基于半监督学习和信息增益率的入侵检测方案
2017-11-07许勐璠李兴华马建峰
许勐璠 李兴华 刘 海 钟 成 马建峰
(西安电子科技大学网络与信息安全学院 西安 710071)(812455541@qq.com)
2017-06-11;
2017-08-03
国家自然科学基金项目(U170820014,61372075,U1135002,61672408) This work was supported by the National Natural Science Foundation of China (U170820014, 61372075, U1135002, 61672408).
李兴华(xhli1@mail.xidian.edu.cn)
基于半监督学习和信息增益率的入侵检测方案
许勐璠 李兴华 刘 海 钟 成 马建峰
(西安电子科技大学网络与信息安全学院 西安 710071)(812455541@qq.com)
针对现有未知攻击检测方法仅定性选取特征而导致检测精度较低的问题,提出一种基于半监督学习和信息增益率的入侵检测方案.利用目标网络在遭受攻击时反应在底层重要网络流量特征各异的特点,在模型训练阶段,为了克服训练数据集规模有限的问题,采用半监督学习算法利用少量标记数据获得大规模的训练数据集;在模型检测阶段,引入信息增益率定量分析不同特征对检测性能的影响程度,最大程度地保留了特征信息,以提高模型对未知攻击的检测性能.实验结果表明:该方案能够利用少量标记数据定量分析目标网络中未知攻击的重要网络流量特征并进行检测,其针对不同目标网络中未知攻击检测的准确率均达到90%以上.
入侵检测;未知攻击;特征选取;半监督学习;信息增益率
随着基于网络的计算机服务及应用的快速发展,其安全问题日益凸显.如何利用入侵检测系统(intrusion detection system, IDS)来保护物联网、工控网络等免受入侵,成为当前网络安全防御的一个关键问题.IDS作为监视和分析主机或网络事件的一种系统,可以用于识别与正常主机/网络行为的偏差.当前最常见的IDS可以分为基于误用的和基于异常的2类[1].其中,基于误用的IDS可以有效地检测已知攻击,例如最著名的开源系统Snort[2].这类IDS对已知类型的攻击具有较低的误报率,但是它无法识别出网络上新的或未知的攻击类型.而基于异常的IDS通过构建一个正常主机/网络行为的模型,然后将与该模型有任何显著偏差的行为判定为入侵.这种类型的IDS可以检测新的或未知的攻击,但是存在误报和漏报率较高的问题.
为了降低基于异常的IDS的误报和漏报率,研究者借用机器学习技术能够在大量数据中提取特征的优势,通过采用不同的特征选取方法对目标网络的网络流量特征进行选取,并结合监督学习算法检测网络中的未知攻击.当前方案对未知攻击的检测均具有较高的检测性能.然而,现有研究仍存在3种问题:
1) 当目标网络遭受攻击时,体现在底层的网络流量特征的重要程度各不相同,即不同网络流量特征的权重各异.然而,现有未知攻击检测方法均仅从定性的角度选出重要网络流量特征,采用启发式算法在全部的特征中搜索使分类结果最优的特征子集来选择最终的分类特征,并结合监督学习的方法进行检测,而忽略了大量未选取特征中包含的分类信息,从而导致了检测模型较高的漏报率.
2) 目标网络所遭受的未知攻击也可能是随时间的推移动态变化的,而不同的攻击所表现出来的底层重要网络流量特征也不尽相同.因此,如何自适应地选取重要的网络流量特征并进行定量分析是当前未知攻击检测的另一大挑战.
3) 现有基于机器学习的未知攻击检测方法均需要利用大量的已标记数据进行训练.然而,在实际攻击场景中,每条标记数据都需要利用专家知识人工生成,从而导致训练数据集规模非常有限,即已标记数据量较小.有限规模的训练数据集进一步地降低了模型的检测精度.
针对上述问题,本文提出一种基于半监督学习和信息增益率的入侵检测方案.主要贡献有3个方面:
1) 针对未知攻击流量特征难以定量选取的问题,引入信息增益率确定不同特征对检测性能的影响程度,减少数据中冗余及噪声特征的干扰,并将已检测数据逐条加入训练数据集以实时更新模型,从而定量选取重要的网络流量特征,提高检测模型的泛化能力,自适应地应对目标网络中的未知攻击.
2) 针对目标网络准确训练数据少的问题,提出了一种基于半监督学习的数据标记方法,利用改进的k-means算法来标记特征相似的数据,在少量人工标记数据的基础上实现了大规模准确标记训练数据集的生成,保证了模型的检测精度.
3) 分别在NSL-KDD[3]数据集和密西西比州立大学关键基础设施保护中心提出的标准数据集[4]上进行了对比实验,并对不同时间段的网络流量特征进行定量提取,验证了本方案的有效性.
1 相关工作
1.1非机器学习的攻击检测
Delgado[5]基于2个参与者都有有限理性和有限战略推理的假设,提出了一种识别无线传感网络恶意节点的入侵检测系统,将恶意节点之间的相互作用建模为一个进化博弈,结果表明:设计的方案可以有效地检测恶意节点,同时提高资源的利用率;Guo等人[6]提出了一种面向多协议的中间件入侵检测方法,为无线传感网络的任何路由协议生成所有已知攻击类型,并自动生成规则进行检测,实验结果表明该方法具有较高的检测率;Jeffrey等人[7]设计了一个基于云系统安全的网络攻击博弈框架,利用传统的信号博弈来建模云和设备之间的内在关系,并采用Flipit博弈来建模攻击者和防御者之间的博弈;Fronimos等人[8]根据可用性和性能标准评估了3个低交互蜜罐(low interaction honeypots, LIHs),并进一步讨论了基于LIHs的网络攻击早期特征发现方案.
然而,现有非机器学习的攻击检测方案更多集中于对已知攻击的检测,并且在处理大数据方面无能为力,难以检测未知攻击.
1.2基于机器学习的未知攻击检测
由于机器学习的方法在处理大数据上具有明显的优势,研究人员针对基于机器学习的入侵检测开展了大量研究,其基本思想是利用网络流量异常检测或主机恶意行为异常检测提取底层原始数据特征进行分析,以检测出攻击.
Taeshik等人[9]针对现有支持向量机(support vector machine, SVM)的检测方法误报率较高的问题,提出了一种基于非监督学习的改进SVM模型,通过自组织映射网方案构建初始的数据包流量特征,并通过被动TCP/IP指纹识别方法过滤不完整的流量信息,最终通过使用遗传算法从KDD99数据集中分别提取了15,17,18和19个特征进行对比检测,实现了一个非监督学习的SVM模型;Haq等人[10]考虑入侵检测系统的检测效率,通过对比3种特征选择方法:最佳优先搜索、遗传搜索以及排名搜索,从NSL-KDD数据集中分别提取5,12,24个特征,并分别对比在若干种机器学习算法上的表现,说明特征选择在入侵检测系统中起着至关重要的作用;Kanakarajan等人[11]提出了在大规模恶意活动的基础设施环境下基于贪婪随机的自适应搜索过程和随机退火算法,使用特定的特征选择方法分别在二分类和多分类问题中选取了NSL-KDD数据集中8,19,32和10,18,23个特征结合机器学习算法进行检测,结果表明,检测性能远高于其他算法,并且检测速率也大幅度提高;Lin等人[12]提出了一种新颖的特征表示方法,称为聚类中心和最近邻方法CANN,该方法通过衡量数据和其聚类中心的距离来构造一维距离的特性,使用该特性进行后续的分类,并使用现有的特征选择方法进行特征提取有效地提高了检测率和检测速度;Liu等人[13]针对大多数现有的入侵检测模型由于仅具有单层结构而导致模型仅能检测滥用或异常攻击中的一种的问题,提出了使用层次入侵检测模型并利用主成分分析(principal component analysis, PCA)神经网络克服这种短缺.在提出的模型中,PCA应用于特征降维,将高维度特征映射至低维度的新特征,并结合神经网络实现了对复合攻击的检测.
以上方案均在未知攻击检测性能方面取得了显著成果.然而,当前基于机器学习的未知攻击检测方案均仅从定性的角度结合专家知识人工选取重要的网络流量特征,而忽略了大量未选取特征所包含的分类信息,导致了特征信息的损失,限制了模型的检测精度.同时,由于目标网络所遭受的未知攻击也可能是随时间的推移动态变化的,而不同的攻击所表现出来的底层重要网络流量特征也不尽相同,上述方法难以应对动态变化的未知攻击.此外,现有研究均以训练数据集规模足够大为前提进行研究,如上述研究均以公开数据集KDD99或NSL-KDD为实验数据集,但是在实际网络攻击场景中准确训练数据集的规模都是非常有限的.
因此,本文提出了一种基于半监督学习和信息增益率的入侵检测方案,在降低准确网络流量数据标记成本的同时自适应地定量选取网络流量特征,消除传统特征提取方法人为因素的影响,尽可能多地保留特征的分类信息,以准确检测网络中的未知攻击.
2 我们的方案
为了应对未知攻击检测中网络流量特征难以自适应地定量选取和训练数据集规模有限的挑战,本方案首先采用半监督学习的方法,利用少量已标记数据生成大规模的数据集以训练模型,之后引入信息增益率对检测模型中划分的每个子数据集进行特征提取,以实现对未知攻击的准确识别.
未知攻击方式虽然各异,但其最终均可反应到底层网络流量数据中,因此本方案采用2014年发布的数据集中常用的网络流量特征,如表1所示,其中包括Command_address,Response_address等.本方案对数据集进行归一化处理,以减小特征之间量纲的影响,即保证每个特征的重要程度不受数值的影响.本方案利用min-max标准化法,将数据的大小范围缩小到[0,1]之间,具体计算为
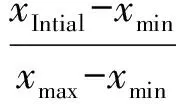
(1)
其中,xNormalized是某一特征归一化后的值,xIntial为特征初始的属性值,xmin是该特征的最小值,xmax是该特征的最大值.如一条数据N1(4,4,183,233,9,18,3,10,3,10,0,41,19,2,0,0,0.528 735 637 664 795,1.106 867 654 990 64,0)经过归一化后为N1(0.016 064,1,0.717 647,1,1,1,0.157 895,0,1,1,0,0,0,1,0,0,0.397 213,0.356 227,0).
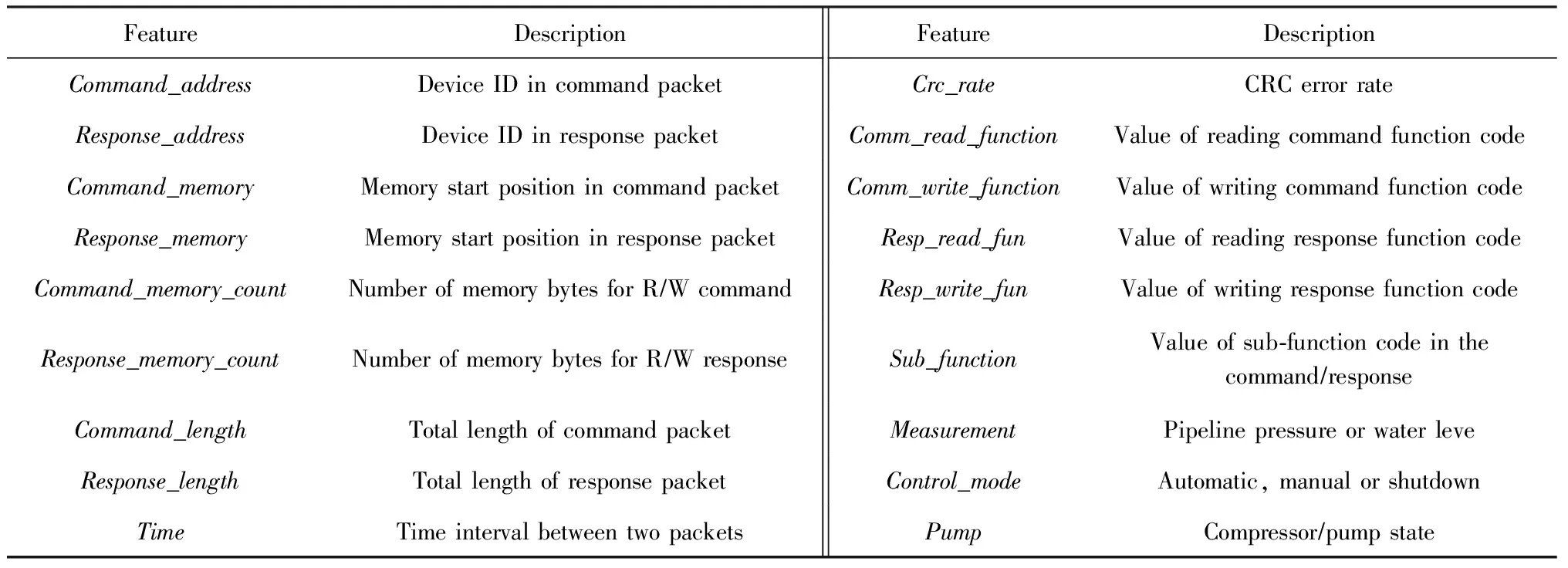
Table 1 Network Traffic Features
2.1基于半监督学习的训练集生成
由于在未知攻击检测中目标网络的历史网络流量数据量巨大,依赖专家知识进行人工标记只能得到少量准确标记的数据作为训练样本,这使得训练出的模型无法准确检测攻击[14].半监督学习则是针对这类问题提出的,即利用少量具有先验知识的数据来辅助无监督学习[15-16].为了实现对历史数据的自动标记并获得更大规模且准确标记的训练数据集,本文提出改进的k-means半监督学习算法,如图1所示:
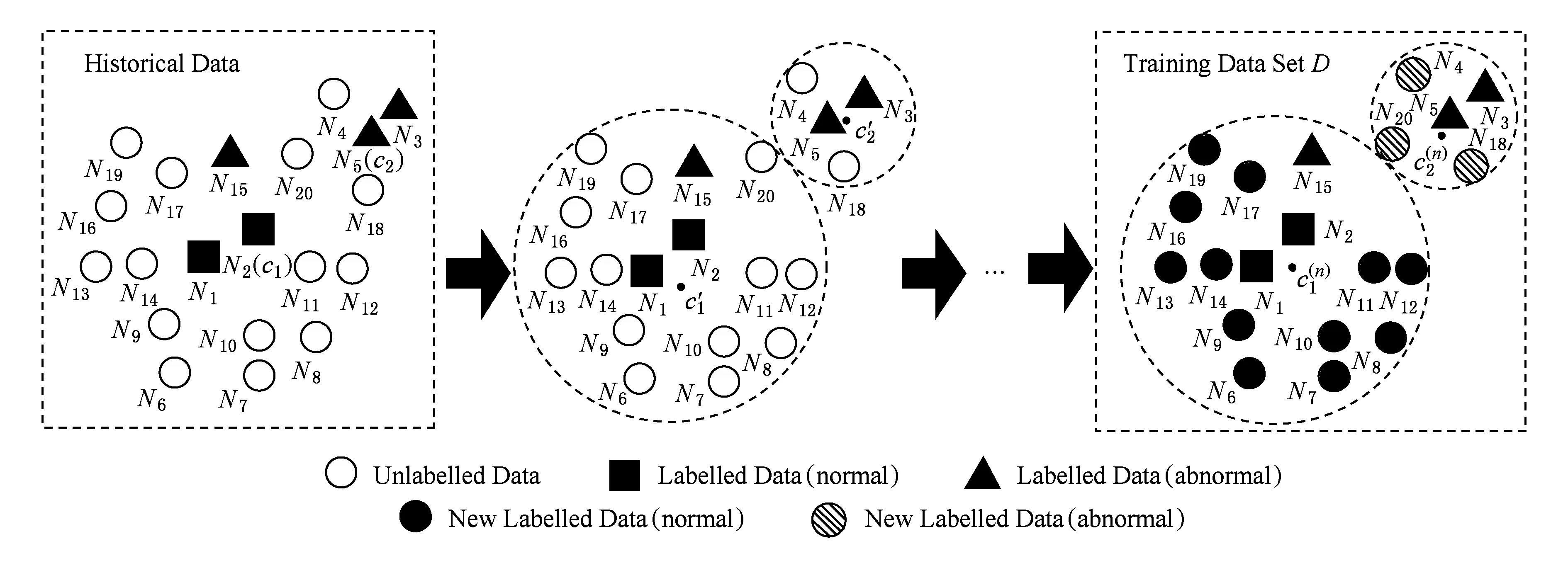
Fig. 1 History of network traffic data labelling based on semi-supervised learning图1 基于半监督学习的历史网络流量数据标记过程
1) 在已标记的正常和异常数据中分别随机选取一条数据作为簇的中心,图1中选取N1,N5作为已标记数据(正常)簇和已标记数据(异常)簇的簇心c1,c2;
2) 利用式(2)计算每条数据Ni分别与簇心c1,c2的距离(相似度)d(Ni,ck),并将d(Ni,ck)值小的数据划分到一个簇内;
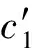
4) 重复步骤2),3)直至总的簇内离散度总和J达到最小时停止,其中离散度总和为每条数据Ni到其对应簇心ck的距离d(Ni,ck)的总和;
5) 计算每类已标记数据在每个簇中出现的概率Pl,k,并以Pl,k最大时的l标记簇k的类别,最终得到训练数据集D.
具体计算为
(2)
(3)
(4)
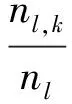
(5)
l=arg maxPl,k,
(6)
其中,Ni,m表示第i条数据的第m个特征值,如N1,1=1.6064×10-2;ck,m表示第k个簇心的第m个特征值,m为网络流量特征的个数,本方案中m=18;I为数据集中样本总个数;I′为簇k中数据样本总个数,如图1所示,I=20,训练数据集D的簇1中I′=15;d(Ni,ck)表示数据Ni到簇中心的欧氏距离,用来描述其相似度的大小;由于本方案将数据集划分成2个簇,因此k=1或2;Pl,k表示第l类已标记类在第k个簇中出现的概率(l=0或1,0代表正常类,1代表异常类),nl,k表示第l类已标记样本在第k个簇中的数量,nl表示第l类已标记样本的总数量,因此当Pl,k最大时用l标记簇k的类别;arg maxf(x)表示满足函数f(x)最大时自变量x的取值.例如在图1中,正常已标记类在簇1中出现的概率P0,1=1,异常已标记类在簇1中出现的概率P1,1=0.33,P0,1>P1,1,因此将簇1标记为0,即簇1为正常类.同理,在簇2中P1,2=0.67,P0,2=0,因此簇2标记为1,即簇2为异常类.
本节成功利用少量已标记样本生成更大规模的训练数据集D,并用于检测模型的训练.
2.2基于信息增益率的流量特征提取
在基于机器学习的IDS中,随机森林算法由于具有优良的泛化性能,相对于其他分类算法对攻击的检测更有优势,使得其成为当前攻击检测普遍选取的基准算法[17].然而,目标网络所遭受的未知攻击可能不同,而不同的未知攻击所反应在底层的重要网络流量特征也是各异的.因此,需要定量选取最有助于划分数据样本的特征.
一个特征能够为分类模型带来的信息越多,该特征越重要[18],模型中它的有无将导致信息量发生较大的变化,而前后信息量的差值就是这个特征给模型带来的信息增益[19].为了在构造决策树的过程中选取更具有代表的特征,在本方案中引入信息增益的概念并用信息增益率来衡量给定的特征区分训练样例的能力,如图2所示.
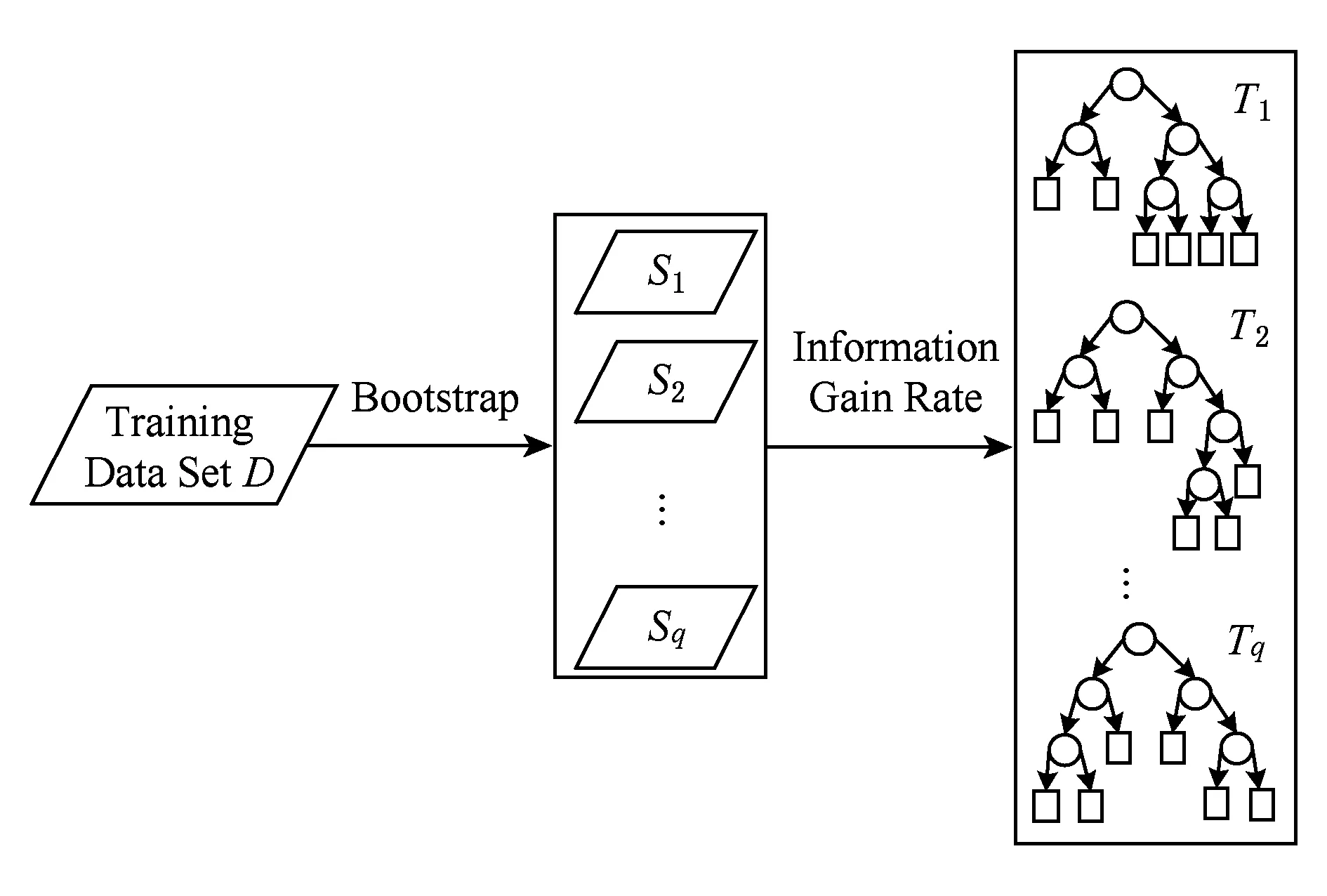
Fig. 2 Traffic features extraction based on information gain ratio图2 基于信息增益率的流量特征提取
设2.1节中生成的训练数据集D中含有I个不同的数据样本{N1,N2,…,NI}.首先利用Bootstrap重采样算法,每次有放回地从集合D中抽取一个数据样本,一共抽取I次,除去重复的数据,得到一个子训练集S1,重复此步骤q次,得到q个子训练数据集{S1,S2,…,Sq}用于生成q个不同的决策树以构建随机森林.其中,生成每棵决策树Tq的具体步骤如下:
1) 选取信息增益率最大的流量特征作为决策树的根节点;
2) 找到选取的特征所对应数据集Sq中使该特征最快分裂到叶子节点的阈值,对该节点进行分裂;
3) 在每个非叶子节点(包括根节点)选择特征前,以剩余特征作为当前节点的分裂特征集,选取信息增益率最大的流量特征作为根节点分裂的非叶子节点;
4) 重复步骤2),3)直至每个特征都对应有叶子节点为止,构建出Sq对应的决策树Tq.
具体计算为
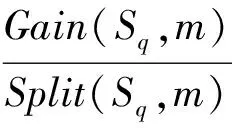
(7)
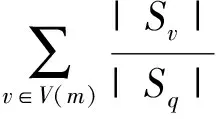
(8)
(9)
(10)
其中,Sq为通过Bootstrap重采样随机选取的训练数据集D的子集:GainRatio(Sq,m),Gain(Sq,m),Split(Sq,m)分别表示子数据集Sq的信息增益率、信息增益和分裂信息,V(m)是特征m的值域;Sv是集合Sq中在特征m上值等于v的子集;A表示特征m的属性总数;H(x)为数据集x的熵;pl为第l类样本数占总数据集的比例.
如图3所示,首先利用Bootstrap重采样算法从训练数据集中随机抽取了一个数据集Sq,计算数据集Sq中特征的信息增益率,假定得到特征Mea-surement的信息增益率最大,将特征Measurement作为根节点开始构建决策树Tq;然后根据数据集Sq中特征Measurement的属性值分布进行分裂,即找出合适的阈值划分数据集Sq.这里假定在数据集Sq中特征Measurement的分裂阈值为0.397,即在数据集Sq中的数据若其特征Measurement≤0.397,即划分为异常,若当Measurement>0.397,则进一步提取特征;当Measurement>0.397,选取剩余特征中信息增益率最大的特征Command_address作为第2个特征,同理找出分裂阈值;最后,重复上述步骤,直到将数据集完全划分为止.图3中,当特征选取到Pump时,数据集完全划分,此时决策树Tq构建完成.
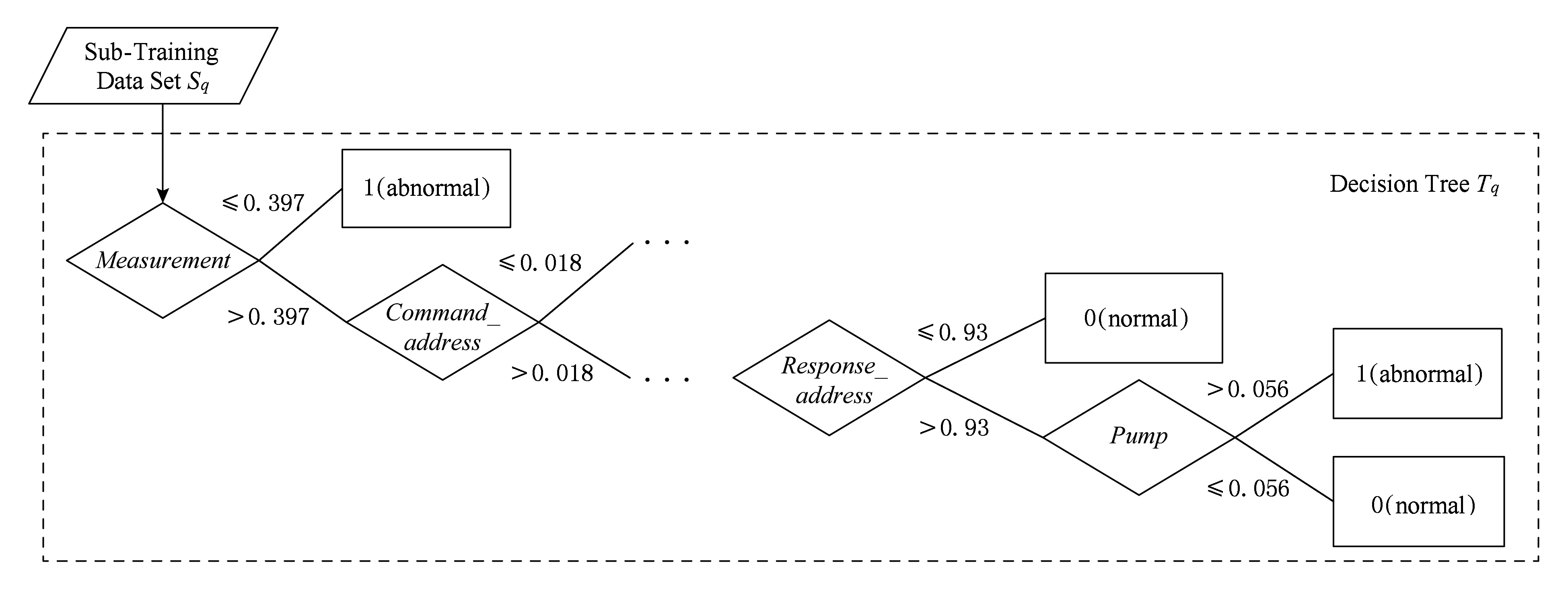
Fig. 3 Decision tree generation process based on feature extraction图3 基于特征提取的决策树生成过程
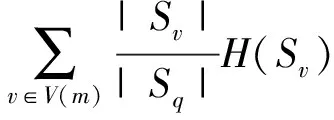
例如当一个含有I个流量数据的集合被特征A彻底分割(即分成I组,I>2),此时分裂信息为lbI;同时,存在一个布尔特征B分割同样的集合,如果恰好平分(I=2),则其分裂信息为1.此时,若仅采用信息增益而不是信息增益率来选取特征,则可以利用式(8)知道Gain(Sq,A)>Gain(Sq,B),从而选取特征A作为构建决策树的非叶子节点(根节点).然而,在实际中由于特征A具有较多属性值,将数据集划分为多个小空间,即每片叶子节点有可能仅包含单纯的正常和异常,此时决策树可以完美的拟合训练数据.但是,当测试数据集中出现有不属于特征A的属性值的数据时,所构建的决策树仍然仅通过特征A对测试数据进行分类,而不考虑其他特征,这必然导致模型的检测性能大幅度下降.因此,本方案引入了信息增益率来解决上述问题.根据式(6),显然特征B信息增益率更高,即优先选取特征B作为非叶子节点(根节点)构建决策树,从而避免了选取属性值多的特征A而导致模型对未知攻击检测能力的降低.因此,利用信息增益率作为一种补偿措施来解决信息增益存在的问题,引入分裂信息来惩罚上述属性值多的特征,以提高模型对未知流量检测的精度.
为了说明特征提取和决策树生成的过程.设Sq为通过Bootstrap算法从训练数据集D={N1,N2,…,N20}抽取的子数据集,Sq={N1,N2,…,N10},为了方便计算,选特征Command_address,Time进行对比,其特征的属性值如表2所示,其中数据类别正常异常用数字01表示,则Sq中正常和异常数据的个数分别为7和3.则特征Command_address的信息增益率计算为
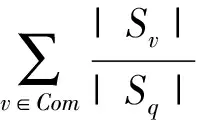
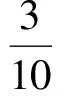
0.1923,

同理计算GainRatio(Sq,Time)=41.27%,可知特征比Time有更大的信息增益率,因此,优先选取特征Time作为构建决策树模型T1的非叶子节点.
Table2ThePropertyValuesandCategoriesoftheFeaturesCommand_address,TimefromN1toN10

表2 N1到N10特征Command_address,Time属性值及类别
2.3基于加权多数算法(weightedmajorityalgorithm,WMA)的攻击检测
由于每棵决策树都是利用Bootstrap算法去重后随机生成的子数据集构建,子数据集规模以及正常/异常数据分布较训练数据集D相比均发生变化,子数据集Sq的信息熵H(Sq)也随之改变,从而导致每个子数据集Sq所对应构建的决策树Tq对最终分类结果的影响程度也各不相同,标准RF中简单地将最多数决策树的分类结果确定为最终分类结果显然是不合适的.同时,在检测过程中测试数据是逐条通过模型进行检测的,由于每次检测都需要通过多次迭代对全部数据进行聚类而导致模型检测效率极低,无法满足实际环境中实时检测的需求,并且仅采用基于半监督学习的方法进行检测会由于其自身划分精度与分类算法相比较低.因此,若直接采用基于半监督学习的方法对数据进行检测标记会导致模型整体检测精度下降.
针对上述挑战,如图4所示,本方案引入加权多数算法给每棵决策树分配权值wq对网络流量数据进行检测,并分析子数据集Sq较训练数据集D在通过Bootstrap重采样算法去重后的集合规模以及数据分布的变化程度,以子数据集Sq较训练数据集D的信息增益Gain(Sq,l)衡量其对应生成的每棵决策树Tq对最终检测结果的影响程度.由于l只有0,1两类,根据2.2节中对信息增益的描述,不存在由于特征属性值过多引起的过拟合问题.因此,采用信息增益Gain(Sq,l)而不是信息增益率来衡量每棵决策树对最终检测结果的影响程度,具体计算为
Gain(Sq,l)=H(D)-H(Sq),
(11)
(12)

Fig. 4 Attack detection based on information gain using WMA图4 基于信息增益的WMA攻击检测
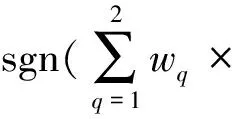
由于未知攻击随时间的推移,攻击方式可能动态变化,使得反映在底层的网络流量数据以及体现攻击的特征也随之改变.为了应对动态变化的攻击方式,本方案将检测完成的数据加入训练数据集中,并去除较早的数据,动态更新训练数据集以应对动态变化的攻击方式.
3 实验及结果分析
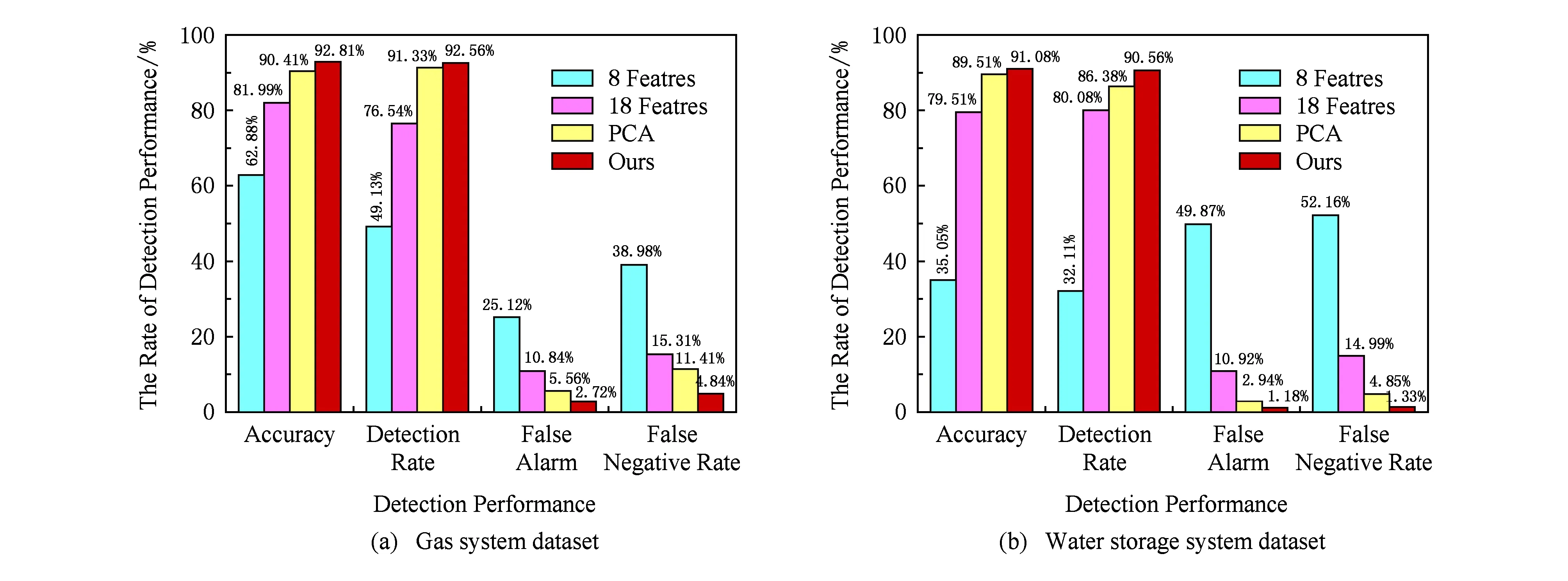
Fig. 5 Comparison of the effect of different datasets by using different features selection methods on detection performance图5 不同数据集特征选取方法对检测性能的影响对比
3.1实验环境
采用密西西比州立大学关键基础设施保护中心提出的标准数据集来评估本方案的检测性能.该数据集于2014年发布,是当前入侵实验中常用的标准数据集,其包含天然气传输和储水池2个控制系统遭受网络攻击的数据.其中,输气控制系统数据集采用gas_final.arff,共97 079条数据;储水池控制系统数据集采用water_final.arff,共35 774条数据.为了验证本方案在不同网络环境中对未知攻击的检测性能,采用目前公开的较大规模的基准数据集NLS-KDD对本方案的检测性能进行评估.实验环境为PC机(i5-4590主频3.3 GHz,内存为4 GB,操作系统为Win7 64 b),实验工具采用Python 2.7.
3.2实验结果分析
1) 方案的有效性分析
首先,分别选取2个系统中的特有特征和18个网络流量特征以及利用PCA对2个数据集进行特征选取并与本方案对比.其中,2个系统中的特有特征如表3和表4所示,PCA差分占比为95%.

Table 3 The Unique Features of Gas System Dataset
Table4TheUniqueFeaturesofWaterStorageSystemDataset(Differentwaterlevelintervalwhenthespecificwaterlevel)
表4储水系统数据集特有特征(不同水位区间时的具体水位)

FeatureDescriptionHHValueofHHsetpointHValueofHsetpointLValueofLsetpointLLValueofLLsetpoint
如图5所示,本方案在数据集[9]上的准确率、检测率、误报率和漏报率分别达到了92.81%,92.56%,2.72%,4.84%和91.08%,90.56%,1.18%,1.33%,这主要是由于不同的特征选取方法均在不同程度上丢失了数据集的原有信息,使得训练出的模型仅具有检测特定某种攻击的能力[20-22],而无法适用于对未知攻击的检测,尤其当特征数仅为各个系统的特有特征时,由于大部分数据信息丢失,数据集已经无法反映目标网络的底层数据流量特征,从而导致训练出的模型无法进行攻击检测.而本方案所采用的基于信息增益率的方法完整地保留了目标网络中数据集的初始信息,使得训练出的模型可以更好地反映目标网络的底层网络流量特征,具有更强的泛化能力以应对目标网络中的不同攻击.
其次,将本方案与标准RF,KNN,SVM算法进行对比.如图6所示.其中,本方案和标准RF分别取gas_final.arff和water_final.arff数据集的10%作为训练样本.
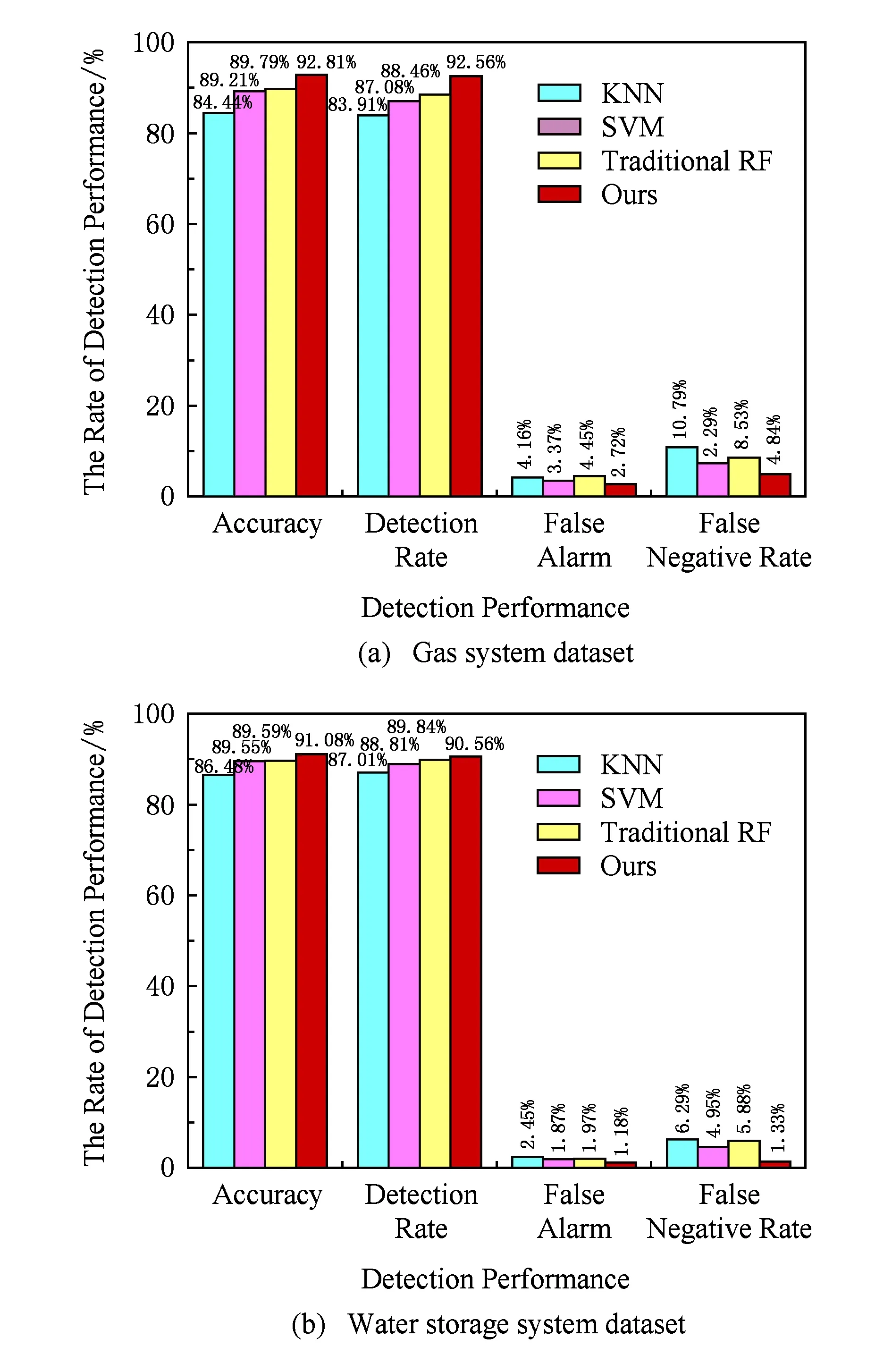
Fig. 6 Comparison of the effect of different datasets by using different algorithm on detection performance图6 不同算法对输气和储水数据集的攻击检测性能对比
与标准RF相比,本方案的漏报率分别降低了38.88%和40.11%.分析可知,这是由于本方案利用半监督学习算法使得模型具有足够的标记样本进行训练,保证了训练出的模型的有效性,从而具有较高的检测精度.
较SVM和KNN算法,本方案的检测率分别提高了6.29%,10.31%和1.97%,4.08%.这是因为本方案通过引入信息增益率选取了最能体现当前目标网络的流量特征,使得检测模型能够针对目标网络中存在的不同异常行为进行检测.同时,利用信息增益对不同决策树赋予权重并基于WMA得到最终检测结果,保证了不同决策树对模型检测性能的影响程度不同,使得模型不再单单依赖于标准随机森林算法中树的棵数的选取.因此,模型的检测精度大幅度提高.
之后,采用NSL-KDD数据集来评估本方案的检测性能,以验证本方案在不同网络环境中对未知攻击的检测能力,并与输气和储水系统数据集对比.如图7所示,本方案在2个数据集中均表现出对未知攻击优良的检测性能,其准确率均达到了90%以上,这验证了本方案具有检测目标网络环境中未知攻击能力的同时还可以检测不同网络中存在的未知攻击.
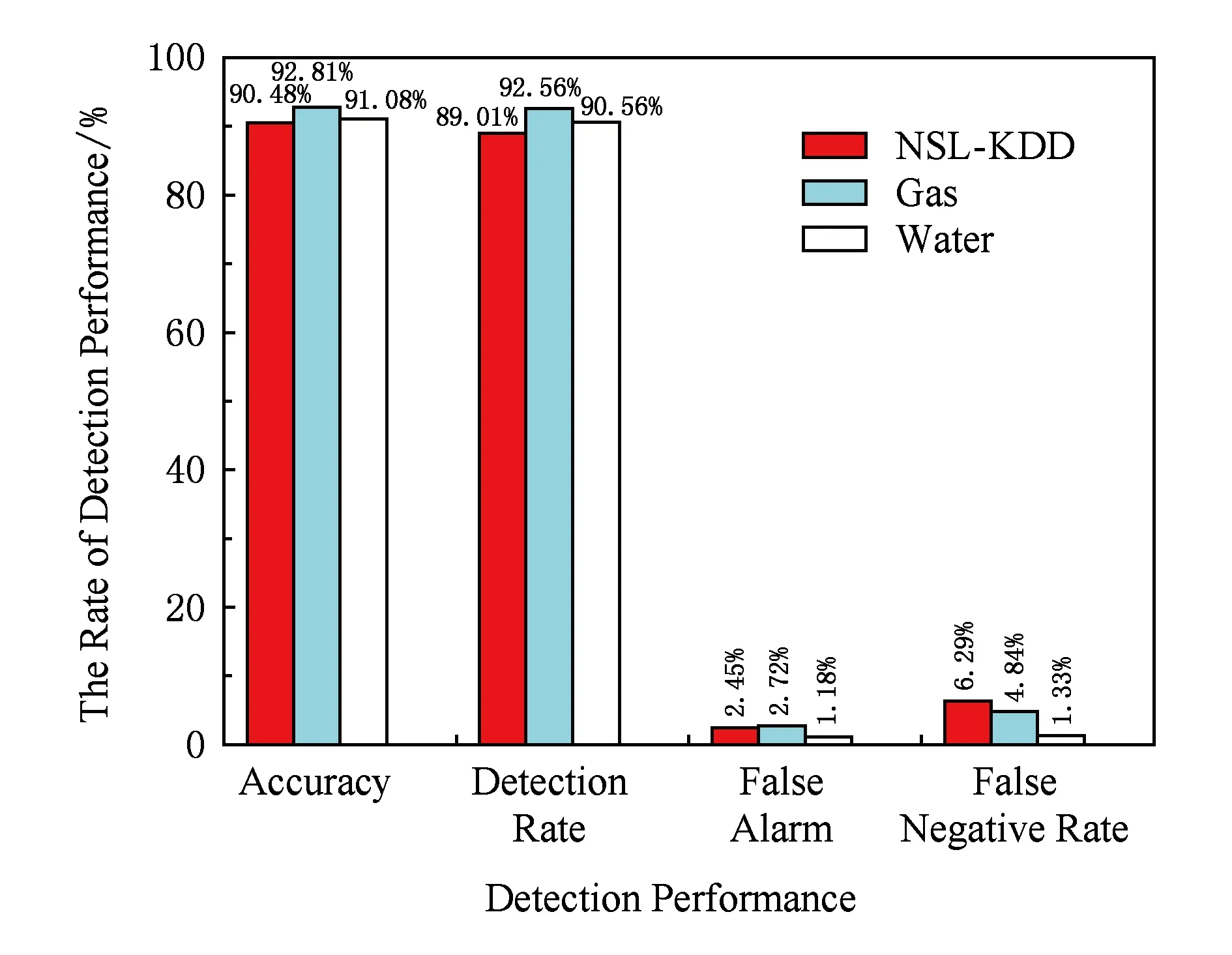
Fig. 7 Comparison of the effect of different datasets by using our scheme on detection performance图7 本方案在不同数据集中的检测性能对比
此外,为了验证不同初始聚类中心的选择对模型检测能力的影响,本方案分别在3个数据集中进行了1 000次实验,实验结果如图8所示:
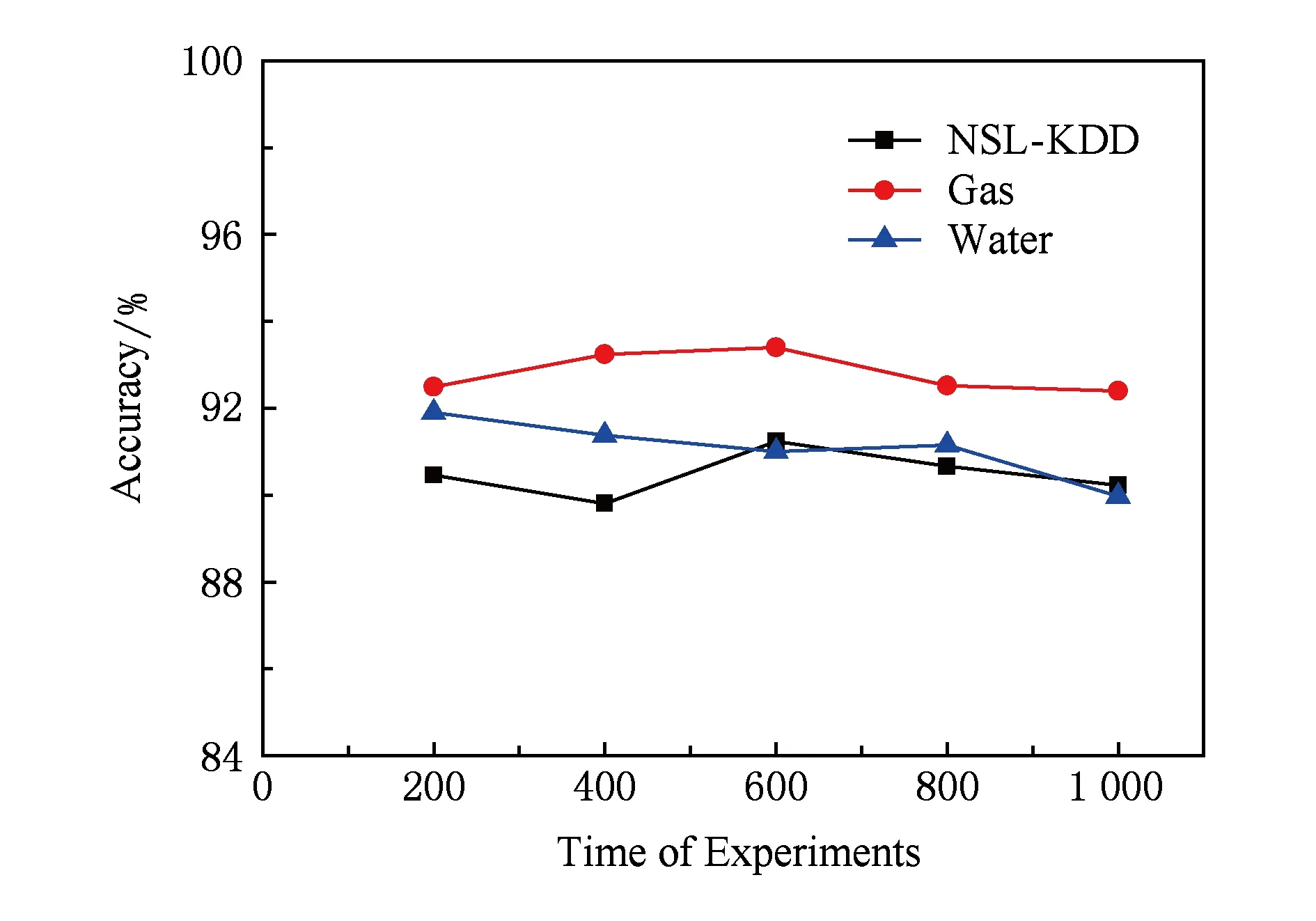
Fig. 8 Comparison of the effect of different initial cluster centers on detection performance(1 000 times)图8 不同初始聚类中心的选择对检测性能的影响(1 000次实验)
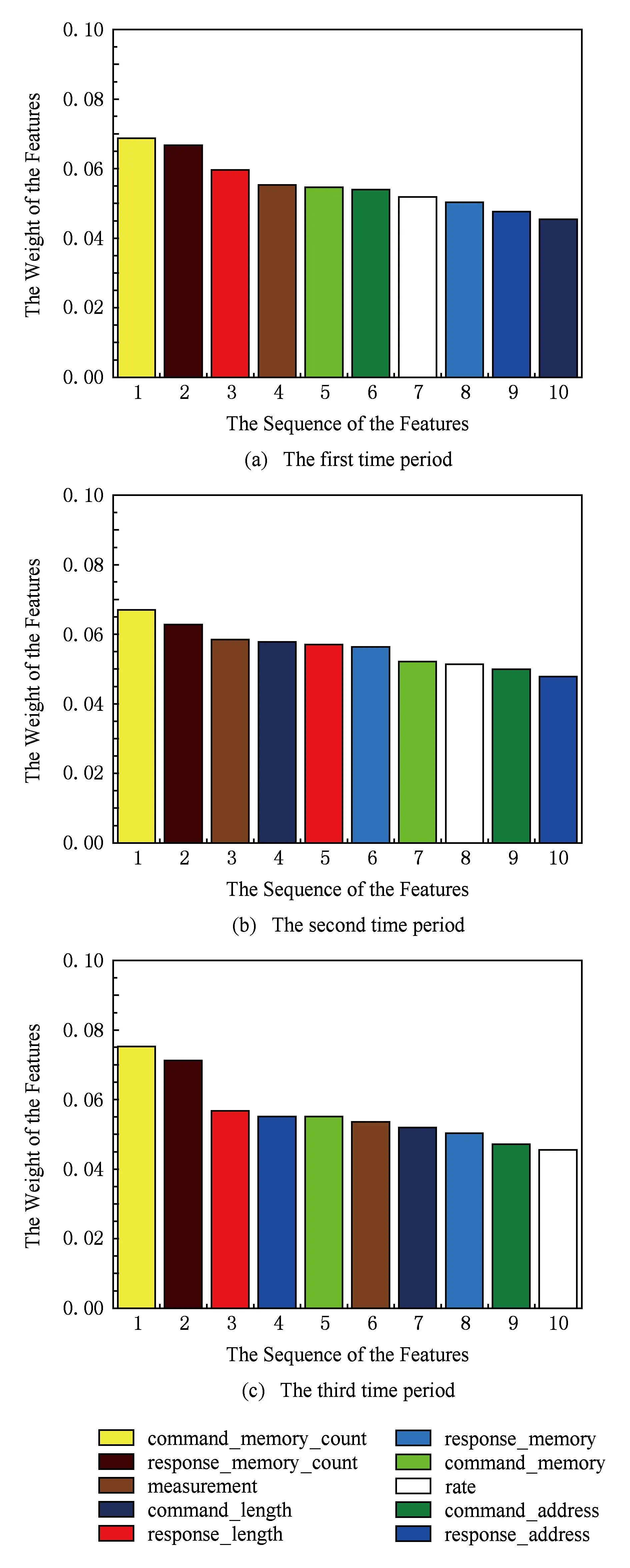
Fig. 9 The important features of the gas system dataset in the different time periods (10 before descending)图9 输气系统数据集不同时间段重要特征排序(由大到小前10位)
本方案在NSL-KDD和文献[9]中提出的3个数据集上的准确率分别在(89.80%, 91.24%),(92.40%, 93.40%),(89.97%, 91.90%),上下浮动均不超过2%.因此,我们认为在本方案中初始聚类中心的选择对于最终的检测精度影响较小.
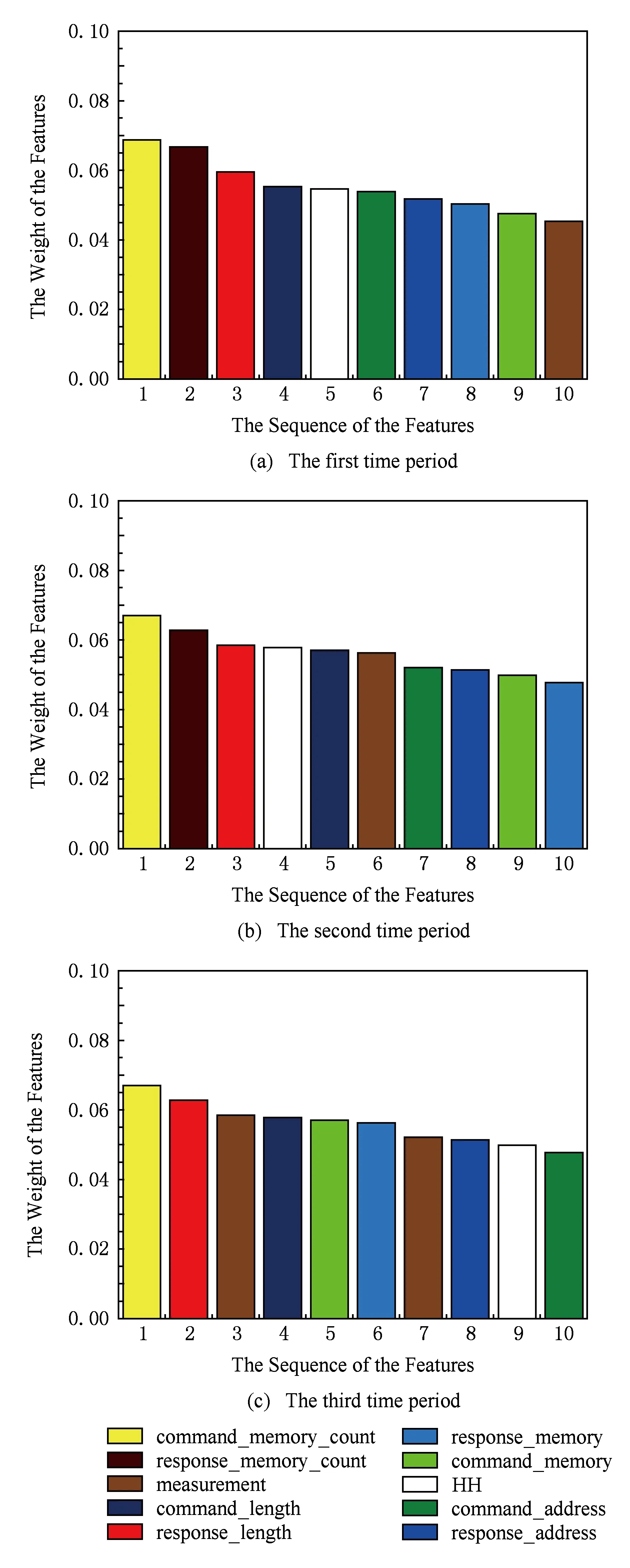
Fig. 10 The important features of the water storage system dataset in the different time periods (10 before descending)图10 储水系统数据集不同时间段重要特征排序(由大到小前10位)
最后,本方案将数据集[9]中的2个子数据集划分成3个时间段,通过分析不同时间段选取的重要特征,以验证模型应对不同目标网络中攻击动态变化的能力,实验结果如图9和图10所示:
如图9和图10所示,不同时间段模型检测提取的特征略不相同,即使相同特征在不同时间段的重要程度也有所不同.特征Command_address,Response_address,Command_memory,Response_memory,Command_memory_count,Response_memory_count,Command_length,Resp_length,Measurement在2个系统的不同时间段中均为重要特征,其中特征Command_memory_count在2个系统的3个时间段中的特征权重均为最高.这说明本方案区别于传统方案中根据检测结果人工筛选重要特征,能够计算不同目标网络底层网络流量数据在不同决策树中的信息增益,选取当前时间段权重最高的数据特征进行检测,最大程度地保留了数据特征中的信息,并通过计算权值定量地分析了各个时间段不同特征对模型检测的重要性,从而成功应对目标网络中攻击动态变化的特点.
2) 决策树个数对检测性能的影响
如图11所示,当决策树个数分别为q=400和q=350时,检测的准确率达到最高92.81%和91.08%,此时模型检测花费的时间分别134 s和97 s,当q值大于上述阈值时,检测精度趋于稳定,而检测花费时间大幅度上升,使得模型无法保证对未知攻击检测的实时性.其中,决策树个数q是影响模型性能和效率的一大主要因素,当决策树个数q较小时,模型的检测精度较差.另外,由于随机森林具有不过拟合性质,因此可以使q尽量大,以保证模型的检测精度.但是模型的复杂度与q成正比,即q过大,模型检测时间花费过大.
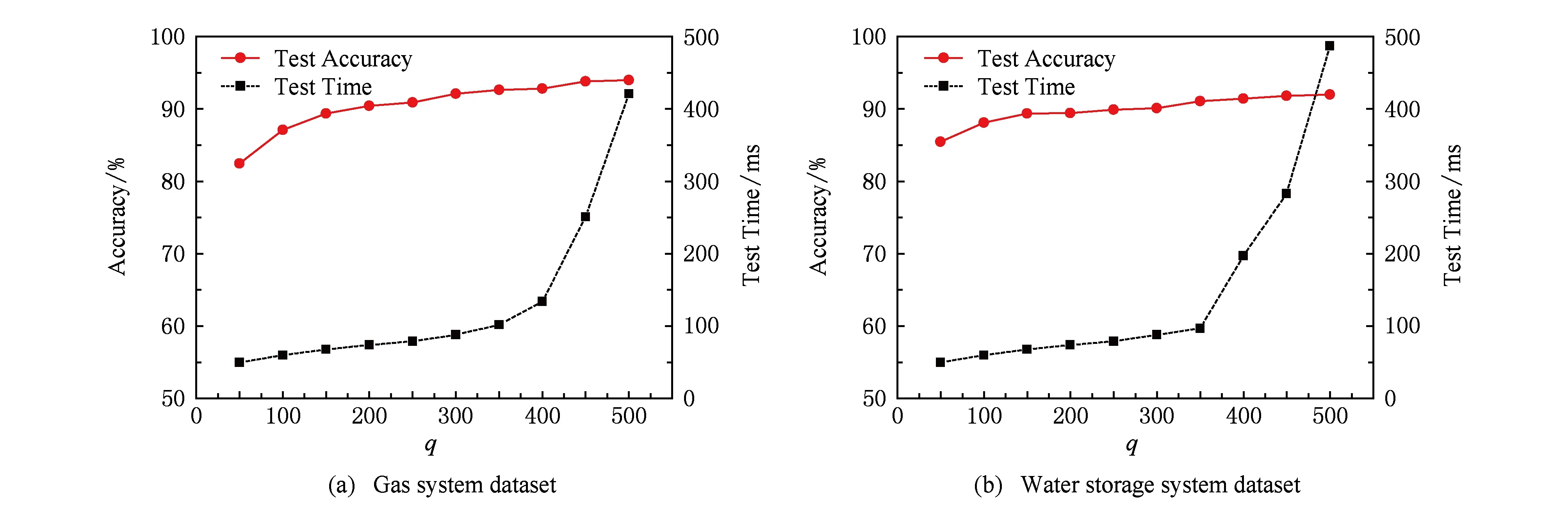
Fig. 11 The effect of the number of decision trees q on the detection accuracy and the model detection time图11 决策树个数q对检测准确率和模型检测时间的影响
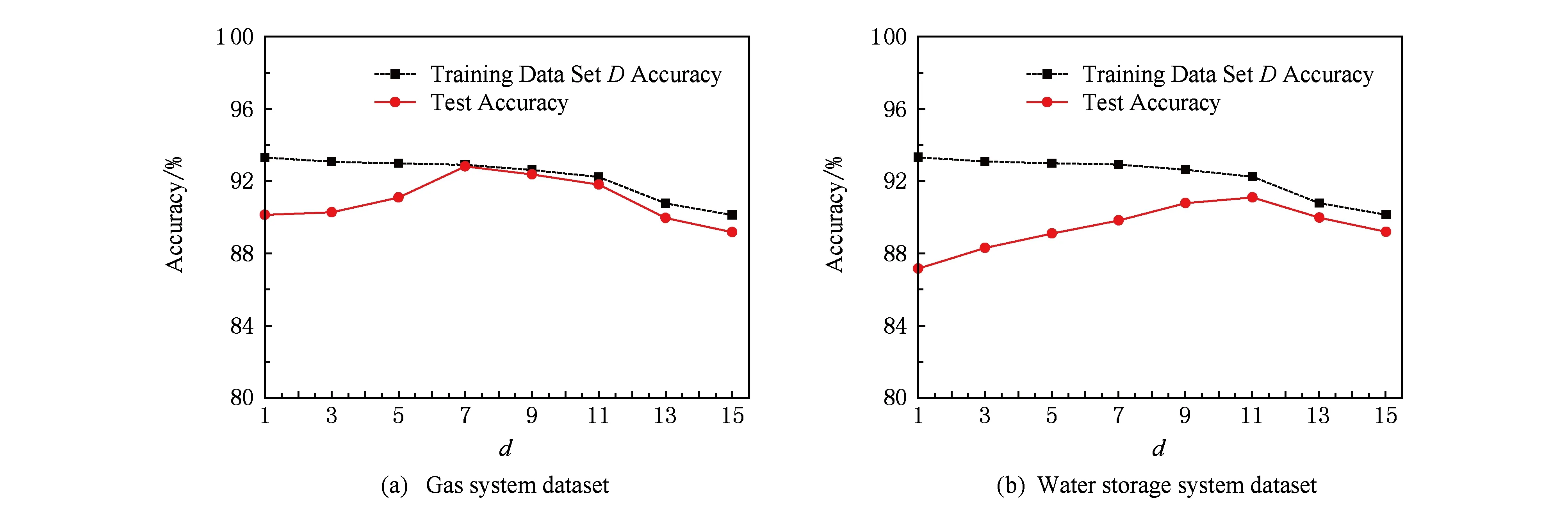
Fig. 12 The detection rate of the model under different d values and the accuracy of the training data set D图12 不同d值下的模型检测率与训练数据集D准确率
3) 不同规模初始训练数据集对检测性能的影响
如图12所示,本方案设已标记准确数据与未标记历史数据的比例为1∶d,其中d表示未标记历史数据的规模.从图12中可以看出,训练数据集D的准确率随d值的增大逐渐下降,而模型检测的准确率随d值的增大呈先上升后下降的趋势,分别在d=7和d=11时达到最大值92.81%和91.08%.这是由于当d值过小时,用于训练模型的数据不足而导致模型检测精度不高;而当d值过大时,由于生成的训练数据集D已经不够准确,而导致训练出的模型自身准确率过低.因此实验选取分别选取d=7和d=11构建训练数据集D.
4) 自适应检测过程中不同规模训练数据集对检测性能的影响
在初始训练数据集规模确定的基础上,本文进一步研究了在自适应检测过程中训练数据集的规模对检测性能的影响.数据集规模分别选取50,100,300,500,1 000,3 000,5 000,10 000,30 000条进行测试.
如图13所示,模型训练所花费的时间随数据集规模的扩大线性增加,分别在5 000条和3 000条数据规模时达到最大准确率92.81%和91.08%;而当数据集规模超过阈值时,模型训练时间达到秒级,此时已无法满足自适应检测的需求.此外,当数据集规模过大时,自适应检测的准确率也有下降的趋势,这主要是由于数据集中存在过多无法反应当前网络流量特征的噪声或冗余数据,导致模型检测性能下降,因此本方案分别选取5 000条和3 000条数据作为自适应检测过程中的训练数据集的规模.
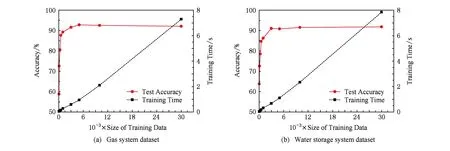
Fig. 13 The effect of the size of training dataset on detection performance during dynamic detection图13 自适应检测过程中训练数据集规模对检测性能的影响
上述实验结果表明:本方案能够利用少量已标记准确数据集生成大规模准确标记训练数据集保证模型训练过程的有效,并能够准确地提取目标网络中的重要网络流量的特征,保证了自适应检测过程中模型对不同攻击的检测精度.
4 结 论
本文提出了一种基于信息增益率和半监督学习的入侵检测方案,针对未知攻击网络流量特征难以定量选取、动态变化的攻击难以自适应地应对以及训练数据集规模过小而导致模型难以训练3个问题,采用半监督学习算法通过少量已标记数据生成大规模训练数据集,以此对检测模型进行训练,并引入信息增益率对网络流量特征自适应地定量提取以实现对目标网络中未知攻击的检测.通过实验与RF, KNN和SVM算法的检测结果对比以及在不同数据集上的检测结果验证了本方案的有效性,并分别分析了不同规模初始训练数据集和决策树个数的选取对检测性能的影响,最后对比了自适应的检测过程中不同规模训练数据集对检测性能的影响.
[1] Lee W, Stolfo S J, Mok K W. A data mining framework for building intrusion detection models[C] //Proc of the 1999 IEEE Symp on Security and Privacy. Piscataway, NJ: IEEE, 1999: 120-132
[2] Roesch M. Snort: Lightweight intrusion detection for networks[C] //Proc of the 13th Conf on Systems Administration. Berkeley, CA: USENIX Association, 1999: 229-238
[3] Tavallaee M, Bagheri E, Lu Wei. A detailed analysis of the KDD CUP 99 data set[C] //Proc of the 2nd IEEE Symp on Computational Intelligence for Security and Defense Applications. Piscataway, NJ: IEEE, 2009: 53-58
[4] Ghinita G, Kalnis P, Skiadopoulos S. Mobihide: A peer-to-peer system for anonymous location-based queries[C] //Proc of the 10th Int Symp. Boston, MA: DBLP, 2007: 221-238
[5] Delgado M L.On the effectiveness of intrusion detection strategies for wireless sensor networks: An evolutionary game approach[J]. Ad Hoc & Sensor Wireless Networks, 2017, 35(1/2): 25-40
[6] Guo Qi, Li Xiaohong, Xu Guangquan, et al. MP-MID: Multi-protocol oriented middleware-level intrusion detection method for wireless sensor networks[J]. Future Generation Computer System, 2017, 70(1): 42-47
[7] Jeffrey P, Sadegh F, Zhu Quanyan. Flip the cloud: Cyber-physical signaling games in the presence of advanced persistent threats[C] //Proc of the 6th Int Conf on Decision and Game Theory for Security. Berlin: Springer, 2015: 289-308
[8] Fronimos D, Emmanouil M, Vassilios C. Evaluating low interaction honeypots and on their use against advanced persistent threats[C] //Proc of the 18th Panhellenic Conf on Informatics. New York: ACM, 2014: 1-2
[9] Taeshik S, Jongsub M. A hybrid machine learning approach to network anomaly detection[J]. Information Sciences, 2007, 177(18): 3799-3821
[10] Haq N F, Onik A R, Shah F M. An ensemble framework of anomaly detection using hybridized feature selection approach (HFSA)[C] //Proc of the 2015 SAI Conf on Intelligent Systems. Piscataway, NJ: IEEE, 2015: 989-995
[11] Kanakarajan N K, Muniasamy K. Improving the accuracy of intrusion detection using GAR-Forest with feature selection[C] //Proc of the 4th Int Conf on Frontiers in Intelligent Computing: Theory and Applications. Berlin: Springer, 2015: 539-547
[12] Lin Weichao, Ke S W, Tsai C F. CANN: An intrusion detection system based on combining cluster centers and nearest neighbors[J]. Knowledge Based Systems, 2015, 78(1): 13-21
[13] Liu Guisong, Yi Zhang, Yang Shangming. A hierarchical intrusion detection model based on the PCA neural networks[J]. Neurocomputing, 2007, 70(7/9): 1561-1568
[14] Chapelle O, Scholkopf B, Zien A. Semi-supervised learning[J]. Journal of the Royal Statistical Society, 2006, 172(2): 1826-1831
[15] Basu S, Bilenko M, Mooney R J. A probabilistic framework for semi-supervised clustering[C] //Proc of the 10th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining (KDD 2004). New York: ACM, 2004: 59-68
[16] Agtawal R, Gehrke J E, Gunopulos D. Automatic subspace clustering of high dimensional data for data mining applications[C] //Proc of the 4th ACM SIGMOD Int Conf on Management of Data. New York: ACM, 1998: 94-105
[17] Manuel F, Eva C, Senen B. Do we need hundreds of classifiers to solve real world classification problems?[J]. Journal of Machine Learning Research, 2014, 15(1): 3133-3181
[18] Leo B. Random forests[J]. Machine Learning, 2001, 45(1): 5-32
[19] Shannon C E. A mathematical theory of communication[J]. Bell System Technical Journal, 1948, 27(3): 379-423
[20] Wang Gang, Hao Jinxing, Ma Jian, et al. A new approach to intrusion detection using artificial neural networks and fuzzy clustering[J]. Expert Systems with Applications, 2010, 37(9): 6225-6232
[21] Zhang Xueqin, Gu Chunhua, Lin Jiajun. Intrusion detection system based on feature selection and support vector machine[C] //Proc of the 1st Int Conf on Communications and Networking. Piscataway, NJ: IEEE, 2006: 1-5
[22] Liu Guisong, Yi Zhang, Yang Shangming. A hierarchical intrusion detection model based on the PCA neural networks[J]. Neurocomputing, 2007, 70(7/9): 1561-1568
AnIntrusionDetectionSchemeBasedonSemi-SupervisedLearningandInformationGainRatio
Xu Mengfan, Li Xinghua, Liu Hai, Zhong Cheng, and Ma Jianfeng
(SchoolofCyberEngineering,XidianUniversality,Xi’an710071)
State-of-the-art intrusion detection schemes for unknown attacks employ machine learning techniques to identify anomaly features within network traffic data. However, due to the lack of enough training set, the difficulty of selecting features quantitatively and the dynamic change of unknown attacks, the existing schemes cannot detect unknown attacks effectually. To address this issue, an intrusion detection scheme based on semi-supervised learning and information gain ratio is proposed. In order to overcome the limited problem of training set in the training period, the semi-supervised learning algorithm is used to obtain large-scale training set with a small amount of labelled data. In the detection period, the information gain ratio is introduced to determine the impact of different features and weight voting to infer the final output label to identify unknown attacks adaptively and quantitatively, which can not only retain the information of features at utmost, but also adjust the weight of single decision tree adaptively against dynamic attacks. Extensive experiments indicate that the proposed scheme can quantitatively analyze the important network traffic features of unknown attacks and detect them by using a small amount of labelled data with no less than 91% accuracy and no more than 5% false negative rate, which have obvious advantages over existing schemes.
intrusion detection; unknown attacks; feature selection; semi-supervised learning; information gain ratio
TP309.7

XuMengfan, born in 1989. PhD candidate. His main research interests include network and information security, APT attack detection.

LiXinghua, born in 1978. Professor and PhD supervisor in Xidian University. His main research interests include wireless networks security, privacy protection, cloud computing, software defined network, and security protocol formal methodology.

LiuHai, born in 1984. PhD candidate at Xidian University. His main research interests include rational cryptographic protocol, location-based privacy protection, and software defined network (liuhai4757@163.com).

ZhongCheng, born in 1994. MSc candidate. His main research interests include network and information security, intrusion detection.

MaJianfeng, born in 1963. Professor and PhD supervisor in Xidian University. Member of CCF. His main research interests include information security, coding theory, and cryptography.
