节点进行处理,比较节点中的中文字符数量。该方法虽利用了中文网页的特性,实现简单,健壮性强,但未考虑英文网页,且对短正文网页效果不理想。(4)基于视觉分块的方法。
通常在浏览网页时,人们往往将不同的功能区域看成不同的语义块。较早的分块方式是按照HTML的树形结构进行[13],但随着HTML的发展,仅仅依赖树形结构,不足以满足通用性。2003年,微软亚洲研究院提出基于页面视觉分块的算法(VIsion-based Page Segmentation,VIPS),利用页面的可视化信息在树形结构的基础上进行网页分块。然而它仅仅是一种分块算法,利用已有的视觉信息,并未对页面进行净化操作,可以在算法的基础上加入规则进行页面净化操作。文献[14]通过修改VIPS算法迭代过程,在块划分后进行一系列的分隔条提取和语义块重构,采用制定规则对页面进行去噪操作。VIPS算法充分考虑了用户的视觉习惯,但由于分隔条提取和语义块重构需要过多的人工参与,复杂度较高,且缺乏对网页中和信息的利用。
文中在VIPS算法分块的基础上,提出样式树,再根据链接比及树路径距离生成相应的权重树,自动调整权重,根据权重进行剪枝操作,生成去噪页面。
2 样式树定义
样式树由DOM树演化而来[15],主要包含两类虚拟节点:样式节点(Style nodes)和元素节点(Element nodes)。样式节点描述了节点布局或者展现风格,样式节点A的表现样式SA是一个序列。其中li是一个二元组(Tag,Styles)元素,通常Styles表示为{width:300,height:200,bg-Color:red},n表示样式长度。节点E描述节点的属性信息,表示为E(Tag,Attrs,Content),其中Tag表示节点标识,Attrs表示属性信息,Content表示节点的文本信息。基本样式树如图1所示。

图1 基本样式树
3 基于节点权重的网页去噪算法
3.1算法基本思想
基于节点权重的去噪算法在VIPS基础上,将VIPS生成的基本视觉块树进行样式树的转化,利用样式树节点中的样式特性,将叶子节点划分成细粒度的样式树,再对样式树进行权重标注,根据权重标注进行剪枝,生成去噪页面。基本流程如图2所示。
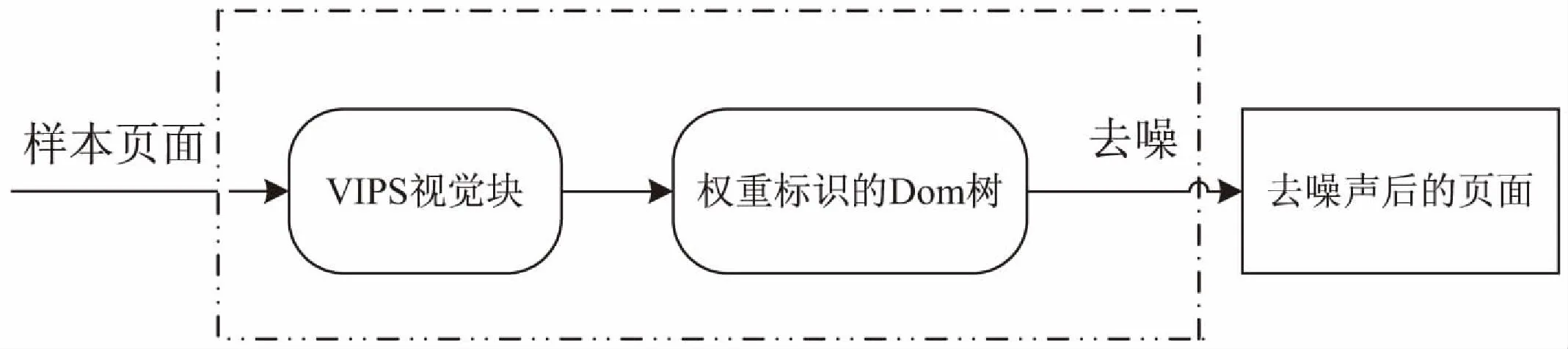
图2 从样本页面到净化页面的总体流程
通常生成的样式树,无权重表示,在属性节点的基础上,引入权重节点的概念。权重节点T表示为QT,记为Q(k,d,t,m)。其中,k表示链接比,即当前节点中链接数占总链接数的比值;d表示树路径距离,即当前节点与容器节点在树形结构上的距离;t表示文本比,即当前节点文本占总文本的比例;m表示节点私有属性的权重系数。为了使H(Qi)的值落在[0,1]之间,使用节点的标签个数n将H(Qi)归一化。
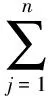
(1)
其中,ki表示第i个标签的链接比;ti表示第i个标签的文本系数;di表示第i个标签的树路径距离;D表示权重树中的节点路径和。
3.2视觉块树细粒度化
通常,VIPS生成的视觉树,只是初步提取了页面的基本布局信息,粗粒度的视觉块树将噪声和正文融合到了相同的块中,必须进行细粒度化。此时对生成的样式树进行样式节点和属性节点的标注。对已经标注完的块节点,进行子元素的相似度分析。子元素的样式节点用二元组表示,属性节点标识为E(Tag,Attrs,Content),由于li的Styles是以键值对的形式存在,在此将键值对转化为样式系数Ci,将块标签Tag表示为HTML中对应的NODE值,此时li表示为(Ti,Ci)。节点相似度判断如下:

(2)
当相关系数较小时,将子节点进行分裂。采用自顶向下的层次遍历方式,完成对视觉树的初步分裂。
3.3细节树剪枝
此时得到的是一棵基于样式的视觉树,在样式和基本属性上已经不可细分,在此基础上进行噪声的判断。根据大量线上页面的统计,噪声区域往往有比正文区域更多的链接比,更少的文本比,以及更浅的树距离。故此处引入权重节点的概念,对细粒度化的视觉块树进行自顶向下的标注,对权重低的节点进行剪枝操作。在初次遍历的过程中,可进行一次简单的预处理,对含有样式树节点中含有键值对display:none和position:fixed的节点进行删除操作,前者是网页中不做显示的元素,后者是悬浮窗,据大量网页的观察,两者都是判断噪声节点的重要依据。
剪枝算法描述如下:
(1)获取样式树,设样式树为Ti;
(2)For(样式树的每个节点Qi)
(3)if(该节点的css属性中含有position:fixed,display:none等键值对时) then
(4)删除该节点;
(5)Else if
(6)计算出文本比,节点的距离深度,计算权重值H(Qi);
(7)For(样式树的每个节点QT);
(8)删除平级节点中权重小的节点。
4 实 验
4.1数据集
为了验证文中算法的去噪效果,使用该算法对含有噪音的网页进行处理。考虑到页面抽取时信息获取的客观性,选取网易、新浪等页面各200个,考研论坛等论坛型网页200个,从网页处理的整体效果出发,进行网页去噪的实验。
4.2评价指标
在实验中,常见的评测指标有准确率和召回率。由于准确率和召回率介于[0,1]之间,而且不相互独立。所以文中引入同时兼顾准确率和召回率的F1,即F-measure,作为综合评价指标。
准确率为:
P=t0/t1
(3)
召回率为:
R=t0/t2
(4)
其中,t0表示当前页面被抽取出的正文块;t1表示当前页面中全部的正文块;t2表示被当做正文中抽取出来的信息块。
由于在F-measure公式中β通常用来调节准确率和召回率的权重,而此处重点考虑的是网页抽取的准确率和召回率,所以取β为1,最终用来判断实验效果的公式如下:

(5)
4.3实验结果与分析
为了验证文中算法,分别进行了两组实验,结果如表1和表2所示[16]。
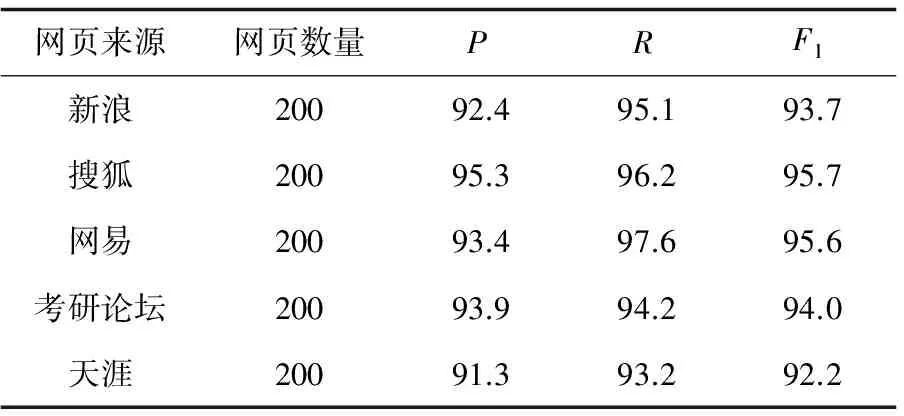
表1 文中算法

表2 基于行块分布函数算法
从上述实验可以看出,文中算法在准确率和召回率方面要优于基于行块分布函数算法的页面处理效果。基于行块分布函数的方法虽然实现简单,但是对去除标签后的文本分块的数量选取将直接影响网页正文提取的准确率,而且去除标签同时也去除了页面中大量可用的视觉信息,当噪音文本与正文文本混杂时,将会被提取。文中充分考虑了页面的视觉特征,在当前视觉元素丰富的网页中,从网页制作者的方向出发,利用大量的视觉特性,提取视觉系数,再利用正文内容特征,合理去除页面中的噪音块,使正文块更易被识别。
5 结束语
文中在VIPS分块的基础上,引入了样式树的概念,取消了原有的基于视觉繁杂的启发式的规则,只使用了VIPS粗粒度的视觉分块,对粗粒度的视觉块树进行细粒度的划分,进一步考虑了视觉块之间的相关性,再对标注完权重的样式树进行去噪操作。实验结果表明,该算法可以更好地去除页面中导航栏等局部噪声以及隐藏中正文块的全局噪声。该算法主要针对主题型页面、论坛型页面,但当正文内容和噪音内容相似度较高时,去噪效果不够理想,这是该算法的局限性。在以后的研究中,将进一步分析这些网页的特征,寻求改进方法,增强算法的健壮性。
[1] 欧石燕,唐振贵,苏翡斐.面向信息检索的术语服务构建与应用研究[J].中国图书馆学报,2016,42(2):32-51.
[2] Witten I H,Frank E.Data mining:practical machine learning tools and techniques[M].[s.l.]:Morgan Kaufmann Publishers Inc.,2011:206-207.
[3] 高 琪,张永平.超链接导向搜索算法中主题漂移的研究[J].计算机应用,2009,29(11):3100-3102.
[4] 刘华星,杨 庚.HTML5-下一代Web开发标准研究[J].计算机技术与发展,2011,21(8):54-58.
[5] 李效东,顾毓清.基于DOM的Web信息提取[J].计算机学报,2002,25(5):526-533.
[6] 胡金栋.网页正文提取及去重技术研究[D].杭州:浙江大学,2011.
[7] 汪建伟,杨冬青,高 军,等.一种基于分类算法的网页信息提取方法[J].计算机科学,2008,35(3):91-93.
[8] 王 琦,唐世渭,杨冬青,等.基于DOM的网页主题信息自动提取[J].计算机研究与发展,2004,41(10):1786-1792.
[9] 李文立,王乐超,宋春雷.基于HTML树和模板的文献信息提取方法研究[J].计算机应用研究,2010,27(12):4615-4617.
[10] Fu Y,Yang D,Tang S,et al.Using XPath to discover informative content blocks of web pages[C]//Proceedings of third international conference on semantics,knowledge and grid.[s.l.]:[s.n.],2007.
[11] 赵 文,唐建雄,高庆锋.基于统计的中文网页正文抽取的研究[J].电脑知识与技术,2008(1):120-123.
[12] 孙承杰,关 毅.基于统计的网页正文信息抽取方法的研究[J].中文信息学报,2004,18(5):17-22.
[13] 刘晨曦,吴扬扬.一种基于块分析的网页去噪音方法[J].广西师范大学:自然科学版,2007,25(2):149-152.
[14] 穆 琼.基于视觉特征的网页清洗研究与实现[D].北京:北京邮电大学,2013.
[15] Yi L,Liu B,Li X.Eliminating noisy information in Webpages for data mining[C]//Proceedings of the 9th ACMSIGKDD international conference on knowledge discovery and data mining.New York:ACM,2003:296-305.
[16] 高庆宁,吴 鹏,张晶晶.基于文档对象模型与行块分布算法的网页信息抽取[J].情报理论与实践,2016,39(4):133-137.
ResearchonWebPageDenoisingMethodBasedonNodeWeight
WANG Jian,ZHANG Jin
(College of Computer,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
As the network information is increasing continuously,website information is not only an important information resource of users,but also important data source for data mining,information retrieval and other studies.To provide the text information with high quality,website denoising has become a nonnegligible step for webpage processing.With the continuous improvement of webpage making technology,visual elements in webpage are raised increasingly,and the information of webpage node becomes richer and richer.Visual information has been a nonnegligible and important part in webpage denoising.From a user’s point of view,the visual information can immediately reflect the importance of module in the page when browsing the web page.Traditional webpage denoising technology is neglected in the visual characteristics of webpage too much.Facing to the current complex webpage,the denoising effects are decreased greatly.Based on the comprehensive visual information and node information,a noise weight-based denoising method is proposed which fully considers the visual and content characteristics of nodes.The experimental results indicate that its accuracy rate and recall rate is improved to certain content.
vision characteristics;node weight;accuracy rate;recall rate
TP301
A
1673-629X(2017)10-0083-04
2016-11-15
2017-03-07 < class="emphasis_bold">网络出版时间
时间:2017-07-19
教育部专项研究项目(2013116)
王 健(1991-),男,硕士,研究方向为大数据。
http://kns.cnki.net/kcms/detail/61.1450.tp.20170719.1110.056.html
10.3969/j.issn.1673-629X.2017.10.018
