部分Web页面的设计很可能不符合W3C规范,可能在进行页面解析时影响解析结果。要想研究Web页面的主要内容,就必须在解析HTML页面的时候排除不相关信息的干扰。
本文使用一款完全开源的HTML页面解析器J-soup框架来完成从HTML到文本转化的过程。J-soup能够准确的解析Web页面并将HTML转换为Dom树结构。程序初始规定所有抓取的页面符合Web浏览器创建文档所使用的模型规则。开发者可以根据自己的需求来自定义匹配规则,避免浪费资源提高程序效率。
1.2 特征词提取技术及加权方法
Web页面文本分类的前期处理工作即文本内容抓取、干扰去除,之后关键的部分就是文本特征词的提取。一个好的特征词抽取算法可以有效的避免数据不平衡的现象,提高数据利用率和分类的准确性[4]。
本文采用中科院研究的NLPIR汉语分词系统中关键词抽取功能进行文本关键词的抽取,该系统的关键词提取技术得到了普遍认可。加权算法采用文本分类中普遍采用的TF-IDF权重计算方法[5]。
1.3 字符串匹配算法的优缺点
常用于文本分类的字符串匹配算法有编辑距离相似度算法、Jaro-Winkler Distance算法及余弦相似度算法。
(1)编辑距离相似度算法思想简单易于实现,所以在文本分类中得到了普遍使用。但编辑距离相似度算法是根据两个字符串之间相互转换需要的步骤多少来确定相似度的,在计算相似度较高的字符串之间的相似度时,计算结果区分度不高。而且在涉及专业词汇的相似度计算时其准确率往往很低[6]。
(2)余弦相似度算法准确率虽然较高,但是由于该算法计算中涉及较多分词对比计算,所以会消耗大量时间[7]。在数据量较大时,使用余弦相似度计算字符串之间的相似度的时间将会量级增长,这远超于用户接受范围[8]。
(3)Jaro-Winkler Distance算法在编辑距离相似度算法的基础上进行了改进,在计算相似度时,规定两个分别来自字符串S1和字符串S2的字符之间的距离即Distance不能超过公式(1)计算结果,很大程度上提高了相似度计算的准确率[9]。然而由于该算法是基于编辑距离相似度算法进行改进的,其计算结果区分度不高的局限性仍然存在[10]。

(1)
通过对比三种字符串匹配算法的准确率及计算消耗时间本文选取Jaro-Winkler Distance算法作为政策文本分类中的字符串匹配算法。
2 基于特征词加权的相似度阈值计算方法
基于特征词匹配的文本分类算法的关键在于字符串匹配算法的选取,而字符串匹配算法的主要难题就是相似度阈值计算[8]。本文基于特征词加权提出一种计算相似度阈值的方法:首先对训练集C1中抽取的特征词进行加权,权值计算方法为TF-IDF,并将所有特征词入库得到文本特征词库K1;为了体现特征词的普遍性(聚合性),对样本集C2进行聚类,将C2分为若干个样本集C21,C22,C23…C2n(n为C2聚类后的子样本集个数),对若干个样本集中抽取的特征词加权并入库得到样本词库K21,K22,K23…K2n。
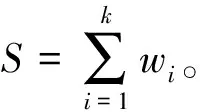
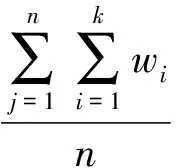
(2)
本文规定在计算相似度之合S1,S2,S3…Sn时,结合特征词的权值不同给每个特征词的相似度乘上不同的系数。图1为特征词的权值分布图:
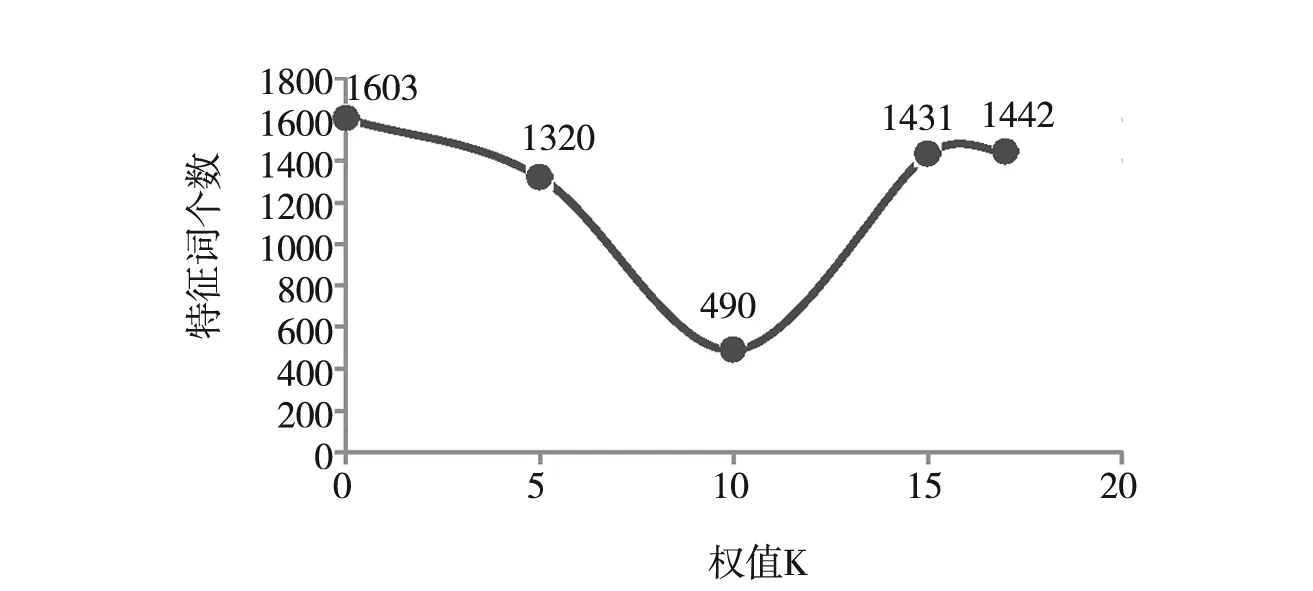
图1 特征词的权值分布图
根据权值分布,分别给权值在0-5和13以上的特征词的相似度赋予系数(1+ρ)(0<ρ<1),权值在6-12之间的特征词的相似度赋予系数(1-ρ)。则公式(2)可变为:

(3)

考虑到特征词权值越大越具有代表性,ρ越大权值大的特征词在阈值计算中所占比重越大,所以ρ取允许范围内的最大值0.9,根据公式(3)计算得出W为0.8(计算精确到0.1)。
从样本集抽取200条政策与训练集进行匹配。当特征词的相似度发生变化时,匹配数量与相似度关系如图3所示。

图2 系数ρ与阈值W关系图

图3 匹配数量图
通过观察实验数据发现,当W取0.8时,能够将测试集文本分类且大部分文本被认为相似,符合一般规律,满足分类要求。
3 文本分类算法研究与实现
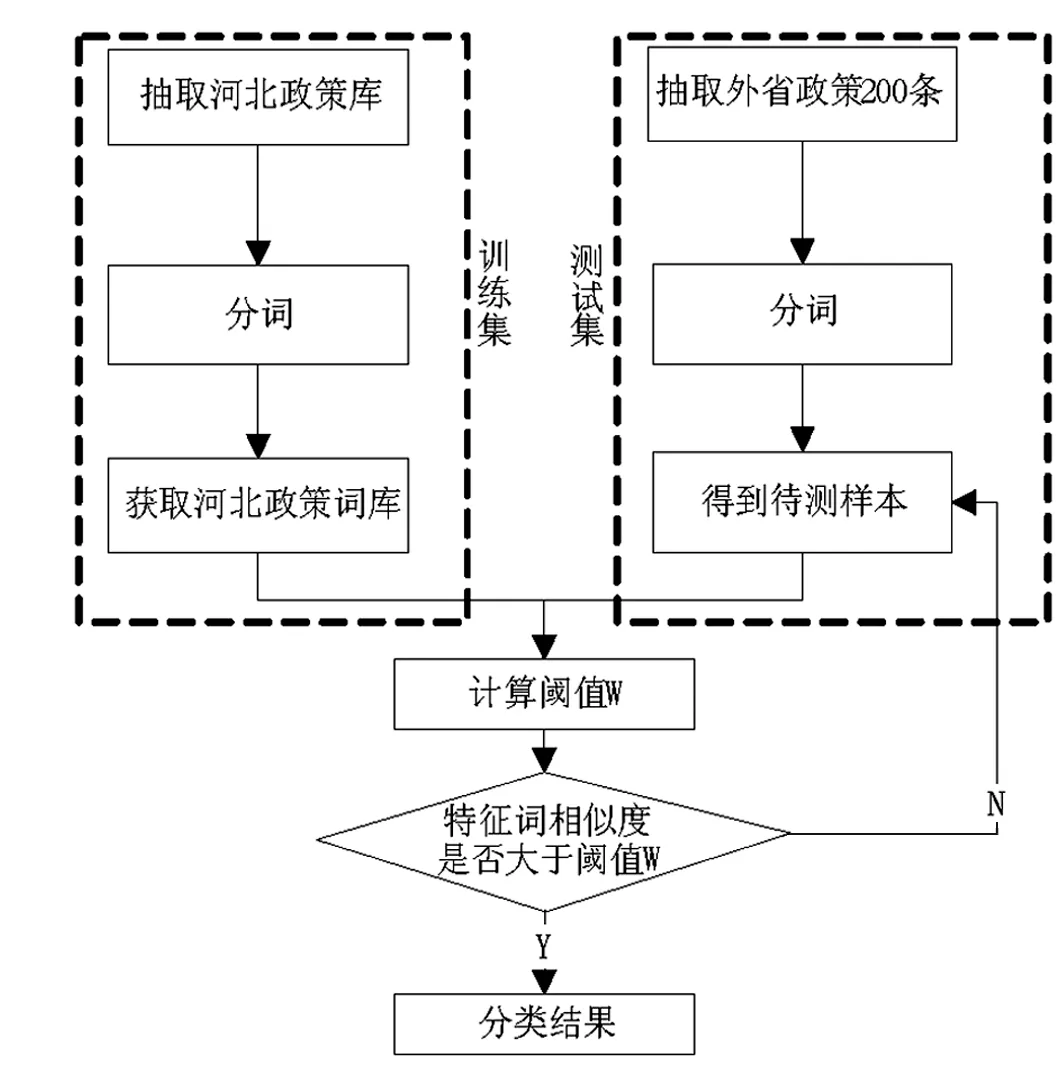
图4 政策文本分类算法流程图
将网页文本抓取入库后,抽取所有河北省数据作为训练集。首先通过NLPIR汉语分词系统将文本碎片化为河北政策语料库。然后通过模糊查询模拟聚类结果得到200条其他省的政策文本并抽取文本特征词作为测试集,将测试集词库与训练集词库(即河北政策词库)进行匹配分类。图4为分类算法流程图。
算法具体步骤如下:
从已经抓取的政策库中抽取所有河北政策文本作为训练集C1;
使用分词系统对河北政策文本进行分词得到河北政策词库K1;
使用加权算法给训练集词库中的特征词加权;
对数据库进行模糊查询随机抽取200条外省政策模拟聚类结果,得到测试集C2;
对测试集文本进行分词得到测试词库K2并计算特征词权值;
使用基于特征词加权的相似度阈值算法计算阈值W12;
使用Jaro-Winkler Distance算法计算训练集词库中所有特征词与测试集词库中所有特征词的相似度,根据阈值W12判定是否为相似(相似度小于W12为不相似,反之则认为相似)得到相似词库S12。
根据一个特征词唯一对应一条文本数据的性质遍历S12中所有特征词,取出C2中的相似文本得到相似文本集合C12。
4 实验设计与结果分析
4.1 实验环境介绍
Windows 7系统,Eclipse,Tomcat7.40,JDK1.8
4.2 实验结果的评估标准
文本分类结果评估指标使用信息检索中常用的标准,即查全率(Recall)、查准率(Precision):
查全率P=相似文本个数/ 测试集文本个数,即系统检索出相关信息的能力;
查准率R=相似文本个数/ 参与测试的文本个数,即系统拒绝非相关信息的能力。
综合指标F=2×R×P/(R+P),表示分类算法的综合分类效率。
4.3 实验数据准备
本文针对于政策文本进行分类,实验政策文本选自于河北人社厅、工信厅、科技厅、政府等11个部门下的政策法规栏目的政策文本。通过主题爬虫Web Magic将相关政策文本抓取入库并进行结构化整理。数据库中政策表的部分字段如表1所示。

表1 文本数据结构化表
图5 实验数据分布
本次实验数据是从已抓取的政策数据库中抽取,为了使实验更加具有普遍性因此选取了各个行业相关的政策文本作为实验数据集。
4.4 实验结果分析
三种字符串相似度算法对应的分类结果的准确率与时间消耗(查准率、查全率及分类时间分别用B、P和T表示)。实验一,比较三种字符串算法用于分类的性能。
由实验结果可知,在三种字符串相似度算法中Jaro-Winkler Distance算法时间消耗较少,准确率高,最适合用于政策文本分类。

表2 算法对比结果表
实验二,比较本文分类算法与传统分类算法对于政策文本分类的性能。

表3 算法分类效果对比表
由表3可知,本文改进算法在政策文本分类中性能优于传统分类算法,满足实际需求。
5 总结
本文首先介绍了文本分类的研究背景和相关研究现状,然后对普遍用于文本分类的三种字符串匹配算法进行了分析及比较实验,选取了最适合政策文本分类的字符串匹配算法,并提出了一种基于特征词加权的相似度阈值计算方法。然而对于不同类型的文本特征词出现的位置及数量也不同,如何高效的抽取一篇文本的特征词,抽取几个特征词能够恰当的代表一篇文本是一个值得研究的方向。由于该文只是抽取河北政策文本作为实验训练集数据,对于其他省市政策分类的系数还有待具体调整,如何恰当的选取值来适应不同地区政策分类也是一个有待研究的方向。
[1] 张强.网页内容获取及基于意图的聚类[D].北京邮电大学, 2010.
[2] 陆洋.基于语义分析的文本挖掘研究[D].浙江工业大学, 2011.
[3] 白凡.改进的K近邻算法在网页文本分类中的应用[D].安徽大学, 2010.
[4] 曾俊.结合SVM和KNN的Web日志挖掘技术研究方法[J].计算机应用研究, 2012, 29(5):1926-1928.
[5] 王艳, 张帆, 杨炳儒.基于Web挖掘的数字图书馆个性化技术研究[J].情报杂志, 2007, 26(1):37-38.
[6] 何锋, 谷锁林, 陈彦辉.基于编辑距离相似度的文本校验技术研究与应用[J].飞行器测控学报, 2015, 34(4):389-394.
[7] 吴凌芬,杨小渊,叶添杰,刘冰,王太宏.改进Jaro-Winkler算法在迎宾机器人语音交互中的应用[J].现代计算机(专业版),2015,(08):8-13.
[8] 彭凯, 汪伟, 杨煜普,等.基于余弦距离度量学习的伪K近邻文本分类算法[J].计算机工程与设计, 2013, 34(6):2200-2203.
[9] 卢苇, 彭雅.几种常用文本分类算法性能比较与分析[J].湖南大学学报(自科版), 2007, 34(6):67-69.
[10] 刁力力, 王丽坤, 陆玉昌,等.计算文本相似度阈值的方法[J].清华大学学报(自然科学版), 2003, 43(1):108-111.
Researchandimplementationoftextcategorizationalgorithmbasedonfeaturewordmatching
WANGLi-peng,ZHANGPeng-yun,HEZhi-qiang
(HebeiUniversityofEconomicsandBusiness,ShijiazhuangHebei050061,China)
In the text categorization algorithm based on the feature word traversal matching, the selection of the string matching algorithm and the similarity threshold control play a decisive role in the text classification result.In this paper, three commonly used string matching algorithms are analyzed and compared experimentally, then, a string matching algorithm which is most suitable for policy text classification is selected.Finally, a similarity threshold calculation method based on feature word weighting is proposed by studying the characteristics of policy text.It is proved that the similarity threshold can meet the classification requirement.
String matching algorithm;Threshold calculation;Text categorization
2017-09-20
河北省科技创新政策法规需求库建设研究(17960119D)
王丽鹏(1991-),男,河北邯郸人,硕士研究生,主要从事数据挖掘,高速数据采集研究.
1001-9383(2017)03-0001-06
TP391
A
