基于NoSQL的新农合高效云存储方法
2017-10-23张国华徐建军刘丽娟
张国华,徐建军,刘丽娟
(南京师范大学泰州学院,江苏 泰州 225300)
基于NoSQL的新农合高效云存储方法
张国华,徐建军,刘丽娟
(南京师范大学泰州学院,江苏 泰州 225300)
国内新型农村合作医疗系统(以下简称新农合)大多采用了关系型数据库作为数据存储介质,新农合中的参合、门诊、药品等数据分布在各省厅、县市乃至镇村等医疗卫生服务部门的服务器中。它们的业务数据量增长速度极快,服务器节点也经常变化,所以该方案一直无法突破数据量横向拓展的瓶颈问题。随着数据量的快速增长,该问题对整个新农合系统的影响也愈加突出。为此,提出了另一种大数据存储解决方案,即采用非关系型数据库MongoDB来存储和扩展新农合中的大数据。为进一步验证该方案在新农合应用中的有效性和可行性,进行了非关系数据库MongoDB与关系型数据库两个集群并发与读写能力的对比实验验证。理论分析和实验结果表明,非关系型数据库MongoDB在处理海量数据方面展现出了更好的优越性和适用性,能有效解决新农合系统大数据的横向拓展问题,也能为其他类似信息系统提供理论支撑和技术参考。
新农合;MongoDB;大数据;NoSQL
0 引 言
新型农村合作医疗制度(以下简称“新农合”)是由政府引导与支持,农民自愿参加,由农民个人、集体和政府等共同筹资,以大病统筹医疗为主要目的农民医疗互助制度。为确保落实这项制度,卫生部出台了新农合信息系统的标准技术规范,即《新型农村合作医疗信息系统基本规范(试行)》(卫办农卫发〔2005〕108号),规定了各省市的卫生主管部门必须充分考虑未来发展规划并结合当地实际情况,合理选择适合本地实情的技术方案、投资成本和阶段性综合性卫生管理信息系统并充分有效地利用相关信息。
目前绝大部分新农合系统采用分布式数据库(DBMS)[1],把数据分散在网络的不同服务器上,而总体上属于相同系统的数据子集,它是数据库技术与网络技术相结合的产物,提供了一种更高层次的大数据服务。而在新农合系统中,参合、门诊、药品等数据分布在省厅、各县市乃至各镇村等医疗卫生部门服务器上[2],各业务部分的数据量增长速度极快,且各医疗卫生部门的服务器节点经常变化,其基本采用关系型数据库来构建分布式系统,而该建立方案一直无法突破数据量的瓶颈[3]。随着数据量的增加,系统的数据操作,并发访问,数据分析等已逐渐不能适应用户需求,研究和探讨分布式环境下的新农合海量数据存储已经十分急迫。
为解决上述问题,文中进行了非关系数据库MongoDB与关系型数据库两个集群并发与读写能力的对比实验验证。结果表明,提出的方案有效可行。
1 系统结构及组成
根据新农合系统实际需求,在市级主管卫生部门建立集中数据中心[4],统筹管理全市新农合业务,其主要涵盖了四个主要的功能模块:决策辅助子系统、业务管理子系统、数据交换平台[5]、表示层网站。系统总体架构如图1所示。
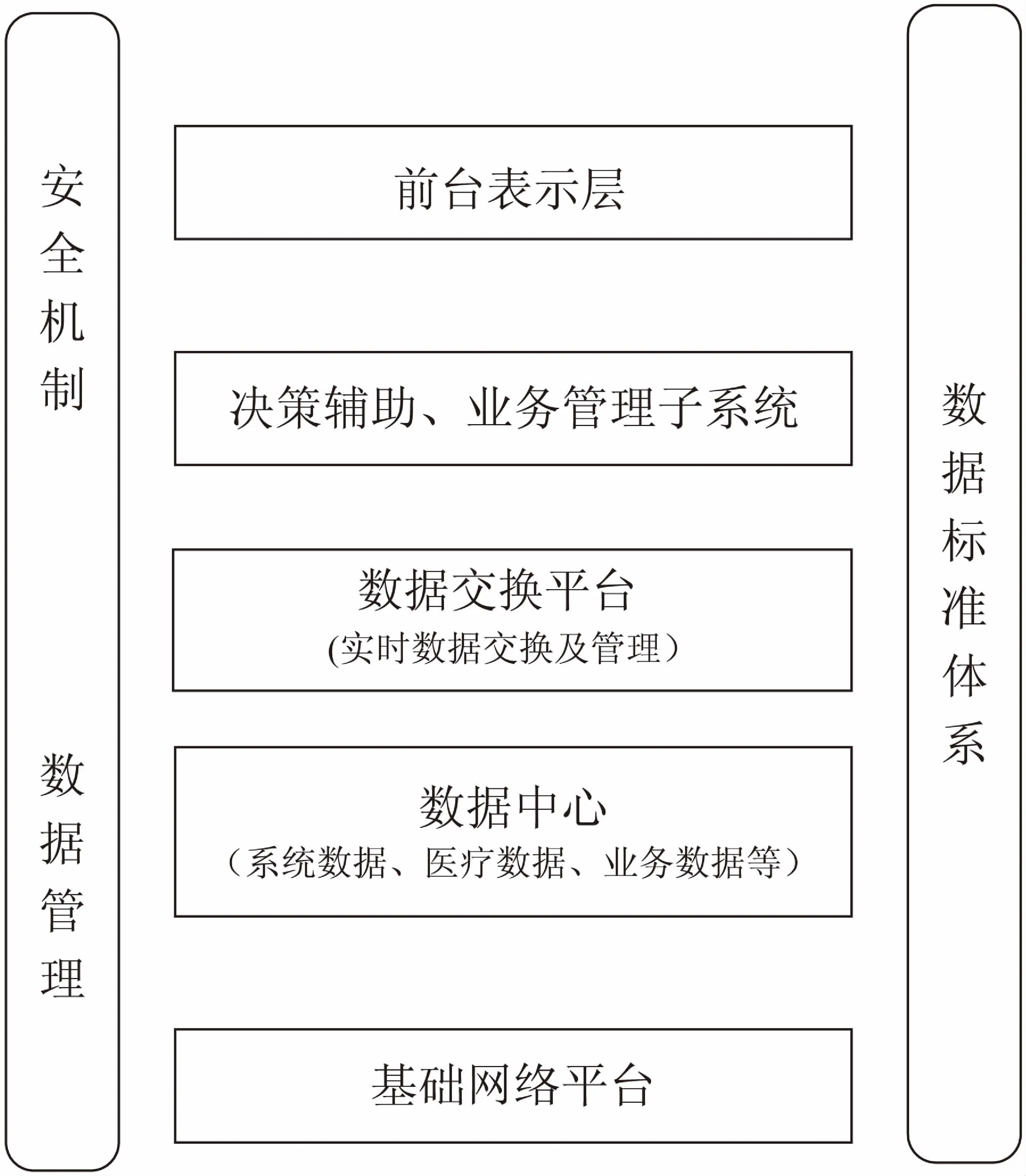
图1 系统总体架构
数据中心的数据主要来自各级医疗卫生部门,各级医疗卫生服务部门(社区卫生服务站),保险公司的结报中心以及各级卫生主管部门。而绝大部分市级新农合系统采用的是分布式的关系型数据库系统,主要问题是,随着新农合系统数据量的迅速增加,参保人数的普及,数据横向扩展需要增加服务器节点,这种架构使原有的整体新农合系统的升级变得非常困难和棘手,同时数据库的并发请求非常高,通常能达到每秒几万次,而该系统消耗的通信开销[6]主要由三部分组成:外存储器读写代价(即I/O消耗代价);数据的处理代价(即CPU的消耗代价);通信传输代价(即网络数据传输代价)。在分布式系统中,因数据分布在网络的若干服务器上,相对来说,通信传输代价在整个处理代价中占比最高,是应该考虑的主要方面。而通信消耗代价模型在网络传输过程中有两种影响:费用与延迟。其中费用占主体地位。所以按传输费用衡量是指使通信中的整个传输开销最小,即传输的数据量最小。其模型为:
CCOM(X)=C0+C1*X
其中,C0为传输数据过程中启动所需的费用(启动一次),简称启动消耗代价;C1为网络单位传输数据费用,简称单位传输代价;X为需传输的数据量。
因此,消耗的硬盘I/O服务器就无法承担了,在庞大的新农合系统中查询数据,效率将极其低下。对于新农合这种24小时进行不间断服务的系统来说,对原有数据库进行升级和扩展变得异常困难,如果采用停止服务来迁移数据,通过添加服务器的节点来扩展是不可能完成的,因为病人入院出院的数据结报都是要求即时完成的。
数据中心架构如图2所示。
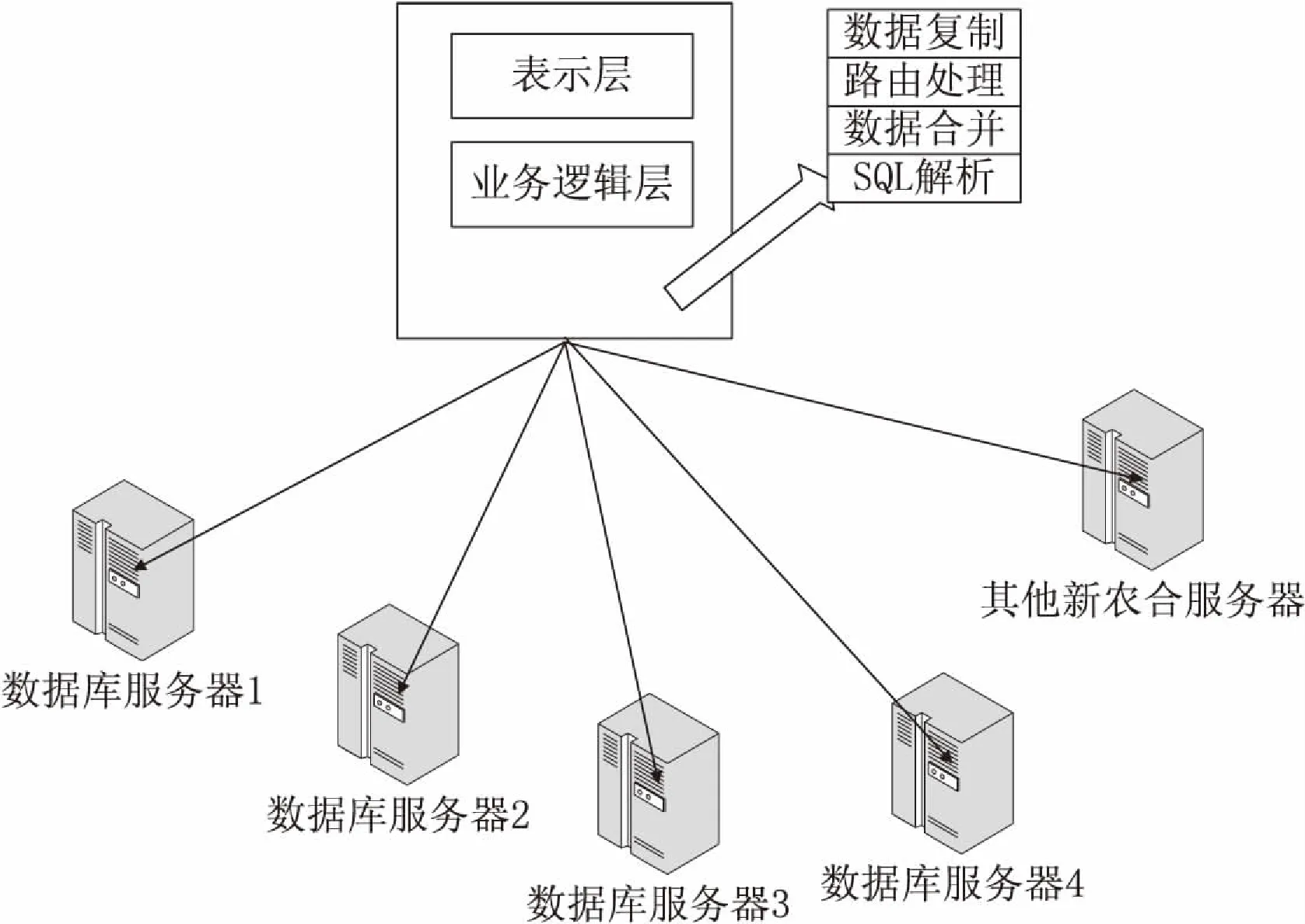
图2 数据中心架构
传统关系数据库海量数据读写主要采用分而治之的方法,图中的数据访问层设计了特定的数据访问组件,它的主要作用是SQL解析[7]与路由处理[8]。其能根据应用的请求智能解析当前访问的SQL,根据相应函数规则来决定访问相应业务数据库的对应数据并返回结果。
虽然很多科研人员在分布式关系数据库操作方面做了大量工作,常见的优化算法包括多元连接算法[8]、贪婪算法[9]、半连接算法[10]、遗传模拟退火算法[11]等,系统整体性能有所优化,而且在系统早期,数据总量不大时能顺畅运行。但随着数据量不断增多,数据处理时间会不断增加,后续一定会出现机器硬件瓶颈问题,一旦分布式数据库服务器的节点需拓展,整个系统架构都会发生变化,其原先的优化算法必须重新设计,消耗的时间代价、资本代价都将无法承受。
为解决这些分布式关系数据库系统存在的问题,采用优化的NoSQL数据库MongoDB来存储和扩展数据节点,达到对原有新农合系统数据扩展和性能提升的目标。
2 NoSQL分布存储与MongoDB
NoSQL[12],非关系型数据库,与传统的RDMS(关系型数据库)采用了完全不同的数据存取方式。随着互联网WEB2.0、3.0系统的不断兴起,传统的关系数据库作为这些系统的数据存储与管理平台已经显得力不从心,特别应对超大规模和高并发的SNS类型的WEB2.0、3.0系统更显得疲惫不堪,暴露出很多无法克服的问题。NoSQL就是为了解决这些问题而产生的,它很好地解决大规模数据集合与多重数据种类带来的挑战,尤其是解决了大数据应用难题。而对于新农合系统涉及的患者的CT,X光片等半结构化的图像数据以及手术过程的视频数据,更适合在NoSQL数据库中进行存储,并对这些数据进行挖掘,也更容易实现图1中的决策辅助子系统。
NoSQL类型的数据库管理系统也很多,其中MongoDB是一种杰出的代表,它是由C++语言编写的,而且是基于分布式文件存储的开源的数据库系统。在负载很高的情况下,能够很便捷地管理更多的节点,并能保证服务器性能。MongoDB很好地为WEB应用提供了可扩展的高性能的数据存储解决方案。能对新农合系统的数据库便捷地实现横向扩展,突破服务器硬件的瓶颈。在2013年8月20日,随着MongoDB 2.4.6第一个稳定版的发布,技术日臻成熟,并且近些年在全球范围内已经有很多知名企业(例如Google、Facebook、百度、华为等机构)均已开始使用MongoDB数据库。
MongoDB中存在一种集群技术,即分片技术,可以满足MongoDB数据量大量增长的需求。MongoDB的分片[13],是将collection的数据进行分割,然后将不同的部分分别存储到不同的机器上。当collection所占空间过大时,需要增加一台新的机器,分片会自动将collection[14]的数据分发到新的机器上,主要有以下三个组件:
Shard(数据分片):用于存储实际数据块,实际架构环境中一个shard server角色可由若干台机器共同组成一个relica set承担,可以防止服务器单点故障;
Config Server(分布式配置服务器):mongod实例,存储了所有的ClusterMetadata;
Query Routers[15](前端路由):客户端接入,能让整个集群像单一数据库那样操作,前端应用的使用非常透明。
3 建立的两种实验集群
实验利用4所不同地点的服务器,分别为A,B(将涉及数据迁徙),C,D。服务器的操作系统均为Windows7,CPU主频为2.7 GHz,内存为8 GB。
3.1方案一:关系数据库实验集群
数据库管理系统均为SQL Server 2010版本,A服务器为基层农民参保信息采集点数据库,其存储了农民参保采集信息表,数据量为1 GB;B服务器为某医院HIS数据库[14],其存储了农民门诊住院记录,数据量为30 GB;C服务器为卫生行政主管部门数据库,其存储了新农合数据统计信息表,数据量为20 GB;D服务器为负责新农合报销的保险公司结算中心数据库,其存储了新农合报销记录表,数据量为15 GB。其分布式架构见图3。其中B服务器数据量增长迅猛,后续将涉及数据迁移及拆分。

图3 分布式关系数据库架构
3.2方案二:基于文件系统实验集群
MongoDB(该方案的软件版本为MongoDB 3.0)是将数据存储在文件里,文件结构及数据分布与方案一保持一致,对于数据的管理具备独有的优势,在MongoDB附带一个文件系统GridFS,能透明地实现数据的分割迁移。实验采用了4台服务器,5个MongoDB服务器进程用来模拟分布式数据库系统,及数据库的横向分片功能,架构如图4所示。
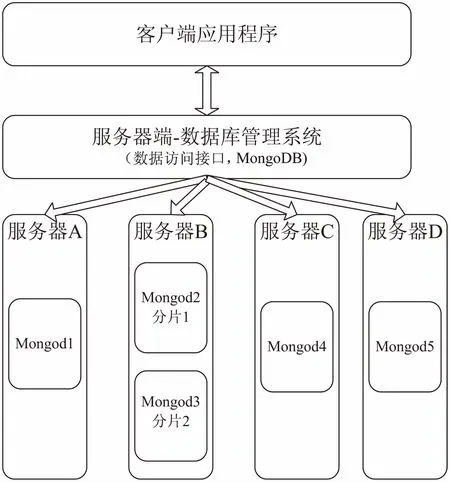
图4 分布式MongoDB架构
4 实 验
以下实验都是通过客户端,对服务器B的操作,因实验均在学校机房完成,故忽略了通信代价,仅对比CPU占用代价。测试程序每次测试100万条记录,如并发10测试,每并发操作10万条记录;并发20测试,每并发5万条记录,依次类推(为简化问题,并发数采用100以内并且可以被100万整除的整数)。
4.1写入性能对比及CPU占用消耗
为增强可比性,方案一和方案二均在相同字段写入,写入次数对比情况见图5。
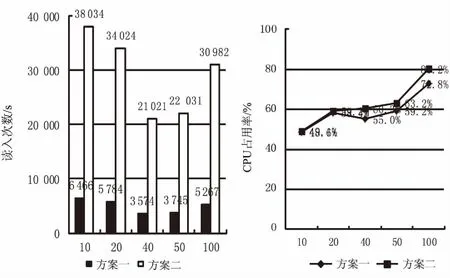
图5 写入次数及CPU占用对比
4.2读入性能对比及CPU占用消耗
同样是方案一和方案二,均对相同字段进行数据读取,读取次数对比情况见图6。
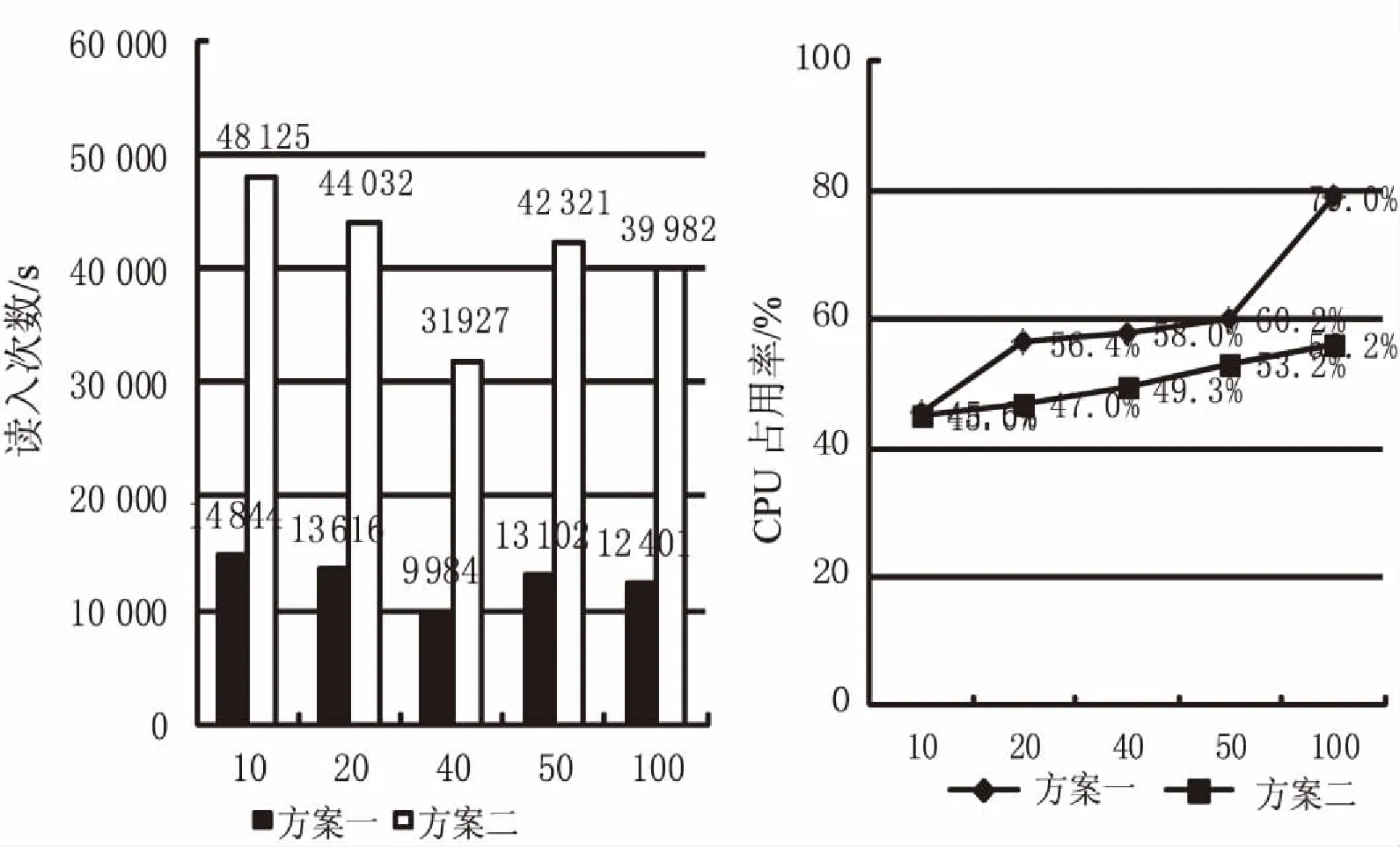
图6 读入次数及CPU占用对比图
4.3实验结果与分析
通过以上对传统关系型分布式数据库与分布式MongoDB数据库的实验对比,得出MongoDB无论是在查询性能,还是数据写入性能上均有一定优势,但在写入时MongoDB占用CPU更高,而读入时MongoDB占用CPU相对较少,而新农合系统的读入数据使用频次更高,所有方案二仍然可取,而且方案二给出了一种针对信息系统数据横向扩展上相对便捷的处理方案,具备很强的实用价值。
5 结束语
为有效解决新农合系统大数据的横向拓展问题,在传统关系型分布式信息系统架构的基础上,提出了基于NoSQL的海量数据存储解决方案。理论分析及实验结果表明,非关系型分布式信息系统在并发效率与读写效率上与传统关系型分布式数据库相比有显著提升,能有效提高新农合系统相关业务部门的工作效率和效能,但也存在数据弱一致性、占用空间较大、管理界面友好性差、事务控制需通过开发者的业务逻辑代码才能完成等缺点,因此采用NoSQL型数据库作为存储介质,开发难度会有所增加。为此,将继续关注和研究NoSQL相关新技术,并进一步解决NoSQL存在的缺陷。
[1] 马骋宇.新型农村合作医疗基金购买商业大病保险的博弈模型研究[J].中国卫生经济,2014,33(4):43-45.
[2] 代志明.“三明医改”模式可以复制吗?—兼与钟东波先生商榷[J].郑州轻工业学院学报:社会科学报,2015,16(2):35-38.
[3] 陈 晓,何晓宁,赵新东.兵团第四师医疗保障制度改革现状及思考[J].兵团党校学报,2015(5):17-21.
[4] 张 宇,张延松,陈 红,等.向量计算Array OLAP查询处理技术[J].计算机工程与应用,2015,51(18):24-31.
[5] 胡诗骏,姚佩阳,孙 昱,等.DLS和NGA结合的平台资源调度方法[J].空军工程大学学报:自然科学版,2015,16(3):82-86.
[6] 吴明礼,任天鸿,李也白.基于OpenStack的私有云平台资源管理技术的应用与研究[J].工业技术创新,2015,2(3):334-341.
[7] 李彦广.基于Spark+MLlib分布式学习算法的研究[J].商洛学院学报,2015,29(2):16-19.
[8] 孙忠芳,谭 智,付海龙.基于MongoDB集群的高性能瓦片服务器[J].中国科技信息,2015(8):107-109.
[9] 申德荣,于 戈,王习特,等.支持大数据管理的NoSQL系统研究综述[J].软件学报,2013,24(8):1786-1803.
[10] 陈崇成,林剑峰,吴小竹,等.基于NoSQL的海量空间数据云存储与服务方法[J].地球信息科学学报,2013,15(2):166-174.
[11] 赵鹏军,刘三阳.求解复杂函数优化问题的混合蛙跳算法[J].计算机应用研究,2009,26(7):2435-2437.
[12] Gilbert S,Lynch N.Brewer’s conjecture and the feasibility of consistent,available,partition-tolerant web services[J].ACM SIGACT News,2002,33(2):51-59.
[13] Baca R,Kratky M. TJDewey-on the efficient path labeling scheme holistic approach[M]//Database systems for advanced applications.Berlin:Springer-Verlag,2009:6-20.
[14] Vogels W. Eventually consistent[J]. Communications of ACM,2009,52(1):14-19.
[15] Elmasri R,Navathe S.Fundamentals of database systems[M].Beijing:Posts and Telecom Press,2009.
AnEfficientCloudStorageMethodwithNoSQLforNewRuralCooperativeMedicalCare
ZHANG Guo-hua,XU Jian-jun,LIU Li-juan
(Nanjing Normal University Taizhou College,Taizhou 225300,China)
The New Rural Cooperative Medical System (NRCMS) in China mostly uses the relational database as the data storage medium,and the data of participation,clinic, drug in NRCMS is distributed in medical and health services department server in all ministries,counties and towns and villages.Their business data volume is extremely fast in growth rate,and server nodes are often changed,so the program has been unable to break through the bottleneck of the horizontal expansion of the data volume.With the rapid increase in the amount of data,the impact of NRCMS is also more prominent.Therefore another solution is proposed with use of non relational database MongoDB for storing and expanding the big data.In order to further verify its effectiveness and feasibility in the new rural cooperative medical system,comparative experiments for verifications of the relationship between the two clusters of non relational database MongoDB and relational database is conducted.Theoretical analysis and experimental results show that the MongoDB in the treatment of massive data indicates better superiority and applicability in solving the expansion of horizontal big data medical system and has provided theoretical support and technical reference for other similar information systems.
NRCMS;MongoDB;big data;NoSQL
TP311
A
1673-629X(2017)10-0197-04
2016-07-25
2016-11-08 < class="emphasis_bold">网络出版时间
时间:2017-07-11
教育部Google2014年产学合作专业综合改革项目(PO640068);江苏省高校自然科学研究面上项目(15KJB170006)
张国华(1981-),男,硕士,讲师,研究方向为分布式数据库。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170711.1454.024.html
10.3969/j.issn.1673-629X.2017.10.042
